

 Technology peripheralsAIWorrying image quality interferes with visual recognition, DAMO Academy proposes a more robust framework
Technology peripheralsAIWorrying image quality interferes with visual recognition, DAMO Academy proposes a more robust frameworkWorrying image quality interferes with visual recognition, DAMO Academy proposes a more robust framework

This article introduces the paper "Improving Training and Inference of Face Recognition Models via Random Temperature Scaling" accepted by AAAI 2023, the top international conference on machine learning. This paper innovatively analyzes the internal relationship between the temperature adjustment parameter and classification uncertainty in the classification loss function from a probabilistic perspective, revealing that the temperature adjustment factor of the classification loss function is the scale coefficient of the uncertainty variable obeying the Gumbel distribution. . Therefore, a new training framework called RTS is proposed to model the reliability of feature extraction. Based on the RTS training framework, a more reliable recognition model is trained, making the training process more stable, and providing a measurement score of sample uncertainty during deployment to reject high-uncertain samples and help build a more robust vision recognition system. Extensive experiments show that RTS can train stably and output uncertainty measures to build a robust visual recognition system.

- ##Paper address: https://arxiv.org/abs/2212.01015
- Open source model: https://modelscope.cn/models/damo/cv_ir_face-recognition-ood_rts/summary
Uncertainty problem:Visual recognition systems usually encounter a variety of interferences in real scenes. For example: occlusion (decoration or complex foreground), imaging blur (focus blur or motion blur), extreme lighting (overexposure or underexposure, etc.). These interferences can be summarized as the influence of noise. In addition, there are misdetected pictures, usually cat faces or dog faces. These misdetected data are called out-of-distribution (OOD) data. For visual recognition, the above-mentioned noise and OOD data constitute a source of uncertainty. Affected samples will superimpose uncertainty on the features extracted based on the depth model, causing interference to the visual recognition system. For example, if the base library image is contaminated by samples with uncertain interference, a "feature black hole" will be formed, which will bring hidden dangers to the visual recognition system. There is therefore a need to model representation reliability.
Related work on characterization reliability modelingTraditional multi-model solution
Traditional The method of controlling reliability in the visual recognition link is done through an independent quality model. The typical image quality modeling method is as follows:
1. Collect annotation data and annotate specific factors that affect quality, such as clarity, presence or absence of occlusion, and posture.
2. Map the quality score from 1 to 10 according to the label of the influencing factors. The higher the score, the better the quality. For specific examples, please refer to the example on the left side of the figure below.
3. After obtaining the quality score annotation from the first two steps, perform ordered regression training to predict the quality score during the deployment phase, as shown in the example on the right side of the figure below.

The independent quality model solution requires the introduction of a new model in the visual recognition link, and the training relies on annotation information .
DUL
The uncertainty modeling method includes "Data Uncertainty Learning in Face Recognition". The features are modeled as the sum of the mean and variance of the Gaussian distribution, and the features containing uncertainty are sent to the subsequent classifier for training. Thus, the uncertainty score related to image quality can be obtained during the deployment stage.

DUL uses a summation method to describe uncertainty. The scale of the noise estimate is also the same as that of a certain type of data. Feature distribution is closely related. If the data distribution is relatively tight, then the scale of the noise estimated by DUL is also relatively small. Work in the field of OOD points out that the density of data distribution is not a good metric for OOD identification.
GODIN
The work in the field of OOD "Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data" uses the form of joint probability distribution to process OOD data, using two independent branches h ( x) and g(x) estimate the classification probability value and the temperature adjustment value.

Since the temperature value is modeled as a probability value and the range is limited to 0-1, the temperature is not better modeled .
Method
In view of the above problems and related work, this paper starts from the probability perspective and studies the relationship between the temperature adjustment factor and uncertainty in the classification loss function. After analysis, the RTS training framework is proposed.

##Analysis of temperature regulation factors based on probability perspective
First analyze the relationship between the temperature adjustment factor and uncertainty. Assume that the uncertainty  is a random variable that conforms to the standard Gumbel distribution, then the probability density function can be written as
is a random variable that conforms to the standard Gumbel distribution, then the probability density function can be written as
 ,The cumulative distribution function is
,The cumulative distribution function is , and the probability value of classified into class k is:
, and the probability value of classified into class k is:

Put  into the above formula to get:
into the above formula to get:


Modeling temperature In order to reduce the impact of uncertainty estimation on classification, the temperature t needs to be near 1, so we model the temperature t as the sum of ##, beta = frac {alpha - 1} {v})$ distribution. The influence of v and  independent gamma distribution variables:
independent gamma distribution variables: where
where , so that t obeys
, so that t obeys 
 on the distribution is as shown below.
on the distribution is as shown below.

The constraints on temperature modeling are implemented using the following regular terms during training

The overall algorithm is organized as:

For more detailed analysis and theoretical proof, please refer to the paper.
ResultIn the training phase, the training data only contains face training data. The OOD data of falsely detected cat faces and dog faces is used to verify the recognition effect of OOD data during testing and the test illustrates the dynamic process of OOD sample uncertainty at different stages in the training process.
Training phase
We draw the in-distribution data (face) and out-of-distribution The uncertainty scores of the data (cat faces and dog faces mistakenly detected as faces) at different epoch numbers. From the figure below, you can see that the uncertainty scores of all samples in the initial stage are distributed near the larger values, and then As training progresses, the uncertainty of OOD samples gradually increases, and the uncertainty of face data gradually decreases. The better the face quality, the lower the uncertainty. ID data and OOD data can be distinguished by setting a threshold, and the image quality is reflected by the uncertainty score.

To illustrate the robustness to noisy training data during the training phase. This article applies different proportions of noise to the training set. The model recognition effects based on different proportions of noise training data are as follows. It can be seen that RTS can also achieve better recognition results for training based on noise data.

Deployment Phase
The picture below It shows that the uncertainty score obtained by the RTS framework during the deployment phase has a high correlation with the face quality

At the same time, the error matching curve after removing low-quality samples is plotted on the benchmark. Based on the obtained uncertainty scores, samples with higher uncertainty in the benchmark are removed in order of uncertainty from high to low, and then the error matching curves of the remaining samples are drawn. As can be seen from the figure below, as more samples with higher uncertainty are filtered, there are fewer false matches, and when the same number of uncertainty samples are removed, RTS has fewer false matches.

#In order to verify the identification effect of the uncertainty score on OOD samples, an in-distribution data set was constructed during testing (face) and out-of-distribution data sets (cat faces and dog faces mistakenly detected as faces). Data sample is as follows.

We explain the effect of RTS from two aspects. First, draw the distribution chart of uncertainty. As can be seen from the figure below, the RTS method has strong discrimination ability for OOD data.

At the same time, the ROC curve on the OOD test set was also drawn, and the AUC value of the ROC authority was calculated, as you can see The uncertainty score of RTS can better identify OOD data.


##General recognition ability
To test the general recognition ability on the benchmark, RTS increases the recognition ability of OOD data without affecting the face recognition ability. Using the RTS algorithm can achieve a balanced result in identification and OOD data identification.


1.https://modelscope.cn/ models/damo/cv_resnet50_face-detection_retinaface/summary
##2.https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary
3.https://modelscope.cn/models/damo/cv_manual_face-detection_tinymog/summary
4.https://modelscope.cn/models/damo/cv_manual_face-detection_ulfd /summary
5.https://modelscope.cn/models/damo/cv_manual_face-detection_mtcnn/summary
6.https:/ /modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary
7.https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary
8. https://modelscope.cn/models/damo/cv_manual_face-liveness_flir/summary
9.https://modelscope.cn/models/ damo/cv_manual_face-liveness_flrgb/summary
10.https://modelscope.cn/models/damo/cv_manual_facial-landmark-confidence_flcm/summary
11.https://modelscope.cn/models/damo/cv_vgg19_facial-expression-recognition_fer/summary
12.https://modelscope.cn/models/damo/cv_resnet34_face -attribute-recognition_fairface/summary
The above is the detailed content of Worrying image quality interferes with visual recognition, DAMO Academy proposes a more robust framework. For more information, please follow other related articles on the PHP Chinese website!

 Can SmolDocling Make Document Parsing More Efficient?Apr 23, 2025 am 09:41 AM
Can SmolDocling Make Document Parsing More Efficient?Apr 23, 2025 am 09:41 AMSmolDocling: A Lightweight Vision-Language Model for High-Precision Document Conversion Digital documents present a significant challenge: accurately converting their rich structure into machine-readable formats. Existing solutions, whether complex
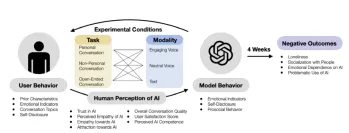 Can AI Cure Loneliness - or Make It Worse?Apr 23, 2025 am 09:37 AM
Can AI Cure Loneliness - or Make It Worse?Apr 23, 2025 am 09:37 AMThis MIT and OpenAI study explores how interacting with AI chatbots impacts users' emotions and social lives. Over four weeks, 981 adults engaged with a modified version of GPT-4, experiencing different interaction styles (text, neutral voice, engag
 Top 7 AI Image Generators to Try in 2025Apr 23, 2025 am 09:27 AM
Top 7 AI Image Generators to Try in 2025Apr 23, 2025 am 09:27 AMAI image generation technology has made great progress in 2025, from initially blurred abstract images to today's realistic photos and stunning works of art, it can do everything. This article will explore the most powerful and creative image generation models on the market today, which perform well in photoreality, creative diversity, moral implementation, and the application of various in-progress works. Digital artists, marketers, content creators, and curious people interested in these tools and their benefits are increasingly important in the digital ecosystem based on images. Table of contents Best AI Image Generators of 2025 Midjourney DALL-E 3 (OpenAI) Flux AI Stable Diffusion I
 What Are Views in SQL?Apr 23, 2025 am 09:26 AM
What Are Views in SQL?Apr 23, 2025 am 09:26 AMIntroduction SQL, the Structured Query Language, is fundamental to managing and manipulating relational databases. A powerful SQL feature is the use of views, which streamline complex queries, boosting database efficiency and manageability. This ski
 How can Simpson's Paradox Uncover Hidden Trends in Data? - Analytics VidhyaApr 23, 2025 am 09:20 AM
How can Simpson's Paradox Uncover Hidden Trends in Data? - Analytics VidhyaApr 23, 2025 am 09:20 AMSimpson's Paradox: Unveiling Hidden Trends in Data Have you ever been misled by statistics? Simpson's Paradox demonstrates how aggregated data can obscure crucial trends, revealing the importance of analyzing data at multiple levels. This concise gui
 What is Nominal Data? - Analytics VidhyaApr 23, 2025 am 09:13 AM
What is Nominal Data? - Analytics VidhyaApr 23, 2025 am 09:13 AMIntroduction Nominal data forms the bedrock of data analysis, playing a crucial role in various fields like statistics, computer science, psychology, and marketing. This article delves into the characteristics, applications, and distinctions of nomi
 What is One-Shot Prompting? - Analytics VidhyaApr 23, 2025 am 09:12 AM
What is One-Shot Prompting? - Analytics VidhyaApr 23, 2025 am 09:12 AMIntroduction In the dynamic world of machine learning, efficiently generating precise responses using minimal data is paramount. One-shot prompting offers a powerful solution, enabling AI models to execute specific tasks using just a single example
 Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AM
Tesla's Robovan Was The Hidden Gem In 2024's Robotaxi TeaserApr 22, 2025 am 11:48 AMSince 2008, I've championed the shared-ride van—initially dubbed the "robotjitney," later the "vansit"—as the future of urban transportation. I foresee these vehicles as the 21st century's next-generation transit solution, surpas


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 English version
Recommended: Win version, supports code prompts!

