
Home >Technology peripherals >AI >A preliminary exploration into the evolution of natural language pre-training technology
A preliminary exploration into the evolution of natural language pre-training technology

- 王林forward
- 2023-04-11 22:04:041305browse
Three levels of artificial intelligence:
Computing functions: data storage and computing capabilities, machines are far better than humans.
Perceptual functions: vision, hearing and other abilities. Machines are already comparable to humans in the fields of speech recognition and image recognition.
Cognitive intelligence: For tasks such as natural language processing, common sense modeling and reasoning, machines still have a long way to go.
Natural language processing belongs to the category of cognitive intelligence. Because natural language has the characteristics of abstraction, combination, ambiguity, knowledge, and evolution, it brings great challenges to machine processing. Some people use natural language to process natural language. Language processing is called the crown jewel of artificial intelligence. In recent years, pre-trained language models represented by BERT have emerged, bringing natural language processing into a new era: pre-trained language models fine-tuned for specific tasks. This article attempts to sort out the evolution of natural language pre-training technology, with a view to communicating and learning with everyone. We welcome criticism and correction of shortcomings and fallacies.
1. Ancient - Word Representation
1.1 One-hot Encoding
Use a vector of the size of a vocabulary to represent a word, where the value of the corresponding position of the word is 1, and the remaining positions are 0. Disadvantages:
- High-dimensional sparsity
- Cannot express semantic similarity: the One-hot vector similarity of two synonyms is 0
1.2 Distribution Expression
Distributed semantics hypothesis: similar words have similar contexts, and the semantics of words can be represented by context. Based on this idea, the context distribution of each word can be used to represent words.
1.2.1 Word frequency representation
Based on the corpus, the context of the word is used to construct a co-occurrence frequency table. Each row of the word table represents the vector representation of a word. Different language information can be captured through different context selections. For example, if the words in the fixed window around the word in the sentence are used as the context, more local information of the word will be captured: lexical and syntactic information. If the document is used as the context, Capture more of the topic information represented by the word. Disadvantages:
- High frequency word problem.
- Cannot reflect higher-order relationships: (A, B) (B, C) (C, D) !=> (A, D).
- There is still a sparsity problem.
1.2.2 TF-IDF representation
Replace the value in word frequency representation with TF-IDF, which mainly alleviates the problem of high-frequency words in word frequency representation.
1.2.3 Point mutual information representation
It also alleviates the high-frequency word problem of word frequency representation. The value in the word frequency representation is replaced by the point mutual information of the word:

1.2.4 LSA
By performing Singular Value Decomposition (SVD) on the word frequency matrix, a low-dimensional, continuous, dense vector representation of each word can be obtained , can be considered to represent the latent semantics of the word, this method is also called latent semantic analysis (Latent Semantic Analysis, LSA).

LSA alleviates problems such as high-frequency words, high-order relationships, sparsity, etc., and the effect is still good in traditional machine learning algorithms, but there are also some shortcomings:
- When the vocabulary list is large, SVD is slower.
- Unable to catch up with new ones. When the corpus changes or new corpus is added, it needs to be retrained.
2. Modern times - static word vectors
The orderliness of text and the co-occurrence relationship between words provide natural self-supervised learning signals for natural language processing , enabling the system to learn knowledge from text without additional manual annotation.
2.1 Word2Vec
2.1.1 CBOW
CBOW(Continous Bag-of-Words) uses the context (window) to predict the target word, and combines the words of the context words The vectors are arithmetic averaged and then the probability of the target word is predicted.

2.1.2 Skip-gram
Skip-gram predicts context by word.

2.2 GloVe
GloVe (Global Vectors for Word Representation) uses word vectors to predict the co-occurrence matrix of words and implements implicit matrix decomposition . First, a distance-weighted co-occurrence matrix X is constructed based on the context window of the word, and then the vector of the word and context is used to fit the co-occurrence matrix X:

The loss function is:



 ##3.1.1 Attention model
##3.1.1 Attention model
The attention model can be understood as a mechanism for weighting a vector sequence and the calculation of weight.
 3.1.2 Multi-Head Self-Attention
3.1.2 Multi-Head Self-Attention
The attention model used in Transformer can be expressed as:
 When Q, K, and V come from the same vector sequence, it becomes a self-attention model.
When Q, K, and V come from the same vector sequence, it becomes a self-attention model.
Multi-head self-attention: Set up multiple groups of self-attention models, splice their output vectors, and map them to the dimension size of the Transformer hidden layer through a linear mapping. The multi-head self-attention model can be understood as an ensemble of multiple self-attention models.

##3.1.3 Position encoding
3.1.4 Others
Advantages:
Compared with RNN, it can model longer-distance dependencies, and the attention mechanism will The distance between words is reduced to 1, resulting in stronger ability to model long sequence data.
- Compared with RNN, it can better utilize the parallel computing power of GPU.
- Strong expressive ability.
- Disadvantages:
Compared with RNN, the parameters are larger, which increases the difficulty of training and requires more training data.
- 3.2 Autoregressive Language Model
Model structure

ELMo independently models forward and backward language models through LSTM, forward language model:

Backward language model:

Optimization goal
Maximization:

Downstream Application
After ELMo is trained, the following vectors can be obtained for use in downstream tasks.

is the word embedding obtained by the input layer, and is the result of splicing the forward and backward LSTM outputs.
When used in downstream tasks, the vectors of each layer can be weighted to obtain a vector representation of ELMo, and a weight can be used to scale the ELMo vector.

Different levels of hidden layer vectors contain text information at different levels or granularities:
- The top layer encodes more semantic information
- The bottom layer encodes more lexical and syntactic information
3.2.2 GPT series
GPT-1
Model structure
In GPT-1 (Generative Pre-Training), it is a one-way language model that uses 12 transformer block structures as decoders. Each transformer block is a multi-head self-attention mechanism. , and then obtain the probability distribution of the output through full connection.


- U: One-hot vector of word
- We: Word vector matrix
- Wp: Position vector matrix
Optimization goal
Maximization:

Downstream application
In the downstream task, for a labeled data set, each instance has an input token:, which consists of the label. First, these tokens are input into the trained pre-training model to obtain the final feature vector. Then the prediction result is obtained through a fully connected layer:

The goal of the downstream supervised task is to maximize:

In order to prevent catastrophic forgetting problems, a certain weight of pre-training loss can be added to the fine-tuning loss, usually pre-training loss.


GPT-2
The core idea of GPT-2 can be summarized as: any supervised task is a subset of the language model. When the capacity of the model is very large and the amount of data is rich enough, training alone The learning of language models can complete other supervised learning tasks. Therefore, GPT-2 did not carry out too many structural innovations and designs on the GPT-1 network. It just used more network parameters and a larger data set. The goal was to train a word vector with stronger generalization ability. Model.
Among the 8 language model tasks, GPT-2 has 7 surpassed the state-of-the-art methods at the time through zero-shot learning alone (of course, some tasks are still not as good as the supervised model) good). The biggest contribution of GPT-2 is to verify that word vector models trained with massive data and a large number of parameters can be transferred to other categories of tasks without additional training.
At the same time, GPT-2 showed that as the model capacity and training data volume (quality) increase, there is room for further development of its potential. Based on this idea, GPT-3 was born.
GPT-3
There is still no change in the model structure, but the model capacity, training data volume and quality are increased. It is known as a giant, and the effect is also very good.
Summary

From GPT-1 to GPT-3, as the model capacity and the amount of training data increase, the language knowledge learned by the model also increases. Rich, the paradigm of natural language processing has gradually changed from "pre-training model fine-tuning" to "pre-training model zero-shot/few-shot learning". The disadvantage of GPT is that it uses a one-way language model. BERT has proven that a two-way language model can improve the model effect.
3.2.3 XLNet
XLNet introduces two-way contextual information through the permutation language model (Permutation Language Model). It does not introduce special tags and avoids inconsistent token distribution in the pre-training and fine-tuning phases. The problem. At the same time, Transformer-XL is used as the main structure of the model, which has better effects on long texts.
Permutation language model
The goal of the permutation language model is:

is the set of all possible permutations of the text sequence.
Two-stream self-attention mechanism
- The purpose of the two-stream self-attention mechanism (Two-stream Self-attention) is: by transforming the Transformer, when inputting a normal text sequence , implement the permutation language model:
- Content representation: the information contained
- Query representation: only the information contained


This method uses the position information of the predicted word.
Downstream application
When applying downstream tasks, no query representation is required, and no mask is required.
3.3 Self-encoding language model
3.3.1 BERT
Masked language model
Masked language model (MLM), random Partially masking words, and then using contextual information to make predictions. There is a problem with MLM, there is a mismatch between pre-training and fine-tuning, because the [MASK] token is never seen during fine-tuning. To solve this problem, BERT does not always replace the "masked" word piece token with the actual [MASK] token. The training data generator randomly selects 15% of the tokens and then:
- 80% probability: replaces them with the [MASK] token.
- 10% probability: replace with a random token from the vocabulary list.
- 10% probability: token remains unchanged.
In native BERT, tokens are masked, and whole words or phrases (N-Gram) can be masked.
Next sentence prediction
Next sentence prediction (NSP): When sentences A and B are selected as pre-training samples, B has a 50% chance of being the next sentence of A, and a 50% chance may be random sentences from the corpus.
Input layer

Model structure

The classic "pre-training model fine-tuning" Paradigm,theme structure is stacked multi-layer Transformers.
3.3.2 RoBERTa
RoBERTa (Robustly Optimized BERT Pretraining Approach) does not drastically improve BERT, but only conducts detailed experiments on every design detail of BERT to find room for improvement of BERT.
- Dynamic mask: The original method is to set the mask and fix it when building the data set. The improved method is to randomly mask the data when entering the data into the model in each round of training, which increases the accuracy of the data. Diversity.
- Abandon NSP tasks: Experiments have proven that not using NSP tasks can improve performance for most tasks.
- More training data, larger batches, and longer pre-training steps.
- Larger vocabulary: Using the byte-level BPE vocabulary of SentencePiece instead of the character-level BPE vocabulary of WordPiece, there will be almost no unregistered words.
3.3.3 ALBERT
BERT has a relatively large number of parameters. The main goal of ALBERT (A Lite BERT) is to reduce the number of parameters:
- BERT words The vector dimension is the same as the hidden layer dimension, and word vectors are context-independent. However, BERT's Transformer layer needs and can learn sufficient contextual information, so the hidden layer vector dimension should be much larger than the word vector dimension. When increasing to improve performance, there is no need to increase the size because the word vector space may be sufficient for the amount of information that needs to be embedded.
- Solution: The word vector is transformed into H dimension through the fully connected layer.
- Word vector parameter decomposition (Factorized embedding parameterization).
- Cross-layer parameter sharing: Transformer blocks of different layers share parameters.
- Sentence-order prediction (SOP), learning subtle semantic differences and discourse coherence.
3.4 Generative Confrontation - ELECTRA
ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) introduces the model of generator and discriminator, transforming the generative Masked language model into (MLM) pre-training task was changed to a discriminative Replaced token detection (RTD) task, which determines whether the current token has been replaced by the language model, which is similar to the idea of GAN.

The generator predicts the token at the mask position in the input text:


The input of the discriminator is the output of the generator, and the discriminator predicts whether the words at each position have been replaced:

In addition, some optimizations have been made:
- The generator and discriminator are each a BERT, which scales the generator BERT parameters.
- Word vector parameter decomposition.
- Generator and discriminator parameter sharing: input layer parameter sharing, including word vector matrix and position vector matrix.
Only use the discriminator, not the generator, in downstream tasks.
3.5 Long Text Processing - Transformer-XL
Transformer A common strategy for processing long text is to split the text into fixed-length blocks and encode each block independently, without any interruption between blocks. Information exchange.

In order to optimize the modeling of long text, Transformer-XL uses two technologies: Segment-Level Recurrence with State Reuse and Relative Positional Encodings.
3.5.1 Block-level loop of state multiplexing
Transformer-XL is also input in the form of fixed-length segments during training. The difference is that Transformer-XL’s previous The state of the fragment is cached and then the hidden state of the previous time slice is reused when calculating the current segment, giving Transformer-XL the ability to model longer-term dependencies.
Two consecutive segments of length L and. The state of the hidden layer node is expressed as, where d is the dimension of the hidden layer node. The calculation process of the status of the hidden layer node is:

Another benefit of fragment recursion is the improvement in reasoning speed. Compared with Transformer's autoregressive architecture, which can only advance one time slice at a time, Transformer-XL's reasoning process directly reuses the representation of the previous fragment instead of Calculate from scratch and improve the reasoning process to reasoning in fragments.

3.5.2 Relative position encoding
In Transformer, the self-attention model can be expressed as:
 ## The complete expression of
## The complete expression of



- Change 1: Medium, It is split into a true sum, which means that the input sequence and positional encoding no longer share weights.
- Change 2: In, absolute position encoding is replaced by relative position encoding.
- Change 3: Two new learnable parameters are introduced to replace the query vector in Transformer. Indicates that the corresponding query position vectors are the same for all query positions. That is, regardless of the query position, the attention bias for different words remains consistent.
- After improvement, the meaning of each part:
- Content-based relevance (): Calculate the correlation information between the content of query and key
- Content-related position offset (): Calculate the association information between the content of query and the position code of key
- Global content offset (): Calculate the association between the position code of query and the content of key Information
- Global position offset (): Calculate the associated information between query and key position coding
DistillBert’s student model:
- Six-layer BERT, while removing the Token-type Embedding (ie Segment Embedding).
- Use the first six layers of the teacher model for initialization.
- Only use the mask language model for training, and do not use the NSP task.
Teacher model: BERT-base:
Loss function:
Supervised MLM loss: using mask Cross-entropy loss obtained from code language model training: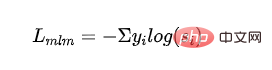
- represents the label of the th category and represents the probability of the student model output of the th category.
- Distilled MLM loss: Using the probability of the teacher model as a guidance signal, calculate the cross-entropy loss with the probability of the student model:
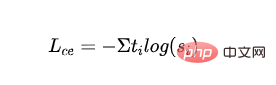
- represents the label of the first category of the teacher model.
- Word vector cosine loss: Align the directions of the hidden layer vectors of the teacher model and the student model, and shorten the distance between the teacher model and the student model from the hidden layer dimension:
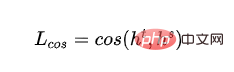
- and represent the hidden layer output of the last layer of the teacher model and student model respectively.
- Final loss:
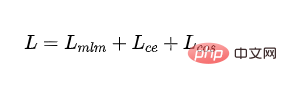
4. References
https ://www.php.cn/link/6e2290dbf1e11f39d246e7ce5ac50a1e
https://www.php.cn/link/664c7298d2b73b3c7fe2d1e8d1781c06
https://www.php.cn/link/67b878df6cd42d142f2924f3ace85c78
##https://www.php.cn/link/f6a673f09493afcd8b129a0bcf1cd5bc
https://www.php.cn/link/82599a4ec94aca066873c99b4c741ed8
#https://www. php.cn/link/2e64da0bae6a7533021c760d4ba5d621##
https://www.php.cn/link/56d33021e640f5d64a611a71b5dc30a3https://www.php.cn/link/4e38d30e656da5ae9d3a425109ce9e04https://www.php.cn/link/c055dcc749c2632fd4dd806301f05ba6https://www.php.cn/link/a749e38f556d5eb1dc13b9221d1f994fhttps://www.php.cn/link /8ab9bb97ce35080338be74dc6375e0ed##https://www.php.cn/link/4f0bf7b7b1aca9ad15317a0b4efdca14
https:/ /www.php.cn/link/b81132591828d622fc335860bffec150
##https://www.php.cn/link/fca758e52635df5a640f7063ddb9cdcb
https://www.php.cn/link/5112277ea658f7138694f079042cc3bb
##https://www.php.cn/link/257deb66f5366aab34a23d5fd0571da4
https://www.php.cn/link/b18e8fb514012229891cf024b6436526
#https://www.php. cn/link/836a0dcbf5d22652569dc3a708274c16
https://www.php.cn/link/a3de03cb426b5e36f5c7167b21395323
https://www.php.cn/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php.cn/link/6b27e88fdd7269394bca4968b48d8df4
https://www.php.cn/link/682e0e796084e163c5ca053dd8573b0c##
https://www.php.cn/link/9739efc4f01292e764c86caa59af353e https://www.php.cn/link/b93e78c67fd4ae3ee626d8ec0c412dechttps://www .php.cn/link/c8cc6e90ccbff44c9cee23611711cdc4The above is the detailed content of A preliminary exploration into the evolution of natural language pre-training technology. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology