
Home >Technology peripherals >AI >This sparse training method for large models with high accuracy and low resource consumption has been found.
This sparse training method for large models with high accuracy and low resource consumption has been found.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-13 19:01:011542browse
Recently, Alibaba Cloud Machine Learning PAI's paper "Parameter-Efficient Sparsity for Large Language Models Fine-Tuning" on sparse training of large models was accepted by IJCAI 2022, the top artificial intelligence conference.
The paper proposes a parameter-efficient sparse training algorithm PST. By analyzing the importance index of the weight, it is concluded that it has two characteristics: low rank and structure. Based on this conclusion, the PST algorithm introduces two sets of small matrices to calculate the importance of weights. Compared with the original need for a matrix as large as the weight to save and update the importance index, the amount of parameters that need to be updated for sparse training is greatly reduced. Compared with commonly used sparse training algorithms, the PST algorithm can achieve similar sparse model accuracy while only updating 1.5% of parameters.
Background
In recent years, major companies and research institutions have proposed a variety of large models. These large models have parameters ranging from tens of billions to tens of thousands. It ranges from billions to hundreds of billions, and even super-large models of tens of trillions have appeared. These models require a large amount of hardware resources to train and deploy, which makes them difficult to implement. Therefore, how to reduce the resources required for large model training and deployment has become an urgent problem.
Model compression technology can effectively reduce the resources required for model deployment. By removing some weights, sparse calculations in the model can be converted from dense calculations to sparse calculations, thereby reducing memory usage and speeding up calculations. . At the same time, compared with other model compression methods (structured pruning/quantization), sparseness can achieve a higher compression rate while ensuring model accuracy, and is more suitable for large models with a large number of parameters.
Challenge
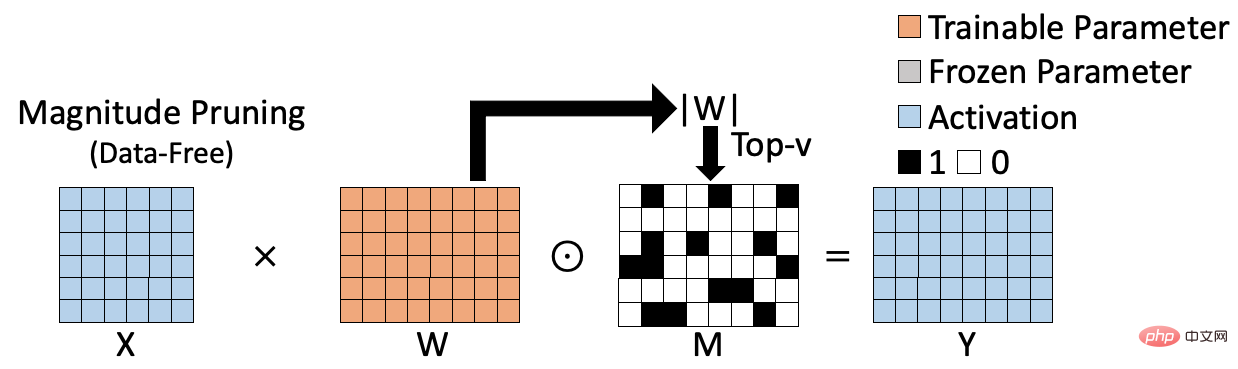
The existing sparse training methods can be divided into two categories, one is weight-based data-free sparse algorithm; the other is data-based data -driven sparse algorithm. The weight-based sparse algorithm is shown in the figure below, such as magnitude pruning [1], which evaluates the importance of the weight by calculating the L1 norm of the weight, and generates the corresponding sparse result based on this. The weight-based sparse algorithm is computationally efficient and does not require the participation of training data, but the calculated importance index is not accurate enough, thus affecting the accuracy of the final sparse model.
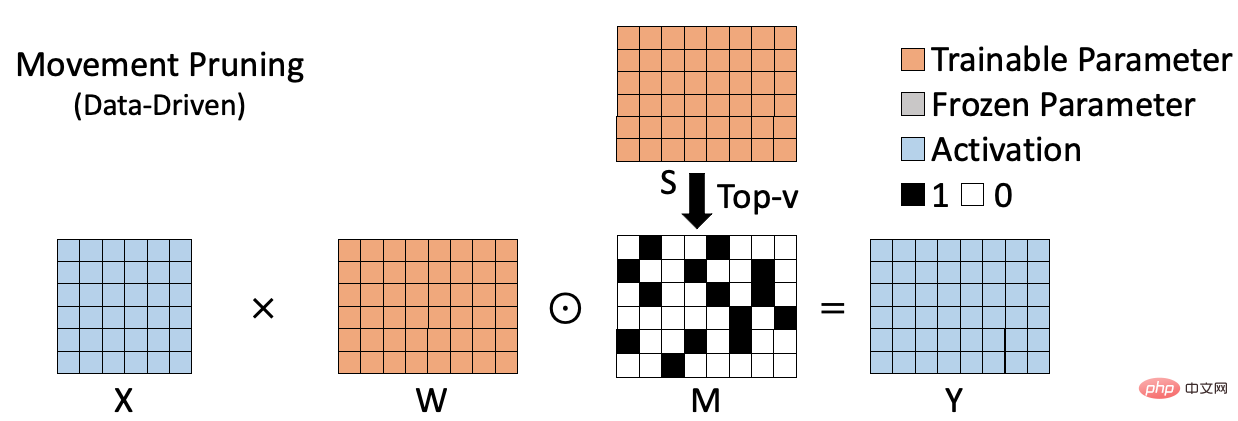
The data-based sparse algorithm is shown in the figure below, such as movement pruning[2], which measures the importance of the weight by calculating the product of the weight and the corresponding gradient. sexual indicators. This type of method takes into account the role of weights on specific data sets and therefore can more accurately assess the importance of weights. However, due to the need to calculate and save the importance of each weight, this type of method often requires additional space to store the importance index (S in the figure). At the same time, compared with weight-based sparse methods, the calculation process is often more complex. These shortcomings become more obvious as the size of the model increases.
To sum up, the previous sparse algorithms are either efficient but not accurate enough (weight-based algorithm), or accurate but not efficient enough (data-based algorithm). algorithm). Therefore, we hope to propose an efficient sparse algorithm that can accurately and efficiently perform sparse training on large models.
Breaking
The problem with data-based sparse algorithms is that they generally introduce additional parameters of the same size as the weights to learn the importance of the weights, which brings us to Think about how to reduce the importance of introducing extra parameters to calculate weights. First, in order to maximize the use of existing information to calculate the importance of weights, we design the importance index of weights as the following formula:
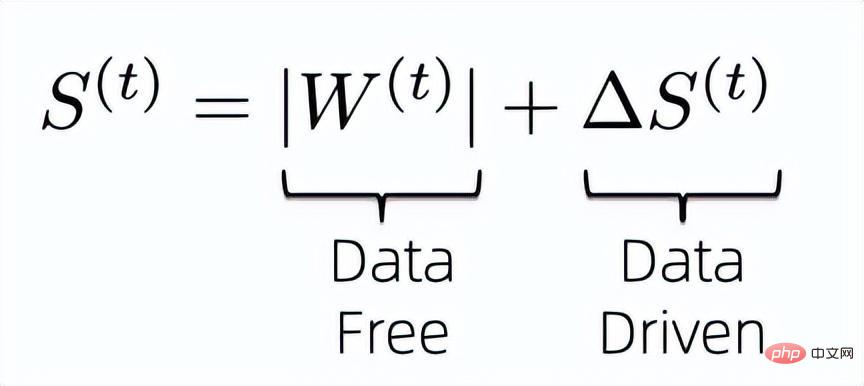
That is, we combine data-free and data-driven indicators to jointly determine the importance of the final model weights. It is known that the previous data-free importance index does not require additional parameters to save and is efficient in calculation, so what we need to solve is how to compress the additional training parameters introduced by the later data-driven importance index.
Based on the previous sparse algorithm, the data-driven importance index can be designed as

, so we started to analyze the redundancy of the importance indicator calculated by this formula. First of all, based on previous work, it is known that both weights and corresponding gradients have obvious low-rank properties [3, 4], so we can deduce that the importance index also has low-rank properties, so we can introduce two low-rank properties A small matrix to represent the original importance indicator matrix that is as large as the weights.
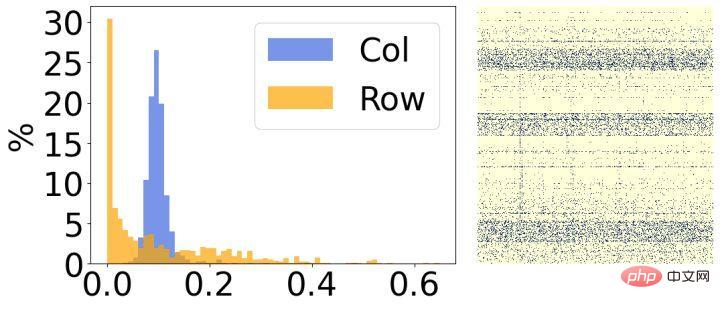
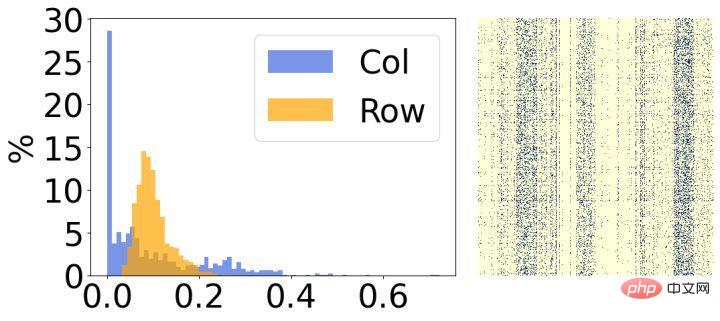
Secondly, we analyzed the results after model sparseness and found that they have obvious structural characteristics. As shown in the figure above, the right side of each picture is the visualization result of the final sparse weight, and the left side is a histogram that counts the corresponding sparsity rate of each row/column. It can be seen that most of the weights in 30% of the rows in the left picture have been removed, and conversely, most of the weights in 30% of the columns in the right picture have been removed. Based on this phenomenon, we introduce two small structured matrices to evaluate the importance of each row/column of weights.
Based on the above analysis, we found that the data-driven importance index has low rank and structure, so we can convert it into the following representation:
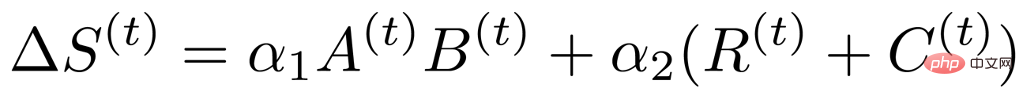
where A and B represent low rank, and R and C represent structure. Through such analysis, the importance index matrix, which was originally as large as the weight, was decomposed into four small matrices, thus greatly reducing the training parameters involved in sparse training. At the same time, in order to further reduce training parameters, we decomposed the weight update into two small matrices U and V based on the previous method, so the final importance index formula becomes the following form:
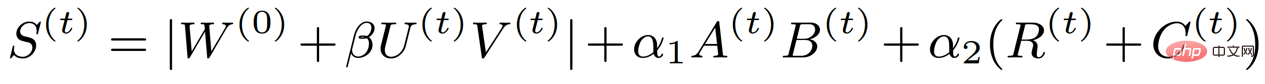
The corresponding algorithm framework diagram is as follows:
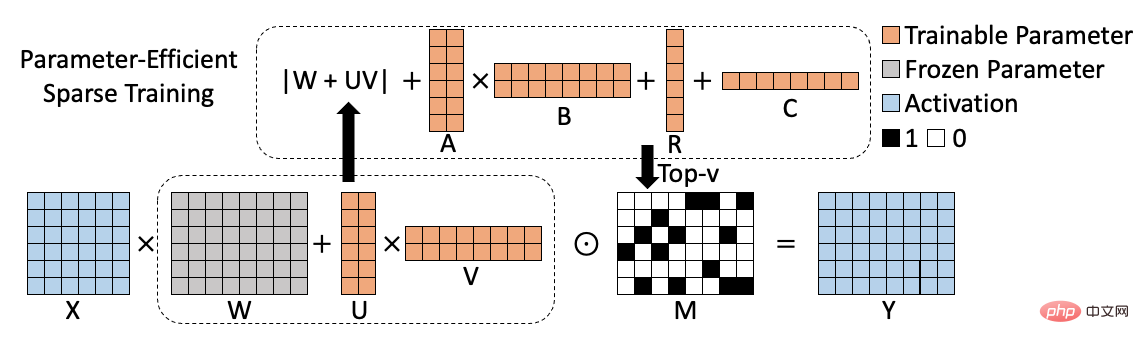
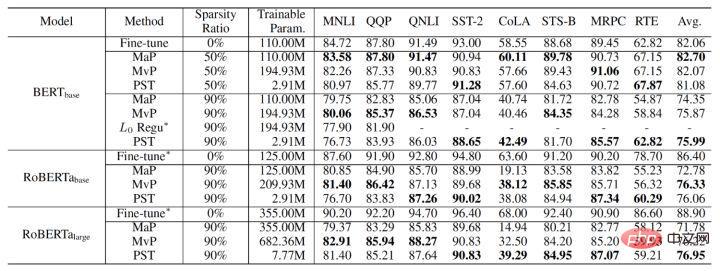
The final PST algorithm experimental results are as follows. We are Compared with magnitude pruning and movement pruning on NLU (BERT, RoBERTa) and NLG (GPT-2) tasks, at a sparsity rate of 90%, PST can achieve model accuracy comparable to the previous algorithm on most data sets, but Only 1.5% of training parameters are required.

PST technology has been integrated into the model compression library of Alibaba Cloud Machine Learning PAI, as well as the Alicemind platform large model In the sparse training function. It has brought performance acceleration to the use of large models within the Alibaba Group. On the tens of billions of large model PLUGs, PST can accelerate 2.5 times without reducing model accuracy and reduce memory usage by 10 times compared with the original sparse training. . At present, Alibaba Cloud Machine Learning PAI has been widely used in various industries, providing full-link AI development services, realizing independent and controllable AI solutions for enterprises, and comprehensively improving the efficiency of machine learning engineering.
Paper name: Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
Paper author: Yuchao Li, Fuli Luo, Chuanqi Tan, Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
Paper pdf link: https://arxiv.org/pdf/2205.11005.pdf
The above is the detailed content of This sparse training method for large models with high accuracy and low resource consumption has been found.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology