
Home >Technology peripherals >AI >The rise of the second generation GAN network? The graphics of DALL·E Mini are so horrifying that foreigners are going crazy!
The rise of the second generation GAN network? The graphics of DALL·E Mini are so horrifying that foreigners are going crazy!

- WBOYforward
- 2023-04-15 23:52:01717browse
Nowadays, Google, OpenAI and other major companies’ text-based graph models are the bread and butter of interesting news reporters and the nectar of a long drought for meme lovers. By entering words, you can generate various beautiful or funny pictures, which can attract people's attention without being tiring or troublesome. Therefore, the DALL·E series and Imagens have the essential attributes of food and clothing and long-term drought: they are only available to a limited extent and are not benefits that can be distributed unlimitedly at any time. In mid-June 2022, Hugging Face Company fully disclosed the easy-to-use and simple version of the DALL·E interface: DALL·E Mini to all users on the entire network for free. As expected, it set off another wave of big news on various social media websites. Creation trend.

If ancient civil servants had these materials, they would not have to work so hard to invent the African giraffe into the mythical beast Kirin. The coders at GitHub are true to their profession and posted a generated work of "Squirrel Programming with Computers" on the official Twitter.

"Godzilla's courtroom sketch", I have to say, it really looks like what is seen in newspapers and magazines in English-speaking countries, Sketch style of case trial reporting that is not open to the public.

 ## except In addition, DALL·E Mini also has outstanding achievements in generating images of "mythical beasts were captured while walking on wild trails". This is "a small dinosaur walking on a wild trail, captured on camera."
## except In addition, DALL·E Mini also has outstanding achievements in generating images of "mythical beasts were captured while walking on wild trails". This is "a small dinosaur walking on a wild trail, captured on camera."
 This is "The Duolingo Parrot trademark was walking on a wild trail and was captured on camera."
This is "The Duolingo Parrot trademark was walking on a wild trail and was captured on camera."
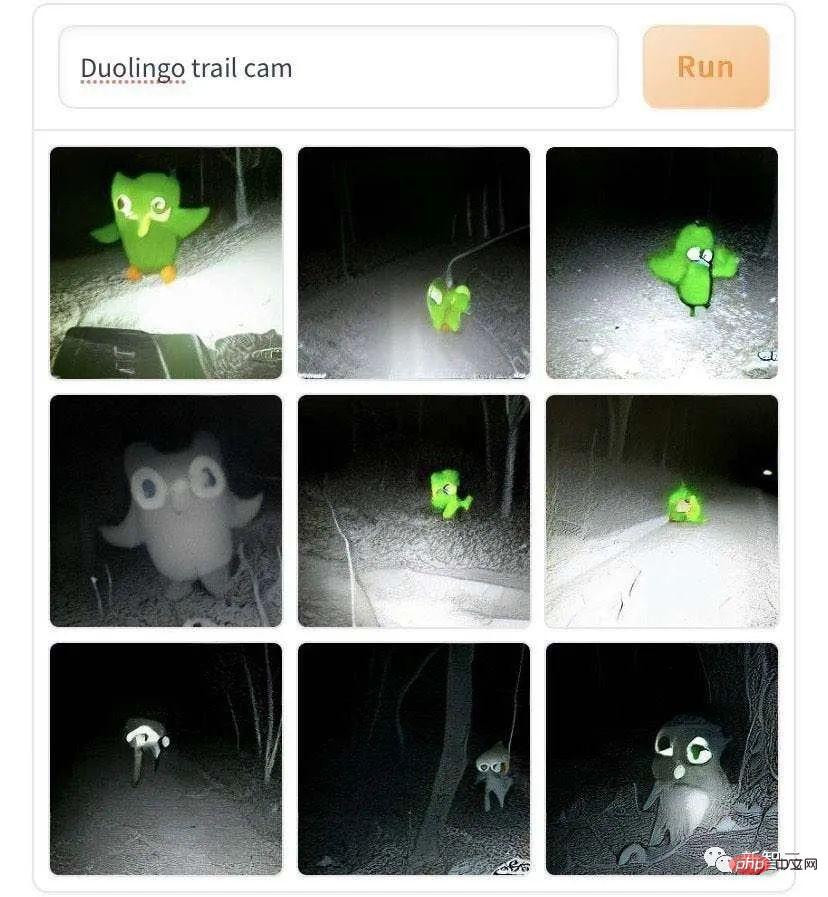 The walking pictures of these mythical beasts generated by DALL·E Mini are so lonely and desolate. But this may be the low-light photography effect simulated by AI. Everyone in the editorial department also imitated it: "Walking on the grass and mud horse on the road", and the tone became much brighter and brighter.
The walking pictures of these mythical beasts generated by DALL·E Mini are so lonely and desolate. But this may be the low-light photography effect simulated by AI. Everyone in the editorial department also imitated it: "Walking on the grass and mud horse on the road", and the tone became much brighter and brighter.
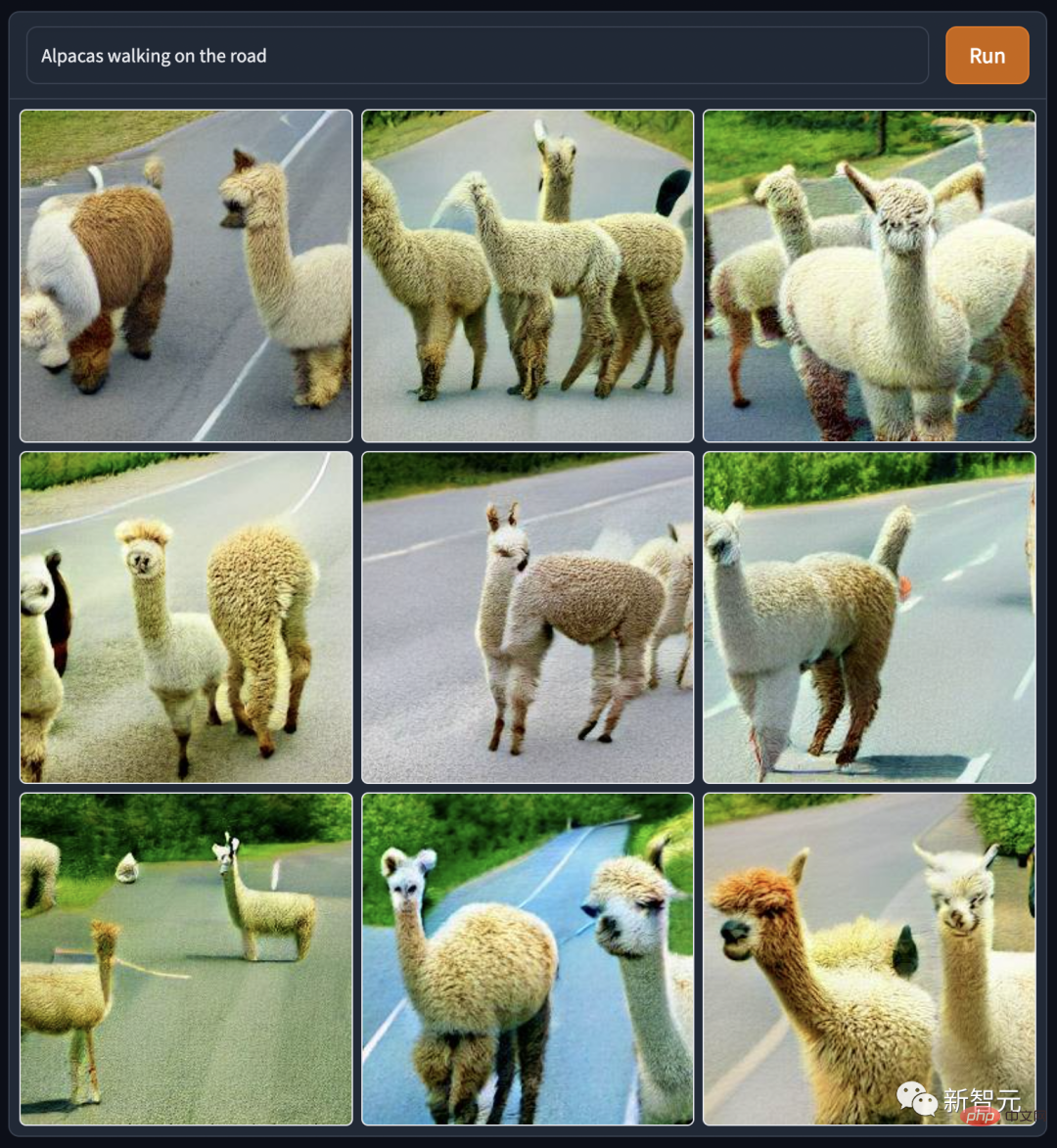 The images of gods and humans generated by DALL·E Mini are no worse than those of mythical beasts. For example, in this picture of "Jesus' Fiery Break Dance", I really didn't know that His body was so flexible. It seems that the "Stretching Exercises with the Lord" advertisements on various fitness websites are for a reason.
The images of gods and humans generated by DALL·E Mini are no worse than those of mythical beasts. For example, in this picture of "Jesus' Fiery Break Dance", I really didn't know that His body was so flexible. It seems that the "Stretching Exercises with the Lord" advertisements on various fitness websites are for a reason.
 There is also this "rapper Gou Ye on the stained glass", right? It really has the style of a church icon window and an impressionist painting.
There is also this "rapper Gou Ye on the stained glass", right? It really has the style of a church icon window and an impressionist painting.
 Using DALL·E Mini to spoof characters in the film and television industry has become a fashion now. The following is "R2D2's Baptism" from the Star Wars universe. Maybe the laws of physics and chemistry in the Star Wars universe are different from those in the real world. Robots will neither leak electricity nor rust after being exposed to water.
Using DALL·E Mini to spoof characters in the film and television industry has become a fashion now. The following is "R2D2's Baptism" from the Star Wars universe. Maybe the laws of physics and chemistry in the Star Wars universe are different from those in the real world. Robots will neither leak electricity nor rust after being exposed to water.

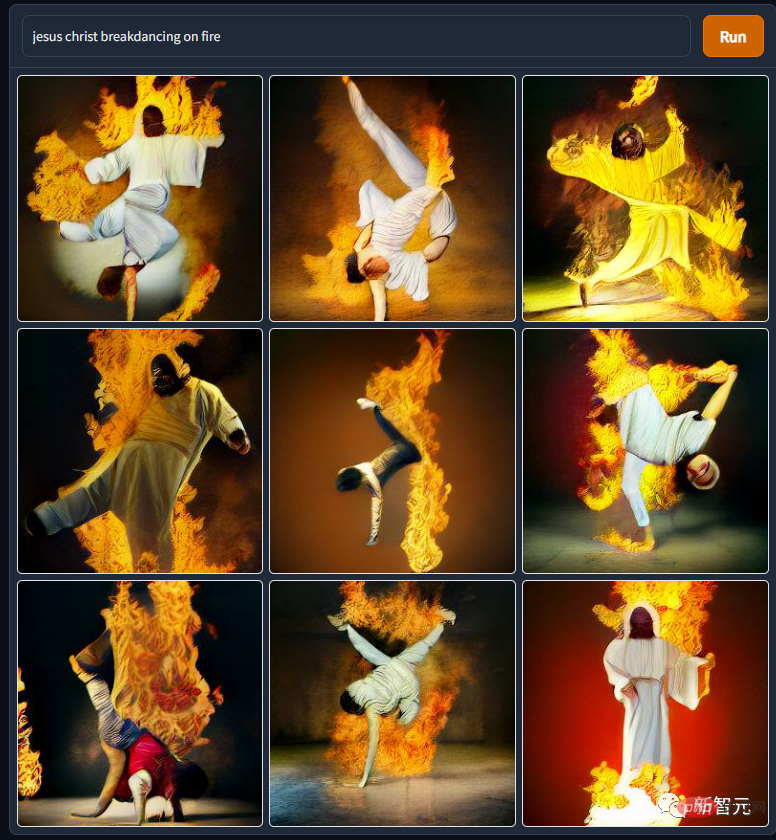
Also from the Star Wars universe, "Darth Vader cuts ice and fishes" Darth Vader is such a good teacher awful. He was chopped down by his master and forced to bathe in the lava of a volcano. After becoming a disabled person, he was chased by his own son. After mastering the force with a ventilator, the disabled person was reduced to the earth to compete with the Eskimos for business...
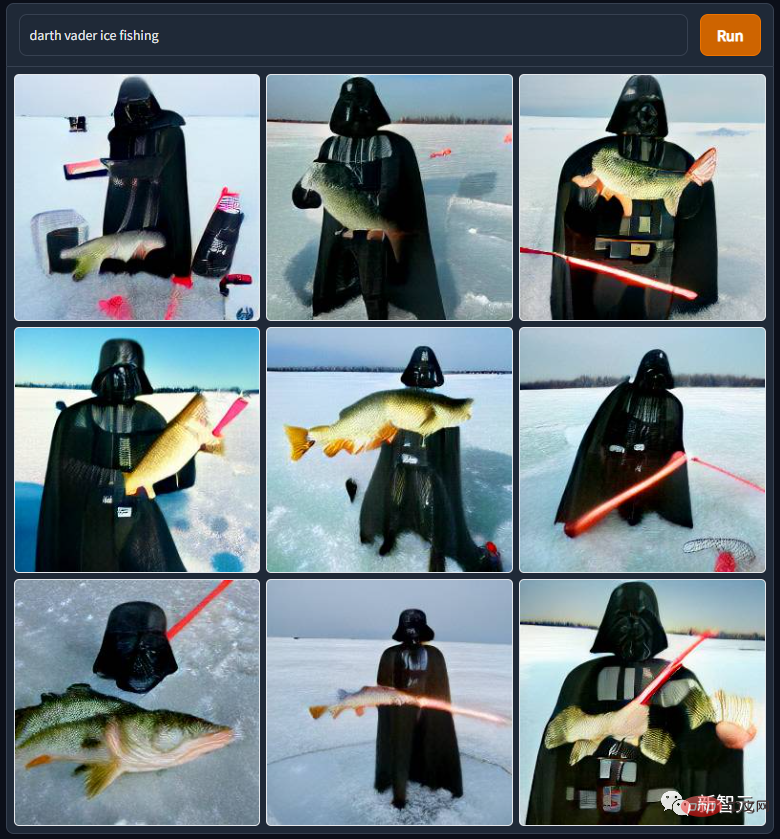
There is also this picture of "Walter White accidentally enters the world of Animal Crossing", the bald, lonely and terminal drug lord suddenly It became cute. It's a pity that Nintendo didn't really launch Animal Crossing in the 2000s, otherwise I would have found that making money through virtual transactions in Animal Crossing is much less troublesome and trouble-free than working hard to make blue ice-shaped physical goods to support my family. Let us sing "Reject pornography~reject drugs~reject pornography, gambling and drugs~".
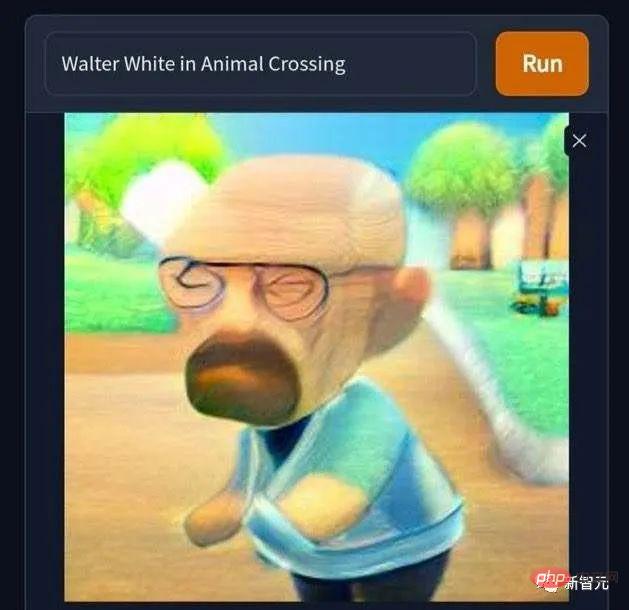
This picture of "Thanos looking for his mother in the supermarket" really fits the core of the character and is very professional in drama interpretation of the bank. "If you are unhappy, you will commit genocide, and if you disagree, you will destroy the universe. This is the character of a giant baby who cries bitterly when he can't find his mother."
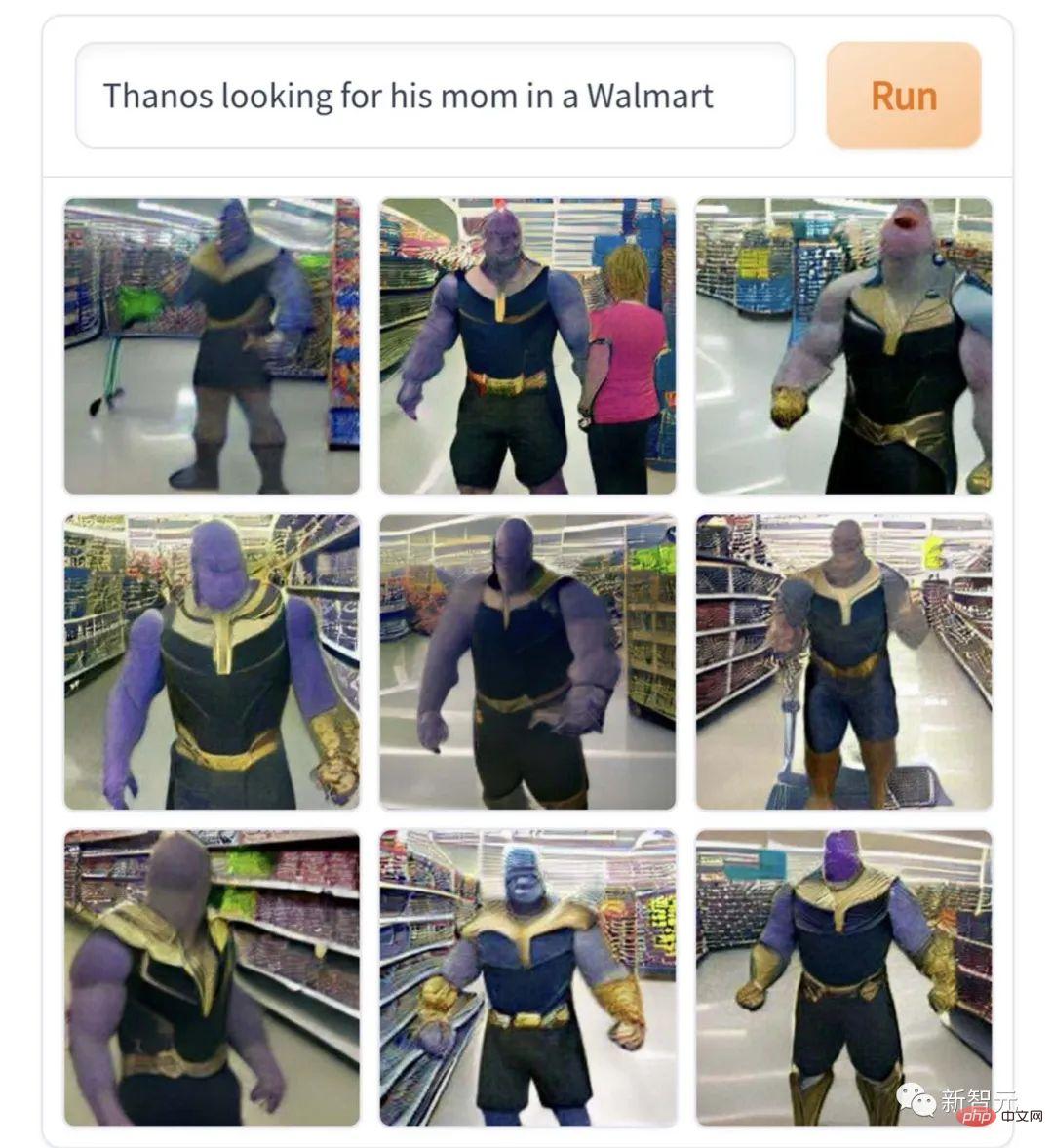
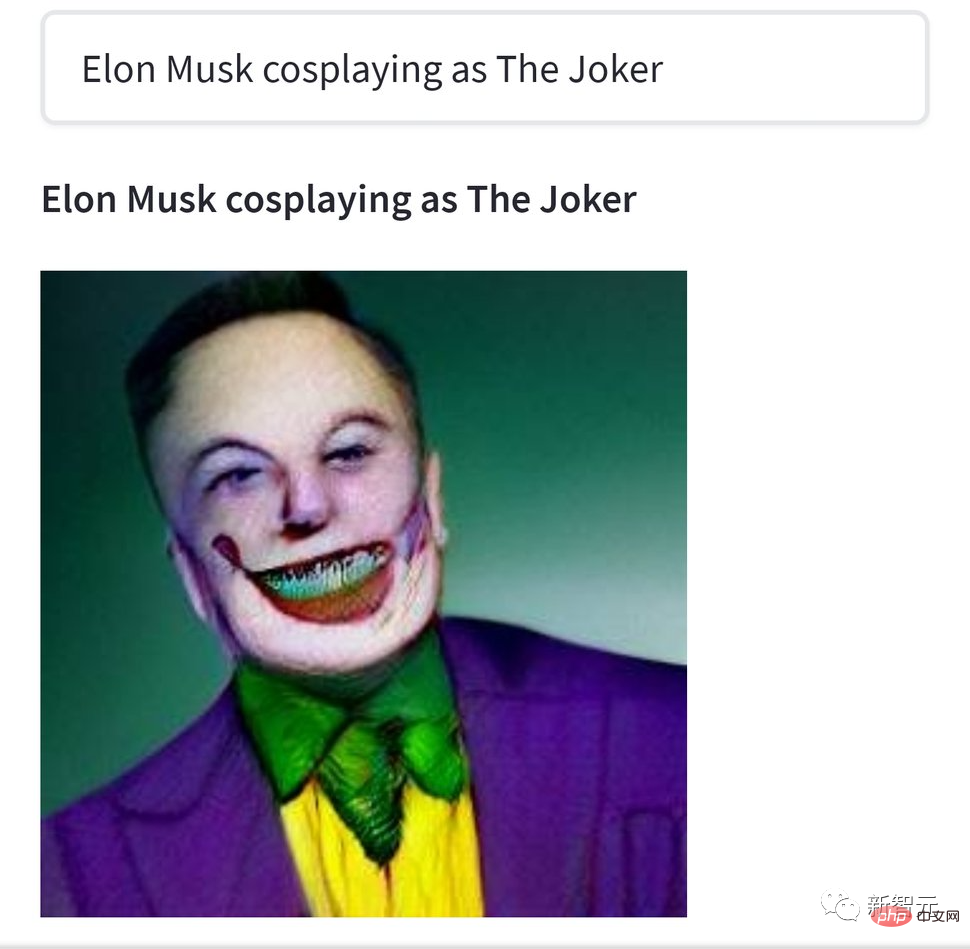
However, these creations are all light-flavored, compared to the heavy-flavored Kesu The works of Lu lovers are simply watery. For example, this picture "Elon Musk plays the Cracked Clown" is a bit scary.
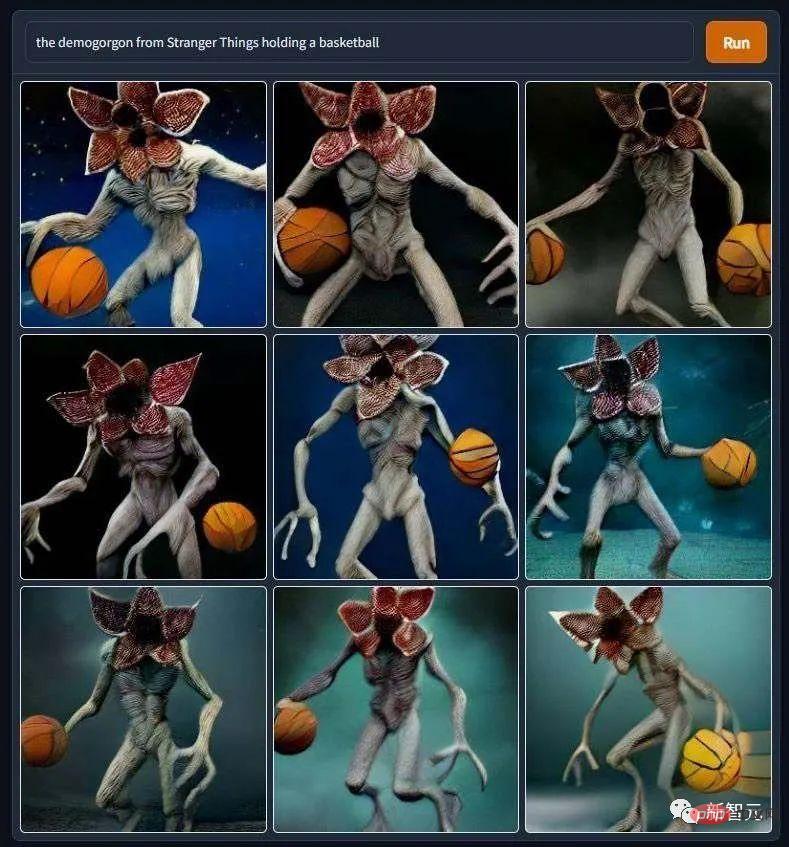
"The Devil Plays Basketball", after seeing this picture, the editor really didn't dare to continue chasing "Stranger Things" 》This drama.
The protagonists of various series of horror films also appear in the work, such as this "Mask Jason eats burritos"

There is also this picture of "A Nightmare on Elm Street" "Eating Pasta"... The pattern is so scary that it reminds the editor of the green days when watching these horror movies in the DVD era and being frightened to the point of panic.

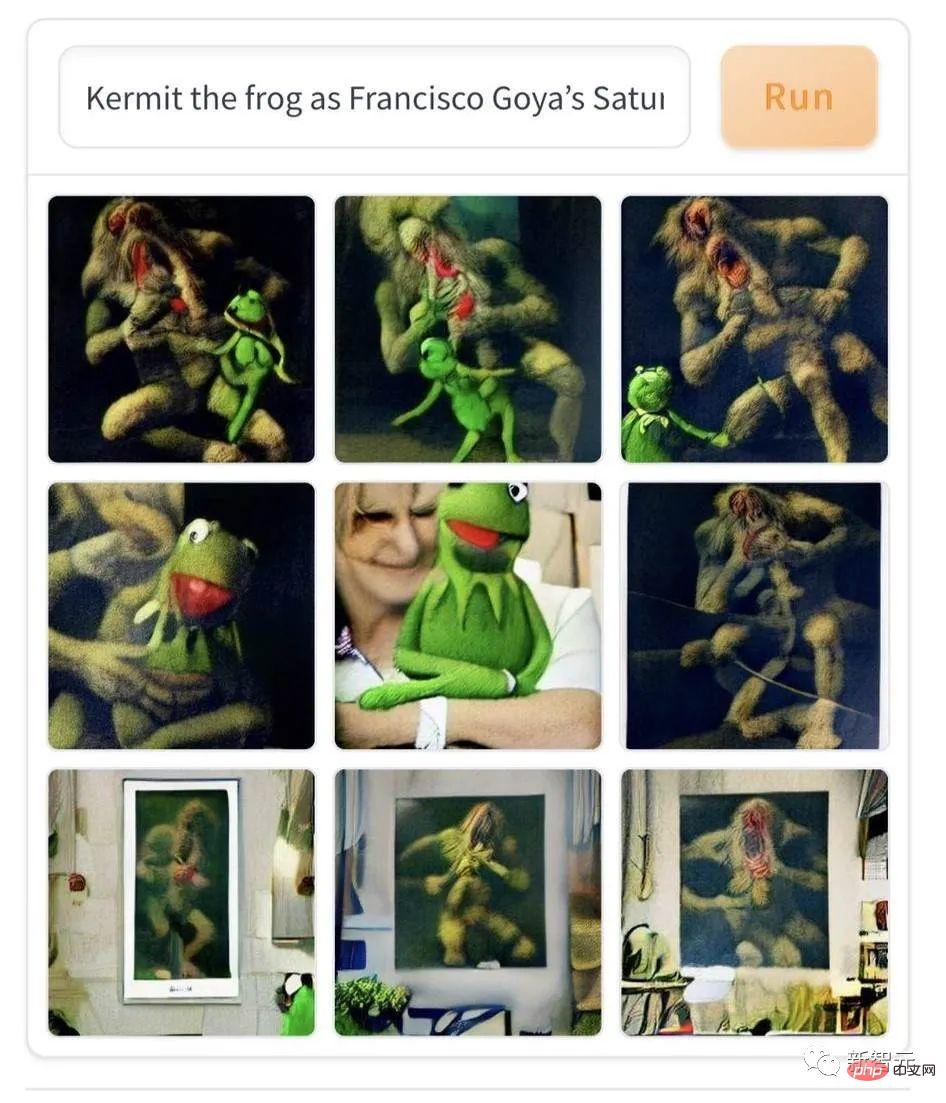
## However, contemporary popular literature and art are slightly less scary than classical art, such as this painting "Komi Frog in Goya" Photogenic in an oil painting of "The Torma of the God of Agriculture". AI combines contemporary cartoons with 19th-century expressionist oil paintings, which can scare anyone who sees it for the first time with cold sweats running down their spines.
There is also this picture of "The God of Death clicks on the golden arch". After reading this, you will still dare to go to work and go to school in the future. Late?

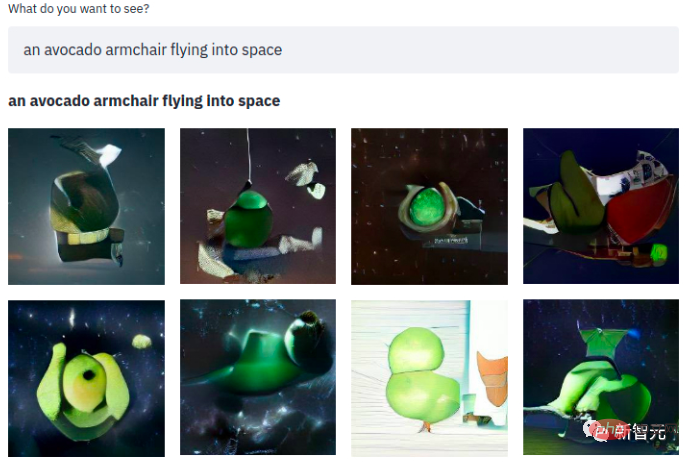
In a simple sentence, what follows is an avocado armchair flashing into space~ The model uses three data sets:
1. "Conceptual" containing 3 million image and title pairs Captions Dataset";
2. The Open AI subset of "YFCC100M", which contains approximately 15 million images. However, due to storage space considerations, the author further processed 2 million images. sampling. Use titles and text descriptions as tags at the same time, and delete corresponding html tags, line breaks, and extra spaces;
3. "Conceptual 12M" containing 12 million image and title pairs.
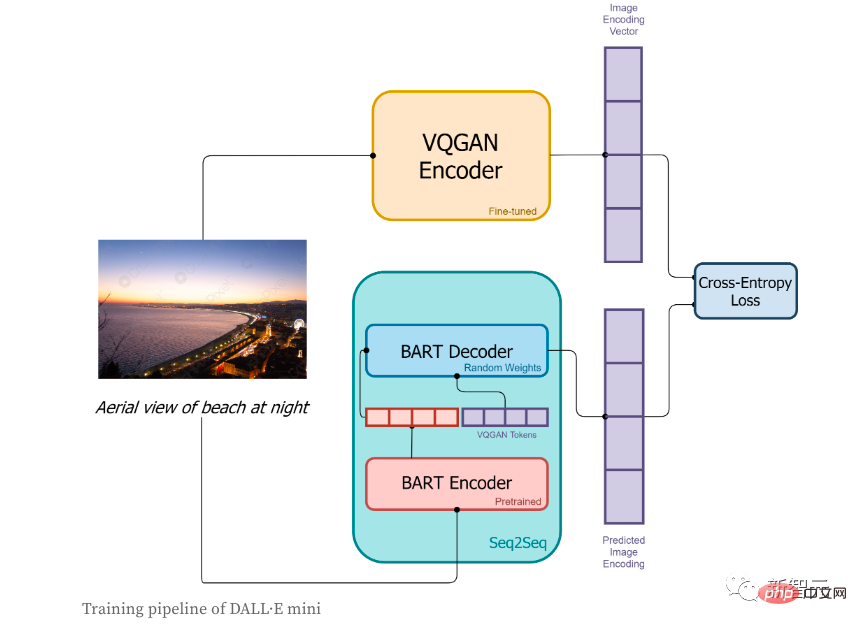
In the training phase:
1. First, the image will be encoded by the VQGAN encoder, with the purpose of converting the image into a token sequence;
2. The text corresponding to the image The description will be encoded by the BART encoder;
3. The output of the BART encoder and the sequence token encoded by the VQGAN encoder will be sent to the BART decoder together. The decoder is an autoregressive model. The purpose is to predict the next token sequence;
4. The loss function is cross-entropy loss, which is used to calculate the loss value between the image coding result predicted by the model and the VQGAN real image coding.
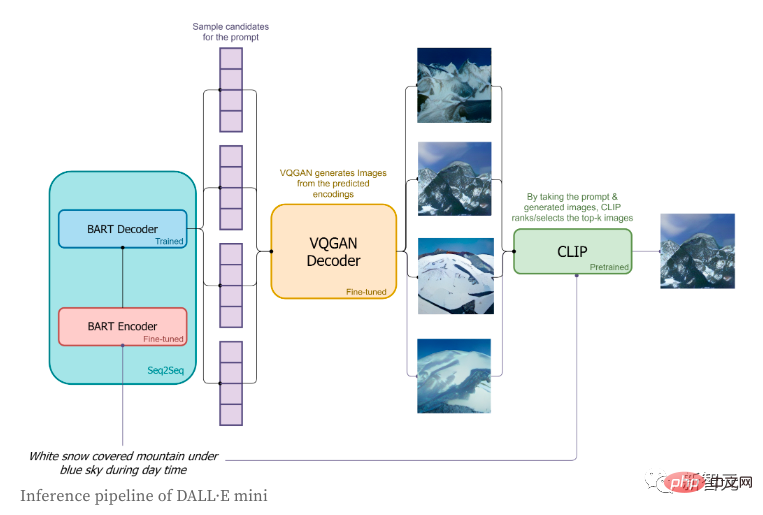
In the inference stage, the author only used short tags and tried to generate their corresponding images. The specific process is as follows:
1. Tags will Encoding through the BART encoder;
2.
3. Based on BART The distribution predicted by the decoder on the next token, the image tokens will be sampled in order;
4. The sequence of image tokens will be sent to the VQGAN decoder for decoding;
5. Finally, "CLIP" will choose the best generation result for us.
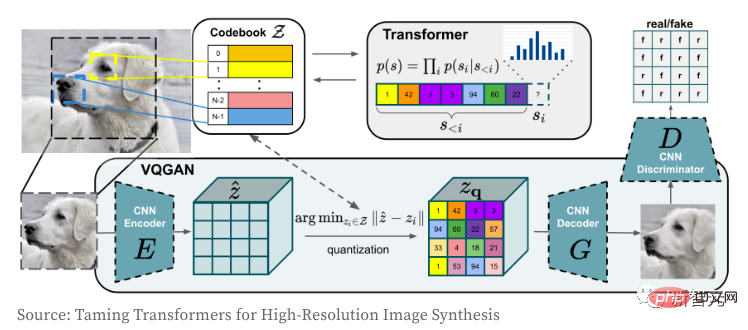
Next let’s take a look at how the VQGAN image encoder and decoder work. The Transformer model must be familiar to everyone. Since its birth, it has not only dominated the NLP field, but also the convolutional CNN network in the CV field. The author's purpose of using VQGAN is to encode the image into a discrete token sequence, which can be used directly in the Transformer model. Due to the use of pixel value sequences, the embedding space of discrete values will be too large, ultimately making it extremely difficult to train the model and meet the memory requirements of the self-attention layer.
VQGAN learns a "codebook" of pixels by combining perceptual loss and GAN's discriminative loss. The encoder outputs the index value corresponding to the "codebook". As the image is encoded into a token sequence, it can be used in any Transformer model. In this model, the author encodes images from a vocabulary of size 16,384 into "16x16=256" discrete tokens, using a compression factor of f=16 (the width and height of 4 blocks are each divided by 2). The decoded image is 256x256 (16x16 on each side). For more detailed understanding of VQGAN, please refer to "Taming Transformers for High-Resolution Image Synthesis".
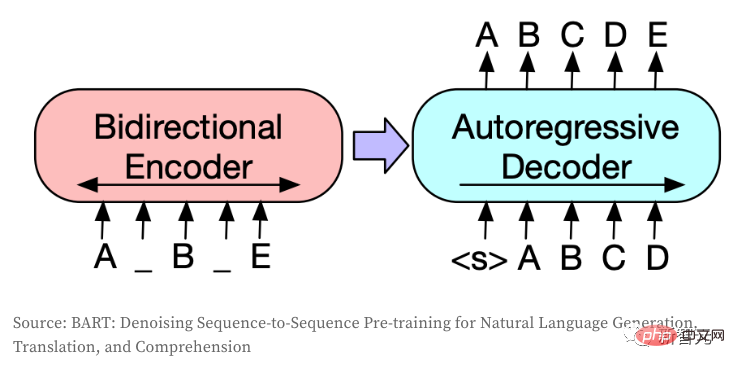
The Seq2Seq model converts one token sequence into another token sequence and is usually used in NLP for tasks such as translation, summary, or conversation modeling. The same idea can also be transferred to the CV field if images are encoded into discrete tokens. This model uses BART, and the author just fine-tuned the original architecture:
1. Create an independent embedding layer for the encoder and decoder (when there are the same type of input and output, both Usually can be shared);
2. Adjust the shape of the decoder input and output to make it consistent with the size of VQGAN (this step does not require an intermediate embedding layer);
3. Force The generated sequence has 256 tokens (the
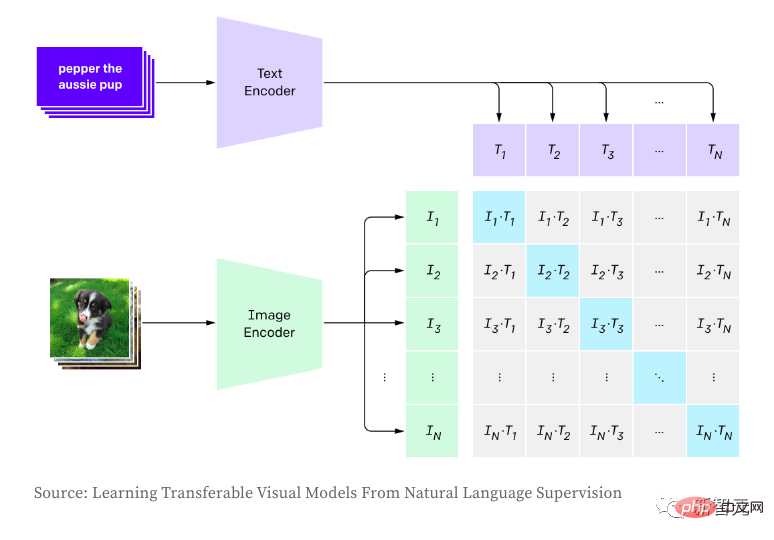
CLIP is used to establish the relationship between images and text and is trained using contrastive learning, including maximizing the product (cosine similarity) between image and text pair embeddings degree, which is the product between positive samples) and minimizing non-correlated pairs (ie negative samples). When generating images, the author randomly samples image labels according to the logits distribution of the model, which results in different samples and inconsistent quality of the generated images. CLIP allows scoring of generated images based on input descriptions, thereby selecting the best generated samples. In the inference phase, the pre-trained version of OpenAI is used directly.
So, how does CLIP compare to OpenAI DALL·E? Not all details about DAL are known to the public, but the following are the main ones in the author’s opinion the difference:
1. DALL·E uses the 12 billion parameter version of GPT-3. In comparison, the author's model is 27 times larger and has about 400 million parameters.
2. The author makes extensive use of pre-trained models (VQGAN, BART encoder and CLIP), while OpenAI must train all models from scratch. The model architecture takes into account the available pre-trained models and their efficiency.
3. DALL·E encodes images using a larger number of tokens (1,024 VS 256) from a smaller vocabulary (8,192 VS 16,384).
4. DALL·E uses VQVAE, while the author uses VQGAN. DALL·E reads text and images as a single data stream when the authors split between the Seq2Seq encoder and decoder. This also allows them to use separate vocabulary for text and images.
5. DALL·E reads text through an autoregressive model, while the author uses a bidirectional encoder.
6. DALL·E trained 250 million pairs of images and texts, while the author only used 15 million pairs. of.
7. DALL·E uses fewer tokens (up to 256 VS 1024) and a smaller vocabulary (16384 VS 50264) to encode text. In the training of VQGAN, the author first started from the pre-trained checkpoint on ImageNet, with a compression factor of f=16 and a vocabulary size of 16,384. Although very efficient at encoding a wide range of images, the pre-trained checkpoint is not good at encoding people and faces (as both are not common in ImageNet), so the author decided to encode it on a 2 x RTX A6000 cloud instance. Approximately 20 hours of fine-tuning. It is obvious that the quality of the generated image on the human face has not improved much, and it may be "model collapse". Once the model is trained, we convert the Pytorch model to JAX for use in the next stage.
Training DALL·E Mini: This model uses JAX programming, making full use of the advantages of TPU. The author pre-encodes all images with an image encoder for faster data loading. During the training, the author quickly determined several nearly feasible parameters:
1. At each step, the batchsize size of each TPU is 56, which is the maximum memory available for each TPU;
2. Gradient accumulation: the effective batchsize size is 56 × 8 TPU chips × 8 steps = 3,584 images updated each time;
3. The memory efficiency of the optimizer Adafactor allows us to use higher batchsize;
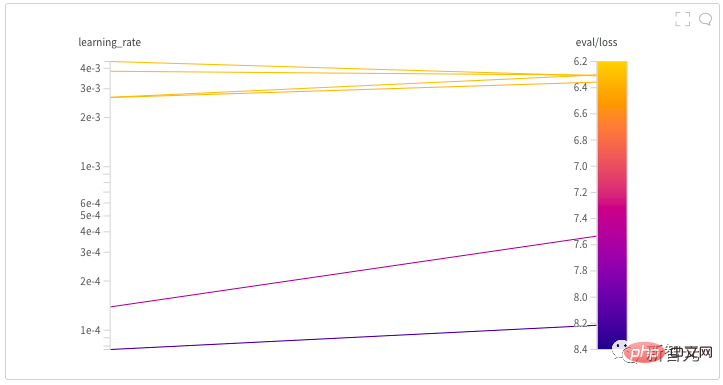
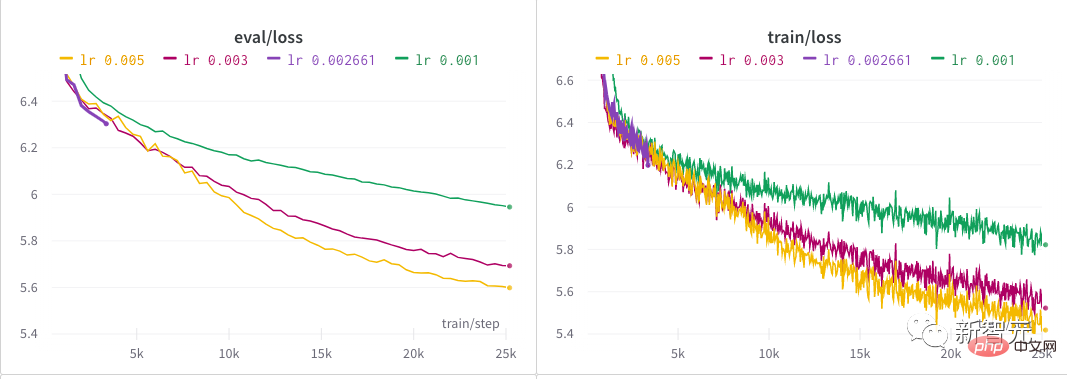
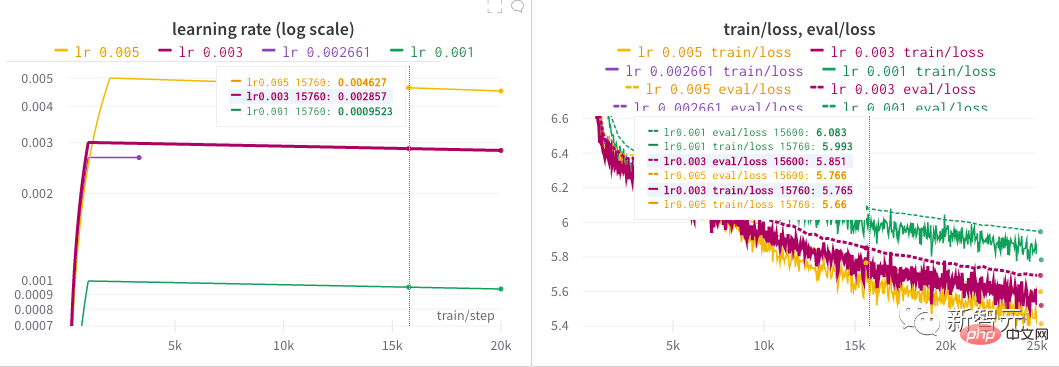
4, 2000 steps of "warm-up" and a learning rate that decays in a linear manner. The author spent almost half a day to find a good learning rate for the model by launching a hyperparameter search. Behind every NB model, there is probably a painstaking process of finding hyperparameters! After the author's initial exploration, several different learning rates were tried over an extended period of time until they finally settled on 0.005.
The above is the detailed content of The rise of the second generation GAN network? The graphics of DALL·E Mini are so horrifying that foreigners are going crazy!. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology