

 Technology peripheralsAIOnly 10% of the parameters are needed to surpass SOTA! Zhejiang University, Byte, and Hong Kong Chinese jointly proposed a new framework for the 'category-level pose estimation' task
Technology peripheralsAIOnly 10% of the parameters are needed to surpass SOTA! Zhejiang University, Byte, and Hong Kong Chinese jointly proposed a new framework for the 'category-level pose estimation' task
Giving robots a 3D understanding of everyday objects is a major challenge in robotics applications.
When exploring in an unknown environment, existing object pose estimation methods are still unsatisfactory due to the diversity of object shapes.

Recently, researchers from Zhejiang University, ByteDance Artificial Intelligence Laboratory and the Chinese University of Hong Kong jointly proposed a new framework for Category-level object shape and pose estimation from a single RGB-D image.

##Paper address: https://arxiv.org/abs/2210.01112
Project link: https://zju3dv.github.io/gCasp
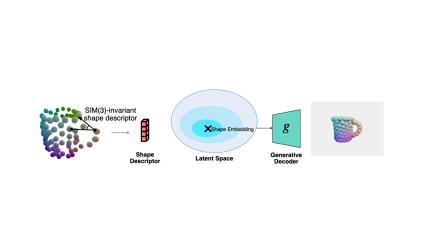
In order to handle the shape changes of objects within categories, researchers Adopting a semantic primitive representation to encode different shapes into a unified latent space, this representation is the key to establishing reliable correspondence between observed point clouds and estimated shapes.
Then by designing a shape descriptor that is invariant to rigid body similarity transformation, the shape and pose estimation of the object are decoupled, thereby supporting any pose. Implicit shape optimization of target objects. Experiments show that the proposed method achieves leading pose estimation performance in public datasets.
Research backgroundIn the field of robot perception and operation, estimating the shape and pose of daily objects is a basic function and has a variety of applications, including 3D scene understanding, robotic operations and autonomous warehousing.
Early work on this task mostly focused on instance-level pose estimation, which mainly obtains the object pose by aligning the observed object with a given CAD model.
However, such a setup is limited in real-world scenarios because it is difficult to obtain an exact model of any given object in advance.
To generalize to unseen but semantically familiar objects, category-level object pose estimation is attracting increasing research attention because it can potentially handle real Various instances of the same category in the scene.

#Existing class-level pose estimation methods usually try to predict the pixel-level normalized coordinates of instances in a class, or use deformed Refer to the prior model to estimate the object pose.
Although these works have made great progress, these one-shot prediction methods still face difficulties when there are large shape differences in the same category.
In order to handle the diversity of objects within the same category, some works utilize neural implicit representation to adapt to the shape of the target object by iteratively optimizing the pose and shape in the implicit space, and Better performance was obtained.
There are two main challenges in class-level object pose estimation. One is the huge intra-class shape difference, and the other is the existing methods that couple shape and pose together. Optimization can easily lead to more complex optimization problems.
In this paper, researchers decouple the shape and pose estimation of objects by designing a shape descriptor that is invariant to rigid body similarity transformations, thereby supporting arbitrary poses Implicit shape optimization of target objects. Finally, the scale and pose of the object are solved based on the semantic association between the estimated shape and the observation.
Algorithm introductionThe algorithm consists of three modules, Semantic primitive extraction, Generative shape estimationandObject pose estimation.

The input of the algorithm is a single RGB-D image. The algorithm uses the pre-trained Mask R-CNN to obtain the semantic segmentation results of the RGB image, and then back-projects the point cloud of each object based on the camera internal parameters. This method mainly processes point clouds and finally obtains the scale and 6DoF pose of each object.
Semantic primitive extraction
DualSDF[1] proposes a representation method of semantic primitives for similar objects. As shown on the left side of the figure below, in the same type of object, each instance is divided into a certain number of semantic primitives, and the label of each primitive corresponds to a specific part of a certain type of object.
In order to extract the semantic primitives of objects from the observation point cloud, the author utilizes a point cloud segmentation network to segment the observation point cloud into semantic primitives with labels.

Generative shape estimation
3D generative model (such as DeepSDF) mostly operates in a normalized coordinate system.
However, there will be a similar pose transformation (rotation, translation and scale) between the object in the real world observation and the normalized coordinate system.
In order to solve the normalized shape corresponding to the current observation when the pose is unknown, the author proposes a shape descriptor that is invariant to similar transformations based on semantic primitive representation.
This descriptor is shown in the figure below, which describes the angle between vectors composed of different primitives:
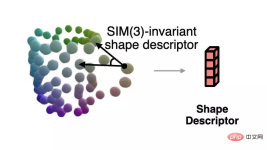
The author uses this descriptor to measure the error between the current observation and the estimated shape, and uses gradient descent to make the estimated shape more consistent with the observation. The process is shown in the figure below.
The author also shows more shape optimization examples.

Pose estimation
Finally, by observing the point cloud and solving the semantic origin between the shapes Based on the language correspondence, the author uses the Umeyama algorithm to solve the pose of the observed shape.

Experimental results
The author is on the REAL275 (real data set) and CAMERA25 (synthetic data set) data sets provided by NOCS Comparative experiments were conducted to compare the pose estimation accuracy with other methods. The proposed method far exceeded other methods in multiple indicators.
At the same time, the author also compared the amount of parameters that need to be trained on the training set provided by NOCS. The author requires a minimum of 2.3M parameters to reach the state-of-the-art level.

The above is the detailed content of Only 10% of the parameters are needed to surpass SOTA! Zhejiang University, Byte, and Hong Kong Chinese jointly proposed a new framework for the 'category-level pose estimation' task. For more information, please follow other related articles on the PHP Chinese website!

 Excel TRANSPOSE FunctionApr 22, 2025 am 09:52 AM
Excel TRANSPOSE FunctionApr 22, 2025 am 09:52 AMPowerful tools in Excel data analysis and processing: Detailed explanation of TRANSPOSE function Excel remains a powerful tool in the field of data analysis and processing. Among its many features, the TRANSPOSE function stands out for its ability to reorganize data quickly and efficiently. This feature is especially useful for data scientists and AI professionals who often need to reconstruct data to suit specific analytics needs. In this article, we will explore the TRANSPOSE function of Excel in depth, exploring its uses, usage and its practical application in data science and artificial intelligence. Learn more: Microsoft Excel Data Analytics Table of contents In Excel
 How to Install Power BI DesktopApr 22, 2025 am 09:49 AM
How to Install Power BI DesktopApr 22, 2025 am 09:49 AMGet Started with Microsoft Power BI Desktop: A Comprehensive Guide Microsoft Power BI is a powerful, free business analytics tool enabling data visualization and seamless insight sharing. Whether you're a data scientist, analyst, or business user, P
 Graph RAG: Enhancing RAG with Graph Structures - Analytics VidhyaApr 22, 2025 am 09:48 AM
Graph RAG: Enhancing RAG with Graph Structures - Analytics VidhyaApr 22, 2025 am 09:48 AMIntroduction Ever wondered how some AI systems seem to effortlessly access and integrate relevant information into their responses, mimicking a conversation with an expert? This is the power of Retrieval-Augmented Generation (RAG). RAG significantly
 SQL GRANT CommandApr 22, 2025 am 09:45 AM
SQL GRANT CommandApr 22, 2025 am 09:45 AMIntroduction Database security hinges on managing user permissions. SQL's GRANT command is crucial for this, enabling administrators to assign specific access rights to different users or roles. This article explains the GRANT command, its syntax, c
 What is Python IDLE?Apr 22, 2025 am 09:43 AM
What is Python IDLE?Apr 22, 2025 am 09:43 AMIntroduction Python IDLE is a powerful tool that can easily develop, debug and run Python code. Its interactive shell, syntax highlighting, autocomplete and integrated debugger make it ideal for programmers of all levels of experience. This article will outline its functions, settings, and practical applications. Overview Learn about Python IDLE and its development benefits. Browse and use the main components of the IDLE interface. Write, save, and run Python scripts in IDLE. Use syntax highlighting, autocomplete and intelligent indentation. Use the IDLE integrated debugger to effectively debug Python code. Table of contents
 Python & # 039: S maximum Integer ValueApr 22, 2025 am 09:40 AM
Python & # 039: S maximum Integer ValueApr 22, 2025 am 09:40 AMPython: Mastering Large Integers – A Comprehensive Guide Python's exceptional capabilities extend to handling integers of any size. While this offers significant advantages, it's crucial to understand potential limitations. This guide provides a deta
 9 Free Stanford AI CoursesApr 22, 2025 am 09:35 AM
9 Free Stanford AI CoursesApr 22, 2025 am 09:35 AMIntroduction Artificial intelligence (AI) is revolutionizing industries and unlocking unprecedented possibilities across diverse fields. Stanford University, a leading institution in AI research, provides a wealth of free online courses to help you
 What is Meta's Segment Anything Model(SAM)?Apr 22, 2025 am 09:25 AM
What is Meta's Segment Anything Model(SAM)?Apr 22, 2025 am 09:25 AMMeta's Segment Anything Model (SAM): A Revolutionary Leap in Image Segmentation Meta AI has unveiled SAM (Segment Anything Model), a groundbreaking AI model poised to revolutionize computer vision and image segmentation. This article delves into SAM


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Dreamweaver Mac version
Visual web development tools

