
Home >Technology peripherals >AI >New research by Stanford Li Feifei's team found that designing, improving, and evaluating data are the keys to achieving trustworthy artificial intelligence
New research by Stanford Li Feifei's team found that designing, improving, and evaluating data are the keys to achieving trustworthy artificial intelligence

- 王林forward
- 2023-04-24 10:04:07941browse
Under the current trend of the development of AI models shifting from model-centric to data-centric, the quality of data has become particularly important.
In previous AI development processes, data sets were usually fixed, and development efforts focused on iterating the model architecture or training process to improve baseline performance. Now, with data iteration taking center stage, we need more systematic ways to evaluate, filter, clean, and annotate the data used to train and test AI models.
Recently, Weixin Liang, Li Feifei and others from the Department of Computer Science at Stanford University jointly published an article titled "Advances, challenges and opportunities in creating data for trustworthy AI" in "Nature-Machine Intelligence" , discussed the key factors and methods to ensure data quality in all aspects of the entire AI data process.

Paper address: https://www.nature.com/articles/s42256-022-00516-1.epdf?sharing_token=VPzI-KWAm8tLG_BiXJnV9tRgN0jAjWel9jnR3ZoTv0MRS1pu9dXg73FQ0NTrwhu7Hi_VBEr6peszIAFc 6XO1tdlvV1lLJQtOvUFnSXpvW6_nu0Knc_dRekx6lyZNc6PcM1nslocIcut_qNW9OUg1IsbCfuL058R4MsYFqyzlb2E=
The main steps in the AI data process include: data design (data collection and recording), data improvement (data filtering, cleaning, annotation, enhancement), and data strategy for evaluating and monitoring AI models, each step of which All will affect the credibility of the final AI model.
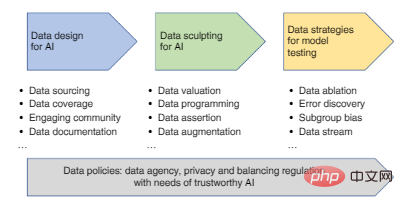
Figure 1: Roadmap for the development of a data-centric approach from data design to evaluation.
1. Data design for AI
After identifying an artificial intelligence application, the first step in developing an AI model is to design the data (i.e., identify and record the source of the data).
Design should be an iterative process—using experimental data to develop an initial AI model, then collecting additional data to patch the model’s limitations. Key criteria for design are ensuring that the data is suitable for the task and covers enough scope to represent the different users and scenarios the model may encounter.
And the data sets currently used to develop AI often have limited coverage or are biased. In medical AI, for example, the collection of patient data used to develop algorithms is disproportionately distributed geographically, which can limit the applicability of AI models to different populations.
One way to improve data coverage is to involve the broader community in the creation of the data. This is exemplified by the Common Voice project, the largest public dataset currently available, which contains 11,192 hours of speech transcriptions in 76 languages from more than 166,000 participants.
And when representative data is difficult to obtain, synthetic data can be used to fill the coverage gaps. For example, the collection of real faces often involves privacy issues and sampling bias, while synthetic faces created by deep generative models are now used to mitigate data imbalance and bias. In healthcare, synthetic medical records can be shared to facilitate knowledge discovery without disclosing actual patient information. In robotics, real-world challenges are the ultimate test bed, and high-fidelity simulation environments can be used to enable agents to learn faster and safer on complex and long-term tasks.
But there are also some problems with synthetic data. There is always a gap between synthetic and real-world data, so performance degradation often occurs when an AI model trained on synthetic data is transferred to the real world. Synthetic data can also exacerbate data disparities if simulators are not designed with minority groups in mind. The performance of AI models is highly dependent on the context of their training and evaluation data, so it is important to document the context of data design in standardized and transparent reporting. .
Now, researchers have created a variety of "data nutrition labels" to capture metadata about the data design and annotation process. Useful metadata includes statistics on the sex, gender, race, and geographic location of participants in the dataset, which can help discover if there are underrepresented subgroups that are not being covered. Data provenance is also a type of metadata that tracks the source and time of data as well as the processes and methods that produced the data.
Metadata can be stored in a dedicated data design document, which is important for observing the life cycle and socio-technical context of the data. Documents can be uploaded to stable and centralized data repositories such as Zenodo.
2. Improve data: filter, clean, label, enhance
After the initial data set is collected, we need to further improve the data to provide more effective data for the development of AI. This is a key difference between model-centric approaches to AI and data-centric approaches, as shown in Figure 2a. Model-centric research is usually based on given data and focuses on improving the model architecture or optimizing this data. Data-centric research, on the other hand, focuses on scalable methods to systematically improve data through processes such as data cleaning, filtering, annotation, and enhancement, and can use a one-stop model development platform.

Figure 2a: Comparison of model-centric and data-centric approaches to AI. MNIST, COCO, and ImageNet are commonly used datasets in AI research.
Data screening
If the data set is very noisy, we must carefully screen the data before training, which can significantly improve the reliability and generalization of the model. The airplane image in Figure 2a is the noisy data point that should be removed from the bird data set.
In Figure 2b, four state-of-the-art models trained on previously used large dermatology data all perform poorly due to bias in the training data, especially on dark skin images. Not good, and Model 1 trained on smaller, high-quality data is relatively more reliable on both dark and light skin tones.
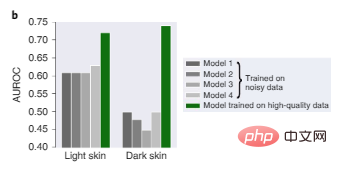
Figure 2b: Dermatology diagnostic test performance on light skin and dark skin images.
Figure 2c shows that ResNet, DenseNet, and VGG, three popular deep learning architectures for image classification, all perform poorly when trained on noisy image datasets. After data Shapley value filtering, poor quality data is deleted, and the ResNet model trained on a cleaner data subset performs significantly better.
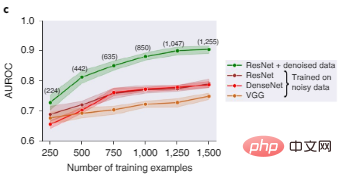
#Figure 2c: Comparison of object recognition test performance of different models before and after data filtering. Numbers in parentheses represent the number of training data points remaining after filtering out noisy data, with results aggregated over five random seeds, and the shaded area represents the 95% confidence interval.
This is what data evaluation is all about, it aims to quantify the importance of different data and filter out data that may harm model performance due to poor quality or bias.
Data Cleaning
In this article, the author introduces two data evaluation methods to help clean the data:
One method is to measure when different data are deleted during the training process The change in AI model performance can be obtained by using the Shapley value or impact approximation of the data, as shown in Figure 3a below. This approach enables efficient computational evaluation of large AI models.
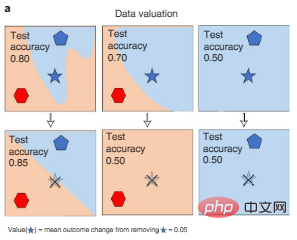
Figure 3a: Data evaluation. The Shapley value of the data measures the change in performance of a model trained on different subsets of the data when a specific point is removed from training (the faded five-pointed star crossed out in the figure), thereby quantifying each data point (the five-pointed star symbol) value. Colors represent category labels.
Another approach is to predict uncertainty to detect poor quality data points. Human annotations of data points can systematically deviate from AI model predictions, and confidence learning algorithms can detect these deviations, with more than 3% of test data found to be mislabeled on common benchmarks like ImageNet. Filtering out these errors can greatly improve model performance.
Data annotation
Data annotation is also a major source of data bias. Although AI models can tolerate a certain level of random label noise, biased errors produce biased models. Currently, we mainly rely on manual annotation, which is very expensive. For example, the cost of annotating a single LIDAR scan may exceed $30. Because it is three-dimensional data, the annotator needs to draw a three-dimensional bounding box, which is more demanding than general annotation tasks.
Therefore, the author believes that we need to carefully calibrate annotation tools on crowdsourcing platforms such as MTurk to provide consistent annotation rules. In the medical environment, it is also important to consider that annotators may require specialized knowledge or may have sensitive data that cannot be crowdsourced.
One way to reduce the cost of annotation is data programming. In data programming, AI developers no longer need to manually label data points, but instead write programmatic labeling functions to automatically label training sets. As shown in Figure 3b, after automatically generating multiple potentially noisy labels for each input using a user-defined label function, we can design additional algorithms to aggregate multiple label features to reduce noise.
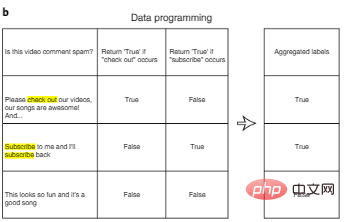
Figure 3b: Data programming.
Another "human-in-the-loop" approach to reducing labeling costs is to prioritize the most valuable data so that we can label it through active learning. Active learning draws ideas from optimal experimental design. In active learning, the algorithm selects the most informative points from a set of unlabeled data points, such as points with high information gain or points on which the model has uncertainty. Click, and then perform manual annotation. The benefit of this approach is that the amount of data required is much smaller than that required for standard supervised learning.
Data Augmentation
Finally, when the existing data is still very limited, data augmentation is an effective method to expand the data set and improve the reliability of the model.
Computer vision data can be enhanced with image rotations, flips, and other digital transformations, and text data can be enhanced with transformations to automated writing styles. There is also the recent Mixup, a more complex augmentation technique that creates new training data by interpolating pairs of training samples, as shown in Figure 3c.
In addition to manual data enhancement, the current AI automated data enhancement process is also a popular solution. Additionally, when unlabeled data is available, label augmentation can also be achieved by using an initial model to make predictions (these predictions are called pseudo-labels), and then training a larger model on the combined data with real and high-confidence pseudo-labels. Model.
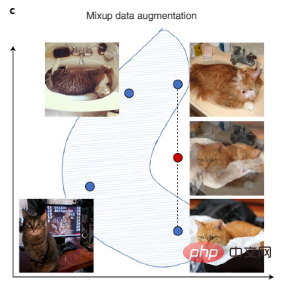
Figure 3c: Mixup augments a dataset by creating synthetic data that interpolates existing data. Blue points represent existing data points in the training set, and red points represent synthetic data points created by interpolating two existing data points.
3. Data used to evaluate and monitor AI models
After the model is trained, the goal of AI evaluation is the generalizability and credibility of the model.
To achieve this goal, we should carefully design the evaluation data to find the real-world settings of the model, and the evaluation data also need to be sufficiently different from the model's training data.
For example, in medical research, AI models are usually trained based on data from a small number of hospitals. When such a model is deployed in a new hospital, its accuracy will decrease due to differences in data collection and processing. In order to evaluate the generalization of the model, it is necessary to collect evaluation data from different hospitals and different data processing pipelines. In other applications, evaluation data should be collected from different sources, preferably labeled as training data by different annotators. At the same time, high-quality human labels remain the most important evaluation.
An important role of AI evaluation is to determine whether the AI model uses spurious correlations as "shortcuts" in training data that cannot be well conceptualized. For example, in medical imaging, the way the data is processed (such as cropping or image compression) can create spurious correlations (i.e., shortcuts) that are picked up by the model. These shortcuts may be helpful on the surface, but can fail catastrophically when the model is deployed in a slightly different environment.
Systematic data ablation is a good way to examine potential model "shortcuts". In data ablation, AI models are trained and tested on ablated inputs of spuriously correlated surface signals.
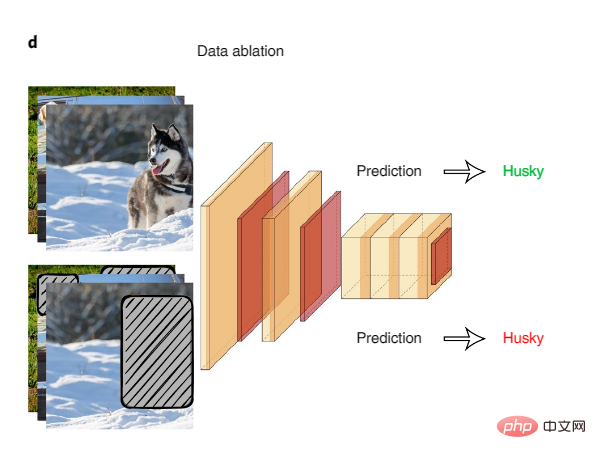
Figure 4: Data ablation
An example of using data ablation to detect model shortcuts is a study on common natural language inference datasets. , an AI model trained on only the first half of a text input achieved high accuracy in inferring the logical relationship between the first and second halves of the text, compared to the level of human inference and random guessing on the same input. almost. This suggests that AI models exploit spurious correlations as a shortcut to accomplish this task. The research team found that specific linguistic phenomena are exploited by AI models, such as negation in text being highly correlated with tags.
Data ablation is widely used in various fields. For example, in the medical field, biologically relevant parts of an image can be masked out as a way to assess whether the AI is learning from false background or an artifact of the image quality.
AI evaluation is often limited to comparing overall performance metrics across an entire test data set. But even if an AI model works well at the overall data level, it may still show systematic errors on specific subgroups of the data, and characterizing clusters of these errors can provide a better understanding of the model's limitations.
When metadata is available, fine-grained assessment methods should, to the extent possible, slice assessment data by the sex, gender, race, and geographic location of the participants in the dataset—for example, “Asian Older Male” or “Native American women”—and quantify the model’s performance on each data subgroup. Multi-accuracy auditing is an algorithm that automatically searches for subgroups of data where AI models perform poorly. Here, auditing algorithms are trained to use metadata to predict and cluster the original model’s errors, then provide explainable answers to questions such as what mistakes the AI model made and why.
When metadata is not available, methods such as Domino automatically identify data clusters where evaluation models are prone to errors and use text generation to create natural language explanations of these model errors.
4. The future of data
Currently most AI research projects develop datasets only once, but real-world AI users often need to continuously update datasets and models. Continuous data development will bring the following challenges:
First, both data and AI tasks can change over time: for example, maybe a new vehicle model appears on the road (i.e., domain shift) , or maybe the AI developer wants to recognize a new object category (for example, a school bus type that is different from a regular bus), which would change the classification of the label. It would be wasteful to throw away millions of hours of old tag data, so updates are imperative. Additionally, training and evaluation metrics should be carefully designed to weigh new data and use appropriate data for each subtask.
Second, in order to continuously obtain and use data, users will need to automate most data-centric AI processes. This automation involves using algorithms to choose which data to send to the annotator and how to use it to retrain the model, and only alerting the model developer if something goes wrong in the process (for example, if accuracy metrics drop). As part of the "MLOps (Machine Learning Operations)" trend, industry companies are beginning to use tools to automate the machine learning life cycle.
The above is the detailed content of New research by Stanford Li Feifei's team found that designing, improving, and evaluating data are the keys to achieving trustworthy artificial intelligence. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology