
Home >Technology peripherals >AI >Technical analysis and practice sharing: user mode and kernel mode in dual-engine GPU container virtualization
Technical analysis and practice sharing: user mode and kernel mode in dual-engine GPU container virtualization

- 王林forward
- 2023-04-23 15:40:101270browse
How to maximize the efficiency of hardware computing power is a matter of great concern to all resource operators and users. As a leading AI company, Baidu has perhaps the most comprehensive AI application scenarios in the industry.
In this article, we will share and discuss GPU container virtualization solutions in complex AI scenarios and best practices within the factory.
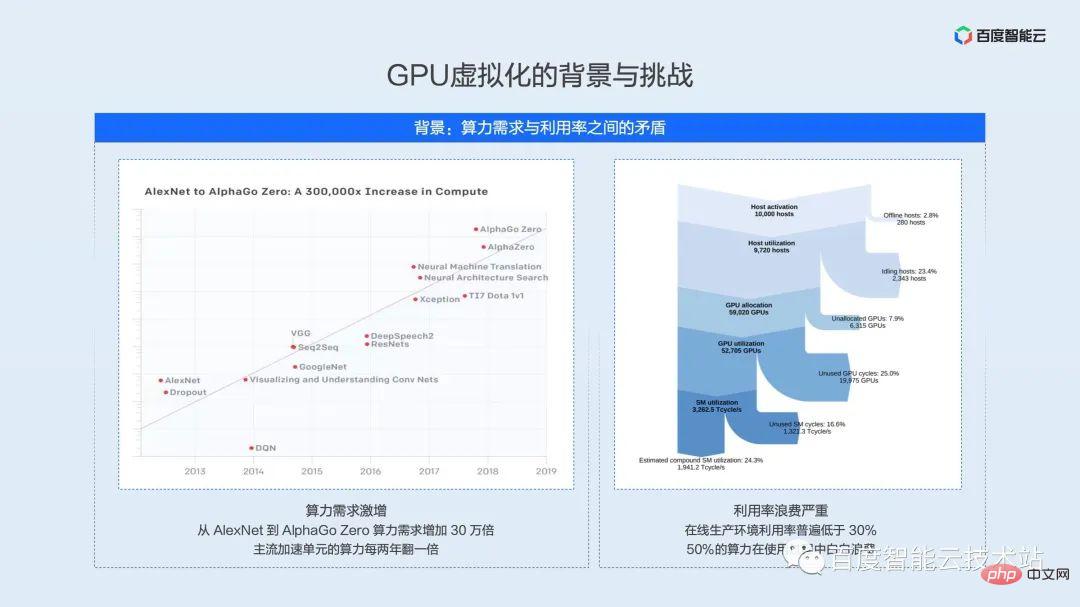
The left and right parts of the picture below have been shown many times on different occasions. The main purpose of putting them here is to emphasize the demand for computing power - the exponential growth of hardware computing power and the utilization in real application scenarios. The contradiction between low efficiency and waste of resources.
The part on the left is statistics from OpenAI. Since 2012, the computing power required for model training has doubled every 3.4 months. As of large models such as AlphaGoZero, the training computing power has increased. 300,000 times, and the trend continues. On the one hand, as the demand for computing power increases, the computing performance of mainstream AI acceleration units is also doubling every two years. On the other hand, resource utilization efficiency restricts the full use of hardware performance.
The part on the right is the result of Facebook's data center machine learning load analysis in 2021. A large amount of AI computing power is lost in links such as failures, scheduling, waste of time slices, and waste of space units, and the real computing power utilization is less than 30%. We believe that this is also the current situation faced by major domestic infrastructure operators.
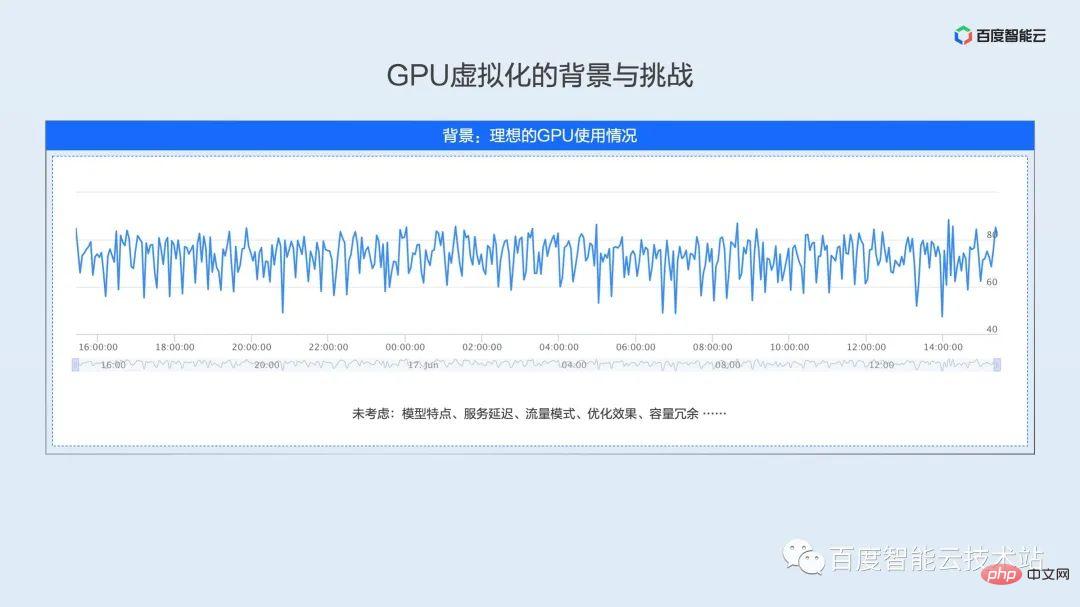
Just mentioned that the utilization rate of the online cluster is less than 30% may not be in line with the perceptions of many students. Many students online may be developers of models and algorithms. Our general understanding is that utilization can remain very high during training and testing, and can even reach 100% utilization.
But when the model is launched in the production environment, it will be subject to many constraints. These constraints cause the utilization rate to fall far short of our expectations.
Let’s use limited space to summarize the main constraints:
- Model characteristics: Each model network is different, and the combination of underlying operators called is different. To a large extent Will affect GPU utilization.
- Service SLA: Services in different scenarios require different SLAs. Some services have high real-time requirements and even need to be strictly controlled within 10ms. Then these services cannot improve utilization by increasing batchsize. Even batchsize can only be 1.
- Traffic pattern: Different model algorithms serve different application scenarios, such as OCR recognition, which may be frequently called during work. Speech recognition is more often called during commuting time or entertainment and leisure, which leads to peak and valley fluctuations in GPU utilization throughout the day.
- Optimization effect: Depending on the iteration frequency of the model and the different coverage scenarios, the optimization granularity of the model is also different. It is conceivable that it is difficult for a model utilization rate that is not fully optimized to reach a high level.
- Capacity redundancy: Before the model goes online, it must undergo detailed capacity planning, what is the maximum traffic, and whether multiple regions are needed. In this process, capacity redundancy will be reserved that is difficult to ignore. These redundancies are usually used in normal times. It also caused a waste of computing power.
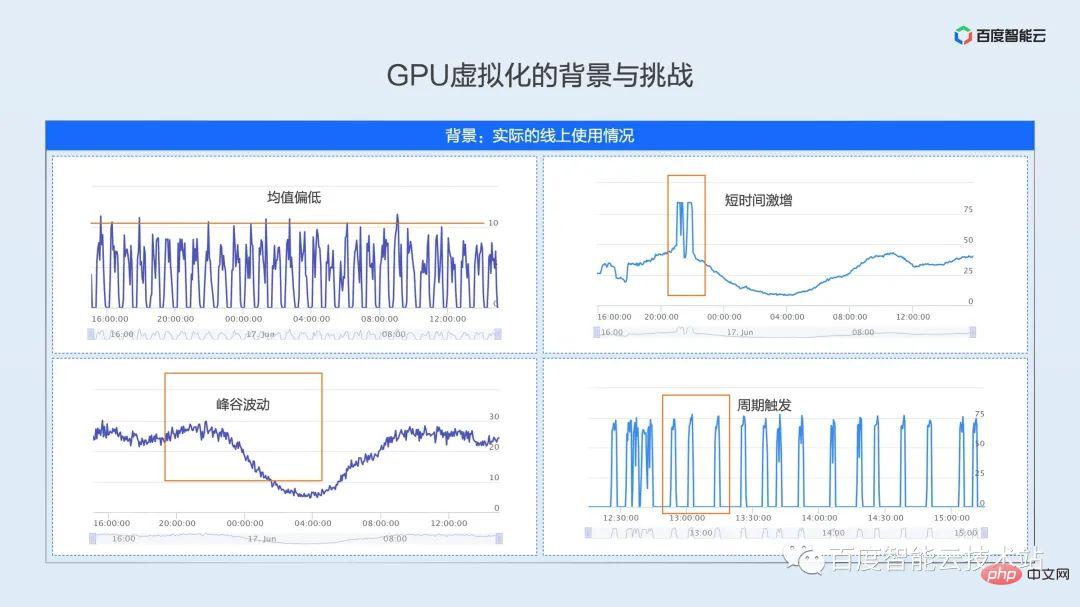
Under the constraints of the above constraints, the utilization rate of the real production environment may be what we want to show next. We abstract these utilization patterns from the complex and changing online production environment.
- Low average type: As shown in the upper left figure, it is a real online inference business. Due to the limitations of model characteristics and service SLA, the peak utilization of the GPU is only 10%, and the average utilization will be even lower.
- Peak and valley fluctuation type: As shown in the figure below, it is a typical utilization pattern of online inference business. The service will reach the peak during the day, and the utilization will be at the trough from late night to the next morning. The average utilization throughout the day The utilization rate is only about 20%, and the low utilization rate is less than 10%.
- Short-term surge type: As shown in the upper right picture, the utilization curve is basically consistent with the lower left picture, but there will be two obvious utilization peaks during the prime time at night, and the peak utilization rate is as high as 80%. In order to meet In terms of service quality during the peak stage, the service will reserve a large buffer during the deployment process, and the average resource utilization is just over 30%.
- Periodic trigger type: As shown in the picture on the right below, it is the utilization mode of a typical online training scenario. The online training task is between offline training and online inference. This is a periodic batch processing task. For example, a batch of data arrives every 15 minutes, but the training of this batch of data only takes 2-3 minutes, and the GPU is idle for a large amount of time.
AI application scenarios are complex and changeable. The above only lists four typical scenarios. How to balance business performance and resource efficiency in complex scenarios is the first challenge we encounter in GPU virtualization.
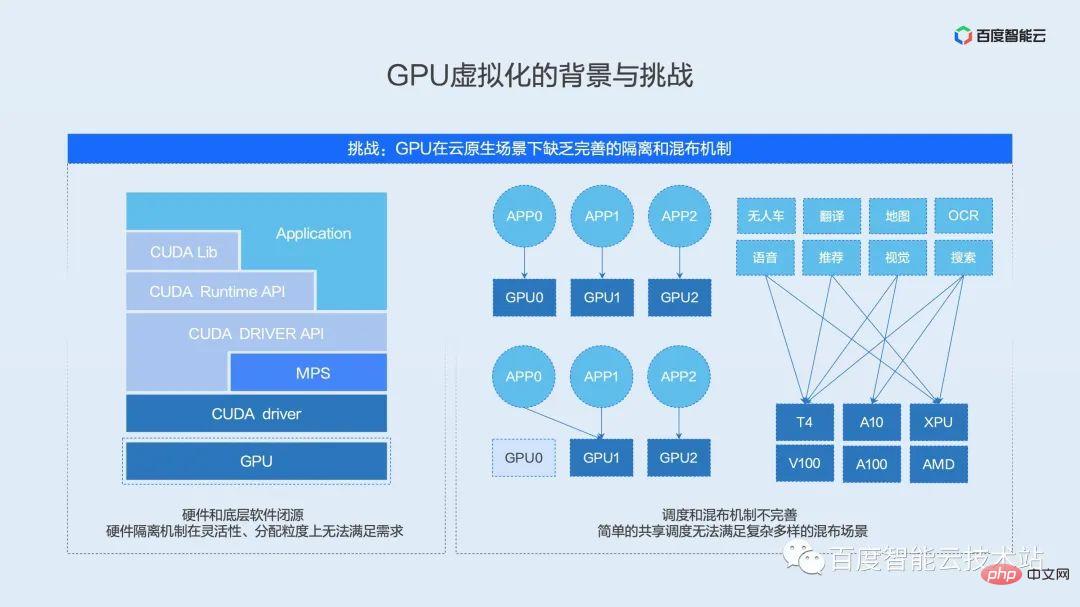
#The second challenge we face during GPU virtualization is the lack of a complete GPU isolation and mixing mechanism.
We take the current mainstream NVIDIA GPU as an example. The typical AI software and hardware ecosystem is divided into several levels - application & framework layer, runtime layer, driver layer, and hardware layer.
First of all, the top layer is the user's application, which includes various common frameworks such as PaddlePaddle, TensorFlow, PyTorch, etc. Under the application layer is the API interface layer encapsulated by the hardware provider, including various common operator libraries and hardware runtime access interfaces. Under this layer of API interface is the driver layer that communicates with the hardware. This layer is located in the kernel state and is the software interface layer that directly communicates with the device. At the bottom is the real AI acceleration hardware, which is responsible for the execution of operators.
Traditional virtualization solutions are implemented in combination with the driver kernel state and hardware virtualization logic. These two levels are the core IP of hardware providers and are generally closed source. As will be mentioned later, the current GPU-native isolation mechanism cannot meet the usage requirements in cloud-native scenarios in terms of flexibility and allocation strength.
In addition to the isolation mechanism, the existing hybrid distribution mechanism is also difficult to meet the needs of complex scenarios. We have seen that there are many open source solutions for shared scheduling in the industry. These open source solutions simply combine two tasks from the resource level. Dispatch onto a card. In actual scenarios, simple sharing will cause mutual impact between businesses, long-tail delays and even deterioration of throughput, making simple sharing unable to be truly applied in production environments.
In the utilization model analysis section above, we saw that different businesses and different scenarios have different utilization models. How to abstract business scenarios and customize hybrid solutions is the key to implementing the production environment.
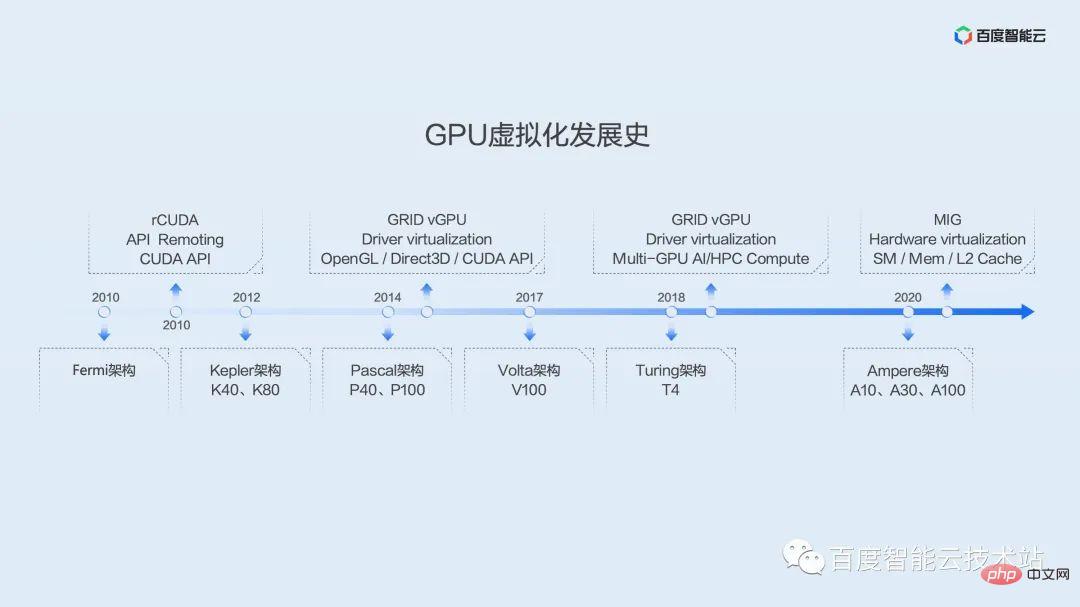
#In order to give everyone a more comprehensive understanding of the development of GPU and the history of virtualization, here we use a picture to show the development history of GPU virtualization.
GPU’s application in general computing can be traced back to the Tesla architecture of the G80 era. It is the first generation architecture to implement unified shaders. It uses a general-purpose processor SM to replace the original graphics and image processing of separate vertex and pixel pipelines. device.
The earliest GPU introduced by Baidu can be traced back to the Fermi architecture. Since this point in time, a number of virtualization solutions have appeared in the industry, most of which focus on API hijacking. The typical representative here is rCUDA, a project originally maintained by academic groups. Until recently, it has maintained a certain frequency of updates and iterations, but it seems to be focused on academic research and has not been widely used in production environments.
Baidu’s large-scale introduction of GPUs was based on the Kepler architecture. The Kepler architecture opened the era of Baidu’s self-developed super AI computer X-MAN. X-MAN 1.0 implements a single-machine 16-card configuration for the first time, and can realize dynamic binding and flexible ratio of CPU and GPU at the PCIe hardware level. Limited by the performance of a single card, at that time more consideration was given to expansion rather than segmentation.
The performance of the subsequent Pascal architecture, Volta architecture, and Turing architecture has improved rapidly, and the demand for virtualization has become increasingly apparent. We have seen that from the earliest Kepler architecture, NV officially provided the GRID vGPU virtualization solution, which was initially targeted at graphics rendering and remote desktop scenarios. Around 2019, solutions were also provided for AI and high-performance computing scenarios. However, these solutions are based on virtual machines and are rarely used in AI scenarios.
In the Ampere generation, NV launched the MIG instance segmentation solution, which realizes the segmentation of multiple hardware resources such as SM, MEM, and L2 Cache at the hardware level, providing good hardware isolation performance. However, this solution is supported starting from the Ampere architecture, and there are certain restrictions on card models. Only a few models, A100 and A30, can support it. And even after slicing, the performance of a single instance exceeds the computing power of T4, and cannot well solve the efficiency problem of the current production environment.
After everyone has some impressions of the history of GPU architecture and virtualization, let’s introduce in detail the main levels, or technical routes, of realizing GPU virtualization. .
To achieve resource virtualization and isolation, the resource first needs to be separable in the time or space dimension. From the user's perspective, multiple tasks can be executed concurrently or in parallel.
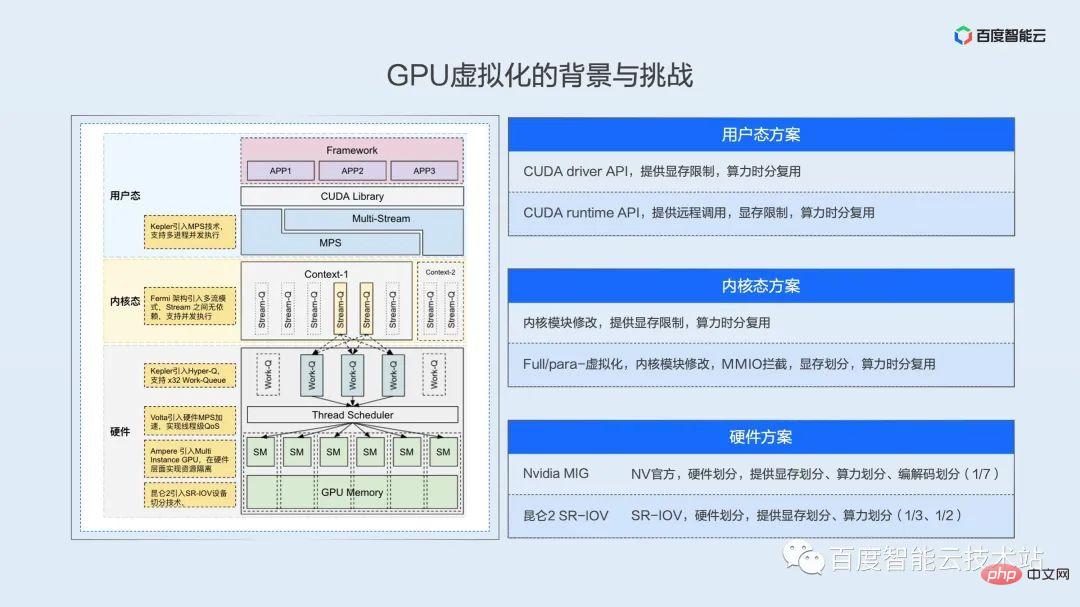
Here we discuss parallel or concurrency space at multiple levels of user mode, kernel mode, and hardware.
Since NV’s software and hardware ecosystem is closed source, the schematic diagram here is drawn from our comprehensive architecture white paper, reverse papers and our own understanding. We hope that everyone can correct the inaccuracies in time.
User Mode Solution
Let’s look at this picture from top to bottom. First of all, from the perspective of the GPU, multiple processes are naturally concurrent, that is, time-division multiplexed. The driver and hardware are responsible for switching tasks in a time slice rotation. Using this layer of mechanism, we can implement limitations on computing resources and video memory resources at the API level to achieve virtualization effects. The API here can be divided into two layers. The first layer is the driver API. This layer of API is close to the driver and is the only way for all upper-layer calls to access the GPU. As long as you control this layer of API, it is equivalent to controlling the user's resource access. Let me mention here that the MPS technology provided by NV can realize spatial division multiplexing, which also provides the possibility for further optimization of business performance. We will expand in detail in the subsequent implementation practice part.
Kernel state solution
The next layer down is the kernel state, whether it is full virtualization or paravirtualization at the virtual machine level, or the container solutions of major cloud vendors in the past two years. System call interception and MMIO hijacking are implemented at the kernel layer. The biggest difficulty in the kernel state is that many registers and MMIO behaviors are not well documented, which requires complex reverse engineering.
Hardware Solution
Below the kernel state is the hardware layer. Real parallelism is guaranteed at this layer, whether it is NV's MIG technology or Baidu Kunlun's SR-IOV technology. The computing power is divided in the hardware logic to achieve true parallelism and space division multiplexing. For example, Kunlun can achieve hardware partitioning of 1/3 and 1/2, and A100 can achieve resource partitioning with a minimum granularity of 1/7.
We have spent a lot of space above introducing you to the challenges and current situation of GPU virtualization. Next, let’s look at how Baidu internally responds to these challenges.
This picture shows Baidu Smart Cloud - dual-engine GPU container virtualization architecture.
Containers are emphasized here because we believe that in the future, AI full-link applications will gradually converge to cloud native platforms to achieve full container development, training, and inference. According to Gartner research, 70% of AI tasks will be deployed in containers in 2023. Baidu's internal containerization started in 2011, and now has more than 10 years of deployment and optimization experience. We are also committed to contributing this part of the product capabilities and optimization experience honed in real life to the community and the majority of users.
Dual engines are also emphasized here. In the overall architecture, we use two sets of isolation engines, user mode and kernel mode, to meet users' different needs for isolation, performance, efficiency and other aspects.
Above the isolation engine is the resource pooling layer. This layer is based on our deep understanding of the software and hardware system and gradually implements the decoupling, remoteness and pooling of AI accelerated resources. It is a pool we build for future infrastructure. abstraction layer.
Above the resource pooling layer is the Matrix/k8s unified resource scheduling layer (Matrix here is the containerized scheduling system in Baidu factory). On top of the scheduling mechanism, we will based on different business scenarios, A variety of mixing strategies are abstracted, including shared mixing, preemptive mixing, time-sharing mixing, tidal mixing, etc. These mixed distribution strategies will be expanded in detail in the subsequent practical part.
Relying on resource isolation and resource scheduling is the full-link scenario of AI business, including model development, model training, and online reasoning.

# Next, I will share with you the implementation of the user-mode and kernel-mode isolation engines respectively.
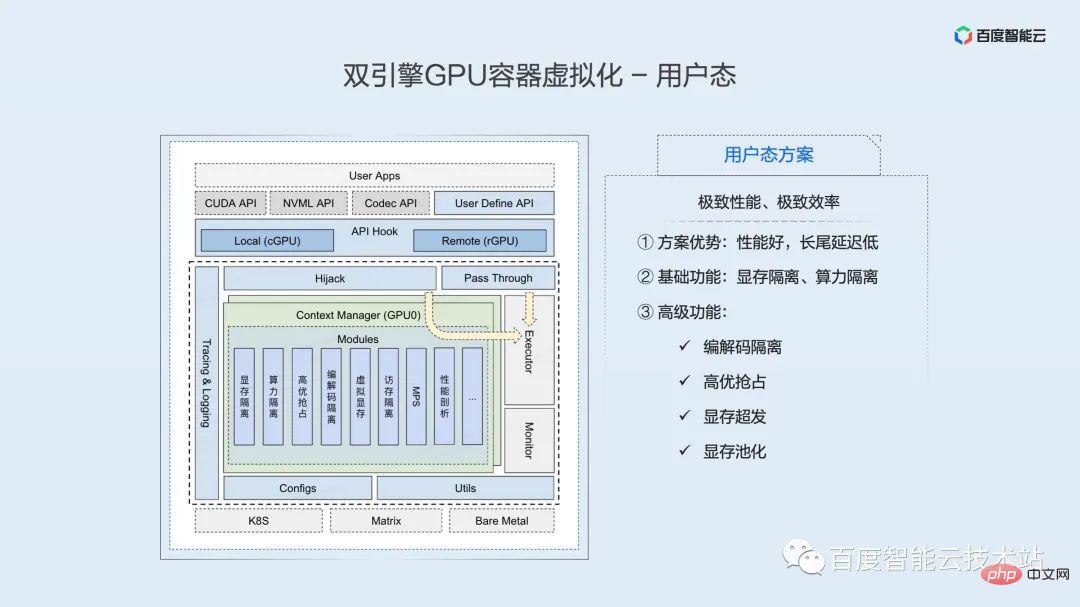
The following figure is a schematic diagram of the core architecture of the user-mode isolation engine. At the top of the architecture diagram is the user application, which includes various commonly used frameworks, such as PaddlePaddle, TensorFlow, PyTorch, etc.
Located under the user application is a series of API Hook interfaces. Based on this set of interfaces, we can realize local use and remote mounting of GPU resources. By replacing the underlying dynamic libraries that the framework relies on, resource control and isolation are achieved. It is important to note that this solution is completely transparent to the application, and the necessary library replacement operations have been automatically completed by the container engine and scheduling part.
The CUDA API will eventually reach the executor through two paths after the Hook. Here, the vast majority of APIs, such as the device management API, do not perform any operations after going through the Hook and directly pass-through to the executor for execution. A small number of APIs related to resource application will go through a layer of interception, through which a series of functions of user-space virtualization can be implemented. The logic of this layer is implemented efficiently enough, and the impact on performance is almost negligible.
Currently, the user-mode isolation engine can provide rich isolation and control functions, including basic video memory isolation and computing power isolation. We have also expanded many advanced features: encoder isolation, high-quality preemption, video memory over-distribution, video memory pooling, etc.
The advantages of the user mode solution are good performance and low long-tail latency. It is suitable for business scenarios that pursue mechanism performance and extreme efficiency, such as delay-sensitive online inference business.
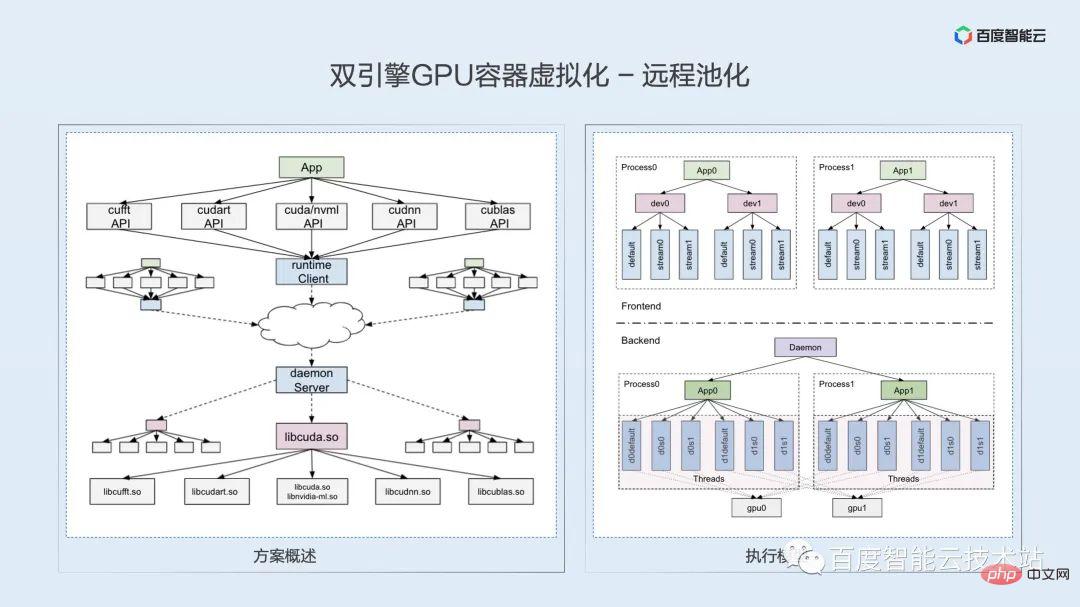
On the basis of isolation, we provide remote functions. The introduction of remote will greatly improve the flexibility of resource configuration and usage efficiency. We will expand on this at the end of this article. .
This sharing is a technology sharing. Here I will use a small amount of space to expand on the key points and difficulties of remote technology, hoping to stimulate everyone's business ideas and technical discussions.
According to the software and hardware technology stack we mentioned in the previous virtualization challenge, remote access to the GPU can generally be implemented at the hardware link layer, driver layer, runtime layer and user layer. However, after in-depth Based on technical analysis and understanding of business scenarios, we believe that the most suitable one at present is the runtime layer.
Determine the runtime layer technical route and how to implement it? What is the point of technology? We think it is mainly a matter of semantic consistency. Based on runtime remoteness, the original local process needs to be split into two processes: client and server. The CUDA runtime is closed source, and the internal implementation logic cannot be explored. How to ensure that the original program logic and API semantics are maintained after splitting the process? Here we use a one-to-one thread model to ensure the logic and semantic alignment within the API.
The difficulty of remote implementation is the problem of numerous APIs. In addition to the libcudart.so dynamic library, the runtime also involves a series of dynamic libraries and APIs such as cuDNN, cuBLAS, and cuFFT, involving thousands of different API interfaces. We use compilation technology to achieve automatic parsing of header files and automatic generation of code, and complete the analysis of hidden APIs through reverse engineering.
Solution to remote solution 0-1 After adaptation, the subsequent backward compatibility is actually relatively easy to solve. At present, it seems that the CUDA API is relatively stable, and new versions only require a small amount of incremental adaptation.
Space division multiplexing and time division multiplexing are mentioned many times above. Here is a detailed explanation:
- Time division multiplexing: As the name suggests, it is multiplexing at the time slice level. This is similar to CPU process scheduling. In a single time slice, only one GPU process is running. Multiple GPU processes run alternately at the micro level and can only be concurrent. This also results in that, within a certain time slice, if the process cannot make good use of computing resources, these computing resources are wasted.
- Space division multiplexing: Different from time division multiplexing, in space division multiplexing, at a certain micro moment, multiple processes can run on a GPU at the same time, as long as the resources of the GPU are not fully used. , the Kernels of other processes can be launched. The Kernels of the two processes are interleaved and run at the micro level, truly realizing parallelism and further utilizing GPU resources.
As introduced in the overview section, currently common virtualization methods, including kernel-state virtualization and NVIDIA vGPU virtualization, are actually time-division multiplexing solutions based on time slice rotation at the bottom level.
NV has launched MPS - a multi-process service solution for multi-process concurrency scenarios. This solution can achieve space division multiplexing and is currently the only solution that takes into account both efficiency and performance.
Here is a brief introduction to MPS. MPS is equivalent to merging the context of two processes into one process. The merged process interweaves the Kernels of the previous two processes together for launch. This has two benefits:
- No need to context switch between processes, which reduces the overhead of context switching.
- At the same time, the kernels of different processes are interleaved, which improves resource space utilization.
Speaking of MPS, we have to mention a shortcoming that has been criticized-fault isolation problem.
How to solve this MPS stability problem? Baidu Intelligent Cloud combines scheduling, container engine, and business keep-alive to propose a complete set of process integration and sharing solutions.
- Realize graceful exit of business processes through kill command redirection
- Realize health check and suspended animation detection through MPS status detection mechanism
- Realize automatic user process through service keep-alive Restart
This solution has covered 90% of commercial (delay-sensitive important services) resources and has been running for more than two years. While providing ultimate performance, I believe it can satisfy the needs of the vast majority of users. Stability needs.
As MPS becomes more and more accepted, NV continues to enhance the stability of MPS. Here is good news in advance. NV will greatly enhance the stability of MPS in the second half of this year, including suspended animation status detection and graceful process exit. These functions will become part of the MPS product, and the stability and ease of use of MPS will be further improved. promote.
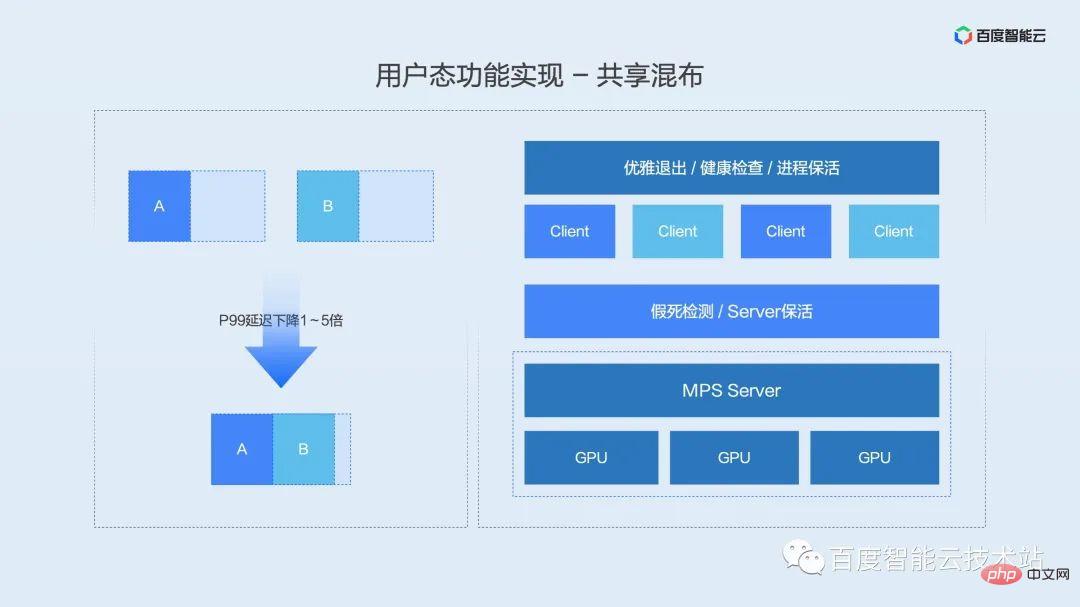
Before introducing the high-quality preemption function, let me first share with you the business scenarios of high-quality preemption. According to our discussions with different users inside and outside the factory, most AI application production environments can be divided into three types of tasks: online, near-line, and offline based on latency sensitivity.
- Online tasks have the highest latency and are generally inference tasks that respond to user requests in real time;
- Nearline tasks are generally batch processing tasks and have no requirements for the delay of a single log. , but the completion time of a batch of data has requirements ranging from hours to minutes;
- Offline tasks have no requirements on delay, only focus on throughput, and are generally model training tasks.
If we define delay-sensitive tasks as high-quality tasks and delay-insensitive near-line and offline tasks as low-quality tasks. And when two types of tasks are mixed, different kernel launch priorities are defined according to different task priorities, which is the high-quality preemption function we mentioned above.
The implementation principle is shown in the figure below. The user-mode isolation engine maintains a logical kernel queue for high-quality tasks and low-quality tasks. When the overall load is low, the two queues are allowed to launch kernels at the same time. At this time, the kernels of the two queues are interleaved and run together. Once the load increases, the hierarchical launch module will immediately wait for the launch of low-quality queues to ensure the execution delay of high-quality tasks.
The advantage of this function is to ensure offline throughput while reducing or even avoiding the impact of online tasks.
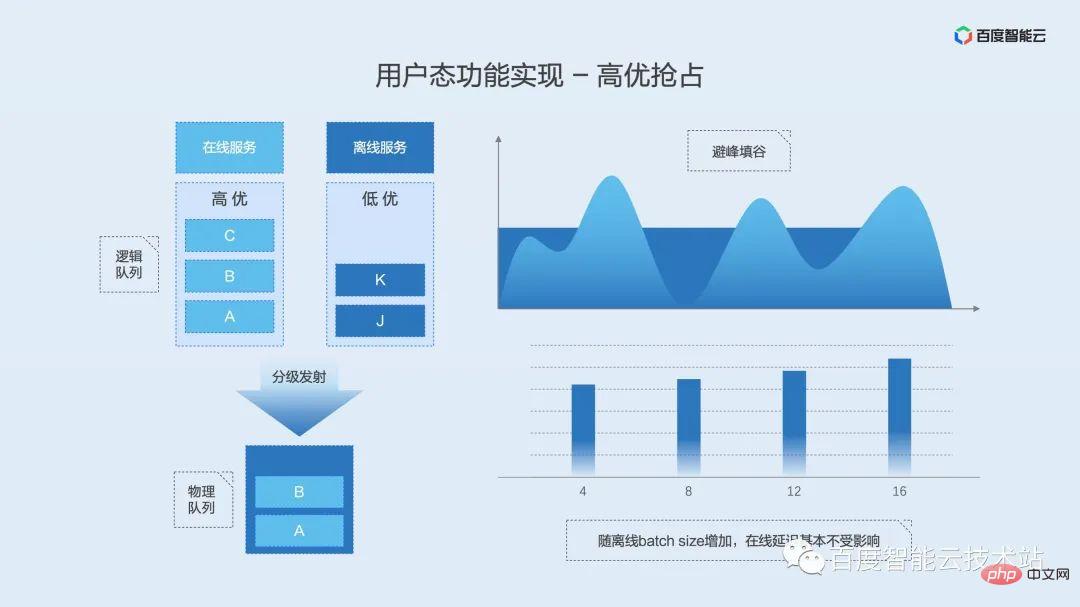
Similarly, we first introduce the definition and scenarios of time-sharing mixing.
Time-sharing mixing is a bit like shared mixing with time slice rotation in the mixing mode. The difference is that time-sharing hybrid distribution does not propose a video memory swap solution for video memory, which comes in handy in scenarios where the video memory is occupied for a long time but the computing power is intermittently used or triggered occasionally. When the process needs computing power, it obtains access rights to the video memory. When the process completes the calculation, it releases the access rights to the video memory, allowing other processes waiting for the permission to get the opportunity to run, so that the intermittent idle GPU resources can be fully utilized.
The core technology of time-sharing mixing is video memory swap. We can compare it to CPU memory swap. When the memory of a certain process is not enough, the system will swap out part of the system memory resources to the disk according to a certain strategy, thereby freeing up space for the running process.
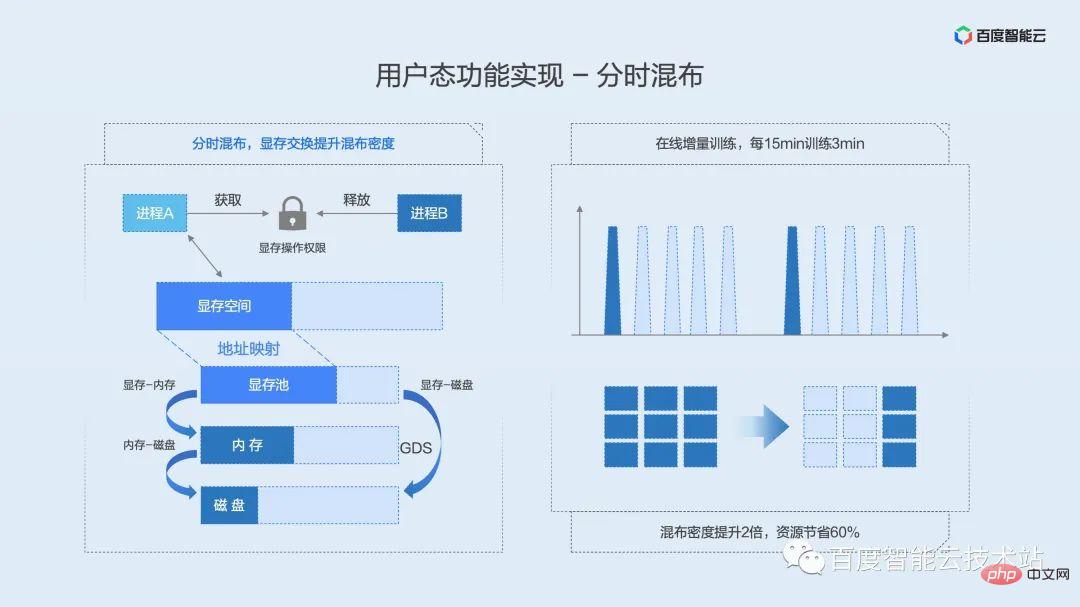
The implementation principle of video memory swap is shown in the figure below. We maintain a video memory pool at the physical address of the video memory, and the upper layer uses resource locks to determine which process has permission to use the GPU. When the process acquires the lock, the video memory will be moved from the memory or disk to the physical video memory pool, and further mapped to the virtual address space for use by the process. When the process releases the lock, the process's virtual memory space is reserved and the physical memory is moved to memory or disk. The lock is mutually exclusive. Only one process can obtain the lock. Other processes are pending on the waiting queue and obtain resource locks in a FIFO manner.
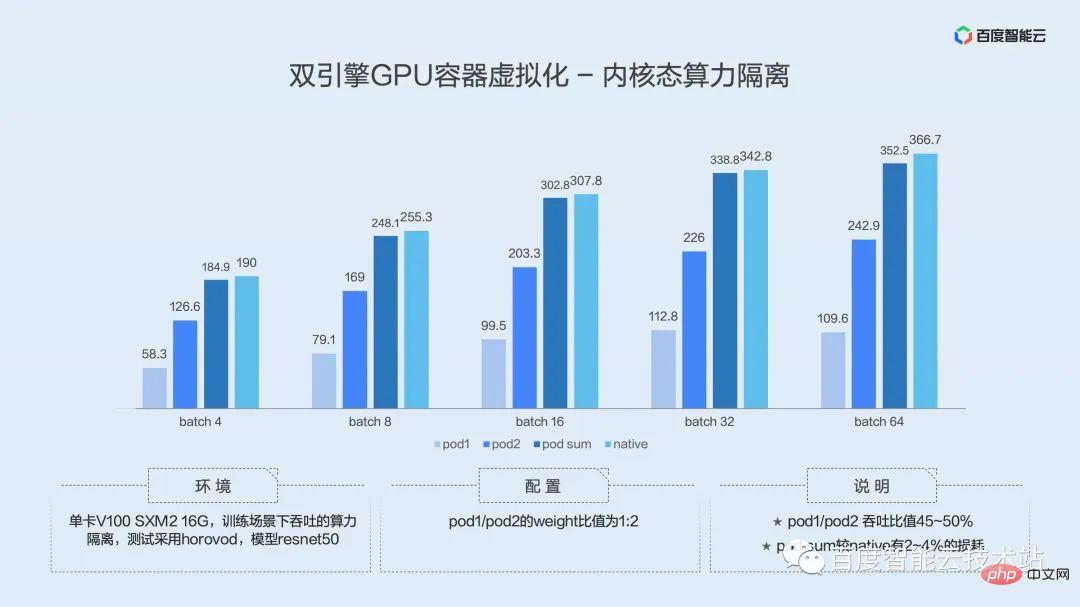
The above introduces the functional implementation of the user-mode isolation engine. In actual applications, how is the performance and what is the impact on users? Here we go directly to the test data.
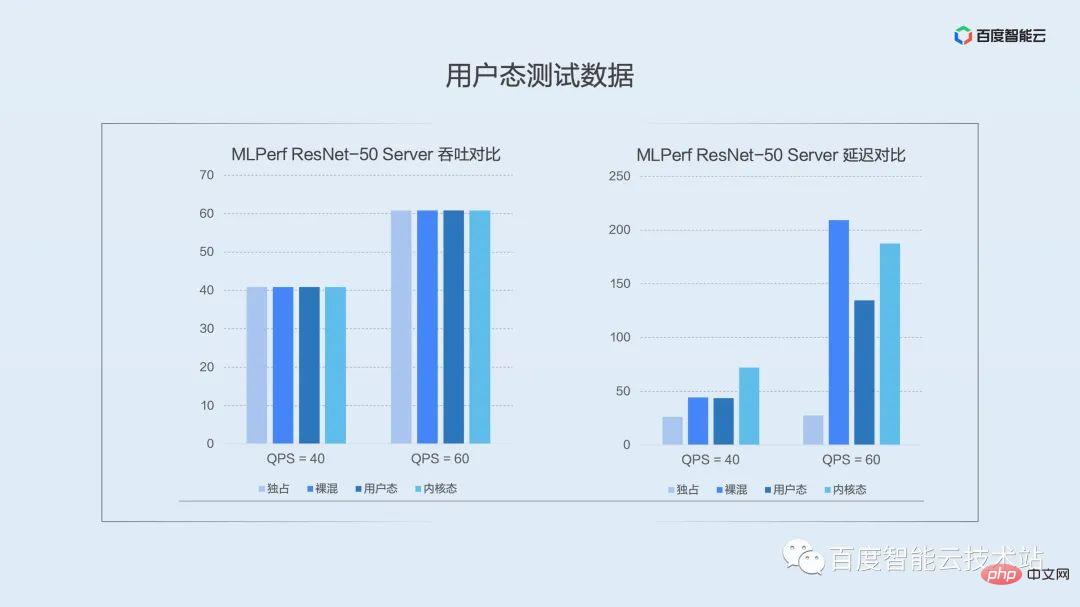
The following figure is the data comparison in the scenario where we selected the typical model ResNet-50 Server on the public test set MLPerf. The columns in the figure represent the performance under exclusive, naked mixed, user-mode isolation, and kernel-mode isolation from left to right.
The picture on the left is a comparison of average throughput. In the inference scenario, requests are triggered intermittently. We can see that no matter which solution can directly reach the pressure value under throughput. I would like to explain here that throughput in inference scenarios cannot demonstrate virtualization performance very well, and you should pay more attention to latency when implementing it in a production environment.
The picture on the right is a comparison of P99 quantile delay. It can be seen that in the user mode under low pressure (QPS = 40), the impact of naked mixing on the long-tail delay is basically the same, while the kernel mode has a slightly greater impact on the long-tail delay due to the use of time division multiplexing. We continue to increase the pressure. When QPS = 60, the advantages of user mode become apparent. Space division multiplexing greatly reduces the impact on long-tail delay. As the pressure further increases, the user-mode process fusion solution is even orders of magnitude better than other hybrid distribution methods.
