
Home >Technology peripherals >AI >UC Berkeley releases ranking of large language models! Vicuna won the championship and Tsinghua ChatGLM ranked among the top 5
UC Berkeley releases ranking of large language models! Vicuna won the championship and Tsinghua ChatGLM ranked among the top 5

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-05-04 23:04:091770browse
Recently, researchers from LMSYS Org (led by UC Berkeley) have made another big news - the large language model version ranking competition!
As the name suggests, "LLM Ranking" is to let a group of large language models randomly conduct battles and rank them according to their Elo scores.
Then, we can tell at a glance whether a certain chat robot is the "King of Strong Mouth" or the "Strongest King".
Key point: The team also plans to bring in all these "closed source" models from domestic and foreign countries. You will know whether it is a mule or a horse! (GPT-3.5 is already in the anonymous arena now)

The anonymous chatbot arena looks like this:
Obviously, Model B answered correctly and won the game; while Model A didn’t even understand the question...
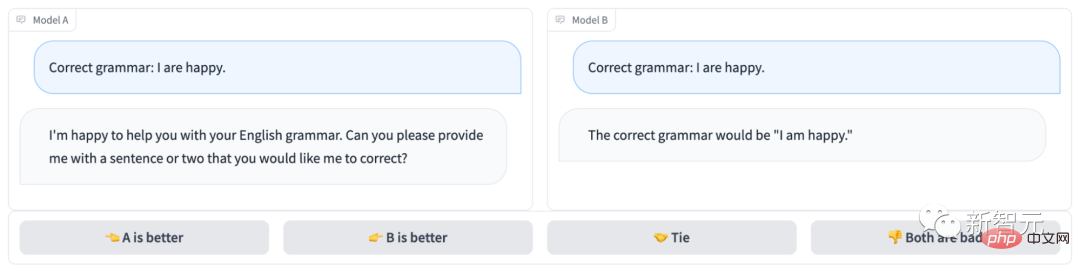
Project address: https://arena.lmsys.org/
In the current rankings , Vicuna with 13 billion parameters ranked first with 1169 points, Koala with 13 billion parameters ranked second, and LAION's Open Assistant ranked third.
ChatGLM proposed by Tsinghua University, although it only has 6 billion parameters, still broke into the top five, only 23 points behind Alpaca with 13 billion parameters.
In comparison, Meta’s original LLaMa only ranked eighth (second to last), while Stability AI’s StableLM scored the only 800 points, ranking first from last.
The team stated that it will not only update the ranking list regularly, but also optimize the algorithm and mechanism, and provide more detailed rankings based on different task types.

Currently, all evaluation codes and data analysis have been published.
Pulling LLM to rank
In this evaluation, the team selected 9 currently well-known open source chat robots.
Every time there is a 1v1 battle, the system will randomly pull two PK players. Users need to chat with both robots at the same time and then decide which chatbot is better.
As you can see, there are 4 options at the bottom of the page, the left (A) is better, the right (B) is better, equally good, or both are bad.
After the user submits a vote, the system will display the name of the model. At this time, the user can continue chatting, or select a new model to restart a round of battle.
However, when analyzing, the team will only use the voting results when the model is anonymous. After almost a week of data collection, the team collected a total of 4.7k valid anonymous votes.
Before starting, the team first grasped the possible ranking of each model based on the results of the benchmark test.
Based on this ranking, the team will let the model give priority to more suitable opponents.
Then, uniform sampling is used to obtain better overall coverage of the rankings.
At the end of qualifying, the team introduced a new model fastchat-t5-3b.
The above operations eventually lead to non-uniform model frequencies.
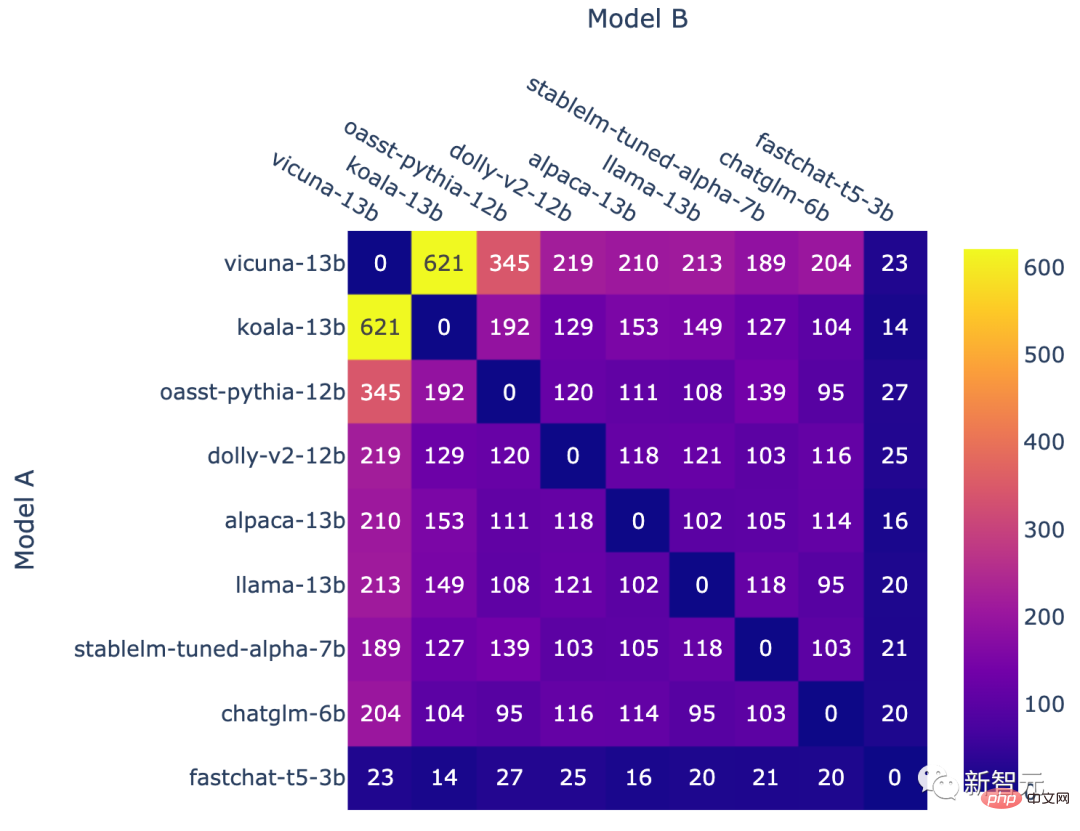
Number of battles for each model combination
From the statistical data, most users use English, with Chinese ranking second.
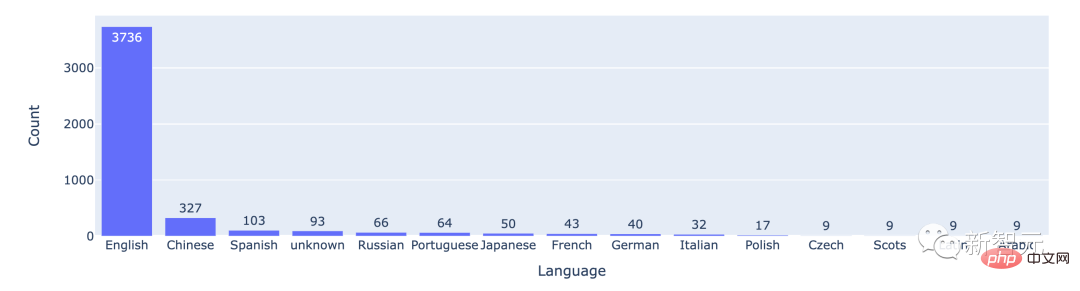
The number of battles in the top 15 languages
It’s really important to evaluate LLM Difficult
Since the popularity of ChatGPT, open source large language models that have been fine-tuned according to instructions have sprung up like mushrooms after a rain. It can be said that new open source LLMs are released almost every week.
But the problem is that it is very difficult to evaluate these large language models.
Specifically, the things currently used to measure the quality of a model are basically based on some academic benchmarks, such as building a test data set on a certain NLP task, and then Look at the accuracy on the test data set.
However, these academic benchmarks (such as HELM) are not easy to use on large models and chatbots. The reasons are:
1. Since judging whether a chatbot is good at chatting is very subjective, it is difficult to measure it with existing methods.
2. These large models scan almost all the data on the Internet during training, so it is difficult to ensure that the test data set has not been seen. Even going a step further, using the test set to directly "specially train" the model will result in better performance.
3. In theory, we can chat with the chatbot about anything, but many topics or tasks simply do not exist in existing benchmarks.
If you don’t want to use these benchmarks, there is actually another way to go - pay someone to do it Model scoring.
In fact, this is what OpenAI does. But this method is obviously very slow, and more importantly, too expensive...
In order to solve this thorny problem, teams from UC Berkeley, UCSD, and CMU invented a A new mechanism that is both fun and practical - Chatbot Arena.
In comparison, the battle-based baseline system has the following advantages:
- Scalability
When sufficient data cannot be collected for all potential model pairs, the system should be able to scale to as many models as possible.
- Incrementality
The system should be able to evaluate new models using a relatively small number of trials.
- Unique order
The system should provide a unique order for all models. Given any two models, we should be able to tell which one ranks higher or if they are tied.
Elo rating system
The Elo rating system is a method of calculating the relative skill level of players and is widely used in competitive games and various sports. among. Among them, the higher the Elo score, the more powerful the player is.
For example, in League of Legends, Dota 2, Chicken Fighting, etc., this is the mechanism by which the system ranks players.
For example, when you play many ranked games in League of Legends, a hidden score will appear. This hidden score not only determines your rank, but also determines that the opponents you encounter when playing ranked are basically of a similar level.
Moreover, the value of this Elo score is absolute. In other words, when new chatbots are added in the future, we can still directly judge which chatbot is more powerful through Elo's score.
Specifically, if player A's rating is Ra and player B's rating is Rb, the exact formula for player A's winning probability (using a base 10 logistic curve) is:

Then, the player's rating will be updated linearly after each game.
Suppose Player A (rated Ra) expected to get Ea points, but actually got Sa points. The formula for updating this player's rating is:
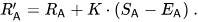
In addition, the author also shows the ranking The head-to-head win rate of each model in the rankings and the predicted head-to-head win rate estimated using the Elo score.
The results show that the Elo score can indeed be predicted relatively accurately
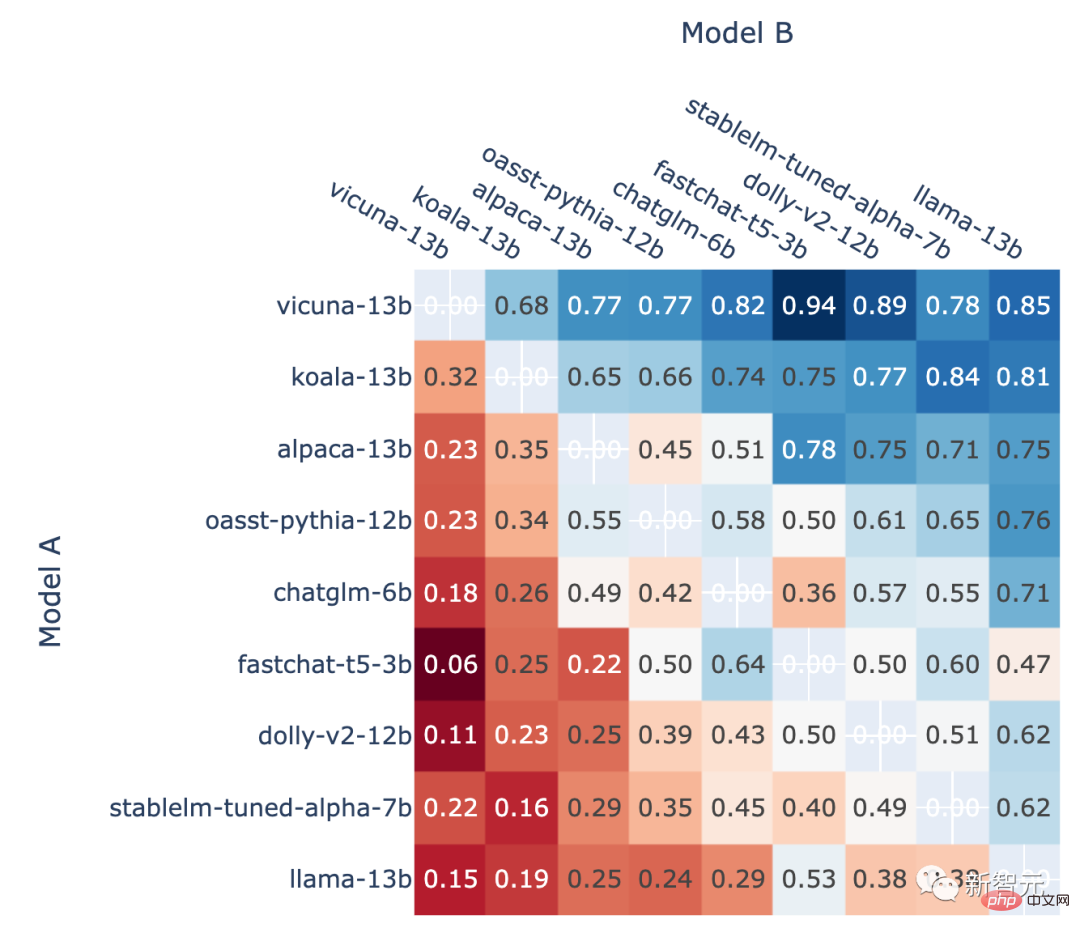
All non- Proportion of Model A winning in a draw A versus B battle
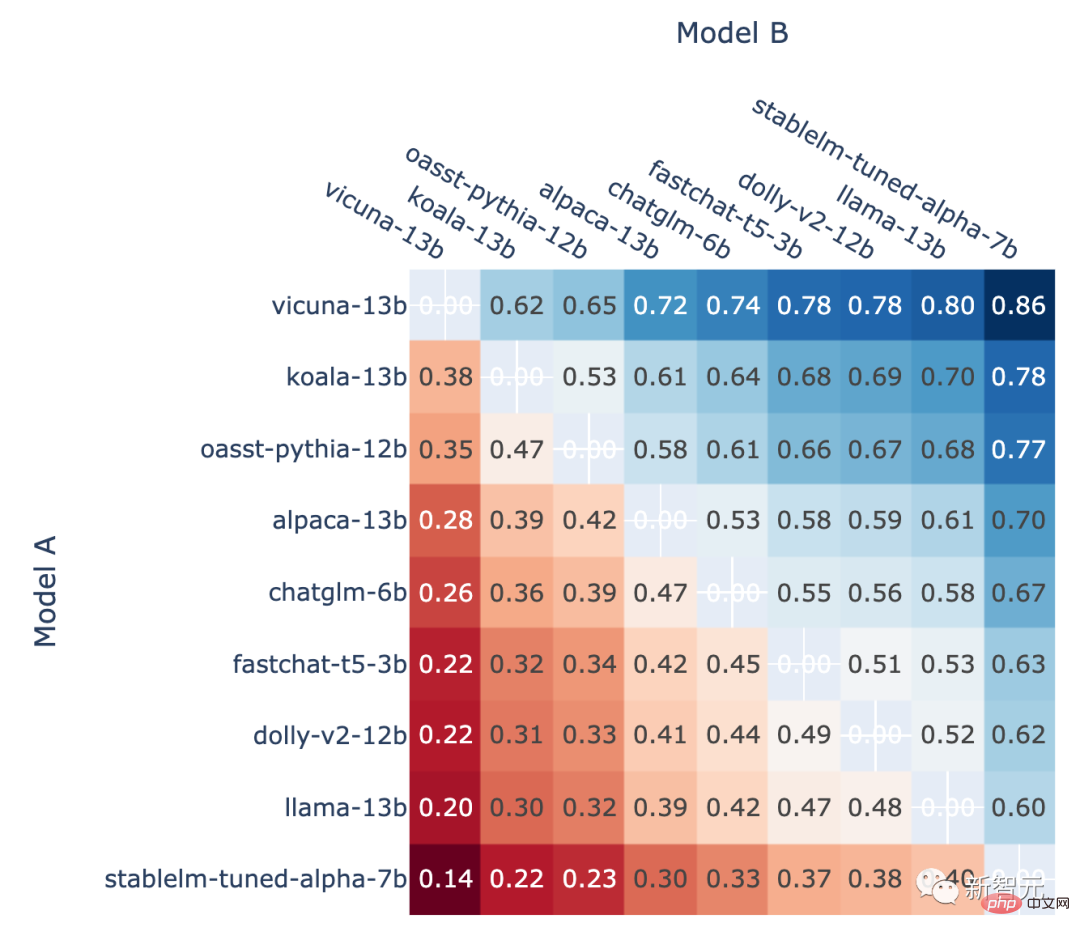
##In an A versus B battle , the winning rate of model A predicted using the Elo score Author introduction
"Chatbot Arena" is released by the former Little Alpaca author organization LMSYS Org.The institution was founded by UC Berkeley Ph.D. Lianmin Zheng and UCSD associate professor Hao Zhang, with the goal of making it accessible to everyone by jointly developing open data sets, models, systems and evaluation tools. Get large models.
Lianmin Zheng is a professor in the Department of EECS, University of California, Berkeley PhD student, his research interests include machine learning systems, compilers, and distributed systems.
Hao Zhang
Hao Zhang is currently a postdoctoral researcher at the University of California, Berkeley. He will serve as an assistant professor at the UC San Diego Halıcıoğlu Data Science Institute and Department of Computer Science starting in fall 2023.
The above is the detailed content of UC Berkeley releases ranking of large language models! Vicuna won the championship and Tsinghua ChatGLM ranked among the top 5. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology