
Home >Technology peripherals >AI >Qingbei Microsoft digs deep into GPT and understands contextual learning! It's basically the same as fine-tuning, except that the parameters haven't changed.
Qingbei Microsoft digs deep into GPT and understands contextual learning! It's basically the same as fine-tuning, except that the parameters haven't changed.

- 王林forward
- 2023-05-10 21:37:041116browse
One of the important features of large-scale pre-trained language models is the ability to learn in context (In-Context Learning, ICL), that is, through some exemplary input-label pairs, you can learn without updating parameters. New input labels are predicted.
Although the performance has improved, where the ICL capabilities of large models come from is still an open question.
To better understand how ICL works, researchers from Tsinghua University, Peking University, and Microsoft jointly published a paper that interprets language models as meta-optimizers (meta- optimizer), and understand ICL as an implicit fine-tuning.

Paper link: https://arxiv.org/abs/2212.10559
Theoretically, this article clarifies that there is a dual form (dual form) based on gradient descent optimization in Transformer attention, and based on this, the understanding of ICL is as follows. GPT first generates meta-gradients based on demonstration instances, and then applies these meta-gradients to the original GPT to build an ICL model.
In experiments, the researchers comprehensively compared the behavior of ICL and explicit fine-tuning based on real tasks to provide empirical evidence supporting this understanding.
The results prove that ICL performs similarly to explicit fine-tuning at the prediction level, representation level and attention behavior level.
In addition, inspired by the understanding of meta-optimization, through the analogy with the momentum-based gradient descent algorithm, the article also designed a momentum-based attention, compared with Ordinary attention has better performance, which once again supports the correctness of this understanding from another aspect, and also shows the potential of using this understanding to further design the model.
The principle of ICL
The researchers first conducted a qualitative analysis of the linear attention mechanism in Transformer to find out the relationship between it and gradient descent-based optimization. Dual form. ICL is then compared with explicit fine-tuning and a link is established between these two forms of optimization.
Transformer attention is meta-optimization
Suppose X is the input representation of the entire query, and X' is an example Characterization, q is the query vector, then under the ICL setting, the attention result of a head in the model is as follows:
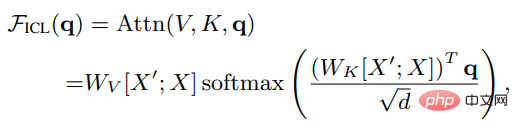
As you can see, the scaling is removed After factoring root d and softmax, the standard attention mechanism can be approximated as:
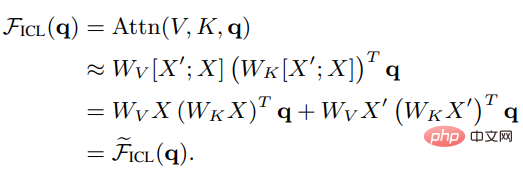
## Set Wzsl to Zero-Shot Learning (ZSL) After the initial parameters, the Transformer attention can be converted to the following dual form:
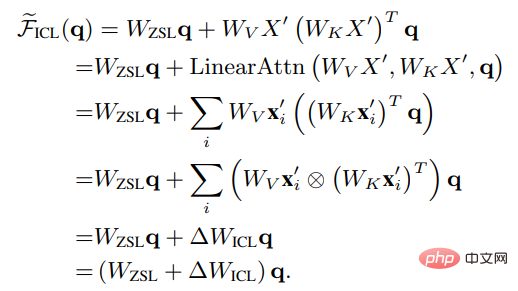
It can be seen that ICL can be interpreted as a meta-optimization (meta -optimization) process:
1. Use the pre-trained language model based on Transformer as a meta-optimizer;
2. Through positive Directional calculation, calculate the meta-gradient based on the demonstration example;
3. Through the attention mechanism, apply the meta-gradient to the original language model to establish an ICL model.
Comparison between ICL and fine-tuningTo compare meta-optimization and explicit optimization of ICL, the researchers designed a specific fine-tuning setting as a baseline for comparison: considering ICL It only directly affects the key and value of attention, so fine-tuning only updates the parameters of key and value projection.
Similarly in the non-strict form of linear attention, the fine-tuned head attention results can be expressed as:
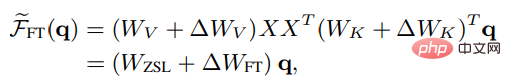
In order to make a fairer comparison with ICL, the fine-tuning setting restrictions are further set in the experiment as follows:
1. Specify the training example as a demonstration example of ICL;
2. Only perform one step of training for each example, and the order is the same as the demonstration order of ICL;
3. Use the ones used by ICL The template formats each training example and fine-tunes it using causal language modeling objectives.
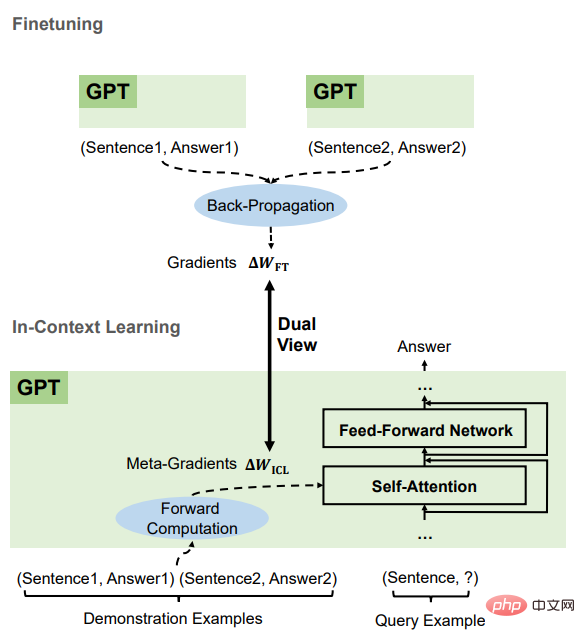
After comparison, it can be found that ICL and fine-tuning have many common attributes, mainly including four aspects.
are all gradient descent
It can be found that both ICL and fine-tuning are performed on Wzsl Update, i.e. gradient descent, the only difference is that ICL produces meta-gradients by forward computation, while finetuning obtains the true gradients by backpropagation.
The same training information
The meta-gradient of ICL is obtained based on the demonstration example , the gradient of fine-tuning is also obtained from the same training samples, that is, ICL and fine-tuning share the same source of training information.
The causal order of the training examples is the same
ICL and fine-tuning share training examples For the causal order, ICL uses decoder-only Transformers, so subsequent tokens in the example will not affect the previous tokens; for fine-tuning, since the order of the training examples is the same and only one epoch is trained, the subsequent tokens can also be guaranteed A sample has no effect on previous samples.
all act on attention
Compared with zero-shot learning, ICL The direct impact of fine-tuning and fine-tuning is limited to the calculation of key and value in attention. For ICL, the model parameters are unchanged, and it encodes the example information into additional keys and values to change the attention behavior; for the limitations introduced in fine-tuning, the training information can only affect the projection of the attention keys and values. in the matrix.
Based on these common characteristics between ICL and fine-tuning, the researchers believe that it is reasonable to understand ICL as a kind of implicit fine-tuning.
Experimental part
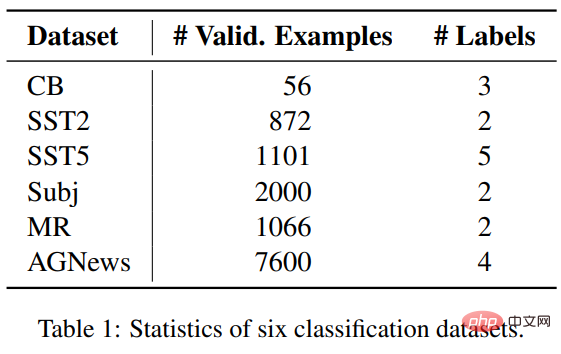
Tasks and datasets
Researchers Six data sets spanning three classification tasks were selected to compare ICL and fine-tuning, including four data sets of SST2, SST-5, MR and Subj for sentiment classification; AGNews is a topic classification data set; CB is used for Natural language reasoning.
Experimental settings
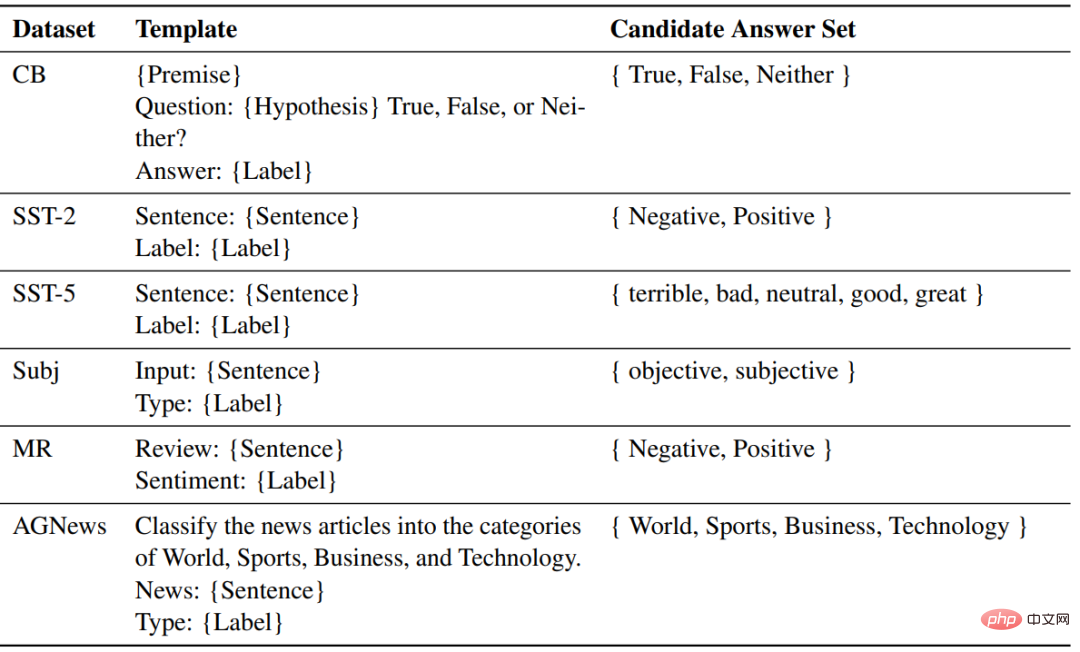
Model part used Two pre-trained language models similar to GPT were released by fairseq, with parameter sizes of 1.3B and 2.7B respectively.
For each task, the same template is used to ZSL, ICL and fine-tuned samples for formatting.
Result
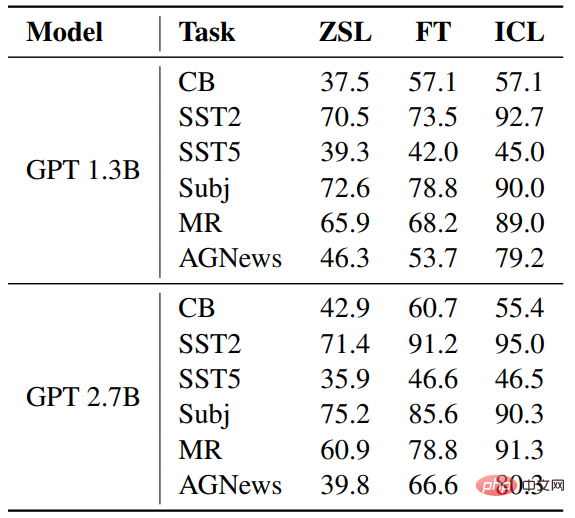
##Accuracy rate
Compared with ZSL, both ICL and fine-tuning have achieved considerable improvements, which means that their optimization is helpful for these downstream tasks. Furthermore, ICL is better than fine-tuning in a few cases.
##Rec2FTP(Recall to Finetuning Predictions)
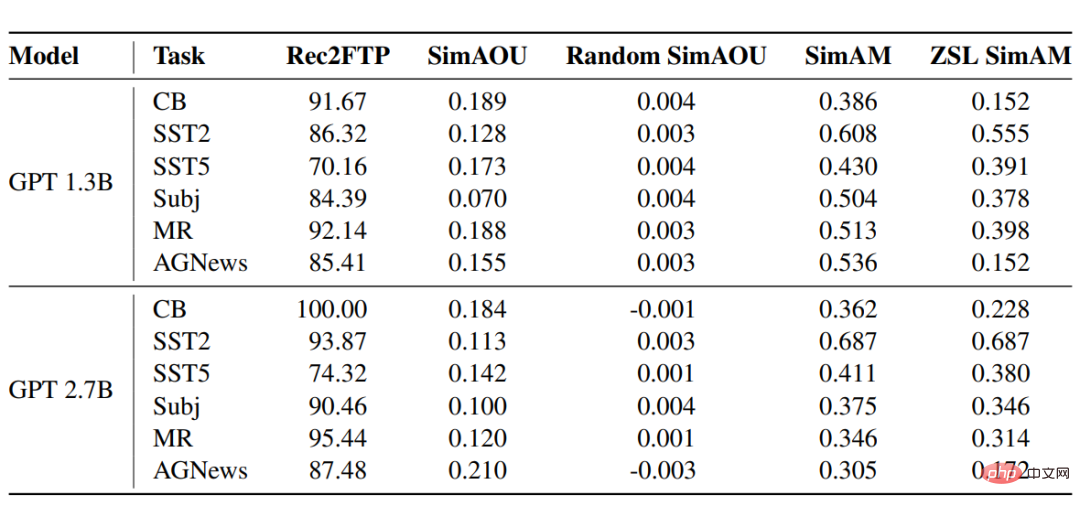
SimAOU(Similarity of Attention Output Updates)
It can be found from the results that the difference between ICL update and fine-tuning update is The similarity is much higher than random updates, which also means that at the representation level, ICL tends to change the attention results in the same direction as fine-tuning changes.
SimAM(Similarity of Attention Map)
As the baseline indicator of SimAM, ZSL SimAM calculates ICL attention Similarity between weights and ZSL attention weights. By comparing these two metrics, it can be observed that compared to ZSL, ICL tends to produce similar attention weights as fine-tuning.Similarly, at the level of attentional behavior, experimental results prove that ICL behaves similarly to fine-tuning.
The above is the detailed content of Qingbei Microsoft digs deep into GPT and understands contextual learning! It's basically the same as fine-tuning, except that the parameters haven't changed.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology