
Home >Technology peripherals >AI >Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!
Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-23 10:16:071807browse
Since Midjourney released v5, significant improvements have been made in the realism of characters and finger details in generated images, and improvements have also been made in the accuracy of prompt understanding, aesthetic diversity and language understanding. progress.
In contrast, although Stable Diffusion is free and open source, you have to write a long list of prompts every time, and generating high-quality images depends on drawing cards multiple times.

Recently, Stability AI officially announced that Stable Diffusion XL, which is under development, has begun testing for the public and is currently available for free trial on the Clipdrop platform.

Trial link: https://clipdrop.co/stable-diffusion
Emad Mostaque, founder and CEO of Stability AI, said that the model is still in the training stage and will be open sourced after the parameters are stable; SD-XL will perform better in image details such as "handshake", Almost completely controllable.
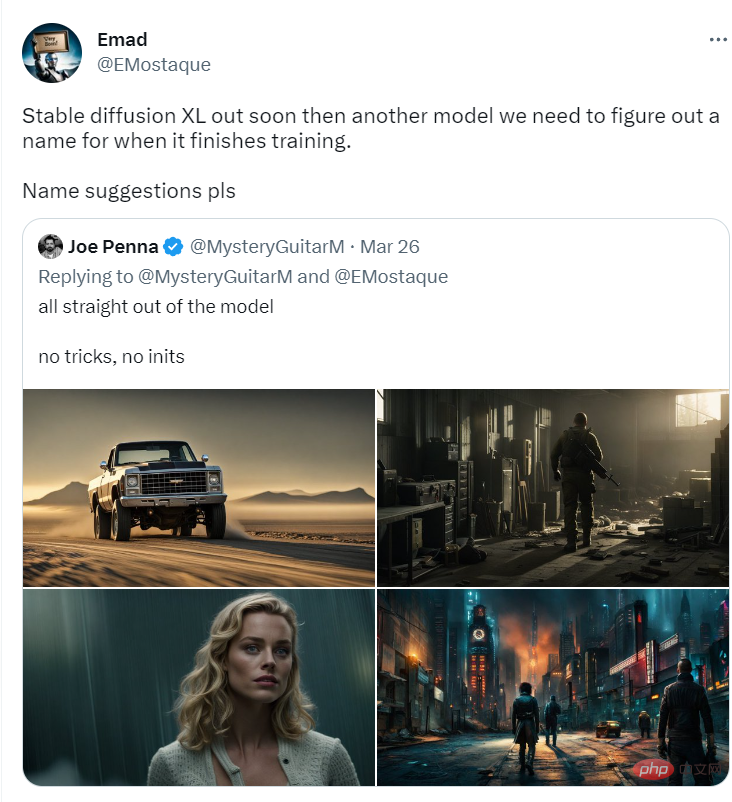
Stable Diffusion XL is not the name of the final release, and it is not v3 because of the architecture of SD-XL and the SD-v2 series The model architecture is very similar.

##Minimalistic home gym with rubber flooring, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mats, high-tech equipment, high detail, organized and efficient.
Simple home gym, rubber floor, wall-mounted TV, weight bench, medicine ball, dumbbells, yoga mat, High-tech equipment, high details, organization and efficiency
# The following examples released by SD-XL officially released, we can see that the quality of the image is already very capable.






SD-XL: Open source version of Midjourney
Officials did not reveal much about the specific information of the Stable Diffusion XL model. At present, we only know that it is a model with a similar architecture to the v2 model, but with a larger scale and parameter count.
SD-v2.1 includes 900 million parameters, and SD-XL has about 2.3 billion parameters. Emad said that the official version may additionally release a smaller distilled version.
The improvements of SD-XL compared to previous versions are as follows:
- Use shorter descriptive prompts to generate high quality Image
- can generate an image that fits the prompt better
- The human body structure in the image is more reasonable
- Compared with v2.1 and v1.5 versions (to a lesser extent), the pictures generated by SD-XL are more in line with public aesthetics
- Negative prompt words (negative prompt) are acceptable Option
- The resulting portrait is more realistic
- The text in the image is clearer
It should be noted that SD-XL may not be compatible with previous versions of plug-ins.
Clear and readable text
In the v1 series and v2.1 version of the Stable Diffusion model, it is not possible to generate it in the image The ability to read text.
While the text information generated by SD-XL is not always accurate, it does provide a huge improvement.

##Photo of a woman sitting in a restaurant holding a menu that says “Menu”
A woman is sitting in a restaurant holding a menu with "Menu" written on it

Photo of a man holding a sign that says “Stable Diffusion”
Stable Diffusion" brand
a young female holding a sign that says "Stable Diffusion", highlights in hair, sitting outside restaurant, brown eyes, wearing a dress , side light
A young woman holding a sign that says "Stable Diffusion" with highlighted hair and brown eyes sits outside a restaurant , wearing a skirt, side lights
Better human anatomy
Stable Diffusion has always had many problems with generating human anatomy , having more legs and fewer arms is a very common problem. It is usually necessary to use the inpaint function to further correct the image details; or use ControlNet's Open Pose function to copy the posture of the human body from the reference image.
For example, when SD-v1.5 generates yoga images, distorted human bodies often appear.

##Photo of a woman in yoga outfit, triangle pose, beach in evening, rim lighting
Photo of a woman in yoga clothing, triangle pose, beach at night, edge lighting Although the images generated by SD-XL are not perfect, they have made significant progress in human posture. For example, with the same house theme, SD-XL This produces photos that are more symmetrical and have better visual effects. The SD-XL also offers significant improvements in portrait photos. ##photo shot of a woman Photo SD-XL can better understand the input prompt and generate more accurate Image. For example, taking duotone (two-color) as an example, SD-v1.5 will only generate black and white images, while SD-XL can generate dual-tone images with multiple colors. The ability to understand prompts has improved compared to the v1 model. duotone portrait of a woman Two-tone portrait #Because SD-XL belongs to the v2 series model, the text model size is larger and the prompt words can be understood better than the v1 model. For example, in the example below, the v1.5 model can never understand the two subjects (robots and humans) in the image, but SD-XL The model can generate normal images (although the robot is still not big enough). big robot friend sitting next to a human, ghost in the shell style, anime wallpaper Big robot friends sitting next to humans Ghost in the Shell style anime wallpaper a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background a young man, with dyed hair Very bright, brown eyes, wearing a white shirt and blue jeans, standing on the beach with a volcano in the background In terms of artistic style, SD-XL has not been significantly improved, and it is different from the previous version. For example, two models generate Edward Hopper-style images from different angles. New York city by Edward Hopper ##New York city by Edward Hopper In Leonid Afmov's style, SD-v1.5 is more accurate, SD-XL lacks unmistakable colorful board brushstrokes. ##New York city by Leonid Afremov In the style of William-Adolphe Bouguereau, both V1.5 and SDXL can generate some similar content, among which SD-XL is closer to the classic academic style created by Bouguereau Painting, and more facial detail.
Portrait of a Beauty Drawn by William-Adolphe Bouguereau Style Shift Issue For example, first generate a photo-style image.
A young man with brightly dyed hair and brown eyes wearing a white shirt and blue jeans is standing on the beach with a volcano in the background After adding a yellow scarf, the image style becomes cartoon style.
##a young man, highlights in hair, brown eyes, A young man with brightly dyed hair and brown eyes wearing a yellow scarf and wearing white shirt and blue jeans, standing on a beach with a volcano as the background #The problem may be caused by a preview issue. It is not known whether the issue can be resolved after the official release. . 
More aesthetic

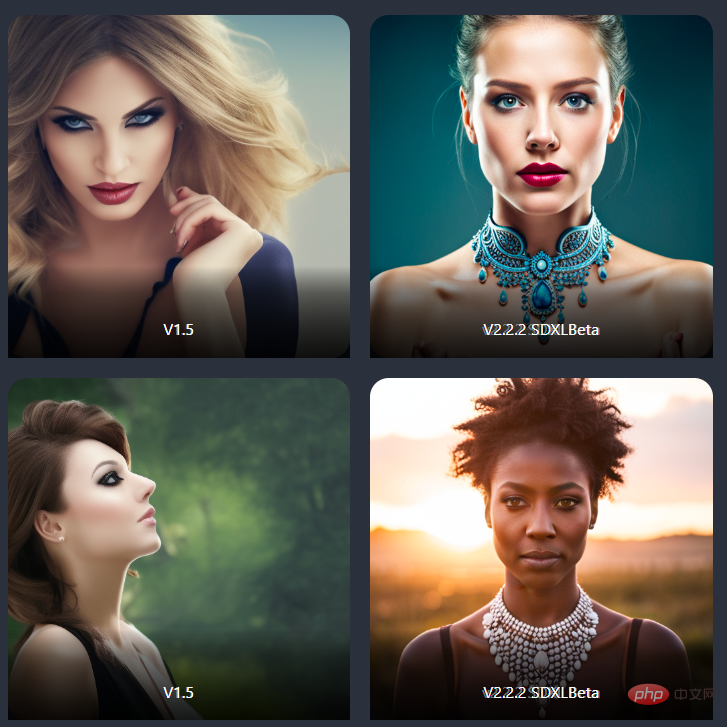
Image that better fits the prompt


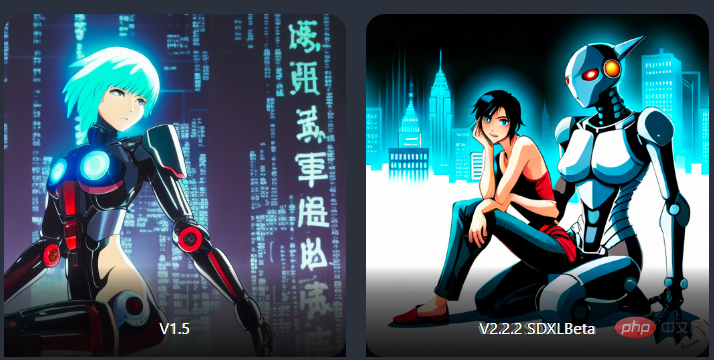

Artistic style


 ##Portrait of beautiful woman by William-Adolphe Bouguereau
##Portrait of beautiful woman by William-Adolphe BouguereauAfter adding some irrelevant keywords, the model The style may change suddenly.
 a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background
a young man, highlights in hair, brown eyes, in white shirt and blue jean on a beach with a volcano in background wearing a yellow scarf,
wearing a yellow scarf,
The above is the detailed content of Stable Diffusion-XL is open for public beta, freeing you from long and cumbersome prompts!. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology