
Home >Technology peripherals >AI >Huawei's young genius Xie Lingxi: Personal views on the development of the field of visual recognition
Huawei's young genius Xie Lingxi: Personal views on the development of the field of visual recognition

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-17 11:52:021354browse
Recently, I have participated in several high-intensity academic activities, including the closed-door seminar of the CCF Computer Vision Committee and the VALSE offline conference. After communicating with other scholars, I came up with many ideas, and I hope to sort them out for reference by myself and my colleagues. Of course, limited by personal level and research scope, there will definitely be many inaccuracies or even errors in the article. Of course, it is impossible to cover all important research directions. I look forward to communicating with interested scholars to flesh out these perspectives and better explore future directions.
In this article, I will focus on analyzing the difficulties and potential research in the field of computer vision, especially in the direction of visual perception (i.e., recognition) direction. Rather than improving the details of specific algorithms, I would rather explore the limitations and bottlenecks of current algorithms (especially the pre-training fine-tuning paradigm based on deep learning), and draw preliminary developmental conclusions from this, including which issues are important. , which issues are unimportant, which directions are worthy of advancement, which directions are less cost-effective, etc.
#Before I start, I first draw the following mind map. In order to find a suitable entry point, I will start with the difference between computer vision and natural language processing (the two most popular research directions in artificial intelligence), and introduce three fundamental properties of image signals: information sparsity, inter-domain diversity, infinite granularity, and correspond them to several important research directions. In this way, we can better understand the status of each research direction: what problems it has solved and what important problems have not been solved, and then analyze future development trends in a targeted manner.
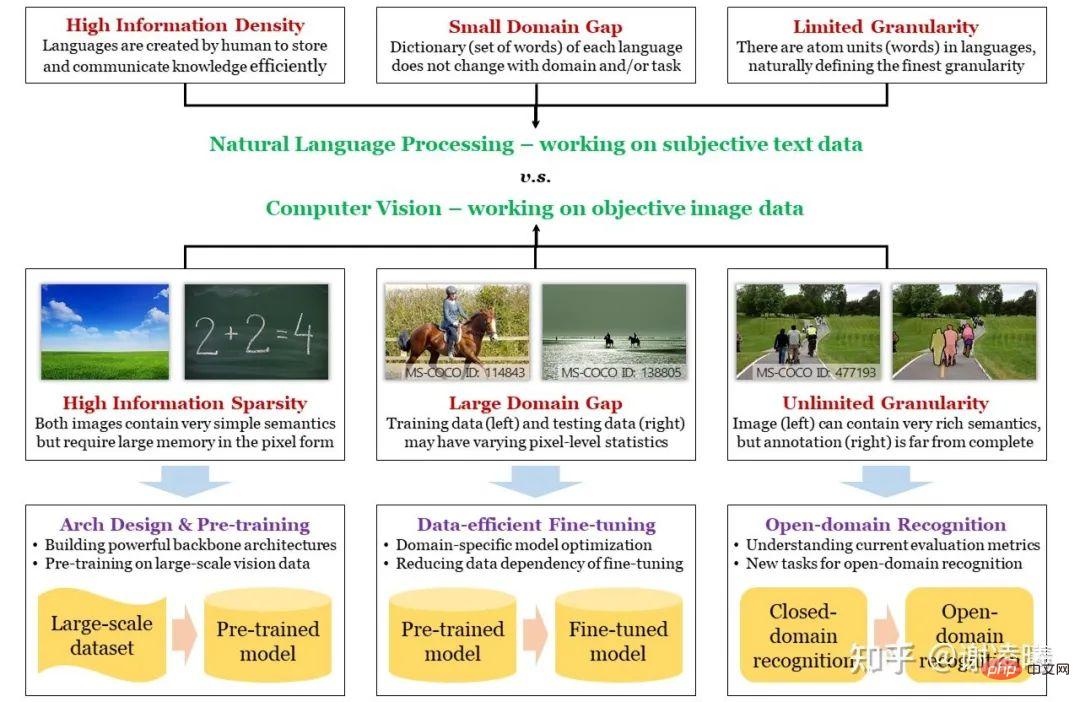
Map: The difference between CV and NLP, the three major challenges of CV and how to deal with them
Three basic difficulties of CV and corresponding research directions
NLP has always been ahead of CV. Whether deep neural networks surpass manual methods or pre-trained large models begin to show a trend of unification, these things first happened in the NLP field and were soon moved to the CV field. The essential reason here is that NLP has a higher starting point: the basic unit of natural language is words, while the basic unit of images is pixels; the former has natural semantic information, while the latter may not be able to express semantics. Fundamentally speaking, natural language is a carrier created by humans to store knowledge and communicate information, so it must have the characteristics of high efficiency and high information density; while images are optical signals captured by humans through various sensors, which can objectively It reflects the real situation, but accordingly does not have strong semantics and the information density may be very low. From another perspective, the image space is much larger than the text space, and the structure of the space is also much more complex. This means that if you want to sample a large number of samples in space and use these data to characterize the distribution of the entire space, the sampled image data will be many orders of magnitude larger than the sampled text data. By the way, this is also the essential reason why natural language pre-training models are better than visual pre-training models - we will mention this later.
#According to the above analysis, we have introduced the first basic difficulty of CV through the difference between CV and NLP, which is semantic sparsity. The other two difficulties, inter-domain differences and infinite granularity, are somewhat related to the above-mentioned essential differences. It is precisely because semantics are not taken into account when sampling images that when sampling different domains (i.e. different distributions, such as day and night, sunny and rainy days, etc.), the sampling results (i.e. image pixels) are strongly related to domain characteristics, resulting in domain differences between. At the same time, because the basic semantic unit of an image is difficult to define (while text is easy to define), and the information expressed by the image is rich and diverse, humans can obtain almost infinitely fine semantic information from the image, far beyond any current CV field. The ability defined by this evaluation index is infinite granularity. Regarding infinite granularity, I once wrote an article specifically discussing this issue. https://zhuanlan.zhihu.com/p/376145664
## Taking the above three basic difficulties as a guide, we summarize the research directions of the industry in recent years as follows:
- Semantic sparsity: The solution is to build efficient computing models (neural networks) and visual pre-training. The main logic here is that if you want to increase the information density of the data, you must assume and model the non-uniform distribution of the data (information theory) (that is, learn the prior distribution of the data). Currently, there are two types of most efficient modeling methods. One is to use neural network architecture design to capture data-independent prior distributions (for example, the convolution module corresponds to the local prior distribution of image data, and the transformer module corresponds to the image data. attention prior); one is to capture the data-related prior distribution through pre-training on large-scale data. These two research directions are also the most basic and the most concerned in the field of visual recognition.
- Differences between domains: The solution is a data-efficient fine-tuning algorithm. According to the above analysis, the larger the network size and the larger the pre-training data set, the stronger the prior stored in the calculation model. However, when there is a large difference in the data distribution between the pre-training domain and the target domain, this strong prior will bring disadvantages, because information theory tells us: increasing the information density of certain parts (pre-training domain) will definitely Reduce the information density of other parts (parts not included in the pre-training domain, that is, parts considered unimportant during the pre-training process). In reality, the target domain is likely to fall partially or entirely in the uninvolved part, resulting in poor direct transfer of the pre-trained model (i.e., overfitting). At this time, it is necessary to adapt to the new data distribution by fine-tuning in the target domain. Considering that the data volume of the target domain is often much smaller than that of the pre-training domain, data efficiency is an essential assumption. Furthermore, from a practical perspective, models must be able to adapt to changing domains, so lifelong learning is a must.
- Unlimited granularity: The solution is an open domain recognition algorithm. Infinite granularity includes open domain features and is a higher pursuit goal. Research in this direction is still preliminary, especially since there are no generally accepted open domain recognition data sets and evaluation indicators in the industry. One of the most essential issues here is how to introduce open domain capabilities into visual recognition. The good news is that with the emergence of cross-modal pre-training methods (especially CLIP in 2021), natural language is getting closer and closer to becoming the tractor of open domain recognition. I believe this will be the mainstream direction in the next 2-3 years. . However, I do not agree with the various zero-shot recognition tasks that have emerged in the pursuit of open domain recognition. I think zero-shot itself is a false proposition. There is no zero-shot identification method in the world and there is no need for it. Existing zero-shot tasks all use different methods to leak information to the algorithm, and the leakage methods vary widely, making it difficult to make a fair comparison between different methods. In this direction, I propose a method called on-demand visual recognition to further reveal and explore the infinite granularity of visual recognition.
An additional explanation is needed here. Due to differences in data space size and structural complexity, at least so far, the CV field cannot directly solve the problem of inter-domain differences through pre-trained models, but the NLP field is close to this point. Therefore, we have seen NLP scholars use prompt-based methods to unify dozens or hundreds of downstream tasks, but the same thing has not happened in the CV field. In addition, the essence of scaling law proposed in NLP is to use a larger model to overfit the pre-training data set. In other words, for NLP, overfitting is no longer a problem, because the pre-training data set combined with small prompts is enough to represent the distribution of the entire semantic space. However, this has not been achieved in the CV field, so domain migration also needs to be considered, and the core of domain migration is to avoid overfitting. In other words, in the next 2-3 years, the research focus of CV and NLP will be very different. Therefore, it is very dangerous to copy the thinking mode of any direction to the other direction.
The following is a brief analysis of each research direction
##Direction 1a: Neural network architecture design
AlexNet in 2012 laid the foundation of deep neural networks in the field of CV. In the following 10 years (to date), neural network architecture design has gone through a process from manual design to automatic design, and back to manual design (introduction of more complex computing modules):
- 2012-2017, manually constructed deeper convolutional neural networks and explored general optimization techniques. Keywords: ReLU, Dropout, 3x3 convolution, BN, skip connection, etc. At this stage, the convolution operation is the most basic unit, which corresponds to the locality prior of image features.
- 2017-2020, automatically build more complex neural networks. Among them, Network Architecture Search (NAS) was popular for a while and was finally established as a basic tool. In any given search space, automatic design can achieve slightly better results and can quickly adapt to different computational costs.
- Since 2020, the transformer module, which originated from NLP, has been introduced into CV, using the attention mechanism to complement the long-distance modeling capabilities of the neural network. Today, optimal results for most visual tasks are achieved with the help of architectures that include transformers.
For the future in this direction, my judgment is as follows:
- If the visual recognition task does not change significantly, then neither automatic design nor the addition of more complex computing modules will be able to push CV to new heights. Possible changes in visual recognition tasks can be roughly divided into two parts: input and output. Possible changes in the input part, such as event camera, may change the status quo of regular processing of static or sequential visual signals and give rise to specific neural network structures; possible changes in the output part are some kind of framework (direction) that unifies various recognition tasks. 3 will be discussed), it may allow visual recognition to move from independent tasks to a unified task, thus giving rise to a network architecture more suitable for visual prompts.
- If you have to choose between convolution and transformer, then transformer has greater potential, mainly because it can unify different data modalities, especially They are text and image, the two most common and important modalities.
- Interpretability is a very important research direction, but I personally am pessimistic about the interpretability of deep neural networks. The success of NLP is not based on interpretability, but on overfitting large-scale corpora. This may not be a good sign for real AI.
Direction 1b: Visual pre-training
is a hot topic in the CV field today In this direction, pre-training methods have high hopes. In the era of deep learning, visual pre-training can be divided into three categories: supervised, unsupervised, and cross-modal. The general description is as follows:
- Supervised The development of pre-training is relatively clear. Since image-level classification data is the easiest to obtain, long before the outbreak of deep learning, there was the ImageNet data set that would lay the foundation for deep learning in the future, and it is still used today. The total ImageNet data set exceeds 15 million and has not been surpassed by other non-classified data sets. Therefore, it is still the most commonly used data in supervised pre-training. Another reason is that image-level classification data introduces less bias, which is more beneficial to downstream migration - further reducing bias is unsupervised pre-training.
- #Unsupervised pre-training has experienced a tortuous development process. Since 2014, the first generation of unsupervised pre-training methods based on geometry has emerged, such as judging based on patch position relationships, image rotation, etc. At the same time, generative methods are also constantly developing (generative methods can be traced back to earlier period, which will not be described here). At this time, the unsupervised pre-training method is still significantly weaker than the supervised pre-training method. By 2019, after technical improvements, the contrastive learning method showed for the first time the potential to surpass the supervised pre-training method in downstream tasks. Unsupervised learning has truly become the focus of the CV world. Beginning in 2021, the rise of visual transformers has given rise to a special type of generative task, MIM, which has gradually become the dominant method.
- In addition to purely supervised and unsupervised pre-training, there is also a type of method in between, which is cross-modal pre-training. It uses weakly paired images and texts as training materials. On the one hand, it avoids the bias caused by image supervision signals, and on the other hand, it can learn weak semantics better than unsupervised methods. In addition, with the help of transformer, the integration of visual and natural language is more natural and reasonable.
Based on the above review, I make the following judgment:
- From a practical application point of view, different pre-training tasks should be combined. That is to say, a mixed data set should be collected, which contains a small amount of labeled data (even stronger labels such as detection and segmentation), a medium amount of image-text paired data, and a large amount of image data without any labels, and in such mixed data Centrally design pre-training methods.
- From the CV field, unsupervised pre-training is the research direction that best reflects the essence of vision. Even though cross-modal pre-training has brought a great impact to the entire direction, I still think that unsupervised pre-training is very important and must be persisted. It should be pointed out that the idea of visual pre-training is largely influenced by natural language pre-training, but the nature of the two is different, so they cannot be generalized. In particular, natural language itself is data created by humans, in which every word and character is written by humans and naturally has semantic meaning. Therefore, in a strict sense, NLP pre-training tasks cannot be regarded as real The unsupervised pre-training is at best weakly supervised pre-training. But vision is different. Image signals are raw data that exists objectively and have not been processed by humans. The unsupervised pre-training task in it must be more difficult. In short, even if cross-modal pre-training can advance the visual algorithm in engineering and achieve better recognition results, the essential problem of vision still needs to be solved by vision itself.
- #Currently, the essence of pure visual unsupervised pre-training is to learn from degradation. Degradation here refers to removing some existing information from the image signal, requiring the algorithm to restore this information: geometric methods remove geometric distribution information (such as the relative position of patches); contrast methods remove the image The overall information (by extracting different views); the generation method such as MIM removes the local information of the image. This method based on degradation has an insurmountable bottleneck, that is, the conflict between degradation intensity and semantic consistency. Since there is no supervised signal, visual representation learning completely relies on degradation, so the degradation must be strong enough; when the degradation is strong enough, there is no guarantee that the images before and after degradation are semantically consistent, leading to ill-conditioned pre-training objectives. For example, if two views extracted from an image in comparative learning have no relationship, it is unreasonable to bring their features closer; if the MIM task removes key information (such as faces) in the image, it is not reasonable to reconstruct this information. Reasonable. Forcibly completing these tasks will introduce a certain bias and weaken the generalization ability of the model. In the future, there should be a learning task that does not require degradation, and I personally believe that learning through compression is a feasible route.
Direction 2: Model fine-tuning and lifelong learning
As a foundation The problem is that a large number of different settings have been developed for model fine-tuning. If you want to unify different settings, you can think of them as considering three data sets, namely the pre-training data set Dpre (invisible), the target training set Dtrain, and the target test set Dtest (invisible and unpredictable). Depending on the assumptions about the relationship between the three, the more popular settings can be summarized as follows:
- Transfer learning: Assume that the data distribution of Dpre or Dtrain and Dtest are very different;
- Weakly supervised learning: Assume that Dtrain only provides incomplete annotation information;
- Semi-supervised learning: Assume that Dtrain only provides part of the data;
- Learning with noise: It is assumed that some of the data annotations of Dtrain may be incorrect;
- Active learning: It is assumed that Dtrain can be interactively Labeling (selecting the most difficult samples) to improve labeling efficiency;
- Continuous learning: Assume that new Dtrains continue to appear, so they may be forgotten during the learning process What to learn from Dpre;
- ……
From the general meaning As mentioned above, it is difficult to find a unified framework to analyze the development and genre of model fine-tuning methods. From an engineering and practical perspective, the key to model fine-tuning lies in the prior judgment of the size of the differences between domains. If you think that the difference between Dpre and Dtrain may be very large, you need to reduce the proportion of weights transferred from the pre-training network to the target network, or add a special head to adapt to this difference; if you think that the difference between Dtrain and Dtest may be very large , it is necessary to add stronger regularization during the fine-tuning process to prevent overfitting, or to introduce some online statistics during the testing process to offset the differences as much as possible. As for the various settings mentioned above, there is a large amount of research work on each, which is very targeted and will not be discussed in detail here.
Regarding this direction, I think there are two important issues:
- From isolated setting to the unity of lifelong learning. From academia to industry, we must abandon the thinking of "one-time delivery model" and understand the delivery content as a tool chain centered on the model and equipped with multiple functions such as data governance, model maintenance, and model deployment. In industry terms, a model or a set of systems must be fully cared for during the entire project life cycle. It must be taken into account that user needs are changeable and unpredictable. Today, the camera may be changed, tomorrow there may be new target types to be detected, and so on. We do not pursue AI to solve all problems independently, but AI algorithms should have a standardized operating process so that people who do not understand AI can follow this process, add the requirements they want, and solve the problems they usually encounter. Only in this way can AI Really bring it to the masses and solve practical problems. For academia, it is necessary to define a lifelong learning setting that conforms to real scenarios as soon as possible, establish corresponding benchmarks, and promote research in this direction.
- #Resolve conflicts between big data and small samples when there are obvious differences between domains. This is another difference between CV and NLP: NLP basically does not need to consider the inter-domain differences between pre-training and downstream tasks, because the grammatical structure is exactly the same as common words; while CV must assume that the upstream and downstream data distributions are significantly different, so that the upstream When the model is not fine-tuned, the underlying features cannot be extracted from the downstream data (they are directly filtered out by units such as ReLU). Therefore, using small data to fine-tune a large model is not a big problem in the NLP field (the current mainstream is to only fine-tune prompts), but it is a big problem in the CV field. Here, designing visually friendly prompts may be a good direction, but current research has not yet reached the core issue.
Direction 3: Infinite fine-grained visual recognition task
About Infinite Fine-grained visual recognition (and similar concepts), there hasn't been a lot of related research yet. Therefore, I will describe this issue in my own way. In this year's VALSE report, I gave a detailed explanation of existing methods and our proposal. I will give a text description below. For a more detailed explanation, please refer to my special article or the report I made on VALSE: https://zhuanlan.zhihu.com/p/ 546510418https://zhuanlan.zhihu.com/p/555377882
First of all, I want to explain the meaning of infinitely fine-grained visual recognition. Simply put, images contain very rich semantic information but do not have clear basic semantic units. As long as humans are willing, they can identify increasingly fine-grained semantic information from an image (as shown in the figure below); but this information is difficult to pass through limited and standardized annotations (even if sufficient annotation costs are spent), Form a semantically complete data set for algorithm learning.

Even finely annotated data sets such as ADE20K lack a large amount of semantic content that humans can recognize
We believe that infinitely fine-grained visual recognition is a more difficult and more essential goal than open-domain visual recognition. We survey existing recognition methods, divide them into two categories, namely classification-based methods and language-driven methods, and discuss the reasons why they cannot achieve infinite fine-graining.
- Classification-based methods: This includes classification, detection, segmentation and other methods in the traditional sense. Its basic feature is to give each feature in the image Basic semantic units (images, boxes, masks, keypoints, etc.) are assigned a category label. The fatal flaw of this method is that when the granularity of recognition increases, the certainty of recognition inevitably decreases, that is, granularity and certainty are in conflict. For example, in ImageNet, there are two major categories: "furniture" and "electrical appliances"; obviously "chair" belongs to "furniture" and "TV" belongs to "home appliances", but does "massage chair" belong to "furniture" or "Home appliances" is difficult to judge - this is the decrease in certainty caused by the increase in semantic granularity. If there is a "person" with a very small resolution in the photo, and the "head" or even "eyes" of this "person" are forcibly labeled, then the judgments of different annotators may be different; but at this time, even if it is one or two pixels The deviation will also greatly affect indicators such as IoU - this is the decrease in certainty caused by the increase in spatial granularity.
- Language-driven methods: This includes the visual prompt class method driven by CLIP, as well as the longer-standing visual grounding problem, etc. Its basic feature is to use language to refer to the semantic information in the image and identify it. The introduction of language indeed enhances the flexibility of recognition and brings natural open domain properties. However, language itself has limited referring capabilities (imagine referring to a specific individual in a scene with hundreds of people) and cannot meet the needs of infinitely fine-grained visual recognition. In the final analysis, in the field of visual recognition, language should play a role in assisting vision, and the existing visual prompt methods feel somewhat overwhelming.
The above survey tells us that the current visual recognition method cannot achieve the goal of infinite fine-grainedness, and there will be more problems on the way to infinite fine-grainedness. encountered insurmountable difficulties. Therefore, we want to analyze how people solve these difficulties. First of all, humans do not need to perform classification tasks explicitly in most cases: going back to the above example, a person goes to a mall to buy something, regardless of whether the mall places the "massage chair" in the "furniture" section or the "home appliances" section. Humans can quickly find the area where the "massage chair" is located through simple guidance. Secondly, humans are not limited to using language to refer to objects in images. They can use more flexible methods (such as pointing to objects with their hands) to complete the reference and conduct more detailed analysis.
#Combining these analyses, to achieve the goal of infinite fine-grainedness, the following three conditions must be met.
- Openness: Open domain recognition is a sub-goal of infinite fine-grained recognition. At present, introducing language is one of the best solutions to achieve openness.
- # Specificity: When introducing language, you should not be bound by the language, but should design a visually friendly reference scheme (i.e. recognition task).
- Variable granularity: It is not always required to identify the finest granularity, but the granularity of recognition can be flexibly changed according to needs.
Under the guidance of these three conditions, we designed an on-demand visual recognition task. Different from unified visual recognition in the traditional sense, on-demand visual recognition uses requests as units for annotation, learning and evaluation. Currently, the system supports two types of requests, which realize segmentation from instance to semantic and segmentation from semantic to instance. Therefore, the combination of the two can achieve image segmentation with any degree of fineness. Another benefit of on-demand visual recognition is that stopping after completing any number of requests will not affect the accuracy of annotation (even if a large amount of information is not annotated), which is beneficial to the scalability of open domains (such as adding new Semantic categories) have great benefits. For specific details, please refer to the article on on-demand visual recognition (see link above).
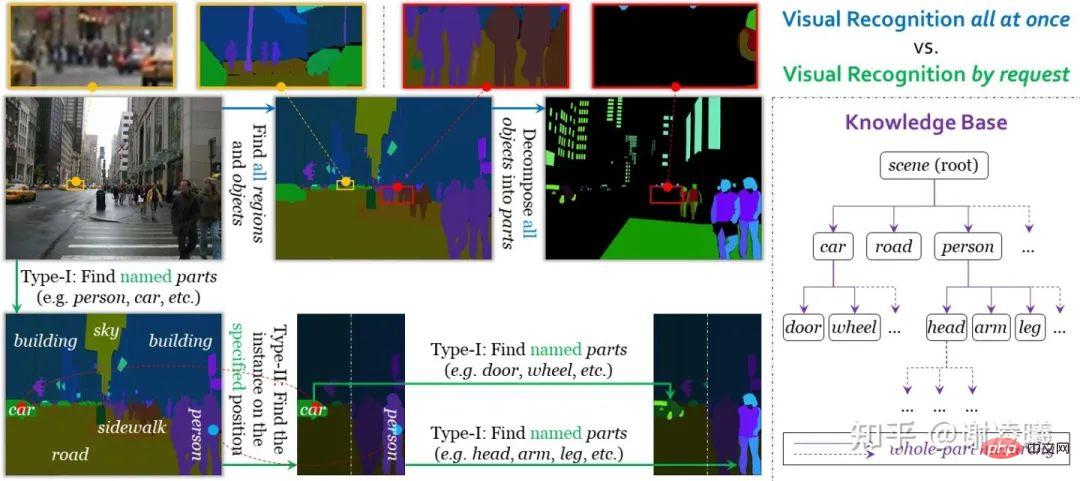
##Comparison between unified visual identity and on-demand visual identity
After completing this article, I am still thinking about the impact of on-demand visual recognition on other directions. Two perspectives are provided here:
- The request in on-demand visual recognition is essentially a visually friendly prompt. It can not only achieve the purpose of interrogating the visual model, but also avoid the ambiguity of reference caused by pure language prompts. As more types of requests are introduced, this system is expected to become more mature.
- #On-demand visual recognition provides the possibility to unify various visual tasks in form. For example, tasks such as classification, detection, and segmentation are unified under this framework. This may bring inspiration to visual pre-training. At present, the boundary between visual pre-training and downstream fine-tuning is not clear. It is still unclear whether the pre-trained model should be suitable for different tasks or focus on improving specific tasks. However, if a formally unified recognition task emerges, then this debate may no longer be relevant. By the way, the formal unification of downstream tasks is also a major advantage enjoyed by the NLP field.
I divide the problems in the CV field into three major categories: recognition, generation, interaction, Identification is just the simplest of them all. Regarding these three sub-fields, a brief analysis is as follows:
- In the field of recognition, traditional recognition indicators are obviously outdated, so people need updated evaluation indicators. At present, the introduction of natural language into visual recognition is an obvious and irreversible trend, but this is far from enough. The industry needs more innovations at the task level.
- #Generation is a more advanced ability than recognition. Humans can easily recognize a variety of common objects, but few can draw realistic objects. In the language of statistical learning, this is because the generative model needs to model the joint distribution p(x,y), while the discriminant model only needs to model the conditional distribution p(y|x): the former can derive The latter cannot be derived from the latter, but the former cannot be derived from the latter. Judging from the development of the industry, although the quality of image generation continues to improve, the stability and controllability of the generated content (without generating obviously unreal content) still need to be improved. At the same time, the generated content is still relatively weak in assisting the recognition algorithm, and it is difficult for people to fully utilize virtual data and synthetic data to achieve results comparable to real data training. For these two issues, our point of view is that better and more essential evaluation indicators need to be designed to replace existing indicators (FID, IS, etc. for generation tasks, while generation and identification tasks need to be combined to define a unified evaluation index).
- In 1978, computer vision pioneer David Marr envisioned that the main function of vision is to build a three-dimensional model of the environment and learn knowledge through interaction. Compared with recognition and generation, interaction is closer to human learning, but there are relatively few studies in the industry. The main difficulty in research on interaction lies in constructing a real interaction environment - to be precise, the current construction method of visual data sets comes from sparse sampling of the environment, but interaction requires continuous sampling. Obviously, to solve the essential problem of vision, interaction is the essence. Although there have been many related studies in the industry (such as embodied intelligence), no universal, task-driven learning goals have yet emerged. We once again repeat the idea put forward by computer vision pioneer David Marr: the main function of vision is to build a three-dimensional model of the environment and learn knowledge through interaction. Computer vision, including other AI directions, should develop in this direction to become truly practical.
#In short, in different sub-fields, attempts to rely solely on statistical learning (especially deep learning) to achieve strong fitting capabilities have come to fruition. limit. Future development must be based on a more essential understanding of CV, and establishing more reasonable evaluation indicators for various tasks is the first step we need to take.
Conclusion
After several intensive academic exchanges, I can clearly feel the confusion in the industry, at least for visual perception (recognition) In general, there are fewer and fewer interesting and valuable research questions, and the threshold is getting higher and higher. If this continues, it is possible that in the near future, CV research will take the path of NLP and gradually divide into two categories:
One type uses huge amounts of calculations The resources are pre-trained and the SOTA is constantly refreshed in vain; the other type is constantly designing novel but meaningless settings to force innovation. This is obviously not a good thing for the CV field. In order to avoid this kind of thing, in addition to constantly exploring the nature of vision and creating more valuable evaluation indicators, the industry also needs to increase tolerance, especially tolerance for non-mainstream directions. Don't complain about the homogeneity of research while simultaneously complaining about the homogeneity of research. Submissions that do not reach SOTA are a pain in the ass. The current bottleneck is a challenge faced by everyone. If the development of AI stagnates, no one can be immune. Thanks for watching till the end. Friendly discussion welcome.
Author's Statement
All contents represent only the author's own views and may be overturned. Secondary reprints must be reprinted together with the statement. Thanks!
The above is the detailed content of Huawei's young genius Xie Lingxi: Personal views on the development of the field of visual recognition. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology