
 Technology peripheralsAI'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'
Technology peripheralsAI'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference''Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'

What if artificial intelligence could read your imagination and turn the images in your mind into reality?

Although this sounds a bit cyberpunk. But a recently published paper has caused a stir in the AI circle.
This paper found that they used the recently very popular Stable Diffusion to reconstruct high-resolution brain activity High-efficiency, high-precision images. The authors wrote that unlike previous studies, they did not need to train or fine-tune an artificial intelligence model to create these images.

- ##Paper address: https://www .biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf
- Webpage address: https://sites.google.com/view/ stablediffusion-with-brain/
How did they do it?
In this study, the authors used Stable Diffusion to reconstruct images of human brain activity obtained through functional magnetic resonance imaging (fMRI). The author also stated that it is also helpful to understand the mechanism of the latent diffusion model by studying different components of brain-related functions (such as the latent vector of image Z, etc.).
This paper has also been accepted by CVPR 2023.
The main contributions of this study include:
- Demonstrating that its simple framework can generate data from brain activities with high semantic fidelity Reconstruct high-resolution (512×512) images in medium without the need to train or fine-tune complex deep generative models, as shown in the figure below;
- by mapping specific components to different brains area, this study quantitatively explains each component of LDM from a neuroscience perspective;
- This study objectively explains how the text-to-image conversion process implemented by LDM combines conditional text expressions semantic information while maintaining the appearance of the original image.
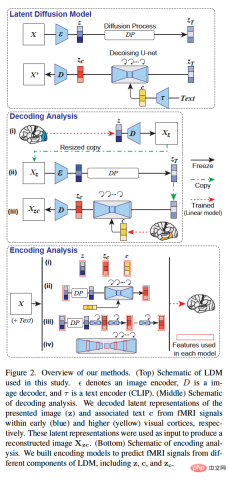
The overall methodology of this study is shown in Figure 2 below. Figure 2 (top) is a schematic diagram of the LDM used in this study, where ε represents the image encoder, D represents the image decoder, and τ represents the text encoder (CLIP).
Figure 2 (middle) is a schematic diagram of the decoding analysis of this study. We decoded the underlying representation of the presented image (z) and associated text c from fMRI signals within early (blue) and advanced (yellow) visual cortex, respectively. These latent representations are used as input to generate the reconstructed image X_zc.
Figure 2 (bottom) is a schematic diagram of the coding analysis of this study. We constructed encoding models to predict fMRI signals from different components of LDM, including z, c, and z_c.
I won’t introduce too much about Stable Diffusion here, I believe many people are familiar with it.
ResultsLet’s take a look at the visual reconstruction results of this study.
Decoding
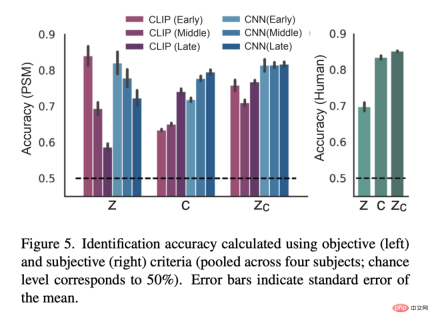
Figure 3 below shows the visual reconstruction results of a subject (subj01). We generated five images for each test image and selected the image with the highest PSM. On the one hand, the image reconstructed using only z is visually consistent with the original image but fails to capture its semantic content. On the other hand, images reconstructed with only c produce images with high semantic fidelity but are visually inconsistent. Finally, using z_c reconstructed images can produce high-resolution images with high semantic fidelity.

Figure 4 shows the reconstruction of the same image by all testers (all images were generated with z_c) . Overall, the reconstruction quality across testers was stable and accurate.

Figure 5 is the result of the quantitative evaluation:
Coding model
## Figure 6 shows the coding model pair related to LDM Prediction accuracy of three latent images: z, the latent image of the original image; c, the latent image of the image text annotation; and z_c, the noisy latent image representation of z after a cross-attention back-diffusion process with c.
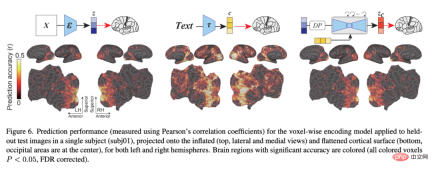
Figure 7 shows that z predicts voxel activity throughout the cortex better than z_c when a small amount of noise is added. Interestingly, z_c predicts voxel activity in high visual cortex better than z when increasing the noise level, indicating that the semantic content of the image is gradually emphasized.

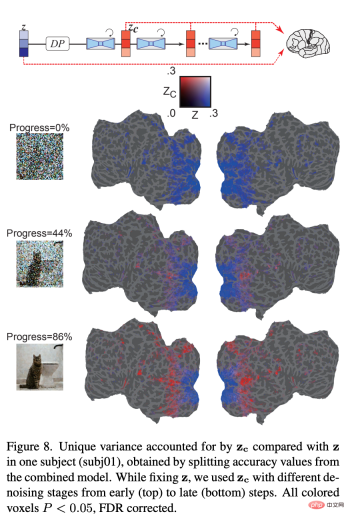
How does the underlying representation of added noise change during the iterative denoising process? Figure 8 shows that in the early stages of the denoising process, the z-signal dominates the prediction of the fMRI signal. At the intermediate stage of the denoising process, z_c predicts activity within high visual cortex much better than z, indicating that most of the semantic content emerges at this stage. The results show how LDM refines and generates images from noise.
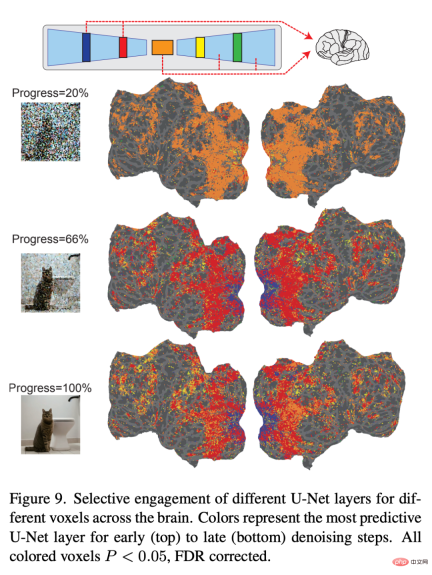
Finally, the researchers explored what information each layer of U-Net is processing. Figure 9 shows the results of different steps of the denoising process (early, mid, late) and the encoding model of different layers of U-Net. In the early stages of the denoising process, U-Net's bottleneck layer (orange) yields the highest prediction performance across the entire cortex. However, as denoising proceeds, the early layers of U-Net (blue) predict activity within early visual cortex, while the bottleneck layers shift to superior predictive power for higher visual cortex.
For more research details, please view the original paper.
The above is the detailed content of 'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'. For more information, please follow other related articles on the PHP Chinese website!

 Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AM
Are You At Risk Of AI Agency Decay? Take The Test To Find OutApr 21, 2025 am 11:31 AMThis article explores the growing concern of "AI agency decay"—the gradual decline in our ability to think and decide independently. This is especially crucial for business leaders navigating the increasingly automated world while retainin
 How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AM
How to Build an AI Agent from Scratch? - Analytics VidhyaApr 21, 2025 am 11:30 AMEver wondered how AI agents like Siri and Alexa work? These intelligent systems are becoming more important in our daily lives. This article introduces the ReAct pattern, a method that enhances AI agents by combining reasoning an
 Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM
Revisiting The Humanities In The Age Of AIApr 21, 2025 am 11:28 AM"I think AI tools are changing the learning opportunities for college students. We believe in developing students in core courses, but more and more people also want to get a perspective of computational and statistical thinking," said University of Chicago President Paul Alivisatos in an interview with Deloitte Nitin Mittal at the Davos Forum in January. He believes that people will have to become creators and co-creators of AI, which means that learning and other aspects need to adapt to some major changes. Digital intelligence and critical thinking Professor Alexa Joubin of George Washington University described artificial intelligence as a “heuristic tool” in the humanities and explores how it changes
 Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AM
Understanding LangChain Agent FrameworkApr 21, 2025 am 11:25 AMLangChain is a powerful toolkit for building sophisticated AI applications. Its agent architecture is particularly noteworthy, allowing developers to create intelligent systems capable of independent reasoning, decision-making, and action. This expl
 What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AM
What are the Radial Basis Functions Neural Networks?Apr 21, 2025 am 11:13 AMRadial Basis Function Neural Networks (RBFNNs): A Comprehensive Guide Radial Basis Function Neural Networks (RBFNNs) are a powerful type of neural network architecture that leverages radial basis functions for activation. Their unique structure make
 The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AM
The Meshing Of Minds And Machines Has ArrivedApr 21, 2025 am 11:11 AMBrain-computer interfaces (BCIs) directly link the brain to external devices, translating brain impulses into actions without physical movement. This technology utilizes implanted sensors to capture brain signals, converting them into digital comman
 Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AM
Insights on spaCy, Prodigy and Generative AI from Ines MontaniApr 21, 2025 am 11:01 AMThis "Leading with Data" episode features Ines Montani, co-founder and CEO of Explosion AI, and co-developer of spaCy and Prodigy. Ines offers expert insights into the evolution of these tools, Explosion's unique business model, and the tr
 A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AM
A Guide to Building Agentic RAG Systems with LangGraphApr 21, 2025 am 11:00 AMThis article explores Retrieval Augmented Generation (RAG) systems and how AI agents can enhance their capabilities. Traditional RAG systems, while useful for leveraging custom enterprise data, suffer from limitations such as a lack of real-time dat


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Dreamweaver Mac version
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

WebStorm Mac version
Useful JavaScript development tools

