
Home >Technology peripherals >AI >Deep convolutional generative adversarial network in practice
Deep convolutional generative adversarial network in practice

- 王林forward
- 2023-04-12 14:22:12928browse
Translator | Zhu Xianzhong
Reviewer | Sun Shujuan

Red Vineyard (Author: Vincent van Gogh)
According to the New York Times, 90% of energy in data centers is wasted because most of the data collected by companies is never analyzed or used in any form. More specifically, this is called "Dark Data."
"Dark data" refers to data obtained through various computer network operations but not used in any way to derive insights or make decisions. An organization's ability to collect data may exceed its throughput of analyzing it. In some cases, organizations may not even know that data is being collected. IBM estimates that approximately 90% of data generated by sensors and analog-to-digital conversion is never used. — Wikipedia definition of “dark data” One of the key reasons why this data is not useful for drawing any insights from a machine learning perspective is the lack of labels. This makes unsupervised learning algorithms very attractive for mining the potential of this data.
Generative Adversarial Network
In 2014, Ian Goodfello et al. proposed a new method to estimate generative models through an adversarial process. It involves training two independent models simultaneously: a generator model that attempts to model the data distribution, and a discriminator that attempts to classify the input as training data or fake data via the generator.
This paper sets a very important milestone in the field of modern machine learning and opens up a new way for unsupervised learning. In 2015, the deep convolutional GAN paper released by Radford et al. successfully generated 2D images by applying the principles of convolutional networks, thus continuing to build on this idea in the paper.
Through this article, I try to explain the key components discussed in the above paper and implement them using the PyTorch framework. What are the compelling aspects of GAN?
In order to understand the importance of GANs or DCGANs (Deep Convolutional Generative Adversarial Networks), let’s first understand what makes them so popular.
1. Since most real data is unlabeled, the unsupervised learning properties of GANs make it ideal for such use cases.
2. Generators and discriminators act as very good feature extractors for use cases with limited labeled data, or generate additional data to improve quadratic model training, as they can generate fake samples instead Use augmentation techniques.
3. GANs provide an alternative to maximum likelihood techniques. Their adversarial learning process and non-heuristic cost function make them very attractive for reinforcement learning.
4. The research on GAN is very attractive, and its results have caused widespread debate about the impact of ML/DL. For example, Deepfake is an application of GAN that overlays a person's face on a target person, which is very controversial in nature because it has the potential to be used for nefarious purposes.
5. Last but not least, working with this kind of network is cool and all the new research in this area is fascinating.
Overall Architecture
Architecture of Deep Convolutional GAN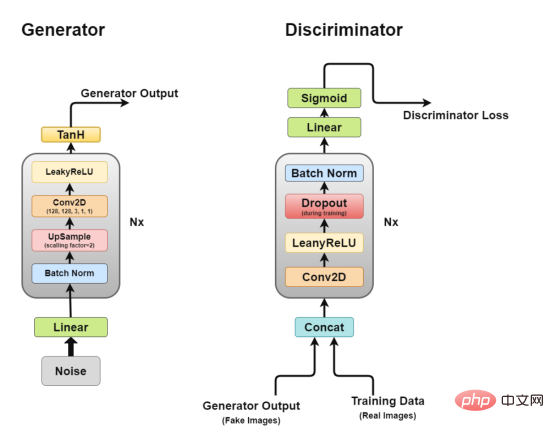 As we discussed earlier, we will work through DCGAN, DCGAN Trying to implement the core idea of GAN, a convolutional network for generating realistic images.
As we discussed earlier, we will work through DCGAN, DCGAN Trying to implement the core idea of GAN, a convolutional network for generating realistic images.
DCGAN consists of two independent models: a generator (G) that tries to model random noise vectors as input and tries to learn the data distribution to generate fake samples, and a discriminator (D) that gets the training data (real samples) and generated data (fake samples) and try to classify them. The struggle between these two models is what we call an adversarial training process, where one party's loss is the other's gain.
Generator
Generator architecture diagram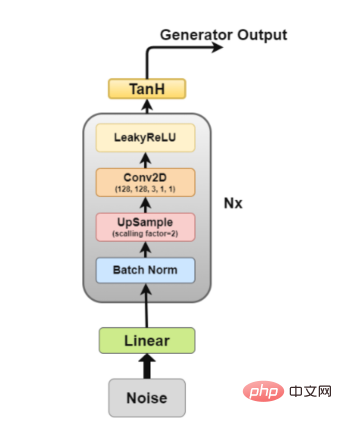 The generator is the part we are most interested in because it is a generator that generates fake images to try to fool the discriminator.
The generator is the part we are most interested in because it is a generator that generates fake images to try to fool the discriminator.
Now, let’s look at the generator architecture in more detail.
- Linear layer: The noise vector is input into the fully connected layer, and its output is transformed into a 4D tensor.
- Batch normalization layer: Stabilizes learning by normalizing the input to zero mean and unit variance. This avoids training problems such as vanishing or exploding gradients and allows gradients to flow through the network.
- Upsampling layer: According to my interpretation of the paper, it mentions using upsampling and then applying a simple convolutional layer on top of it, instead of using a convolutional transpose layer for upsampling. But I've seen some people use convolution transpose, so the specific application strategy is up to you.
- 2D Convolutional Layer: When we upsample a matrix, we pass it through the convolutional layer with a stride of 1 and use the same padding, allowing it to learn from the upsampled data.
- ReLU layer: This article mentions using ReLU instead of LeakyReLU as the generator because it allows the model to quickly saturate and cover the color space of the training distribution.
- TanH activation layer: This article recommends that we use the TanH activation function to calculate the generator output, but does not explain in detail why. If we had to make a guess, this is because the properties of TanH allow the model to converge faster.
Among them, layer 2 to layer 5 constitute the core generator block, which can be repeated N times to obtain the desired output image shape.
The following is the key code of how we implement it in PyTorch (for the complete source code, see the address https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
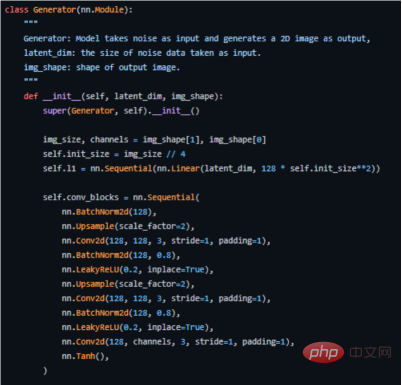
Use the generator of the PyTorch framework to implement the key code
Discriminator
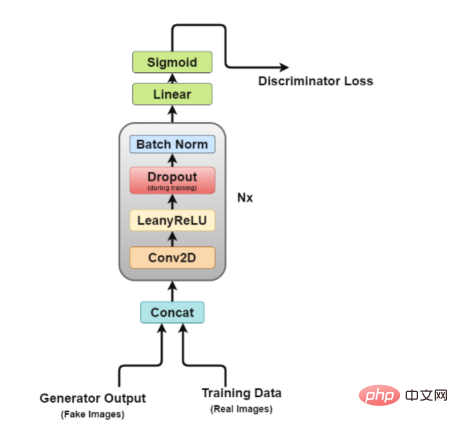
Discriminator architecture Figure
It is easy to see from the figure that the discriminator is more like an image classification network, but with some minor adjustments. For example, instead of using any pooling layers for downsampling, it uses a special convolutional layer called a stride convolutional layer, which allows it to learn its own downsampling.
Now, let’s take a closer look at the discriminator architecture.
- Concat Layer: This layer combines fake and real images in a batch to feed to the discriminator, but this can also be done separately, just to obtain the generator loss.
- Convolutional layer: We use stride convolution here, which allows us to downsample images and learn filters in one training session.
- LeakyReLU layer: As the paper mentions, it was found that Leakyrelus is very useful for the discriminator as it allows easier training compared to the maximum output function of the original GAN paper.
- Dropout layer: used for training only, helps avoid overfitting. The model has a tendency to memorize real image data, at which point the training may break down because the discriminator can no longer be "fooled" by the generator.
- Batch Normalization Layer: The paper mentions that it applies batch normalization at the end of each discriminator block (except the first one). The reason mentioned in the paper is that applying batch normalization on each layer can lead to sample oscillations and model instability.
- Linear Layer: A fully connected layer that takes a reshaped vector from a 2D batch normalization layer applied.
- Sigmoid Activation Layer: Since we are dealing with binary classification of the discriminator output, the logical choice of Sigmoidd layer is made.
In this architecture, layer 2 to layer 5 form the core block of the discriminator, and the calculation can be repeated N times to make the model more complex for each training data.
Here's how we implement it in PyTorch (for the complete source code, see the address https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
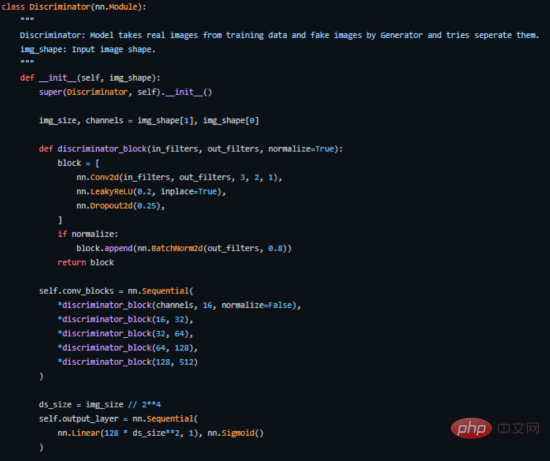
Key code part of the discriminator implemented with PyTorch
Adversarial training
We train the discriminator (D) to maximize the correct The probability that a label is assigned to a training sample and a sample from the generator (G), which can be done by minimizing log(D(x)). We simultaneously train G to minimize log(1 − D(G(z))), where z represents the noise vector. In other words, both D and G use the value function V (G, D) to play the following two-player minimax game:
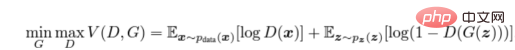
Adversarial cost function calculation formula
In a practical application environment, the above equation may not provide enough gradients for G to learn well. In the early stages of learning, when G is poor, D can reject samples with high confidence because they are significantly different from the training data. In this case, the log(1 − D(G(z))) function reaches saturation. Instead of training G to minimize log(1 − D(G(z))), we train G to maximize logD(G(z)). This objective function generates the same fixed points for dynamic G and D, but provides stronger gradient calculations early in learning. ——arxiv paper
This can be tricky since we are training two models at the same time, and GANs are notoriously difficult to train, which we will discuss later One of the known issues is called mode collapse.
The paper recommends using the Adam optimizer with a learning rate of 0.0002. Such a low learning rate indicates that GANs tend to diverge very quickly. It also uses first- and second-order momentum with values of 0.5 and 0.999 to further speed up training. The model is initialized to a normal weighted distribution with a mean of zero and a standard deviation of 0.02.
The following shows how we implement a training loop for this (see https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py for the complete source code).
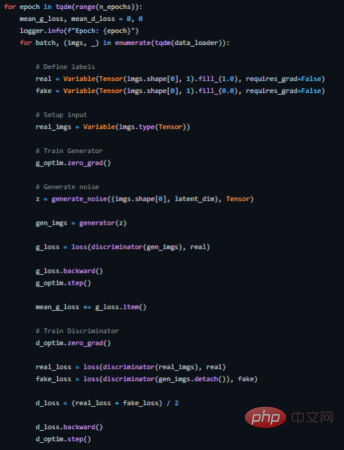
DCGAN’s training loop
Mode Collapse
Ideally, we want the generator to produce a variety of outputs. For example, if it generates faces, it should generate a new face for every random input. However, if the generator produces sufficiently good enough plausible output to fool the discriminator, it may produce the same output over and over again.
Eventually, the generator will over-optimize a single discriminator and rotate between a small set of outputs, a situation called "mode collapse".
The following methods can be used to correct the situation.
- Wasserstein loss function method (Wasserstein loss): The Wasserstein loss function mitigates mode collapse by letting you train the discriminator to optimality without worrying about vanishing gradients. If the discriminator does not get stuck in a local minimum, it will learn to reject the stable output of the generator. Therefore, generators have to try new things.
- Unrolled GAN method (Unrolled GANs): Unrolled GAN uses a generator loss function, which not only contains the classification of the current discriminator, but also contains the output of future discriminator versions. Therefore, the generator cannot be over-optimized for a single discriminator.
APPS
- Style Shift: Face retouching apps are all the rage right now. Among them, facial aging, crying face and celebrity face deformation are just some of the applications that have become widely popular on social media.
- Video Games: Texture generation of 3D objects and image-based scene generation are just some of the applications that are helping the video game industry develop bigger games faster.
- Film Industry: CGI (computer-generated imagery) has become a big part of model movies, and with the potential brought by GANs, filmmakers can now dream bigger than ever before.
- Speech Generation: Some companies are using GANs to improve text-to-speech applications by using them to generate more realistic speech.
- Image Restoration: Use GANs to denoise and restore damaged images, colorize historical images, and improve old videos by generating missing frames to increase frame rates.
Conclusion
In short, the paper on GAN and DCGAN mentioned above is simply a landmark paper, because it opened up a new chapter in unsupervised learning. A new way. The adversarial training method proposed in it provides a new method for training models that closely simulate the real-world learning process. So it will be very interesting to see how this field develops.
Finally, you can find the complete implementation source code of the sample project in this article on my GitHub source code repository. Translator Introduction
Zhu Xianzhong, 51CTO community editor, computer teacher at a university in Weifang, and a veteran in the freelance programming industry.
Original title:Implementing Deep Convolutional GAN, author: Akash Agnihotri
The above is the detailed content of Deep convolutional generative adversarial network in practice. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology