
Home >Technology peripherals >AI >Introducing eight free and open source large model solutions because ChatGPT and Bard are too expensive.
Introducing eight free and open source large model solutions because ChatGPT and Bard are too expensive.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-08 22:13:074149browse
1.LLaMA
The LLaMA project contains a set of basic language models, ranging in size from 7 billion to 65 billion parameters. These models are trained on millions of tokens, and it is trained entirely on publicly available datasets. As a result, LLaMA-13B surpassed GPT-3 (175B), while LLaMA-65B performed similarly to the best models such as Chinchilla-70B and PaLM-540B.
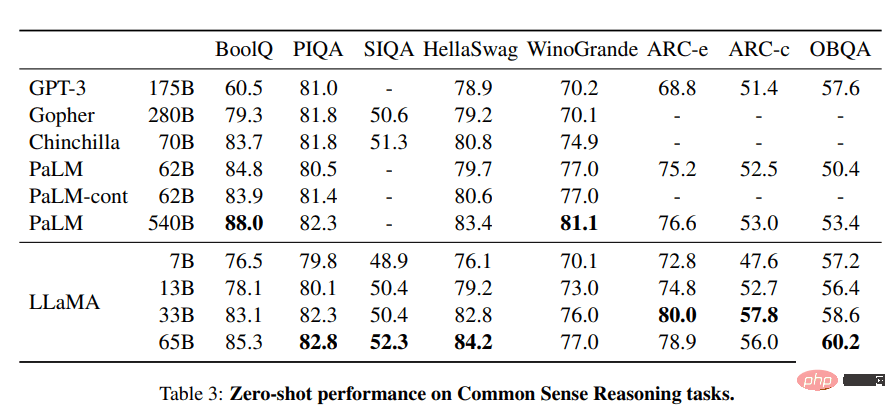
Image from LLaMA
Source:
- Research paper: “LLaMA: Open and Efficient Foundation Language Models (arxiv. org)" [https://arxiv.org/abs/2302.13971]
- GitHub: facebookresearch/llama [https://github.com/facebookresearch/llama]
- Demo: Baize Lora 7B [https://huggingface.co/spaces/project-baize/Baize-7B]
2.Alpaca
Stanford's Alpaca claims it can compete with ChatGPT and anyone can copy it for less than $600. Alpaca 7B is fine-tuned from the LLaMA 7B model on a 52K instruction follow demonstration.
Training content | Pictures from Stanford University CRFM
Resources:
- Blog: Stanford University CRFM. [https://crfm.stanford.edu/2023/03/13/alpaca.html]
- GitHub:tatsu-lab/stanford_alpaca [https://github.com/tatsu-lab/stanford_alpaca]
- Demo: Alpaca-LoRA (the official demo has been lost, this is a rendition of the Alpaca model) [https://huggingface.co/spaces/tloen/alpaca-lora]
3.Vicuna
Vicuna is fine-tuned based on the LLaMA model on user shared conversations collected from ShareGPT. The Vicuna-13B model has reached more than 90% of the quality of OpenAI ChatGPT and Google Bard. It also outperformed the LLaMA and Stanford Alpaca models 90% of the time. The cost to train a Vicuna is approximately $300.
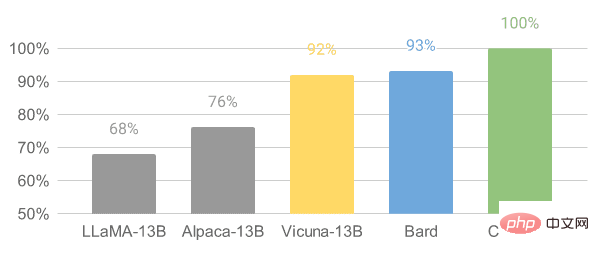
Image from Vicuna
Source:
- Blog post: “Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality” [https://vicuna.lmsys.org/]
- GitHub: lm-sys/FastChat [https://github.com/lm-sys/FastChat#fine-tuning ]
- Demo: FastChat (lmsys.org) [https://chat.lmsys.org/]
4.OpenChatKit
OpenChatKit: An open source alternative to ChatGPT, a complete toolkit for creating chatbots. It provides large language models for training users' own instruction adjustments, fine-tuned models, a scalable retrieval system for updating bot responses, and instructions for filtering bot review of questions.
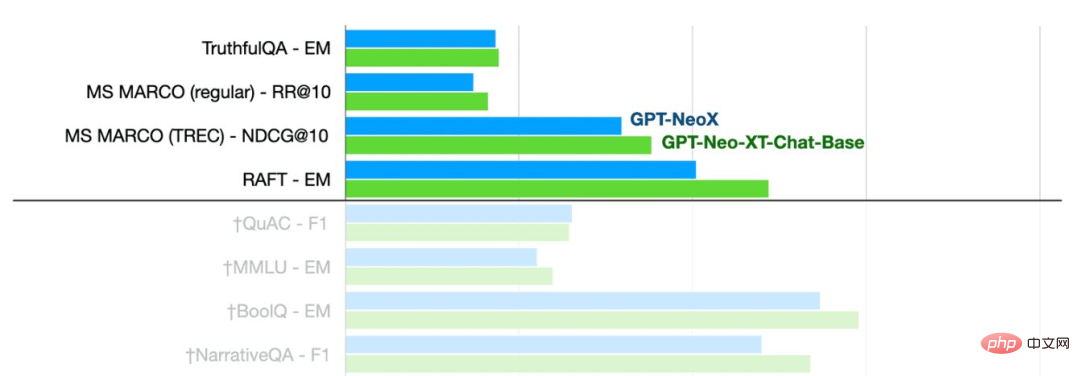
Pictures from TOGETHER
It can be seen that the GPT-NeoXT-Chat-Base-20B model performs better than Basic mode GPT-NoeX.
Resources:
- Blog post: "Announcing OpenChatKit" —TOGETHER [https://www.together.xyz/blog/openchatkit]
- GitHub: togethercomputer /OpenChatKit [https://github.com/togethercomputer/OpenChatKit]
- Demo: OpenChatKit [https://huggingface.co/spaces/togethercomputer/OpenChatKit]
- Model Card: togethercomputer/ GPT-NeoXT-Chat-Base-20B [https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B]
##5.GPT4ALL
GPT4ALL is a community-driven project and is trained on a large-scale corpus of auxiliary interactions, including code, stories, descriptions, and multiple rounds of dialogue. The team provided the dataset, model weights, data management process, and training code to facilitate open source. Additionally, they released a quantized 4-bit version of the model that can be run on a laptop. You can even use a Python client to run model inference.
- Technical Report: GPT4All [https://s3.amazonaws.com/static.nomic.ai/gpt4all/2023_GPT4All_Technical_Report.pdf]
- GitHub: nomic-ai/gpt4al [https:/ /github.com/nomic-ai/gpt4all]
- Demo: GPT4All (unofficial). [https://huggingface.co/spaces/rishiraj/GPT4All]
- Model card: nomic-ai/gpt4all-lora · Hugging Face [https://huggingface.co/nomic-ai/gpt4all-lora ]
6.Raven RWKV
Raven RWKV 7B is an open source chat robot that is driven by the RWKV language model and generates The results are similar to ChatGPT. This model uses RNN, which can match the transformer in terms of quality and scalability, while being faster and saving VRAM. Raven is fine-tuned on Stanford Alpaca, code-alpaca, and more datasets.
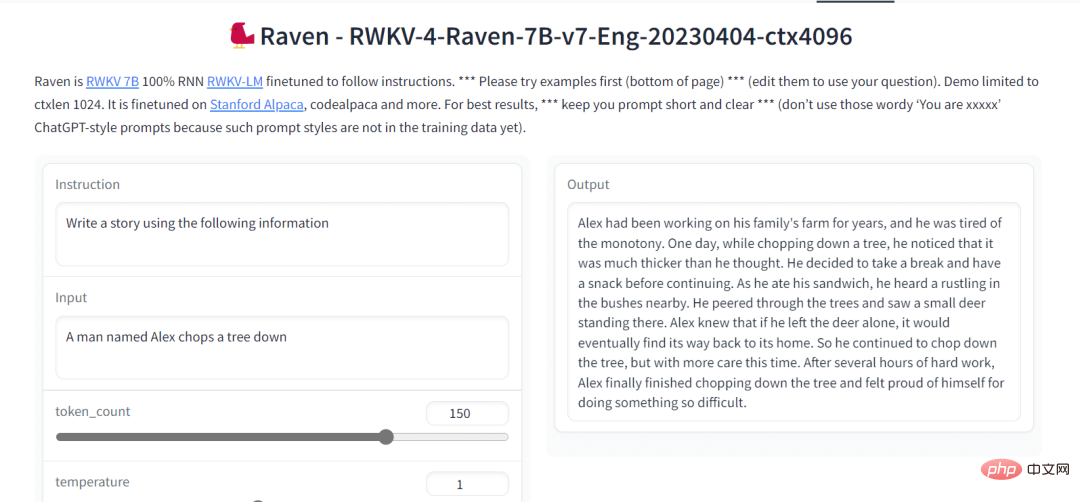
Image from Raven RWKV 7B
Source:
- GitHub: BlinkDL/ChatRWKV [https://github.com /BlinkDL/ChatRWKV]
- Demo: Raven RWKV 7B [https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B]
- Model Card: BlinkDL/rwkv-4- raven [https://huggingface.co/BlinkDL/rwkv-4-raven]
7.OPT
OPT: The Open Pre-trained Transformer language model is not as powerful as ChatGPT, but it shows excellent capabilities in zero-shot and few-shot learning and stereotype bias analysis. It can also be integrated with Alpa, Colossal-AI, CTranslate2 and FasterTransformer for better results. NOTE: The reason it makes the list is its popularity, as it has 624,710 downloads per month in the text generation category.
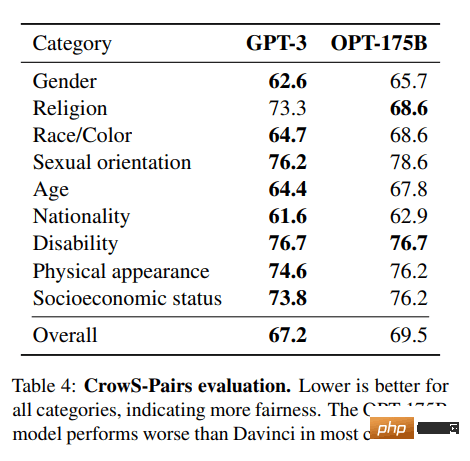
Image from (arxiv.org)
Source:
- Research paper: "OPT: Open Pre-trained Transformer Language Models (arxiv.org)” [https://arxiv.org/abs/2205.01068]
- GitHub: facebookresearch/metaseq [https://github.com/facebookresearch/metaseq]
- Demo: A Watermark for LLMs [https://huggingface.co/spaces/tomg-group-umd/lm-watermarking]
- Model card: facebook/opt-1.3b [https://huggingface. co/facebook/opt-1.3b]
##8.Flan-T5-XXL
Flan-T5-XXL The T5 model is fine-tuned on the data set expressed in the form of instructions. Fine-tuning of the instructions greatly improved the performance of various model classes, such as PaLM, T5 and U-PaLM. The Flan-T5-XXL model is fine-tuned on more than 1000 additional tasks, covering more languages.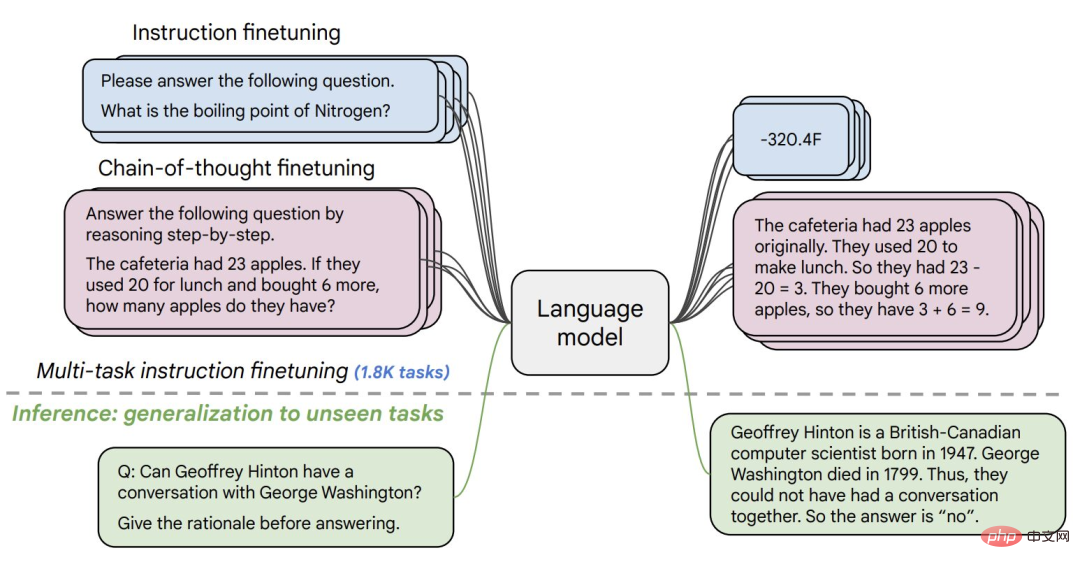
- Research paper: “Scaling Instruction-Fine Tuned Language Models ” [https://arxiv.org/pdf/2210.11416.pdf]
- GitHub: google-research/t5x [https://github.com/google-research/t5x]
- Demo: Chat Llm Streaming [https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming]
- Model card: google/flan-t5-xxl [https://huggingface.co/google /flan-t5-xxl?text=Q: ( False or not False or False ) is? A: Let's think step by step]
##SummaryThere are many open source large models to choose from. This article involves 8 of the more popular large models.
The above is the detailed content of Introducing eight free and open source large model solutions because ChatGPT and Bard are too expensive.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology