
Home >Database >Mysql Tutorial >Example analysis of MySQL index creation principles
Example analysis of MySQL index creation principles

- 王林forward
- 2023-04-17 17:01:031104browse
1. Suitable for creating indexes
1. The value of the field has uniqueness restrictions
According to Alibaba specifications, it indicates that it has business requirements Fields with unique characteristics, even combined fields, must be uniquely indexed.

For example, the student number in the student table is a unique field. Creating a unique index for this field can quickly query the information of a certain student. If you use the name If so, there may be the same name, which will slow down the query speed.
2. Fields that are frequently used as Where query conditions
If a field is often used in the Where condition of the Select statement, then you need to create an index for this field, especially if the amount of data is large. In this case, creating a common index can greatly improve query efficiency.
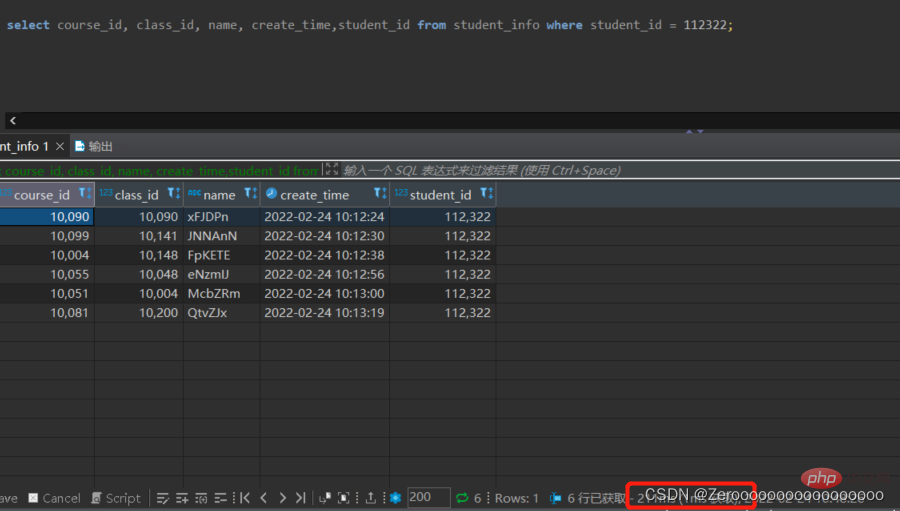
For example, the test table student_info has 1 million data. Assume that the user information of student_id=112322 is queried. If no index is created on the student_id field, the query results are as follows:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
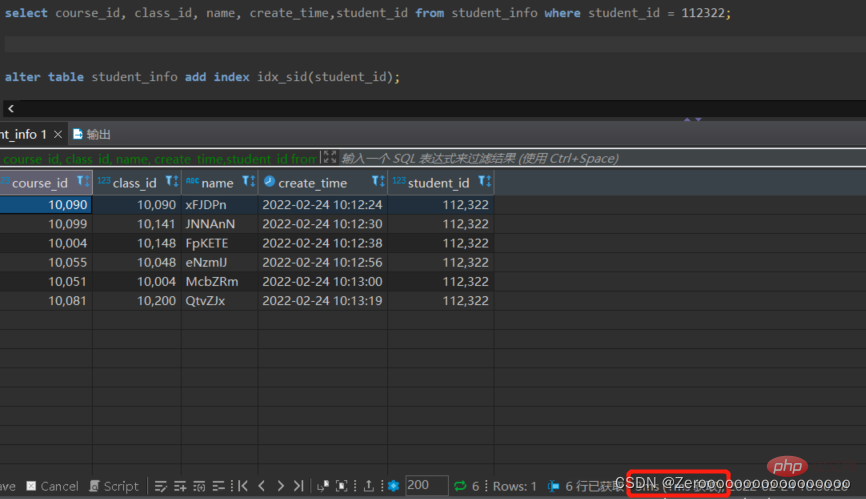
After creating an index for student_id, the query results are as follows:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
3. Often Group by and Order by columns
The index is to make the data according to a certain Therefore, when using Group by to group query data or Order by to sort data, you need to index the grouped or sorted fields. If there are multiple columns to be sorted, a combined index can be built on these columns.
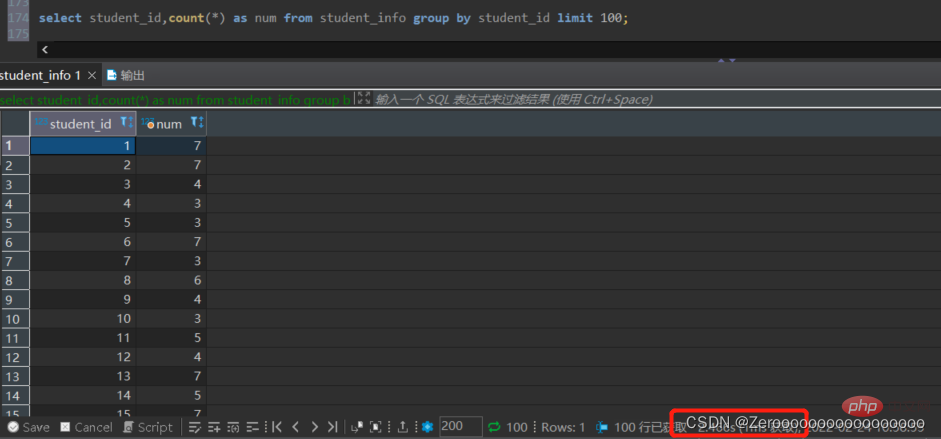
For example, group the courses selected by students according to student_id, display different student_id and the number of courses, and display 100 items. If you do not create an index for student_id, the query results are as follows:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
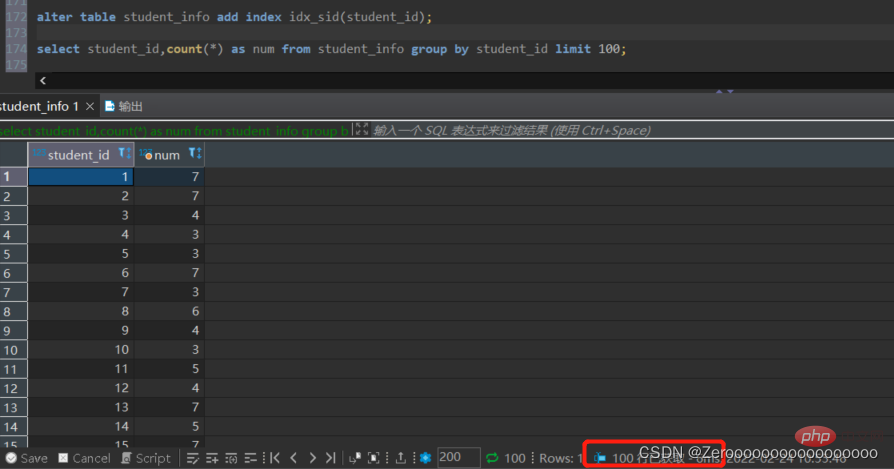
After creating an index for student_id, the query results are as follows:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
For query statements that include both group by and order by, it is recommended to establish a joint index and put the fields in group by in front of the order by field to meet the "leftmost prefix matching principle" , so that the utilization rate of the index will be high, and the efficiency of natural query will also be high; at the same time, versions after 8.0 support descending indexes. If the fields after order by are in descending order, you can consider directly creating a descending index, which will also improve query efficiency. .
4. Where condition column of Update and Delete
Query the data according to a certain condition and then perform the Update or Delete operation. If an index is created for the Where field, Can reply to improve efficiency. The reason is that this record needs to be retrieved based on the Where condition column first, and then updated or deleted. If the updated fields are non-index fields when updating, the efficiency improvement will be more obvious. This is because the update of index fields does not require maintenance.
For example, if the name field in the student_info table is sdfasdfas123123, the student_id is modified to 110119. Without indexing the name field, the execution situation is as follows:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
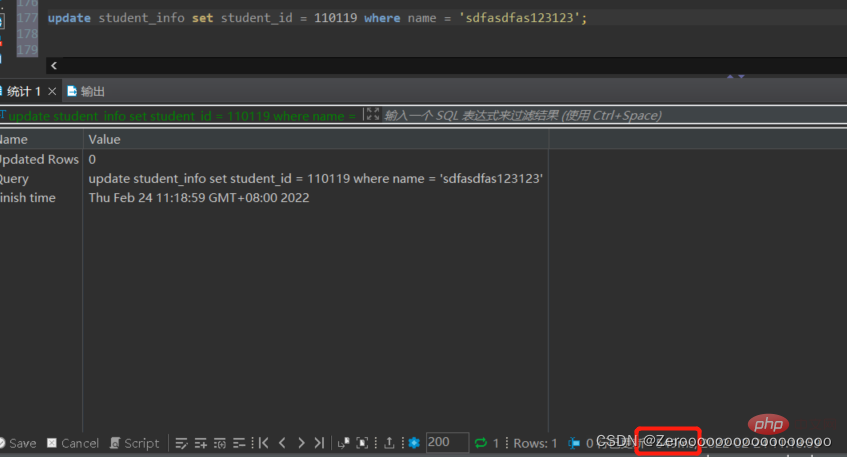
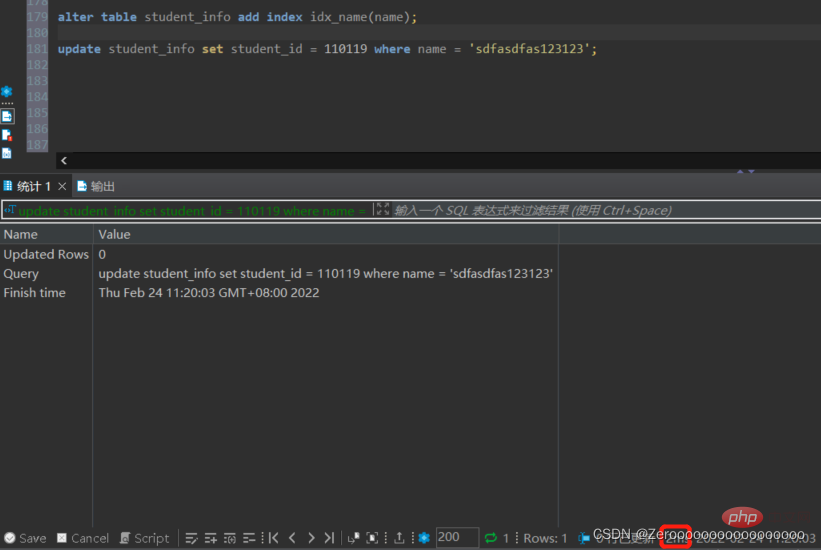
After adding the index, the execution situation is as follows:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
5. Distinct fields need to create indexes
Sometimes it is necessary to delete a certain field If you use Distinct, creating an index for this will also improve query efficiency.
For example, query the different student_ids in the course schedule. If no index is created for student_id, the execution situation is as follows:
select distinct(student_id) from student_id;#花费2ms
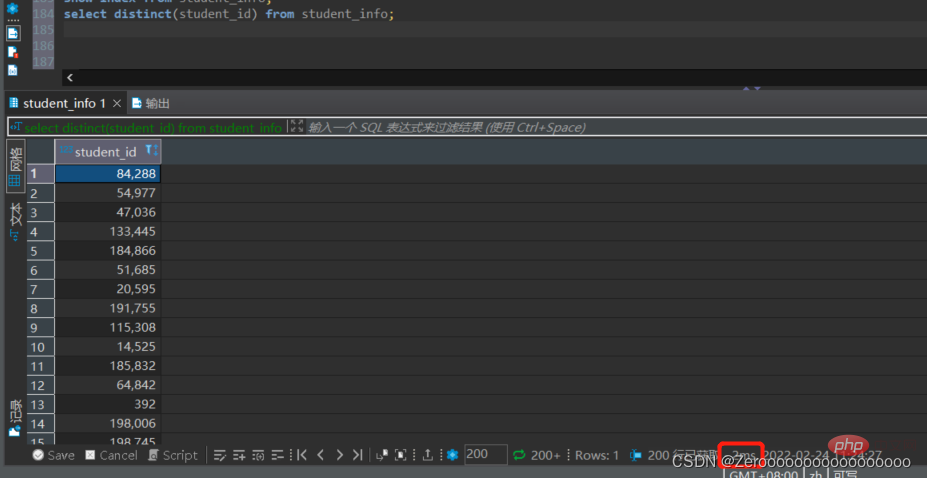
After the index is created, the execution situation As follows:
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms
6. When creating a multi-table Join connection operation, things to note when creating an index
First of all, the amount of data in the connected table should not exceed 3, because each additional table is equivalent to A nested loop is added, and the order of magnitude increases very quickly, seriously affecting query efficiency. Secondly, create an index for the Where condition, because Where is the filter for data conditions. If the amount of data is very large, it will be very scary if there is no Where condition for filtering. Finally, create an index for the connected fields, and change the fields again. The types in multiple tables must be consistent.

For example, if you create an index only for student_id, the query results are as follows:
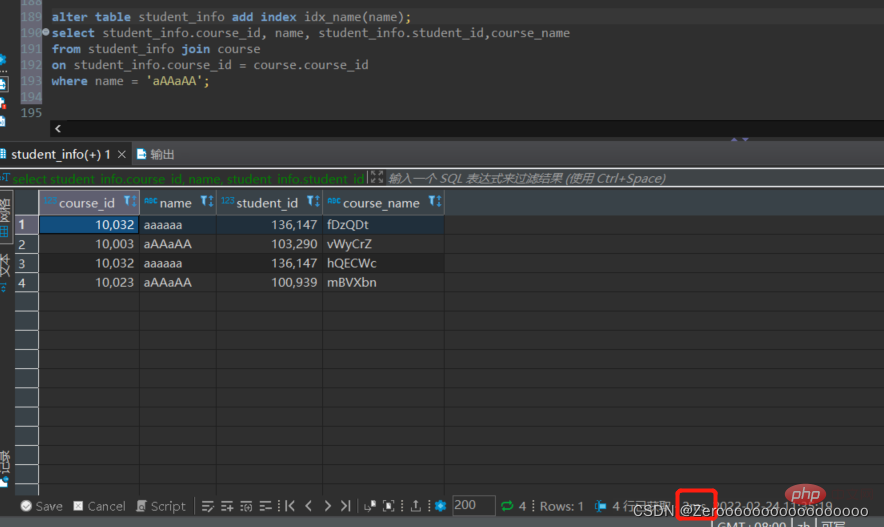
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
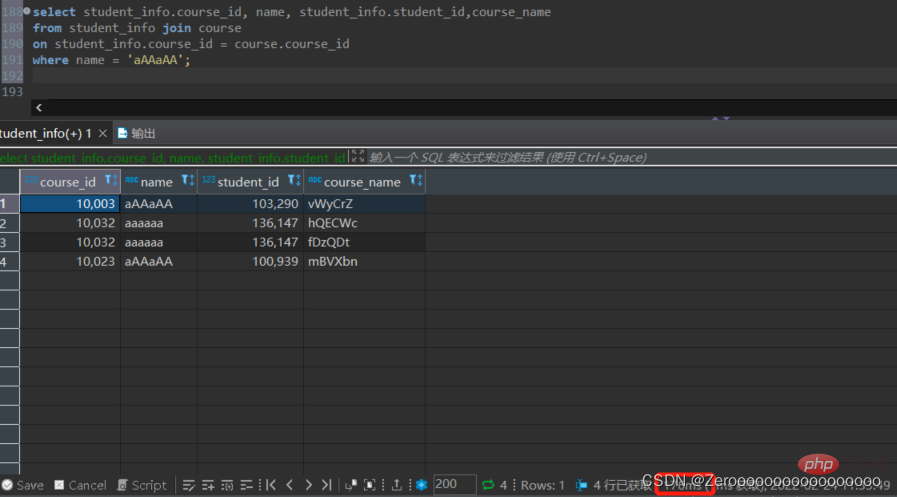
After creating an index for the name field, The query results are as follows:
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9. Do not define redundant or duplicate indexes
The above is the detailed content of Example analysis of MySQL index creation principles. For more information, please follow other related articles on the PHP Chinese website!