
Home >Technology peripherals >AI >The Nature sub-journal of Renmin University's Hillhouse School of Artificial Intelligence attempts to use multi-modal basic models to move towards general artificial intelligence
The Nature sub-journal of Renmin University's Hillhouse School of Artificial Intelligence attempts to use multi-modal basic models to move towards general artificial intelligence

- 王林forward
- 2023-05-09 14:34:09793browse
Recently, Professor Lu Zhiwu, Permanent Associate Professor Sun Hao, and Dean Professor Wen Jirong of the Hillhouse School of Artificial Intelligence of Renmin University of China were co-corresponding authors in the international comprehensive journal "Nature Communications" (English name: Nature Communications, referred to as Nat Commun) ) published a research paper titled "Towards Artificial General Intelligence via a Multimodal Foundation Model". The first author of the article is doctoral student Fei Nanyi. This work attempts to leverage multimodal base models toward general artificial intelligence and will have broad implications for various AI fields, such as neuroscience and healthcare. This article is an interpretation of this paper.

- Paper link: https://www.nature.com/articles /s41467-022-30761-2
- Code link: https://github.com/neilfei/brivl-nmi
The basic goal of artificial intelligence is to imitate human core cognitive activities, such as perception, memory, reasoning, etc. Although many artificial intelligence algorithms or models have achieved great success in various research fields, most artificial intelligence research is still limited by the acquisition of large amounts of labeled data or insufficient computing resources to support training on large-scale data. Limited to the acquisition of a single cognitive ability.
To overcome these limitations and take a step towards general artificial intelligence, we developed a multimodal (visual Language) basic model, that is, pre-trained model. In addition, in order for the model to obtain strong generalization ability, we propose that the pictures and texts in the training data should follow the weak semantic correlation hypothesis (as shown in Figure 1b), rather than the fine matching of picture areas and words (strong semantic correlation), because of the strong semantic correlation The assumption of semantic correlation will cause the model to lose the complex emotions and thoughts that people imply when captioning pictures.
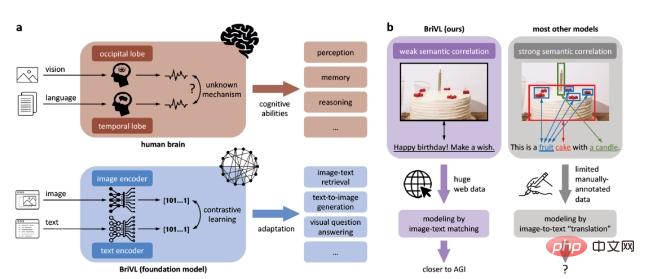

Figure 1: BriVL model based on weak semantic correlation assumption. a. Comparison between our BriVL model and the human brain in processing visual language information. b. Comparison between modeling weakly semantically related data and modeling strongly semantically related data.
By training on large-scale image and text data crawled from the Internet, the multi-modal basic model we obtained shows strong generalization ability and imagination ability . We believe that our work represents an important (albeit potentially small) step toward general artificial intelligence and will have broad implications for a variety of AI fields, such as neuroscience and healthcare.
Method
We developed a large-scale multi-modal basic model for self-supervised training on massive multi-modal data, and named it BriVL (Bridging-Vision-and-Language).
First, we use a large-scale multi-source graphic and text dataset built from the Internet, called Weak Semantic Correlation Dataset (WSCD). WSCD collects Chinese image-text pairs from multiple sources on the web, including news, encyclopedias, and social media. We only filtered out pornographic and sensitive data in WSCD without any form of editing or modification on the original data to maintain its natural data distribution. Overall, WSCD has about 650 million picture-text pairs covering many topics such as sports, daily life, and movies.
Secondly, for our network architecture, since fine-grained regional word matching does not necessarily exist between images and texts, we discard the time-consuming object detector and adopt a simple double Tower architecture, thus being able to encode image and text input via two independent encoders (Figure 2). The twin-tower structure has obvious efficiency advantages in the inference process because the features of the candidate set can be calculated and indexed before querying, meeting the real-time requirements of real-world applications. Third, with the development of large-scale distributed training technology and self-supervised learning, it has become possible to train models with massive unlabeled multi-modal data.
Specifically, in order to model the weak correlation of image-text pairs and learn a unified semantic space, we designed a cross-modal contrastive learning algorithm based on the single-modal contrastive learning method MoCo. As shown in Figure 2, our BriVL model uses the momentum mechanism to dynamically maintain the negative sample queue in different training batches. This way, we have a relatively large number of negative samples (critical for contrastive learning), while using a relatively small batch size to reduce GPU memory usage (i.e. GPU resource savings).
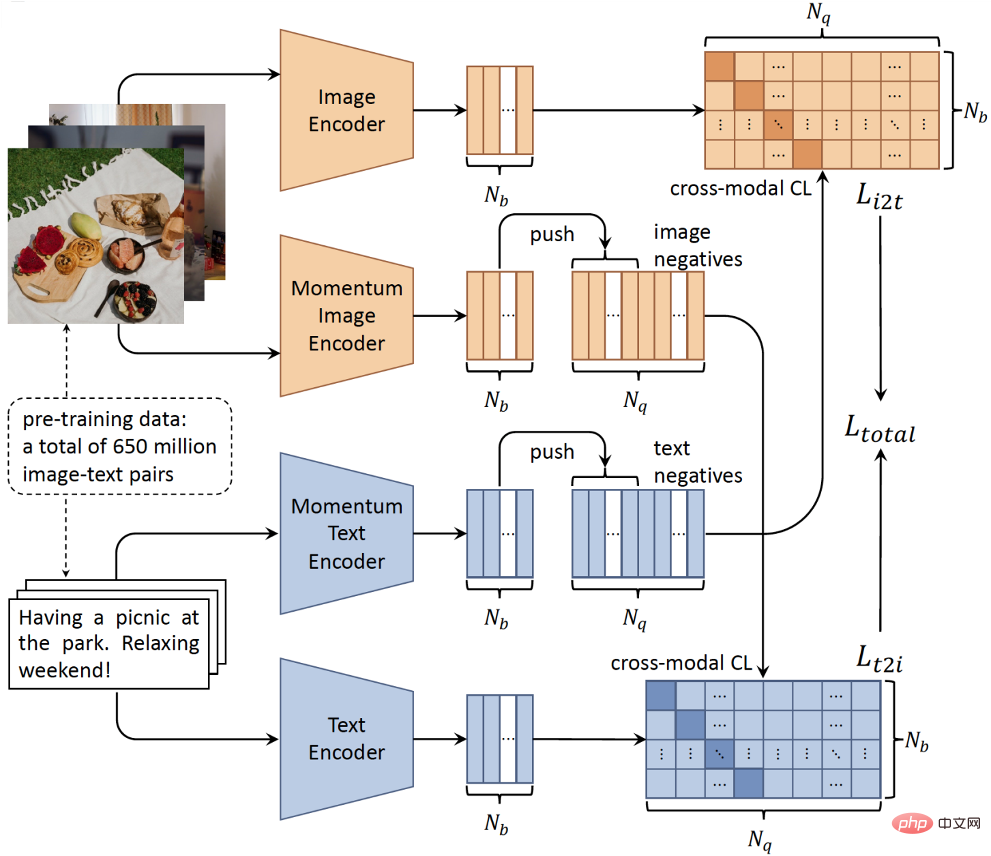
Figure 2: Schematic diagram of the BriVL model for large-scale multi-modal pre-training.
Main Results
Neural Network Visualization
When we hear words or descriptive sentences, something comes to mind Scenes. For our BriVL, after it is pre-trained on such a large number of weakly correlated image-text pairs, we are very curious about what it will imagine when given text.
Specifically, we first input a piece of text and obtain its text embedding through BriVL’s text encoder. Then we randomly initialize a noisy image and get its feature embedding through the image encoder. Since the input image is randomly initialized, its features must be inconsistent with those of the input text. Therefore, we define the goal of matching two feature embeddings and update the input image via backpropagation. The resulting image clearly shows how BriVL imagined the input text. Here we do not use any additional modules or data, and the pretrained BriVL is also frozen throughout the visualization process.
We first introduce BriVL’s ability to imagine some high-level semantic concepts (Figure 3). As you can see, although these concepts are very abstract, the visualization can still show their concrete form (e.g., "nature": grass-like plants; "time": a clock; "science": a face with glasses and an Erlenmeyer flask; "Dreamland": clouds, a bridge to the door, and a dreamlike atmosphere). This ability to generalize abstract concepts to a series of concrete objects demonstrates the effectiveness of our multimodal pre-training using only weakly semantically related data.

Figure 3: BriVL model’s imagination of abstract concepts.
In Figure 4, we show BriVL’s imagination for sentences. BriVL's imagination of "There is sunshine behind the clouds" not only literally embodies the sunshine behind the clouds, but also seems to show dangerous conditions at sea (there are ship-like objects and waves on the left), expressing the implicit meaning of this sentence . In the visualization “Blooming as Summer Flowers” we can see a cluster of flowers. The more complex text inputs for the next two scenarios are both from ancient Chinese poetry, and their syntax is completely different from the vast majority of texts in the training set. It seems that BriVL can also understand them well: for "Three or two branches of peach blossoms outside the bamboo", we can see that there are bamboos and pink flowers; for "The sun is over the mountains, the Yellow River flows into the sea", we can see The trees on the mountain cover the setting sun, and there is a small boat on the river in front. Overall, we found that BriVL remains highly imaginative even when prompted by complex sentences.


Figure 4: BriVL model’s imagination of Chinese sentences.
In Figure 5, several similar texts are used for BriVL’s neural network visualization. For "Mountains with Forests" there are more green areas in the image; for "Mountains with Stones" there are more rocks in the image; for "Mountains with Snow" the ground around the middle trees is either white or Blue; for "Mountains with Waterfalls" blue water can be seen falling down and even some water vapor. These visualizations demonstrate that BriVL can accurately understand and imagine mountain modifiers.

Figure 5: BriVL model’s imagination of “mountains with…”.
Text generation diagram
Neural network visualization is very straightforward, but sometimes difficult to interpret. So we developed an alternative visualization/interpretability approach so that the imagined content of BriVL can be better understood by us humans. Specifically, we leverage VQGAN to generate images under the guidance of BriVL because VQGAN, pretrained on the ImageNet dataset, is very good at generating realistic images. We first randomly obtain a token sequence and obtain a generated image from a pre-trained VQGAN. Next, we feed the generated image into BriVL’s image encoder, and a piece of text into the text encoder. Finally, we define the target of matching between image and text embeddings and update the initial token sequence via backpropagation. As with neural network visualizations, both VQGAN and BriVL are frozen during the generation process. For comparison, we also show images generated by OpenAI’s CLIP model instead of BriVL.
We first selected four text inputs and showed the text generation graph results of CLIP and our BriVL in Figure 6 and Figure 7 respectively. Both CLIP and BriVL understand text well, however we also observe two major differences. First, cartoon-style elements will appear in the images generated by CLIP, while the images generated by BriVL are more realistic and natural. Second, CLIP tends to simply place elements together, whereas BriVL produces images that are more globally unified. The first difference may be due to the different training data used by CLIP and BriVL. The images in our training data are scraped from the Internet (mostly real photos), while there may be a certain number of cartoon images in CLIP's training data. The second difference may be due to the fact that CLIP uses image-text pairs with strong semantic correlation (through word filtering), while we use weakly correlated data. This means that during multi-modal pre-training, CLIP is more likely to learn correspondences between specific objects and words/phrases, while BriVL attempts to understand each image with the given text as a whole.

Figure 6: CLIP (w/ ResNet-50x4) uses VQGAN to realize text generation graph example .


# Figure 7: Our BriVL An example of VQGAN implementation to generate graphs.
We also considered a more challenging task of generating a sequence of images based on multiple consecutive sentences. As shown in Figure 8, although each image is generated independently, we can see that the four images are visually coherent and have the same style. This demonstrates another advantage of the BriVL model: although the environment and background in images are difficult to explicitly mention in the relevant text, they are not ignored in our large-scale multi-modal pre-training.

Figure 8: An example of our BriVL using VQGAN to generate a series of coherent content.
In Figure 9, we have chosen some concepts/scenarios that humans rarely see (such as "burning sea" and "glowing forest"), even those that do not exist in real life Concepts/scenarios (e.g. "cyberpunk city" and "castle in the clouds"). This proves that the superior performance of BriVL does not come from overfitting to the pre-training data, because the concepts/scenarios input here do not even exist in real life (of course, it is most likely not in the pre-training data set). Furthermore, these generated examples reaffirm the advantage of pre-training BriVL on weakly semantically related data (as fine-grained regional word alignment would impair BriVL's imagination ability).

Figure 9: More BriVL text generation graph results, the concepts/scenarios are It’s something that humans don’t often see or even doesn’t exist in real life.
In addition, we have also applied BriVL to multiple downstream tasks such as remote sensing image zero-sample classification, Chinese news zero-sample classification, visual question and answer, etc., and have achieved some interesting results. Please see the original text of our paper for details.
Conclusion and Discussion
We developed a large-scale multi-modal basic model called BriVL, which operates on 650 million weakly semantically related images and texts. training. We intuitively demonstrate the aligned image-text embedding space through neural network visualization and text-generated graphs. In addition, experiments on other downstream tasks also show BriVL’s cross-domain learning/transfer capabilities and the advantages of multi-modal learning over single-modal learning. In particular, we found that BriVL appears to have acquired some ability to imagine and reason. We believe these advantages mainly come from the weak semantic correlation assumption followed by BriVL. That is, by mining complex human emotions and thoughts in weakly correlated image-text pairs, our BriVL becomes more cognitive.
We believe that this step we take towards general artificial intelligence will have a broad impact not only on the field of artificial intelligence itself, but also on all fields of AI. For artificial intelligence research, based on our GPU resource-saving multi-modal pre-training framework, researchers can easily extend BriVL to larger magnitudes and more modalities to obtain a more general base model. With the help of large-scale multi-modal base models, it is also easier for researchers to explore new tasks (especially those without sufficient human annotation samples). For the field of AI, basic models can quickly adapt to specific working environments due to their strong generalization capabilities. For example, in the field of health care, multimodal basic models can make full use of multimodal data of cases to improve the accuracy of diagnosis; in the field of neuroscience, multimodal basic models may even help find out how multimodal information works in Mechanisms of fusion in the human brain, as artificial neural networks are easier to study than real neural systems in the human brain.
Despite this, multimodal basic models still face some risks and challenges. The base model may learn biases and stereotypes about certain things, and these issues should be carefully addressed before model training and monitored and addressed in downstream applications. In addition, as the basic model acquires more and more capabilities, we must be careful that it is abused by people with evil intentions to avoid having a negative impact on society. In addition, there are also some challenges in future research on the basic model: how to develop deeper model interpretability tools, how to build pre-training data sets with more modalities, and how to use more effective fine-tuning techniques to transform the basic model. Applied to various downstream tasks.
The authors of this paper are: Fei Nanyi, Lu Zhiwu, Gao Yizhao, Yang Guoxing, Huo Yuqi, Wen Jingyuan, Lu Haoyu, Song Ruihua, Gao Xin, Xiang Tao, Sun Hao, Wen Jirong ; The co-corresponding authors are Professor Lu Zhiwu, Permanent Associate Professor Sun Hao, and Professor Wen Jirong from the Hillhouse School of Artificial Intelligence, Renmin University of China. The paper was published in the international comprehensive journal "Nature Communications" (English name: Nature Communications, abbreviated as Nat Commun). This paper was interpreted by Fei Nanyi.
The above is the detailed content of The Nature sub-journal of Renmin University's Hillhouse School of Artificial Intelligence attempts to use multi-modal basic models to move towards general artificial intelligence. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology