
Home >Technology peripherals >AI >The secret of data-centered AI in the GPT model
The secret of data-centered AI in the GPT model

- 王林forward
- 2023-04-30 17:58:071586browse
Translator | Zhu Xianzhong
Reviewer| Chonglou
The image comes from the article https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363, produced by the author myself
Artificial intelligence is making incredible progress in changing the way we live, work, and interact with technology. Recently, an area that has made significant progress is the development of large language models (LLM), such as GPT-3, ChatGPT and GPT-4. These models are able to perform tasks such as language translation, text summarization, and question answering with impressive accuracy. While it’s hard to ignore the ever-increasing model sizes of large language models, it’s equally important to recognize that their success is largely due to the large number of high-performance machines used to train them. Quality data.
In this article, we will provide an overview of recent advances in large language models from a data-centric artificial intelligence perspective, referring to our recent survey paper (end The views in documents 1 and 2) and the corresponding
technical resources on GitHub. In particular, we will take a closer look at the GPT model through the lens of data-centric artificial intelligence, a growing trend in the data science community A point of view. We will reveal the data-centric artificial intelligence behind the GPT model by discussing three data-centric artificial intelligence goals - training data development, inference data development and data maintenance. Concept. Large Language Model vs. GPT ModelLLM (Large Language Model) is a natural language processing model that is trained to infer words in context. For example, the most basic function of LLM is to predict missing tokens given context. To do this, LLM is trained to predict the probability of each candidate token from massive amounts of data.
#Illustrative example of predicting the probability of missing tokens using a large language model with context (provided by the author himself Picture)

GPT model refers to a series of large-scale language models created by OpenAI, such as GPT-1, GPT-2、GPT-3、InstructGPT and ChatGPT/GPT-4. Like other large-scale language models, the architecture of the GPT model is heavily based on Transformers, which use text and positional embeddings as input and use attention layers to model relationships between tokens.
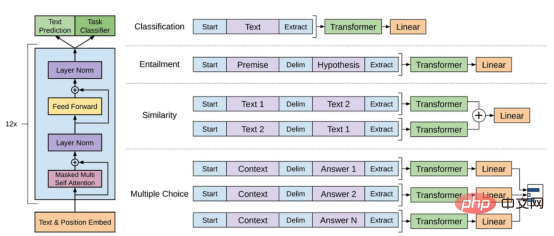
GPT-1 model architecture diagram, this image comes from the paper https://www.php.cn/link/c3bfbc2fc89bd1dd71ad5fc5ac96ae69
The later GPT model used a similar architecture to GPT-1, but used more model parameters, with more layers, larger context length, Hidden layer size, etc.

Comparison of various model sizes of the GPT model (picture provided by the author)
What is data-centric artificial intelligence?
Data-centric artificial intelligence is an emerging new way of thinking about how to build artificial intelligence systems. Artificial intelligence pioneer Andrew Ng has been championing this idea.
Data-centric artificial intelligence is the discipline of systematic engineering of the data used to build artificial intelligence systems.
——Andrew Ng
In the past, we mainly focused on creating better models (model-centric artificial intelligence) when the data is basically unchanged. However, this approach can cause problems in the real world because it does not take into account different issues that can arise in the data, such as inaccurate labels, duplications, and biases. Therefore, "overfitting" a data set may not necessarily lead to better model behavior.
In contrast, data-centric AI focuses on improving the quality and quantity of data used to build AI systems. This means that attention will be focused on the data itself, while the model is relatively more fixed. A data-centric approach to developing AI systems has greater potential in the real world because the data used for training ultimately determines the model’s maximum capabilities.
It is worth noting that "data-centric" is fundamentally different from "data-driven" because the latter only emphasizes the use of data to guide artificial intelligence development, while AI development often remains centered around developing models rather than engineering data.
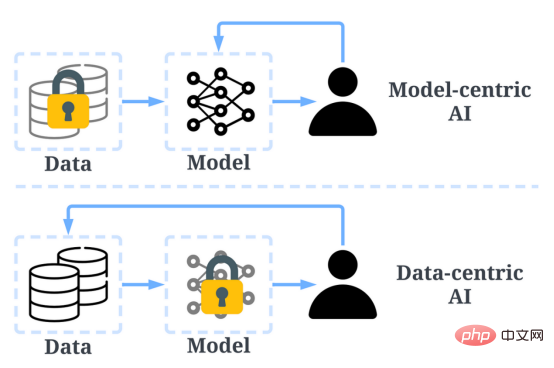
Comparison of data-centered artificial intelligence and model-centered AI (picture from https:/ /www.php.cn/link/f9afa97535cf7c8789a1c50a2cd83787Paper author)
Overall, the data-centered artificial intelligence framework consists of three goals:
- Training data development is the collection and generation of rich, high-quality data to support the training of machine learning models.
- Inference data development is used to create new evaluation sets that can provide more granular insights to the model or trigger the model through engineering data input. specific abilities.
- #Data maintenance is to ensure the quality and reliability of data in a dynamic environment. Data maintenance is critical because real-world data is not created once but requires ongoing maintenance.
Data-centered artificial intelligence framework (image from paperhttps://www.php.cn/link/ Author of f74412c3c1c8899f3c130bb30ed0e363)
Why does data-centric artificial intelligence make the GPT model so successful?
A few months ago, Yann LeCun, a leader in the artificial intelligence industry, stated on Twitter that ChatGPT is nothing new. In fact, all the techniques used in ChatGPT and GPT-4 (Ttransformer and reinforcement learning from human feedback, etc.) are not new technologies. However, they did achieve incredible results that previous models couldn't achieve. So what drives their success?
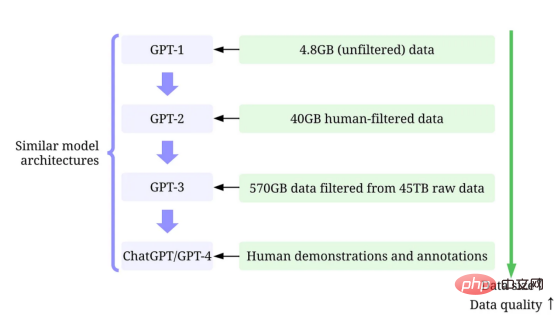
First, strengthen training data development. Through better data collection, data labeling, and data preparation strategies, the quantity and quality of data used to train GPT models has increased significantly.
- GPT-1: BooksCorpus dataset is used for training. The dataset contains 4629MB of raw text, covering books in a range of genres including adventure, fantasy, and romance.
- #Not using a data-centric AI strategy.
- Training results: Applying GPT-1 on this dataset can improve the performance of downstream tasks through fine-tuning.
- Adopts a data-centric artificial intelligence strategy: (1) Control/filter data using only outbound links from Reddit that receive at least to 3 results; (2) use the tools Dragnet and Newspaper to extract "clean" content; (3) adopt deduplication and some other heuristic-based purification methods (the details are not mentioned in the paper).
- #Training results: 40GB of text was obtained after purification. GPT-2 achieves robust zero-sample results without fine-tuning.
- A data-centric artificial intelligence strategy is used: (1) Train a classifier to filter out low-quality documents based on their similarity to WebText Documentation, WebText is a proxy for high-quality documents. (2) Use Spark’s MinHashLSH to perform fuzzy deduplication on documents. (3) Use WebText, book corpora, and Wikipedia to enhance data.
- Training results: 570GB of text was filtered from 45TB of plaintext (only 1.27% of the data was selected in this quality filtering). In the zero-sample setting, GPT-3 significantly outperforms GPT-2.
- uses a data-centric artificial intelligence strategy: (1) Use manually provided prompt answers to adjust the model through supervised training. (2) Collect comparative data to train a reward model, and then use the reward model to tune GPT-3 through reinforcement learning from human feedback (RLHF).
- Training results: InstructGPT shows better authenticity and less bias, that is, better consistency.
- GPT-2: Use WebText Come for training. This is an internal dataset within OpenAI created by scraping outbound links from Reddit.
- GPT-3: The training of GPT-3 is mainly based on the Common Crawl tool.
- InstructGPT: Let human evaluation adjust GPT-3 answers so that they better match human expectations. They designed tests for annotators, and only those who could pass the tests were eligible for annotation. Additionally, they even designed a survey to ensure that annotators enjoyed the annotation process.
- ChatGPT/GPT-4: OpenAI did not disclose details. But as we all know, ChatGPT/GPT-4 largely follows the design of previous GPT models, and they still use RLHF to tune the model (possibly with more and higher quality data/labels). It is generally believed that GPT-4 uses larger data sets as the model weights increase.
Secondly, develop inference data. Since recent GPT models have become powerful enough, we can achieve various goals by adjusting the hints (or adjusting the inference data) while fixing the model. For example, we can perform text summarization by providing the text of the summary along with instructions such as "summarize it" or "TL;DR" to guide the reasoning process.

Prompt fine-tuning, picture by Provided by the author
Designing the right inference prompts is a challenging task. It relies heavily on heuristic techniques. A good survey summarizes the different prompting methods people use so far. Sometimes, even semantically similar cues can have very different outputs. In this case, soft-cue-based calibration may be needed to reduce the discrepancy.
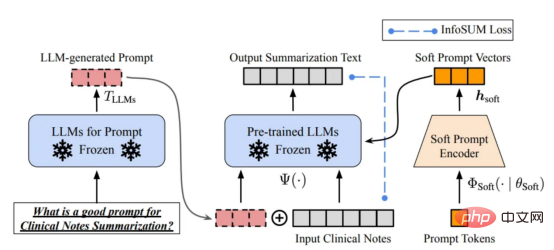
Soft prompt based calibration. This image comes from the paper https://arxiv.org/abs/2303.13035v1, with permission from the original author
Research on the development of large-scale language model inference data is still In early stages. In the near future, more inference data development techniques already used in other tasks may be applied to the field of large language models.
In terms of data maintenance, ChatGPT/GPT-4, as a commercial product, is not just a successful training once, but requires continuous training. Updates and maintenance. Obviously, we don't know how data maintenance is performed outside of OpenAI. Therefore, we discuss some general data-centric AI strategies that are likely to have been used or will be used in GPT models:
- Continuous Data Collection: When we use ChatGPT/GPT-4, our tips/feedback can in turn be used by OpenAI to further advance their models. Quality metrics and assurance strategies may have been designed and implemented to collect high-quality data during the process.
- Data Understanding Tools: It is possible that various tools have been developed to visualize and understand user data, promote a better understanding of user needs, and guide the future direction of improvement.
- Efficient data processing: With the rapid growth of the number of ChatGPT/GPT-4 users, an efficient data management system is needed to achieve rapid data collection. .
ChatGPT/GPT-4 system is able to collect user feedback through the two icon buttons of "thumbs up" and "thumbs down" as shown in the figure to further promote them system development. The screenshot here is from https://chat.openai.com/chat.
What can the data science community learn from this wave of large language models?
The success of large language models has revolutionized artificial intelligence. Going forward, large language models may further revolutionize the data science lifecycle. To this end, we make two predictions:
- Data-centric artificial intelligence becomes more important. After years of research, model design has become very mature, especially after Transformer. Engineering data becomes the key (or perhaps the only) way to improve AI systems in the future. Furthermore, when the model becomes powerful enough, we do not need to train the model in our daily work. Instead, we only need to design appropriate inference data (just-in-time engineering) to explore knowledge from the model. Therefore, research and development of data-centric AI will drive future progress.
- Large language models will enable better data-centric artificial intelligence solutions. Many tedious data science tasks can be performed more efficiently with the help of large language models. For example, ChaGPT/GPT-4 already makes it possible to write operational code to process and clean data. Additionally, large language models can even be used to create data for training. For example, recent work has shown that using large language models to generate synthetic data can improve model performance in clinical text mining.
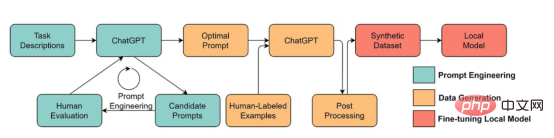
Use a large language model to generate synthetic data to train the model, the image here is from the paper https:/ /arxiv.org/abs/2303.04360, with permission from the original author
References
I hope this article can be used in your own Inspire you at work. You can learn more about data-centric AI frameworks and how they can benefit large language models in the following papers:
[1]A review of data-centered artificial intelligence.
[2]The prospects and challenges of data-centered artificial intelligence.
Note that we also maintain a GitHub code repository, which will be updated regularly of data-centric artificial intelligence resources.
In future articles, I will delve into the three goals of data-centric artificial intelligence (training data development, inference data development, and data maintenance) and introduce representative sexual method.
Translator introduction
Zhu Xianzhong, 51CTO community editor, 51CTO expert blogger, lecturer, computer teacher at a university in Weifang, freelance programming community A veteran.
Original title: What Are the Data-Centric AI Concepts behind GPT Models?, Author: Henry Lai
The above is the detailed content of The secret of data-centered AI in the GPT model. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology