
Home >Technology peripherals >AI >Two semi-supervised label propagation algorithms in sklearn: LabelPropagation and LabelSpreading
Two semi-supervised label propagation algorithms in sklearn: LabelPropagation and LabelSpreading

- 王林forward
- 2023-04-12 19:28:041171browse
The label propagation algorithm is a semi-supervised machine learning algorithm that assigns labels to previously unlabeled data points. To use this algorithm in machine learning, only a small fraction of the examples have labels or classifications. These labels are propagated to unlabeled data points during the algorithm's modeling, fitting, and prediction processes.

LabelPropagation
LabelPropagation is a fast algorithm for finding communities in graphs. It uses only the network structure as a guide to detect these connections and does not require a predefined objective function or a priori information about the population. Tag propagation is achieved by propagating tags in the network and forming connections based on the tag propagation process.
Close tags are usually given the same tag. A single label can dominate in densely connected groups of nodes, but will have trouble in sparsely connected regions. Labels will be restricted to a tightly connected group of nodes, and when the algorithm is complete, those nodes that end up with the same label can be considered part of the same connection. The algorithm uses graph theory and is as follows:-
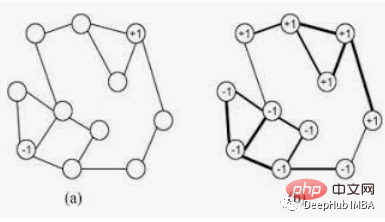
LabelPropagation algorithm works in the following way:-
- Each node uses a unique Tag is initialized.
- These tags spread through the Internet.
- In each propagation iteration, each node updates its label to the label to which the maximum number of neighbors belongs.
- The label propagation algorithm reaches convergence when each node has a majority of labels of its neighbors.
- The label propagation algorithm stops if convergence or a user-defined maximum number of iterations is reached.
To demonstrate how the LabelPropagation algorithm works, we use the Pima Indians data set. When creating the program, I imported the libraries required to run it

Copy a copy of the data and use the lable column as the training target

Use matplotlib visualization:

Use random The number generator randomizes 70% of the labels in the dataset. Then random labels are assigned -1:-
After preprocessing the data, define the dependent and independent variables, which are y and X respectively. The y variable is the last column and the
 ##The accuracy rate of finding it is 76.9%.
##The accuracy rate of finding it is 76.9%.
 Let’s take a look at another algorithm, LabelSpreading.
Let’s take a look at another algorithm, LabelSpreading.
LabelSpreading
LabelSpreading is also a popular semi-supervised learning method. Create a graph connecting the samples in the training dataset and propagate known labels through the edges of the graph to label unlabeled examples. 
L is the Laplacian matrix, D is the degree matrix, and A is the adjacency matrix.
The following is a simple example of undirected graph labeling and the result of its Laplacian matrix

This article will use the sonar data set to demonstrate how to use sklearn's LabelSpreading function.
There are more libraries here than above, so a brief explanation:
- Numpy performs numerical calculations and creates Numpy arrays
- Pandas processes data
- Sklearn performs machine learning operations
- Matplotlib and seaborn to visualize data and provide statistical information for visual data
- Warning, used to ignore warnings that occur during program execution
After the import is completed, use pandas to read the data set:

I used seaborn to create the heat map:-

First do a simple preprocessing, delete highly correlated columns, thus reducing the number of columns from 61 to 58:

Then re-shuffle the data row, so that predictions are generally more accurate in shuffled data sets, make a copy of the data set and define y_orig as the training target:

Use matplotlib to plot the data points 2D Scatter Plot: -

Randomize 60% of the labels in the dataset using a random number generator. Then random labels are assigned -1:-

After preprocessing the data, define the dependent and independent variables, which are y and X respectively. The y variable is the last column and the
Using this method, we can achieve an accuracy of 87.98%:-
Simple comparison
1. Labelspreading contains alpha= 0.2, alpha is called the clamping coefficient, which refers to the relative amount of using the information of its neighbors instead of its initial label. If it is 0, it means retaining the initial label information. If it is 1, it means replacing all the initial information; set alpha=0.2 , meaning that 80% of the original label information is always retained; 
The above is the detailed content of Two semi-supervised label propagation algorithms in sklearn: LabelPropagation and LabelSpreading. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology