

 Technology peripheralsAIGMMSeg, a new paradigm of generative semantic segmentation, can handle both closed set and open set recognition
Technology peripheralsAIGMMSeg, a new paradigm of generative semantic segmentation, can handle both closed set and open set recognitionGMMSeg, a new paradigm of generative semantic segmentation, can handle both closed set and open set recognition

The current mainstream semantic segmentation algorithm is essentially a discriminative classification model based on the softmax classifier, which directly models p (class|pixel feature) and completely ignores the underlying pixel data distribution, that is, p ( class|pixel feature). This limits the model's expressiveness and generalization on OOD (out-of-distribution) data.
In a recent study, researchers from Zhejiang University, University of Technology Sydney, and Baidu Research Institute proposed a new semantic segmentation paradigm - based on Gaussian mixture model (GMM) generative semantic segmentation model GMMSeg.

- ## Paper link: https://arxiv.org/abs/2210.02025
- Code link: https://github.com/leonnnop/GMMSeg
GMMSeg performs the joint distribution of pixels and categories Modeling uses the EM algorithm to learn a Gaussian mixture classifier (GMM Classifier) in the pixel feature space, and uses a generative paradigm to finely capture the pixel feature distribution of each category. Meanwhile, GMMSeg adopts discriminative loss to optimize deep feature extractors end-to-end. This gives GMMSeg the advantages of both discriminative and generative models.
Experimental results show that GMMSeg has achieved performance improvements on a variety of segmentation architectures and backbone networks; at the same time, without any post-processing or fine-tuning, GMMSeg can be directly applied to anomaly segmentation tasks.
To date, this is the first time that a semantic segmentation method can use a single model instance, In closed-set (closed-set) and open Achieve advanced performance simultaneously under open-world conditions. This is also the first time that generative classifiers have demonstrated advantages in large-scale vision tasks.
Discriminative vs. Generative Classifier
Before delving into the existing segmentation paradigms and proposed methods, a brief introduction is given here. The concepts of discriminative and generative classifiers.
Suppose there is a data set D, which contains pairs of samples-label pairs (x, y); the ultimate goal of the classifier is to predict the sample classification probability p ( y|x). Classification methods can be divided into two categories: discriminative classifiers and generative classifiers.
- Discriminant classifier: directly models the conditional probability p (y|x); it only learns the optimal decision boundary for classification, but does not Considering the distribution of the sample itself, it cannot reflect the characteristics of the sample.
- Generative classifier: first model the joint probability distribution p (x, y), and then derive the classification conditional probability through Bayes’ theorem; its explicit To model the distribution of the data itself, a corresponding model is often established for each category. Compared with the discriminative classifier, it fully considers the characteristic information of the sample.

Most of the current mainstream pixel-by-pixel segmentation models use depth The network extracts pixel features, and then uses the softmax classifier to classify the pixel features. Its network architecture consists of two parts:
The first part is the pixel feature extractor, and its typical architecture is an encoder-decoder pair , pixel features are obtained by mapping the pixel input of the RGB space to the D-dimensional high-dimensional space.
The second part is the pixel classifier, which is the mainstream softmax classifier; it encodes the input pixel features into C-class Real number output (logits), and then use the softmax function to normalize the output (logits) and assign probability meaning, that is, use logits to calculate the posterior probability of pixel classification:

Ultimately, the complete model consisting of two parts will be optimized end-to-end with cross-entropy loss:

Here In the process, the model ignores the distribution of the pixels themselves and directly estimates the conditional probability p (c|x) of the pixel classification prediction. It can be seen that the mainstream softmax classifier is essentially a discriminative classifier.
The discriminant classifier has a simple structure, and because its optimization goal is directly aimed at reducing the discrimination error, it can often achieve excellent discriminant performance. However, at the same time, it has some fatal shortcomings that have not attracted the attention of existing work, which greatly affects the classification performance and generalization of the softmax classifier:
- First of all , which only models the decision boundary; completely ignores the distribution of pixel features, and therefore cannot model and utilize the specific characteristics of each category; weakening its generalization and expression capabilities.
- Secondly, it uses a single parameter pair (w,b) to model a class; in other words, the softmax classifier relies on the unimodality assumption ; This extremely strong and oversimplified assumption often fails to hold in practical applications, which results in only sub-optimal performance.
- Finally, the output of the softmax classifier cannot accurately reflect the true probabilistic meaning; its final prediction can only be used as a reference when comparing with other categories. This is also the fundamental reason why it is difficult for a large number of mainstream segmentation models to detect OOD input.
In response to these problems, the author believes that the current mainstream discriminative paradigm should be rethought, and the corresponding solution is given in this article: Generative semantic segmentation model— —GMMSeg.
Generative semantic segmentation model: GMMSeg
The author reorganized the semantic segmentation process from the perspective of a generative model. Compared with directly modeling the classification probability p (c|x), the generative classifier models the joint distribution p (x, c), and then derives it using Bayes’ theorem Classification probability:

Among them, for generalization considerations, the category prior p (c) is often set to a uniform distribution, and how to Modeling the category conditional distribution p (x|c) of pixel features has become the primary issue at present.
In this paper, namely GMMSeg, a Gaussian mixture model is used to model p (x|c), which has the following form:

When the number of components is not limited, the Gaussian mixture model can theoretically fit any distribution, so it is very elegant and powerful; at the same time, it The nature of hybrid models also makes it feasible to model multimodality, that is, to model intra-class variation. Based on this, this article uses maximum likelihood estimation to optimize the parameters of the model:

The classic solution is the EM algorithm, that is, by alternately executing E-M - Two-step stepwise optimization of F - function:

Specific to the optimization of Gaussian mixture models; the EM algorithm actually re-estimates the probability that the data points belong to each sub-model in the E-step. In other words, it is equivalent to soft clustering of pixels in the E-step; then, in the M-step, the clustering results can be used to update the model parameters again.

However, in practical applications, the author found that the standard EM algorithm converged slowly and the final results were poor. The author suspects that the EM algorithm is too sensitive to the initial values of parameter optimization, making it difficult to converge to a better local extreme point. Inspired by a series of recent clustering algorithms based on optimal transport theory, the author introduces an additional uniform prior to the mixture model distribution:

Correspondingly, the E-step in the parameter optimization process is transformed into a constrained optimization problem, as follows:

This process can be Intuitively understood, an equal distribution constraint is introduced to the clustering process: during the clustering process, data points can be evenly distributed to each sub-model to a certain extent. After introducing this constraint, this optimization process is equivalent to the optimal transmission problem listed in the following formula:

This formula can use Sinkhorn-Knopp The algorithm solves quickly. The entire improved optimization process is named Sinkhorn EM, which has been proven by some theoretical work to have the same global optimal solution as the standard EM algorithm, and is less likely to fall into the local optimal solution.
Online Hybrid optimization
After that, in the complete optimization process, the article uses an online hybrid optimization mode: Through the generative Sinkhorn EM, the Gaussian mixture classifier is continuously optimized in the gradually updated feature space; while for another part of the complete framework, that is, the pixel feature extractor part, based on the prediction results of the generative classifier, use Optimize with discriminative cross-entropy loss. The two parts are optimized alternately and aligned with each other, making the entire model tightly coupled and capable of end-to-end training:

In this process, the features The extraction part is only optimized through gradient backpropagation; while the generative classifier part is only optimized through SinkhornEM. It is this alternating optimization design that allows the entire model to be compactly integrated and inherit the advantages from the discriminative and generative models.

Ultimately, GMMSeg benefits from its generative classification architecture and online hybrid training strategy, demonstrating features that the discriminative softmax classifier does not have The advantages:
- First, benefiting from its universal architecture, GMMSeg is compatible with most mainstream segmentation models, that is, compatible with models that use softmax for classification: you only need to replace the discriminative softmax classifier. Painlessly enhance the performance of existing models.
- Secondly, due to the application of hybrid training mode, GMMSeg combines the advantages of generative and discriminative classifiers, and to a certain extent solves the problem that softmax cannot model intra-class changes. ; greatly improves its discriminative performance.
- Third, GMMSeg explicitly models the distribution of pixel features, that is, p (x|c); GMMSeg can directly give the probability that the sample belongs to each category , which enables it to naturally handle unseen OOD data.
Experimental results
The experimental results show that whether it is based on CNN architecture or Transformer architecture, it can achieve better results in widely used semantic segmentation data sets (ADE20K, Cityscapes , COCO-Stuff), GMMSeg can achieve stable and obvious performance improvements.


In addition, in the abnormal segmentation task, there is no need to perform the closed set task, that is, the regular If any modification is made to the trained model in the semantic segmentation task, GMMSeg can surpass other methods that require special post-processing in all common evaluation indicators.



The above is the detailed content of GMMSeg, a new paradigm of generative semantic segmentation, can handle both closed set and open set recognition. For more information, please follow other related articles on the PHP Chinese website!

 Can SmolDocling Make Document Parsing More Efficient?Apr 23, 2025 am 09:41 AM
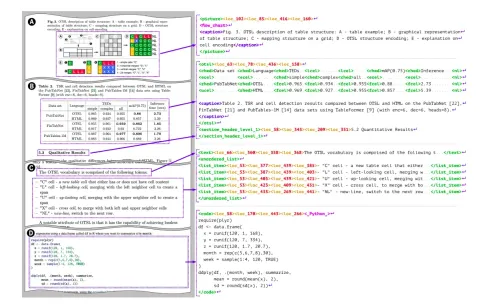
Can SmolDocling Make Document Parsing More Efficient?Apr 23, 2025 am 09:41 AMSmolDocling: A Lightweight Vision-Language Model for High-Precision Document Conversion Digital documents present a significant challenge: accurately converting their rich structure into machine-readable formats. Existing solutions, whether complex
 Can AI Cure Loneliness - or Make It Worse?Apr 23, 2025 am 09:37 AM
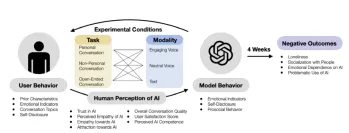
Can AI Cure Loneliness - or Make It Worse?Apr 23, 2025 am 09:37 AMThis MIT and OpenAI study explores how interacting with AI chatbots impacts users' emotions and social lives. Over four weeks, 981 adults engaged with a modified version of GPT-4, experiencing different interaction styles (text, neutral voice, engag
 Top 7 AI Image Generators to Try in 2025Apr 23, 2025 am 09:27 AM
Top 7 AI Image Generators to Try in 2025Apr 23, 2025 am 09:27 AMAI image generation technology has made great progress in 2025, from initially blurred abstract images to today's realistic photos and stunning works of art, it can do everything. This article will explore the most powerful and creative image generation models on the market today, which perform well in photoreality, creative diversity, moral implementation, and the application of various in-progress works. Digital artists, marketers, content creators, and curious people interested in these tools and their benefits are increasingly important in the digital ecosystem based on images. Table of contents Best AI Image Generators of 2025 Midjourney DALL-E 3 (OpenAI) Flux AI Stable Diffusion I
 What Are Views in SQL?Apr 23, 2025 am 09:26 AM
What Are Views in SQL?Apr 23, 2025 am 09:26 AMIntroduction SQL, the Structured Query Language, is fundamental to managing and manipulating relational databases. A powerful SQL feature is the use of views, which streamline complex queries, boosting database efficiency and manageability. This ski
 How can Simpson's Paradox Uncover Hidden Trends in Data? - Analytics VidhyaApr 23, 2025 am 09:20 AM
How can Simpson's Paradox Uncover Hidden Trends in Data? - Analytics VidhyaApr 23, 2025 am 09:20 AMSimpson's Paradox: Unveiling Hidden Trends in Data Have you ever been misled by statistics? Simpson's Paradox demonstrates how aggregated data can obscure crucial trends, revealing the importance of analyzing data at multiple levels. This concise gui
 What is Nominal Data? - Analytics VidhyaApr 23, 2025 am 09:13 AM
What is Nominal Data? - Analytics VidhyaApr 23, 2025 am 09:13 AMIntroduction Nominal data forms the bedrock of data analysis, playing a crucial role in various fields like statistics, computer science, psychology, and marketing. This article delves into the characteristics, applications, and distinctions of nomi
 What is One-Shot Prompting? - Analytics VidhyaApr 23, 2025 am 09:12 AM
What is One-Shot Prompting? - Analytics VidhyaApr 23, 2025 am 09:12 AMIntroduction In the dynamic world of machine learning, efficiently generating precise responses using minimal data is paramount. One-shot prompting offers a powerful solution, enabling AI models to execute specific tasks using just a single example
 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 English version
Recommended: Win version, supports code prompts!

