



In recent years, data closed-loop has become a hot topic in the autonomous driving industry, and many autonomous driving companies are trying to build their own data closed-loop systems.
In fact, data closed loop is not a new concept. In the field of traditional software engineering, data closure is used as an important way to improve user experience. I believe everyone has had this experience. When using software, a pop-up window pops up on the screen, asking you "Do you allow this software to collect your data?" If you agree to the relevant regulations, then the data will be used to improve the user. experience.
When the client software captures a problem, the background can capture the corresponding data, and then the development team analyzes the problem, repairs and improves the software, and hands it over to the testing team for testing The new version of the software will be placed in the cloud and updated to the terminal by the user. This is a data closed-loop process in software engineering.
In autonomous driving scenarios, problem data are usually collected on test vehicles, and very few vehicles can be collected on mass-produced vehicles. After collection, the data needs to be annotated, and then engineers use the new data to train the neural network model in the cloud. The retrained model is usually deployed to the vehicle through OTA.
A complete data closed loop usually includes data collection, data reflow, data processing, data annotation, model training, and testing and verification.
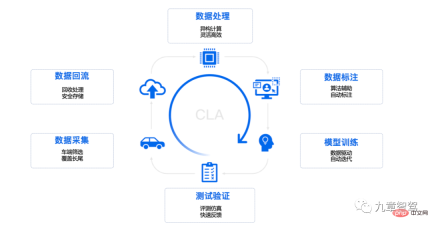
Momenta data closed-loop process illustration
Taking Tesla as an example, fleets equipped with autonomous driving hardware collect data filtered by rules and triggers in shadow mode, and the semantically filtered data is sent back to the cloud. After that, engineers use tools in the cloud to do some processing on the data, then put the processed data into the data cluster, and then use these effective data to train the model. After the model is trained, engineers will deploy the trained model to the vehicle terminal for a series of indicator tests. The verified new model will be deployed to the vehicle terminal for driver use.
Under this model, new data will be continuously triggered to be sent back, thus forming a cycle. At this point, a complete data-driven iterative development cycle is formed.
Currently, using data closed loop to drive algorithm iteration has almost been recognized as the only way to improve autonomous driving capabilities. Many OEMs and autonomous driving Tier 1 are building their own data closed-loop systems, and even have a dedicated position of data closed-loop architect.
What is the meaning of data closed loop? What is the background for data closed loop to be implemented in mass-produced cars? What are the pain points in the implementation of data closed loop in mass production vehicles and how to deal with them?
Next, this article will discuss these topics one by one.
01 The significance of data closed loop
According to the introduction of Zhijia Technology MAXIEYE, “Data closed loop is not just about the performance of a product. The performance of the function is improved, and new functions can be verified in the form of shadow mode. At the same time, according to the category of data triggering, it can also help optimize other aspects of the system, such as radar/camera blockage detection, and the threshold can be optimized based on the return data. In At the performance level, data backhaul can basically optimize all performance, such as AEB, LKA, ELK, ACC, TJA, NOA, etc. MAXIEYE has continuously upgraded AEB, ACC, TJA and other system functions through data backhaul OTA, and has pre-embedded Shadow mode of new functions."
Nowadays, various companies are building their own data closed-loop systems. The main effects they hope to achieve include improving the efficiency of corner case data collection and improving the generalization of models. capabilities and drive iteration of algorithms.
1.1 Collect corner case data
As long as it is L2 and above products , all need to have the ability to continue to evolve. In order for the autonomous driving system to continue to evolve, it is necessary to continuously obtain corner case data. As more and more corner cases are converted from "unknown" to "known", it becomes increasingly difficult to excavate new corner cases through a limited number of test vehicles with limited form routes.
By deploying the data collection system on mass-produced vehicles with wider scene coverage, it is a better way to trigger data backhaul when encountering situations that the current autonomous driving system cannot handle well enough. Method to obtain corner case.
For example, the AEB system can be deployed on a mass-produced vehicle equipped with L2 assisted driving, and then collect the driver's braking, accelerator, steering, steering, etc. Data is used to analyze why the AEB system does not respond when the driver performs these operations. Corresponding improvements should be made to address the problem that the AEB system does not respond well enough to improve the capabilities of the AEB system.
1.2 Improve the generalization ability of the model
Currently, high-level assisted driving It is moving from the highway to the city. To solve relatively simple scenes such as high-speed, it is basically enough to train the model only with the data collected by the test car, instead of having to return the data of the production car; however, the complexity of urban scenes has greatly increased, and There are also many differences in road conditions in different cities. For example, in Guangzhou, you can see tricycles pulling goods speeding on the road everywhere, but you rarely see this in Shanghai.
Therefore, many self-driving Tier 1 and car companies have a strong demand for scene integration - that is, the vehicle's assisted driving system can properly handle various road conditions in mainstream cities. Because car companies cannot limit the driving range of users, if the assisted driving function is only provided for a small area, it will greatly reduce the scope of the user base. This is obviously not what car companies want to see.
To achieve the goal of opening up scenarios, the generalization ability of the model needs to be greatly improved. To greatly improve the generalization ability of the model, it is necessary to collect data corresponding to various scenarios as much as possible. Only passenger car assisted driving based on large-scale real human driving data has the ability to accumulate data of sufficient scale and diversity.
1.3 Drive algorithm iteration
As mentioned earlier, artificial intelligence based on deep learning The algorithm has been developed for more than ten years. During this period, with the evolution of models and the development of computing power, it became possible for the autonomous driving system to digest big data. In addition, if the autonomous driving system needs to be upgraded, the capabilities of perception, planning and other aspects need to be improved accordingly. Using data to drive the algorithm to continuously evolve is an efficient way to improve the capabilities of perception, planning and other aspects.
Urban NOA - that is, the point-to-point navigation assistance function in the city is the next focus of many OEMs and autonomous driving Tier1. To realize the point-to-point navigation assistance driving function, the perception system Semantic recognition, obstacle recognition, and drivable area recognition all require a certain degree of accuracy. However, this standard has not yet been achieved.
The current mainstream perception system network architecture is based on the BEV Transformer model, which relies solely on software engineers or algorithm architects to optimize. There is not much room for improvement in the model, and the BEV Transformer architecture It can accommodate a large amount of data, which is expected to improve the model effect.
At the planning level, data drive can also play a role. Tesla had earlier used the optimal solution under partial constraints as the initial value, then used an incremental method to continuously add new constraints, and then solved the optimization problem after adding constraints, and finally obtained the optimal solution for the planning problem. Tesla engineers did a lot of offline pre-generation for this method and did parallel optimization online, so that the calculation time of each candidate path is still as long as 1 to 5ms. According to what Tesla disclosed at its AI day on September 30, 2022, Tesla engineers now use a set of data-driven decision tree generation models to help the autonomous driving system quickly generate planned paths. This data-driven decision tree generation model uses the driving data of human drivers in the Tesla fleet and the optimal path without time constraints as the true value for training. It can generate a candidate planning path within 100us, greatly shortening the generation of candidate planning. path time.
It can be seen from the above that building a good data closed-loop system is an important way to improve the capabilities of the autonomous driving system.
02 Background of data closed loop
Currently, many mass-produced vehicles are equipped with assisted driving systems, and people can drive on the mass-produced vehicles It is not difficult to collect data and the road test mileage of the autonomous driving system exceeds 100 million kilometers. In addition, chip computing power has been further enhanced - for example, NVIDIA's OrinX chip has a computing power of up to 254TOPS, so large models are beginning to be applied to perception systems, making it possible for autonomous driving systems to digest big data. On the other hand, cloud technology is relatively mature, and autonomous driving has slowly begun to enter the data-driven era.
MAXIEYE company's explanation is: "To be precise, it is not just data-driven, but AI algorithm and data are jointly driven. AI algorithm solves the problem of learning efficiency, and data solves learning The problem of content, algorithm and data is a symbiotic relationship."
"The development of artificial intelligence algorithms based on deep learning has exceeded ten years. In the early stages of this decade, supervised learning It is the mainstream in academia and industry. Supervised learning has a fatal flaw, which is that it requires a large amount of manual annotation, which greatly limits the progress of AI. However, in recent years, unsupervised and semi-supervised learning algorithms have slowly As the world begins to emerge, computers can continuously clean data and iterate algorithms through self-learning. Therefore, the conditions for developing autonomous driving technology through a data-driven approach are ripe."
Yang Jifeng, head of the Great Wall Salon Intelligent Center, mentioned in a speech: "From the perspective of the entire vehicle, the closed-loop architecture and data closed-loop from L2 to L4 will be completed in 2022, and the vehicle-side architecture and cloud architecture will be further unified. Continue The next competition is data mining, the effective use of data, the understanding of data by the entire technology stack, and how to balance the entire computing efficiency on large-scale infrastructure."
03 Data Closed Loop Pain points and countermeasures for implementation
At present, everyone has reached a consensus on the significance of data closed loop for autonomous driving systems, and the time for data closed loop to be implemented on mass-produced vehicles is basically mature. So, how is the actual implementation of each company's data closed loop? How do we judge the effectiveness of a company's data closed-loop system?
The author learned from MAXIEYE, a smart driving technology, that for autonomous driving Tier 1, technically achieving data closed loop is not a problem. Essentially, what matters is the product strength of the Tier 1 - whether It can empower car manufacturers through data closed loop. Secondly, the effect of data closed loop also depends on whether the iteration of the product is driven by data closed loop, whether the software and algorithm can be optimized based on the returned data, and regularly deployed to the terminal through OTA.
Currently, according to the level of data closed-loop capabilities, autonomous driving Tier 1 can be divided into three categories: the first is data closed-loop that has achieved large-scale mass production, and the second is through The collection vehicle realizes closed loop. The third type is that it has not yet achieved the ability to realize data closed loop. At present, the first type is still in the minority.
According to the information exchanged between the author and industry insiders, most companies currently use collection vehicles as their data source. Due to various factors such as user privacy, infrastructure, and cost, large-scale data collection on mass-produced vehicles for iterative upgrades of autonomous driving systems has not yet been realized. Some companies have not yet set up a process for collecting data on mass-produced vehicles for closed-loop data use. Although some companies have set up a process and collected some data, they have not yet put the data to good use.
It is reported that a few companies will collect some data from mass-produced vehicles, but industry insiders report that the data currently collected is mainly used to diagnose faults in the current autonomous driving system, etc. Not used for iteration of deep learning models.
In other words, few companies have truly realized the data closed loop of large-scale mass production-that is, making good use of the data collected from large-scale mass production vehicles to realize automatic Improvement of driving system capabilities. So, what are the pain points of mass production of data closed loop? What are the strategies to deal with these pain points?
Issues that need to be considered in the practice of mass production include but are not limited to: how to ensure the compliance of data collection and use, how to solve the problem of data verification, and how to integrate the data collection function with The coexistence of autonomous driving systems, the difficulty of data processing, the high complexity of data-driven software systems, and the difficulty of model training, etc.
3.1 Compliance issues in data collection and use
Compliance is divided into Surveying and mapping compliance and privacy compliance: Surveying and mapping compliance mainly involves compliance when collecting national geographic information, and privacy compliance mainly involves compliance when collecting user privacy-related data.
In terms of surveying and mapping compliance, in recent years, the country has tightened its management of data security and introduced relevant laws and regulations to limit the scope of data returned. After the “830 New Regulations” in 2022, the data collected by vehicles on the road belongs to surveying and mapping data. If an enterprise wants to use surveying and mapping data, subsequent data encryption and data compliance are essential.
First of all, when collecting data on the road, companies need to have national surveying and mapping qualifications and make corresponding filings. Otherwise, the collection process will be blocked by national security and other departments. At present, there are a total of about 30 institutions in China with relevant qualifications. Some companies have national electronic navigation Class A qualifications, which have a wide range of applications and can be collected in many cities in the country. Some companies have Class B qualifications, which have a wide range of applications. It will be smaller and can only be collected in specific cities.
Since surveying and mapping qualifications are difficult to obtain, long-term business accumulation is required. Moreover, to maintain surveying and mapping qualifications, enterprises need to have corresponding surveying and mapping services. Therefore, OEMs and autonomous driving Tier 1 generally entrust qualified suppliers or units. For example, some cloud vendors now help customers design a compliance plan around the acquisition, processing, and use of data.
After the data is collected, it needs to be desensitized and encrypted on the car side. After it is uploaded to the cloud (generally speaking, it is a private cloud), some compliance work needs to be done. This part will Qualified suppliers or units will help with surveying and mapping compliance. For some very sensitive data, it needs to be collected by the image dealer, and the data needs to be desensitized and stored in the server supervised by the image dealer.
In addition, surveying and mapping data must not be leaked, especially the data must not be moved abroad. Non-Chinese nationals can neither obtain surveying and mapping data nor operate surveying and mapping data within the company.
Generally speaking, OEMs and autonomous driving Tier1 will establish their own data centers. For security reasons, these data centers are relatively closed. When OEMs and autonomous driving Tier 1 need to use the data stored in these data centers to do some training, simulation, etc., based on compliance requirements, relevant models need to be deployed to the data center for use.
Some industry experts said, "The compliance process for surveying and mapping is too complicated, and qualifications are difficult to obtain. Everyone hopes to reduce dependence on high-precision maps as much as possible. This is currently popular in the industry." This is part of the reason for the "emphasis on perception and light map" solution. But in fact, light map is not necessarily "better", because the effect of having map data is definitely better than not having it. This current trend is not necessarily the final form, nor is it necessarily the best Yes, we just hope it can be made simpler."
In terms of privacy compliance, companies need user authorization to collect data from mass-produced vehicles. Similar to when using WeChat, companies require users to sign an authorization agreement at the beginning and inform users which data will be collected and which usage behaviors will be recorded.
At present, in terms of privacy compliance, the country has not yet issued a particularly specific plan stipulating which data can be collected and which cannot. Instead, there is only a relatively broad clause stipulating the data collection party. User privacy must not be leaked."
In actual operation, data related to user information needs to be desensitized, for example, the license plate number needs to be hidden, etc.
3.2 Data confirmation issue
Can we collect cameras and lasers needed by the autonomous driving industry on the car? Or what about data formed by millimeter waves?
Su Linfei, product manager of Moshi Intelligent, introduced: "In accordance with the relevant provisions of China's "Personal Information Protection Law", data collection that is not permitted by law is subject to privacy protection. In Germany, the former German Federal The Information Protection Bureau has regulations that if the driver is not a victim, recording other drivers’ faces and vehicles without their consent is a violation of the Personal Information Protection Act. In other words, even the owner of the vehicle may be breaking the law by recording other people’s information. However, since the autonomous driving industry associated with new energy vehicles is very new, there is currently no legal provisions. Therefore, we deduce based on basic legal concepts that the data collected by mass-produced vehicles should be owned by the car owners."
Can the data collected by car owners using their own vehicles be authorized to be used by other units?
Currently there are no relevant legal provisions and restrictions. But in other industries, such as mobile phones and the Internet, it is widely allowed.
Who can get the data uploaded by car owners?
From the perspective of the division of labor in the automotive industry chain, two types of entities can be obtained. The first is an unmanned fleet operating company, such as Baidu’s driverless taxi, and the second is a host. factory. However, since the former is relatively small, we focus on the latter.
Since the OEM is closest to the user, it is easiest to obtain the data uploaded by the user. Globally, Tesla is the best OEM in this regard.
Currently, OEMs rarely open data to the outside world. As a result, after autonomous driving Tier1 helps OEMs implement OEM-customized functions, it is difficult to collect feedback data from users when using these functions, unless Tier1 itself There are a lot of test cars. Then, it will be difficult for autonomous driving Tier 1 to perform subsequent optimization of relevant functions based on user feedback data, and it will be difficult to achieve a data closed loop.
Su Linfei, product manager of Moshi Intelligent, told the author: "After we complete a project for the OEM, if the OEM does not open the data interface, it will be difficult for us to get feedback from users. Data, and then further iterate product performance for this model. In the end, most autonomous driving system suppliers became companies with project operations as the core, and were slowly eliminated as product performance fell behind.
What’s worse is that since the trend of open source source code for autonomous driving systems has emerged, some OEMs hope to build their own data closed-loop systems to realize autonomous driving functions, and therefore are unwilling to share data with suppliers. But I don’t think it’s reasonable for OEMs to do this. I think from the overall ecosystem of autonomous driving, it’s best for everyone to perform their duties and professional people to do professional things. But the industry is still in a relatively early stage of development. Maybe Everyone will want to try and thus seize greater initiative."
An expert from a new energy OEM said: "In the past, OEMs were unwilling to give data to suppliers because they didn't understand. How can suppliers give back to themselves? The other party may not know how to use the data after giving it to them. But now, for cooperative suppliers, such as those that provide autonomous driving solutions to OEMs, OEMs can open up the right to use data. Of course, the prerequisite for open data usage rights is compliance. Suppliers need to ensure that the entire process is compliant when receiving data provided by the OEM and when using the data."
For OEMs, if they do not open the data to suppliers, they will have to explore the value of the data themselves. In the early days, no one knew the specific value of this data. Only by using it could the value be slowly discovered. The OEM can give the data to suppliers first and keep a copy for itself. The supplier can then give back to the OEM after discovering the value of the data.
Now some OEMs will require suppliers to continue to help them iterate software after SOP, and suppliers can also use this as an opportunity to obtain data. In this way, OEMs A win-win situation can be achieved with suppliers. Of course, from the perspective of the OEM, this method still has some flaws, because it is difficult for suppliers to guarantee that the effect will get better after iterations. It is also difficult for OEMs to verify the effects of iterations, so OEMs often require suppliers to open interfaces for data on intermediate results (such as sensory target recognition results), so that OEMs can verify the iterations of suppliers through statistical indicators of intermediate results. Effect.
At present, it mainly requires both parties to have a mentality of mutual trust and sincere cooperation. The OEM will open the right to use data to the supplier, and then the supplier will regularly update the software and be able to see the corresponding effect, so that the cooperation can continue. It’s just that this model has not yet been widely accepted because everyone has not seen obvious effects.
3.3 Data collection will occupy system resources
Collecting data on mass-produced vehicles will occupy some system resources. Such as computing, storage, etc. In theory, it can be assumed that computing resources, network bandwidth, etc. are not limited. However, in the actual implementation process, how to ensure that the collected data does not affect the normal operation of the autonomous driving system on mass-produced vehicles, for example, how to not affect the delay of the autonomous driving system. Wait, this is a problem that needs to be solved.
Of course, some companies will upload data when the autonomous driving system is not running, so that there is no resource occupation problem. However, some people in the industry believe that uploading data only when the autonomous driving system is not running will limit the amount of data collected. At this stage, it is still necessary to collect as much data as possible. Then, when designing, it is necessary to consider the impact of data collection on the operation of the autonomous driving system.
3.4 Data annotation and subsequent processing are difficult
It is estimated that after data is returned from mass-produced cars , the amount of data transmitted back by bicycles every day is about 100 megabytes. In the research and development stage, the total number of vehicles may be only a few dozen or a few hundred. But in the mass production stage, the number of vehicles can reach tens of thousands, hundreds of thousands or even more. Then, in the mass production stage, the amount of data generated by the entire fleet every day is a huge number.
The sharply increasing amount of data has brought challenges to both storage space and data processing speed. After mass production, the latency of data processing needs to be kept at the same level as in the R&D stage. But if the underlying infrastructure cannot keep up, data processing delays will increase correspondingly as the amount of data grows, which will greatly slow down the progress of the research and development process. For system iteration, this reduction in efficiency is unacceptable.
An industry expert told the author, “Currently, we have not seen any company that has the ability to handle the large-scale data transmitted back from mass-produced vehicles. Even if a company in New car-making forces that are relatively cutting-edge at the data closed-loop level. Even if each mass-produced car only sends back 5 minutes of data every day, they will be unable to cope with such a volume of data because of the current storage devices, file reading systems, and computing systems. Tools, etc. are still unable to cope with the huge amount of data."
To cope with the increasing amount of data, the underlying infrastructure and platform design need to be upgraded accordingly.
The engineering team needs to develop a complete data access SDK. Since the file sizes of visual data and radar data are very large, the data access, query, jump, and decoding processes need to be efficient enough, otherwise the research and development progress will be greatly slowed down.
After the vehicle-side data is transmitted back to the cloud, the engineering team needs to label a large amount of data in a timely manner. The industry currently uses pre-trained models for auxiliary annotation, but when the amount of data is large, annotation still requires a lot of work.
When labeling data, you also need to ensure the consistency of the labeling results. At present, the industry has not yet implemented fully automatic data annotation, and still requires manual work to complete part of the workload. In manual operation, how to ensure the consistency of labeling results when the amount of data is huge is also a big challenge.
In addition, the data related to autonomous driving is not only large in volume, but also of various types, which also makes data processing more difficult. Data types are divided according to source, including vehicle data, location data, environment sensing data, application data, personal data, etc., and divided according to format, including structured data and unstructured data, and data service types include files, objects, etc. How to unify Standards and coordinating different types of storage and access interfaces are also a big problem.
3.5 Data-driven software systems are highly complex
The traditional V-shaped development model is difficult to apply Data closed loop. Moreover, there is currently no unified software development platform and middleware for high-level autonomous driving in the industry.
A technical expert from a company’s autonomous driving department told the author, “The iterative system of autonomous driving functions driven by data and deep learning models can be called software 2.0. Under this model, The entire system, including team building, R&D processes, testing methods, and tool chains, are built around data."
In the software 1.0 era, what code did everyone submit, what was expected The effects are easy to assess. However, in the Software 2.0 era, it has become more difficult to measure the impact of each person's contribution on the overall effect, and it is also difficult to predict in advance, because what everyone communicates with each other is no longer clearly visible code, but data and data-based communication. Updated model.
When the amount of data is very small, for example, when we used to develop AI vision algorithms for mobile Internet applications, due to the small amount of data, the visual model engineers involved were basically Windows or Ubuntu's folders are managed individually, and team members directly use various renamed folders to transfer back and forth between each other, which is very inefficient for data exchange or collaboration.
But when it comes to autonomous driving tasks, we are faced with hundreds of thousands of pictures, and hundreds of people jointly develop a system. Each change involves modules that may It's hundreds or even thousands. How to evaluate the code quality of each module and how to check whether there are conflicts between modules are relatively complex tasks. So far, I think this system is still poor and the engineering part is not mature enough.
At the software 2.0 stage, problems that still need to be addressed are: how to measure the impact of new data on specific scenarios and on the overall situation, and how to avoid re-engineering based on new data. The trained model becomes better on some specific tasks but overall its performance decreases. To solve these problems, we need to do unit testing to check whether adding some data will help the segmented scenarios we want to solve and whether it will help the overall situation.
For example, if for a specific task, the original data set contains 20 million pictures, and then 500 new pictures are added, the ability to solve this specific task will be improved, but sometimes this will also This means that the model's score decreases when dealing with global tasks.
In addition, for visual tasks, in addition to judging the impact of new data on the model based on indicators, we also need to actually see what the specific impact is, so as to know whether the optimization meets expectations. . Just looking at the indicators may lead to situations where although the indicators have improved, the actual results still do not meet expectations.
We also need a set of infrastructure to ensure that each update is globally optimal. This infrastructure will involve data management, training evaluation, etc. Tesla is at the forefront of the industry in this regard. Its entire data-driven link has been designed to lead the industry from the very beginning, and from 2019 to 2022, it will not need much change to support its products. Iterate.
3.6 The difficulty of model training increases
After solving the problems of data collection, storage, labeling, etc., the subsequent model Training and function iteration are still challenges.
The large amount of data returned from the training mass production vehicle requires an efficient file transfer system to ensure that it is not "stuck" by I/O during training.
At the same time, there must be sufficient computing power. The way to improve computing power is usually to build a multi-card parallel cluster. Then, how to maintain efficient inter-card communication during training to reduce data transmission delays and fully and effectively utilize the computing power of each card is also an issue that needs to be considered.
In order to cope with the demand for computing power in model training, some OEMs have specially built their own intelligent computing centers. However, the cost of building an intelligent computing center is very high, and for small and medium-sized enterprises, this is almost impossible.
#Although there are still many pain points, we can still expect that over time, the current problems will be solved one by one. By then, the data closed-loop can be truly implemented on mass-produced vehicles, and the data collected after being implemented on mass-produced vehicles will feed back the data closed-loop system and push the autonomous driving system to a higher level.
The above is the detailed content of The ideal and reality of autonomous driving data closed loop. For more information, please follow other related articles on the PHP Chinese website!

 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas
 Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AM
Sam's Club Bets On AI To Eliminate Receipt Checks And Enhance RetailApr 22, 2025 am 11:29 AMRevolutionizing the Checkout Experience Sam's Club's innovative "Just Go" system builds on its existing AI-powered "Scan & Go" technology, allowing members to scan purchases via the Sam's Club app during their shopping trip.
 Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AM
Nvidia's AI Omniverse Expands At GTC 2025Apr 22, 2025 am 11:28 AMNvidia's Enhanced Predictability and New Product Lineup at GTC 2025 Nvidia, a key player in AI infrastructure, is focusing on increased predictability for its clients. This involves consistent product delivery, meeting performance expectations, and
 Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AM
Exploring the Capabilities of Google's Gemma 2 ModelsApr 22, 2025 am 11:26 AMGoogle's Gemma 2: A Powerful, Efficient Language Model Google's Gemma family of language models, celebrated for efficiency and performance, has expanded with the arrival of Gemma 2. This latest release comprises two models: a 27-billion parameter ver
 The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AM
The Next Wave of GenAI: Perspectives with Dr. Kirk Borne - Analytics VidhyaApr 22, 2025 am 11:21 AMThis Leading with Data episode features Dr. Kirk Borne, a leading data scientist, astrophysicist, and TEDx speaker. A renowned expert in big data, AI, and machine learning, Dr. Borne offers invaluable insights into the current state and future traje
 AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AM
AI For Runners And Athletes: We're Making Excellent ProgressApr 22, 2025 am 11:12 AMThere were some very insightful perspectives in this speech—background information about engineering that showed us why artificial intelligence is so good at supporting people’s physical exercise. I will outline a core idea from each contributor’s perspective to demonstrate three design aspects that are an important part of our exploration of the application of artificial intelligence in sports. Edge devices and raw personal data This idea about artificial intelligence actually contains two components—one related to where we place large language models and the other is related to the differences between our human language and the language that our vital signs “express” when measured in real time. Alexander Amini knows a lot about running and tennis, but he still
 Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AM
Jamie Engstrom On Technology, Talent And Transformation At CaterpillarApr 22, 2025 am 11:10 AMCaterpillar's Chief Information Officer and Senior Vice President of IT, Jamie Engstrom, leads a global team of over 2,200 IT professionals across 28 countries. With 26 years at Caterpillar, including four and a half years in her current role, Engst
 New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AM
New Google Photos Update Makes Any Photo Pop With Ultra HDR QualityApr 22, 2025 am 11:09 AMGoogle Photos' New Ultra HDR Tool: A Quick Guide Enhance your photos with Google Photos' new Ultra HDR tool, transforming standard images into vibrant, high-dynamic-range masterpieces. Ideal for social media, this tool boosts the impact of any photo,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Atom editor mac version download
The most popular open source editor

Dreamweaver Mac version
Visual web development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