Although long-tail delay control is not as good as user mode, kernel mode has advantages in terms of isolation, focusing more on scenarios with strong isolation requirements.
Let’s take a look at the technical implementation of the kernel-state isolation engine.
First let’s look at the characteristics of kernel state virtualization implementation, including the following:
Kernel state implementation; good isolation: supports video memory, computing power and fault isolation; MB level isolation of video memory; computing power 1% level allocation; supports P4, V100, T4, A100/A10/A30 and other mainstream GPUs; supports 410 to 510 GPU driver versions; no changes are required to the user mode operating environment; supports containerized deployment.
Different from user-mode implementation, the GPU isolation function of kernel-mode virtualization is implemented in the kernel mode. The left half of the figure below is an architectural diagram of our kernel-state virtualization implementation. From the bottom to the upper layer, they are GPU hardware, kernel layer, and user layer.
The hardware level is our GPU. This GPU can be a bare metal GPU or a transparent GPU.
Underneath the kernel layer is the original driver of the GPU, which actually controls the functions of the GPU. It is this driver that actually operates the GPU. And above the GPU driver is a kernel module for the GPU virtualization we implemented. That is, the GPU interception driver is the yellow part and contains three functions, including memory interception, computing power interception and computing power scheduling. Video memory isolation and computing power isolation are implemented separately.
User layer, first is the interception interface. This interface is provided by the interception module and is divided into two parts: one is the device file interface, and the other is the interface for configuring the interception module. Device files are provided to containers. Let’s look at containers first. Above the container is the application, below is the cuda runtime, and below is the cuda underlying library, including driver api/nvml api, etc. By providing our device file to the container as a fake device file, when the upper layer CUDA accesses it, it will access our device file. This completes the interception of access to the GPU driver by the CUDA underlying library.
Our interception module in the kernel will intercept all accessed system calls, intercept and parse them, and then redirect the real access to the real GPU underlying driver. After the GPU underlying driver completes processing, it returns the result to our interception module, which processes it again, and finally returns the result to the underlying library in the container.
To put it simply, it intercepts the access of the underlying library to the GPU driver by simulating device files, and completes the interception of video memory and computing power through operations such as interception, parsing and injection.
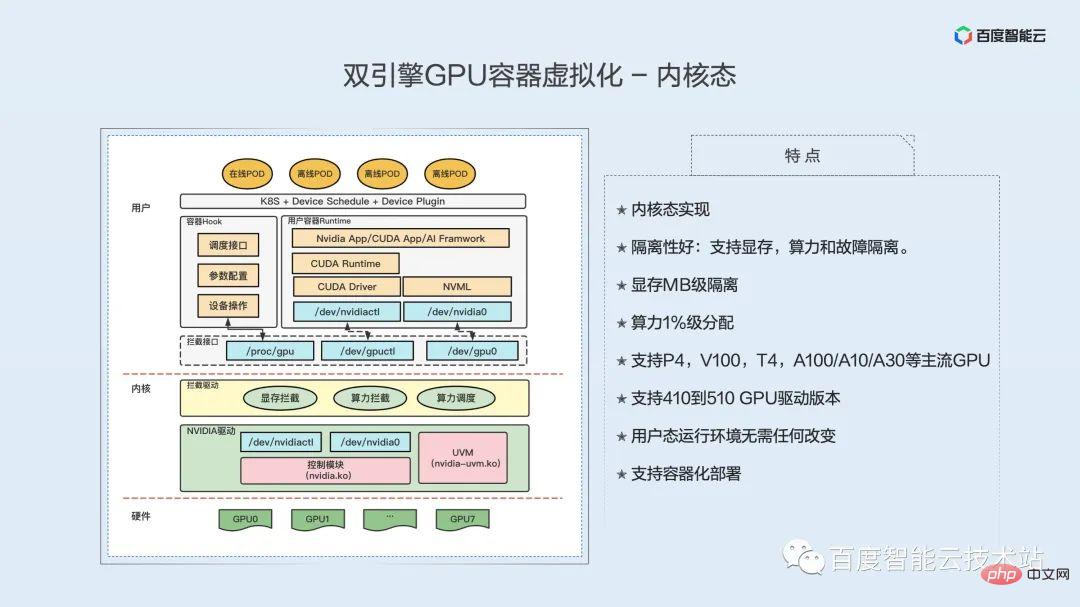
Currently, video memory isolation is achieved by intercepting all video memory-related system calls, which mainly includes video memory information, video memory allocation, and video memory release. Moreover, the current memory isolation can only be set statically and cannot be changed dynamically. While the user mode can support over-development of video memory, the kernel mode cannot support over-development of video memory.
In terms of computing power isolation, relevant information is obtained by intercepting the CUDA Context of the process. The scheduling object is the process-related CUDA Context. The computing resources corresponding to CUDA Context include computing resources (Execution) and memory copy (Copy) resources. Each GPU has one kernel thread that schedules all CUDA Contexts on this GPU.

We have implemented 4 kernel-state computing power scheduling algorithms:
- Fixed Share: Each POD allocates fixed computing power resources, that is The computing power of the entire GPU is fixedly divided into n parts, and each POD is divided into 1/n computing power.
- Equal Share: All active PODs share the computing power resources equally, that is, the number of active PODs is n, and each POD shares 1/n of the computing power.
- Weight Share: Each POD allocates computing power resources according to weight, that is, the computing power of the entire GPU is allocated to each POD according to the weight value. Regardless of whether the POD has a business load, the computing power is allocated according to the weight.
- Burst Weight Share: Active PODs allocate computing power resources according to weights, that is, each POD is assigned a weight value, and active PODs are allocated computing power according to the ratio of weights.

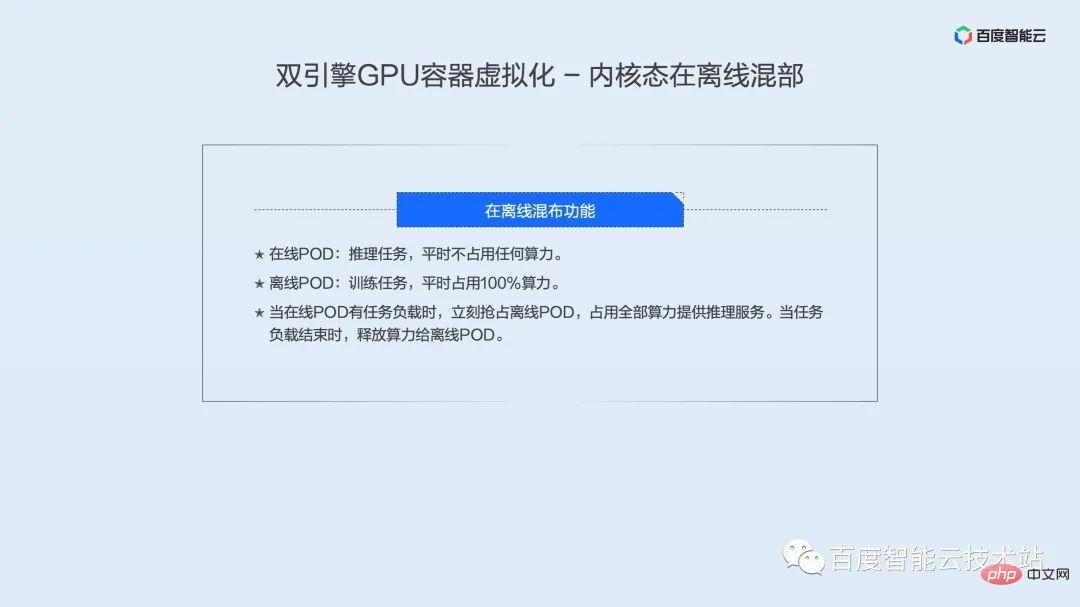
Because the kernel state schedules computing power through time slices, it is not very friendly to delay-sensitive businesses. We have specially developed offline co-location technology. Through co-location of online business and offline business, we can greatly improve the response speed of online business and also allow offline business to share GPU computing resources to achieve the goal of increasing GPU resource utilization. . The characteristics of our offline mixed deployment are:
- Online POD: reasoning tasks, which usually occupy a small amount of computing power.
- Offline POD: training task, which usually takes up most of the computing power.
When the online POD has a task load, it immediately seizes the offline POD and uses all the computing power to provide inference services. When the task load ends, the computing power is released to the offline POD.
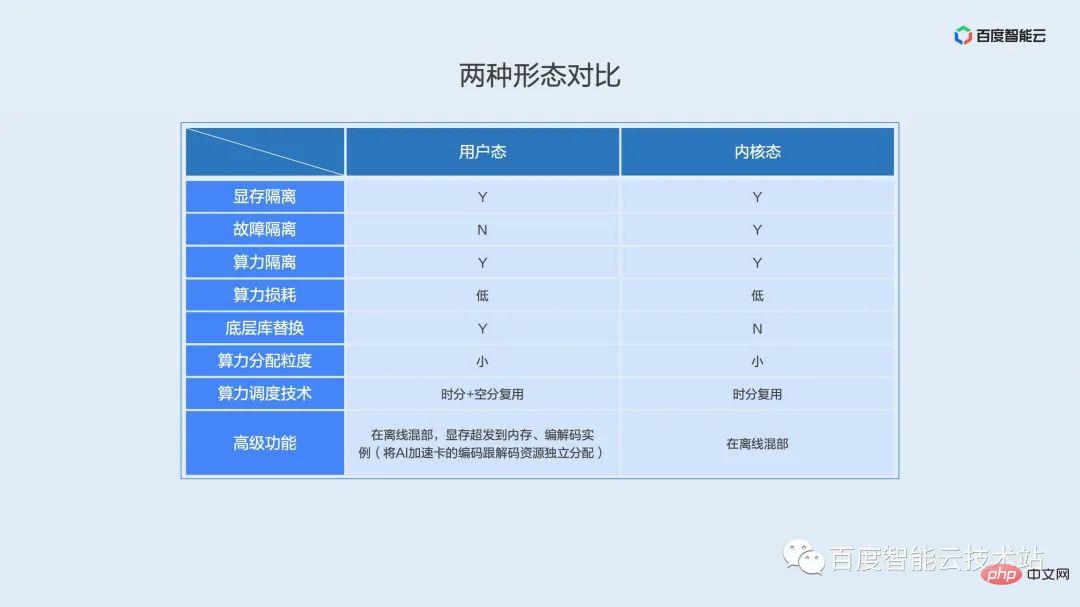
Let’s compare the characteristics of kernel mode and user mode.
In terms of fault isolation, the kernel state has advantages over the user state, and the kernel state does not need to replace the underlying library. User mode computing power scheduling adopts time division plus space division multiplexing, and kernel mode adopts time division multiplexing. Advanced functions in user mode include offline co-location, over-distribution of video memory to memory, encoding and decoding instances (independent allocation of encoding and decoding resources of the AI accelerator card), and we also support offline co-location in kernel mode.
How to use virtualization technology to improve GPU utilization efficiency in AI scenarios. Let’s share the best practices in large-scale AI scenarios based on actual cases in the factory.
Let’s first look at a typical scenario in inference service. Due to the model's own architecture or high service latency requirements, some tasks can only be run in a configuration where the batchsize is very small, or even when the batchsize is 1. This directly leads to long-term low GPU utilization, and even the peak utilization is only 10%.
In this scenario, the first thing that should be thought of is mixing multiple low-utilization tasks.
We summarize this mixing strategy as shared mixing. Whether in development, training, or inference scenarios, we can use shared mixing between multiple low-utilization tasks.
Combined with the process fusion technology mentioned above, it is possible to achieve shared mixing of 2 instances or even multiple instances on the basis of ensuring service delay, and increase resource utilization by more than 2 times.
At the same time, most GPUs have independent encoding and decoding resources. In most scenarios, as shown in the lower left figure, the resource remains idle for a long time. On the basis of shared computing resources, we can mix an encoding or decoding instance to further improve resource performance and activate idle resources.
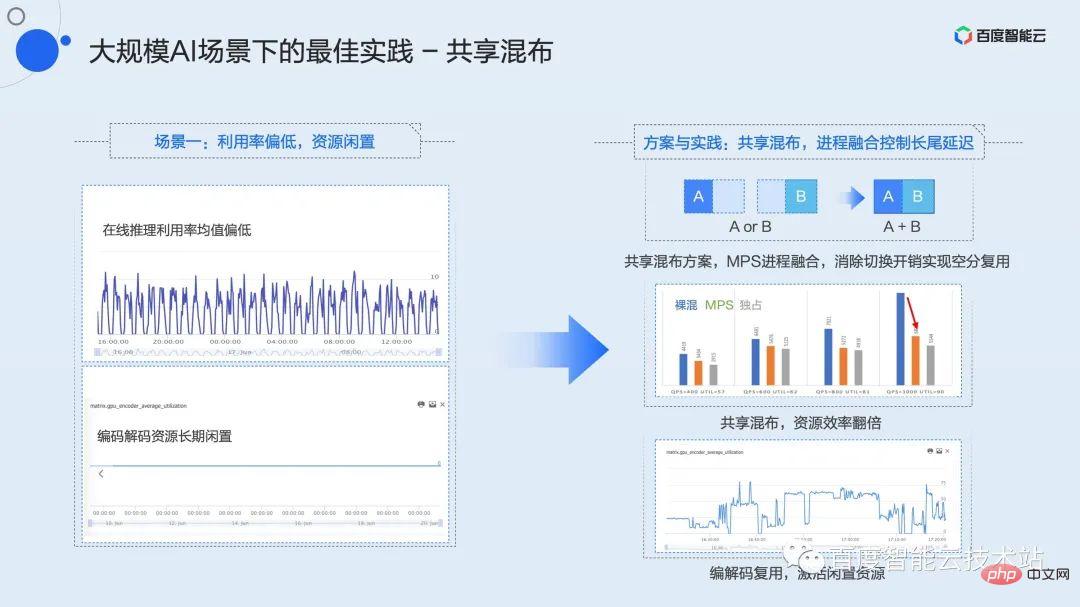
A typical load pattern of the inference service is that there are obvious peak and valley fluctuations throughout the day, and there will be unpredictable short-term traffic surges. This shows that although the peak value is high, the average utilization is very poor, with the average value often being less than 30% or even 20%.
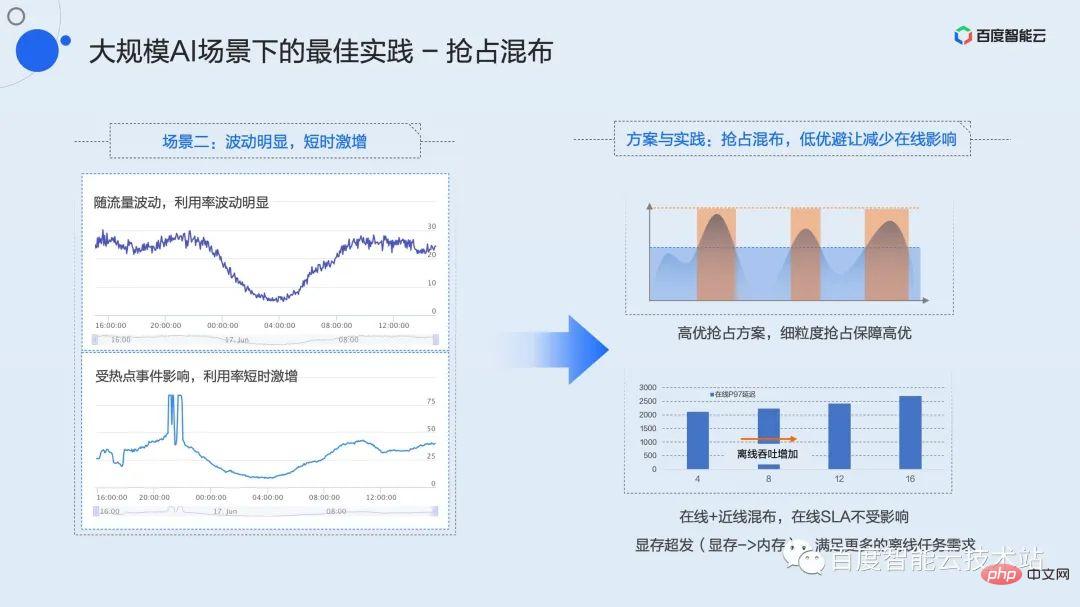
This kind of fluctuation is obvious. How to optimize the efficiency of short-term surge services? We propose a preemptive mixed distribution strategy.
Preemptive mixing is to mix a delay-insensitive low-quality task with a high-quality service that has a high peak value and is sensitive to delay. The high-quality and low-quality here are defined by the user and explicitly declared when applying for resources. In Baidu's internal practice, we define near-line and offline database brushing or training tasks as low-quality. This type of business has certain requirements for throughput and basically no requirements for latency.
Using the high-quality preemption mechanism in the virtualization function, high-quality tasks always have the initiative to occupy resources. When the traffic is at the trough, the load on the entire card is not high, and low-optimal tasks can run normally. Once the traffic is at the peak or there is a short-term surge, the high-optimal preemption mechanism can sense in real time and preempt computing power at the kernel granularity. At this time Low-quality tasks will be flow-limited or even completely pending to ensure the service quality of high-quality tasks.
In this hybrid mode, there may be insufficient video memory, and there may be a lot of redundancy in computing power. For this kind of scenario, we provide an implicit video memory over-send mechanism. Users can use environment variables to over-distribute video memory for low-quality tasks and deploy more instances to ensure that computing power is always available to fill utilization troughs and maximize overall utilization efficiency.
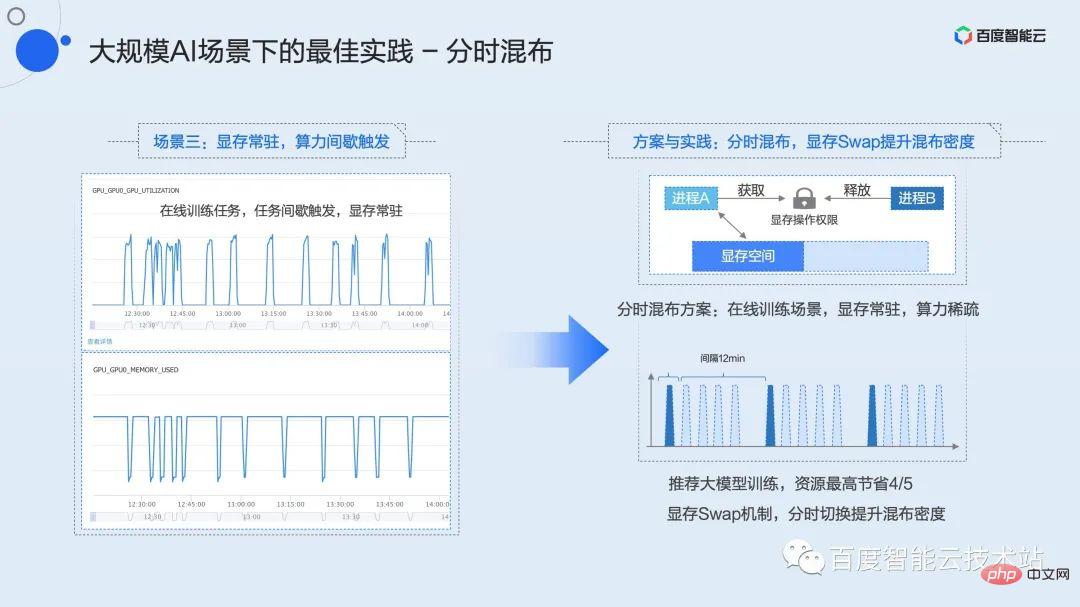
#The third type of business scenario may be familiar to everyone. This is the scenario where the graphics memory is resident and the computing power is intermittently triggered. Typical representative businesses are development tasks and online training.
Here is online training as an example. We know that many models need to be updated online based on daily or even hourly user data, such as recommendation models, which requires online training. Different from offline training where the throughput is full in real time, online training needs to accumulate a batch of data and trigger a training session. Within Baidu, the typical model may be that a batch of data arrives in 15 minutes, but the actual training time is only 2 to 3 minutes. In the remaining time, the training process will reside in the video memory and wait there until the next batch of data arrives from the upstream. During this period, the utilization rate was 0 for a long time, causing a lot of waste of resources.
This type of task cannot use the shared mixing or preemptive mixing mentioned above because the video memory is basically full. Combined with the previously mentioned video memory swap mechanism, we proposed a time-sharing mixing strategy.
Time-sharing mixing is similar to the shared mixing of time slice rotation, but at this time the video memory will also be swapped in and out along with the computing context. Since the underlying virtualization layer cannot sense when the business requires calculation, we maintain a global resource lock for each GPU card. And encapsulates the corresponding C and Python interfaces for users to call. Users only need to apply for this lock when they need to calculate, and the video memory will be automatically swapped into the video memory space from other spaces; after the calculation is completed, the lock will be released, and the corresponding video memory will be swapped out to the memory or disk space. Using this simple interface, users can achieve time-sharing and exclusive use of the GPU for multiple tasks. In online training scenarios, using time-sharing mixing can save up to 4/5 of resources while increasing overall utilization.
The best practices of the three scenarios mentioned above have been verified and implemented on a large scale in Baidu’s internal business. Related functions have also been launched on Baidu Baige·AI heterogeneous computing platform, and you can apply and try it out immediately.
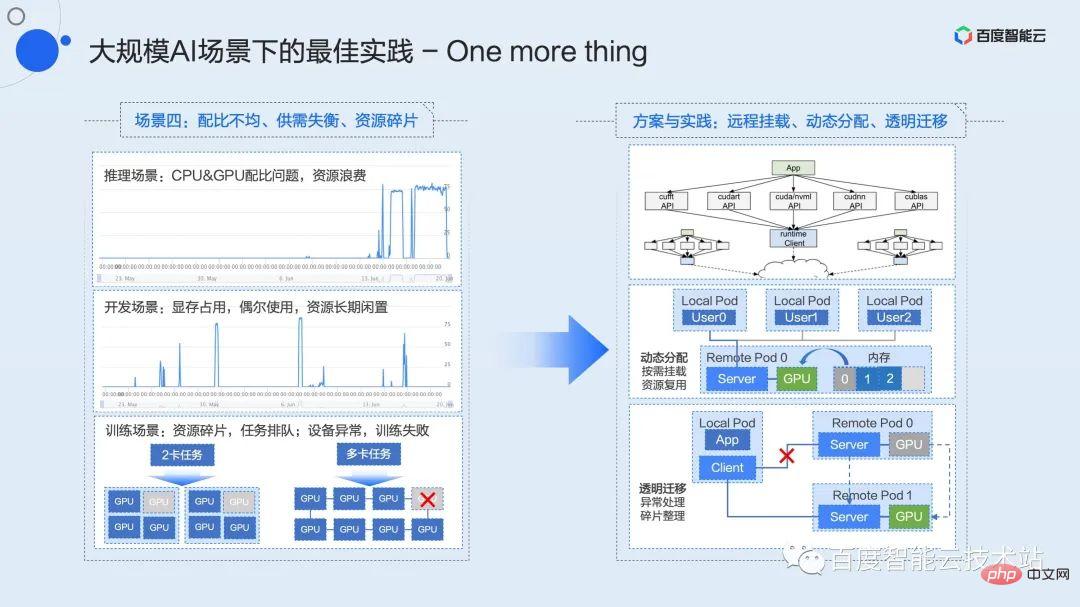
Here I will spend about three minutes talking about the functions that are still under internal verification. These functions will be completed on the Baidu Baige platform in the near future to further solve common configuration problems in large-scale AI scenarios. Problems such as uneven ratio, imbalance of supply and demand, and resource fragmentation.
Students who work on infrastructure will often hear concepts such as resource decoupling and pooling. How to implement the concept of pooling and transform it into actual productivity is what we have been actively exploring and promoting. As early as 2015, we implemented the industry's first hardware pooling solution based on the PCIe Fabric solution, and implemented it on a large scale within Baidu. This is the X-MAN 1.0 mentioned just now (it has now evolved to 4.0). Configure the interconnection between CPU and GPU through the PCIe Fabric network to achieve dynamic allocation of resources and solve the ratio problem in various scenarios. Limited by hardware connections and protocols, this solution can only solve pooling within the cabinet.
Software layer pooling is a technical solution that we think is more flexible. As data center networks continue to upgrade, 100G or even 200G networks will become the standard configuration of infrastructure in the future, and high-speed networks provide a communications highway for resource pooling.
The decoupling and pooling of resources give the business greater flexibility and provide greater room for imagination for performance optimization. For example, the ratio problem between CPU and GPU, the problem of long-term resource occupation supply and demand imbalance in development scenarios and low efficiency, the problem of resource fragmentation task blocking in training scenarios, and the problem of equipment abnormal training restart. Such scenarios can all be solved in pooling and derivative solutions. be resolved.
Finally, all the virtualization technologies and best practices shared above have been launched on Baidu Baige AI heterogeneous computing platform. Search "Baidu Baige" on the official website of Baidu Intelligent Cloud to instantly accelerate AI tasks and stimulate business imagination!
Q & A Featured
Q: General resources are containerized through namespace and cgroup. May I ask what technology the GPU uses to achieve resource control?
A: Namespace and cgroup are both mechanisms provided by the kernel, and essentially rely on the related capabilities provided by the hardware. This does not exist on the current GPU. The GPU is currently and will be closed source for a long time. Only hardware providers can provide these functions that can be upstreamed to the kernel mainline. The current three-party solutions are all non-standard implementations in user mode or kernel mode, and there is currently no way to include them in namespace and cgroup categories. But it can be considered that what GPU virtualization wants to implement is the corresponding mechanism under these interfaces. Whether it can be standardized is another bigger question.
Q: In addition to GPGPU virtualization technology, have we developed NPU-related virtualization technology? Whether to decouple from the NV technology stack. Thanks!
A: I understand that the NPU mentioned here should be Network Processing Unit, which generally refers to all current AI acceleration hardware. We are working on virtualization adaptation of other AI acceleration hardware. The first is the Kunlun core. We have already adapted the virtualization capabilities mentioned above on the Kunlun core. As the scene expands, other mainstream acceleration hardware will continue to be adapted.
Q: Are user mode and kernel mode two different products?
A: It is the same product, with different underlying implementation methods, but the user interface level is unified.
Q: What granularity can user-mode virtualization achieve?
A: The computing power is divided into 1% granularity, and the video memory is divided into 1MB.
Q: Will kernel-mode virtualization cause greater control overhead?
A: Kernel state virtualization is based on time slicing. The overhead here is caused by time slicing. Accurate isolation will inevitably bring about a loss of computing power. If it refers to the overhead caused to application performance, it is true that the kernel mode will be larger than the user mode.
Q: According to the time-division implementation plan, online reasoning feels that the average time of free competition is faster.
A: According to our test results, the order of performance from good to poor is: process fusion, naked mixing (free competition), and hard limit isolation.
Q: Can the two virtualization methods of GPU coexist in a k8s cluster?
A: In terms of mechanism and principle, coexistence is possible. But currently we don’t want the design to be so complicated from a product perspective, so we still keep them separate. If there is widespread demand from subsequent businesses, we will consider launching a similar coexistence solution.
Q: Can you please introduce in detail how to expand the k8s scheduler? Is the agent on the node required to report the GPU topology and total volume?
A: Yes, this requires a stand-alone agent to upload resources (including video memory resources and computing power resources) and topology information.
Q: Do you have any suggestions on the choice of time and space minutes?
A: For delay-sensitive online reasoning tasks, it is recommended to choose a space division solution based on process fusion. For scenarios that require strict isolation, it is recommended to choose a time-sharing solution. There is no difference between the two in other scene selections.
Q: Which CUDA version can the kernel mode support? If NV is updated, how long will the update cycle of Baidu Smart Cloud take?
A: Because the kernel state is virtualized in the kernel, there are no special requirements for the CUDA version. Currently, all CUDA versions are supported. If NV updates CUDA, no special support work is expected.
Q: To use kernel mode, do I need to use a special OS image provided by Baidu Smart Cloud? Dedicated driver?
A: The kernel state does not require Baidu Smart Cloud to provide a dedicated OS image. Currently we support centos7 and ubuntu. But we need to use our own deployment framework to use it. There are no special requirements for container images, and all can be supported transparently.
Q: Is it only available on public cloud? Can it be deployed privately?
A: Both public cloud and private cloud can be deployed and used.
The above is the detailed content of Technical analysis and practice sharing: user mode and kernel mode in dual-engine GPU container virtualization. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology