The GPT series is a series of pre-training articles from OpenAI. The full name of GPT is Generative Pre-Trained Transformer. As the name suggests, the purpose of GPT is to use Transformer as the basic model and use pre-training technology to obtain universal Text model. The papers that have been published so far include text pre-training GPT-1, GPT-2, GPT-3, and image pre-training iGPT. GPT-4, which has not yet been released, is rumored to be a multi-modal model. The recently very popular ChatGPT and [1] announced at the beginning of this year are a pair of sister models. They are preheating models released before GPT-4, sometimes also called GPT3.5. ChatGPT and InstructGPT are completely consistent in terms of model structure and training methods, that is, they both use instruction learning (Instruction Learning) and reinforcement learning from human feedback (RLHF) to guide the training of the model. The only difference between them is There are differences in how data are collected. So to understand ChatGPT, we must first understand InstructGPT.
Before introducing ChatGPT/InstructGPT, we first introduce the basic algorithms they rely on.
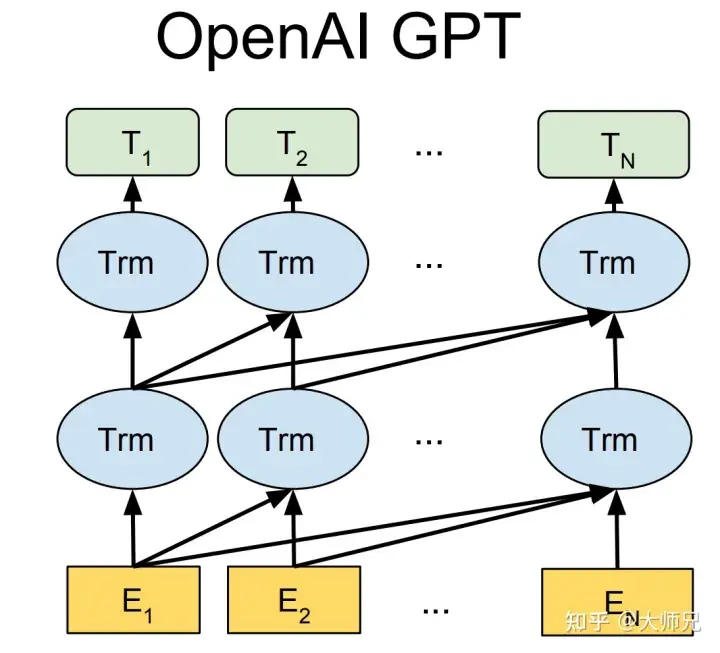
The three generations of GPT-1[2], GPT-2[3], and GPT-3[4] models based on text pre-training all use Transformer as the core Structure model (Figure 1), the difference is the number of layers of the model and the length of word vectors and other hyper-parameters, their specific contents are shown in Table 1.
Figure 1: Model structure of the GPT series (where Trm is a Transformer structure)
Table 1: Release time, parameter amount and training of previous generations of GPT Quantity
| #Model
|
Release time
|
Number of layers
|
Number of heads
|
Word vector length
|
Parameter amount
|
Pre-training data amount
|
| GPT-1
|
June 2018
|
12
| ##12 |
768 |
117 million |
About 5GB |
GPT-2 |
##February 2019
|
48
|
-
|
1600
|
1.5 billion
|
40GB
|
| GPT-3
|
May 2020
|
96
| 96
|
12888
|
175 billion
|
45TB |
GPT-1 was born a few months earlier than BERT. They all use Transformer as the core structure. The difference is that GPT-1 builds pre-training tasks generatively from left to right, and then obtains a general pre-training model. This model can be used for downstream tasks like BERT. Fine tune. GPT-1 achieved SOTA results on 9 NLP tasks at that time, but the model size and data volume used by GPT-1 were relatively small, which prompted the birth of GPT-2.
Compared with GPT-1, GPT-2 did not make a big fuss about the model structure, but only used a model with more parameters and more training data (Table 1). The most important idea of GPT-2 is the idea that "all supervised learning is a subset of unsupervised language models". This idea is also the predecessor of prompt learning. GPT-2 also caused a lot of sensation when it was first born. The news it generated was enough to deceive most humans and achieve the effect of pretending to be real. It was even called "the most dangerous weapon in the AI world" at the time, and many portals ordered to ban the use of news generated by GPT-2.
When GPT-3 was proposed, in addition to its effect far exceeding GPT-2, what caused more discussion was its 175 billion parameters. In addition to GPT-3 being able to complete common NLP tasks, researchers unexpectedly found that GPT-3 also has good performance in writing codes in languages such as SQL and JavaScript, and performing simple mathematical operations. The training of GPT-3 uses in-context learning, which is a type of meta-learning. The core idea of meta-learning is to find a suitable initialization range through a small amount of data, so that the model can Fast fitting on limited data sets and good results.
Through the above analysis, we can see that from a performance perspective, GPT has two goals:
- Improve the performance of the model on common NLP tasks;
- Improve the model's generalization ability on other atypical NLP tasks (such as code writing, mathematical operations).
In addition, since the birth of the pre-training model, a problem that has been criticized is the bias of the pre-training model. Because pre-trained models are trained on models with extremely large parameter levels through massive data, compared to expert systems that are completely controlled by artificial rules, pre-trained models are like a black box. No one can guarantee that the pre-trained model will not generate some dangerous content containing racial discrimination, sexism, etc., because its tens of gigabytes or even dozens of terabytes of training data almost certainly contain similar training samples. This is the motivation for InstructGPT and ChatGPT. The paper uses 3H to summarize their optimization goals:
- Useful (Helpful);
- Trusted (Honest);
- Harmless.
OpenAI's GPT series models are not open source, but they provide a trial website for the model, and qualified students can try it out on their own.
1.2 Instruct Learning (Instruct Learning) and Prompt Learning (Prompt Learning) Learning
Instructed learning is an article titled "Finetuned Language Models Are" by Google Deepmind's Quoc V.Le team in 2021 The idea proposed in the article "Zero-Shot Learners" [5]. The purpose of instruction learning and prompt learning is to tap the knowledge of the language model itself. The difference is that Prompt stimulates the completion ability of the language model, such as generating the second half of the sentence based on the first half of the sentence, or filling in the blanks, etc. Instruct stimulates the understanding ability of the language model. It allows the model to take correct actions by giving more obvious instructions. We can understand these two different learning methods through the following examples:
- Tips for learning: I bought this necklace for my girlfriend. She likes it very much. This necklace is so ____.
- Instructions for learning: Determine the emotion of this sentence: I bought this necklace for my girlfriend and she likes it very much. Options: A=good; B=average; C=poor.
The advantage of instruction learning is that after fine-tuning for multiple tasks, it can also do zero-shot on other tasks, while instruction learning is all aimed at one task. Generalization ability is not as good as instructed learning. We can understand fine-tuning, cued learning and instructed learning through Figure 2.
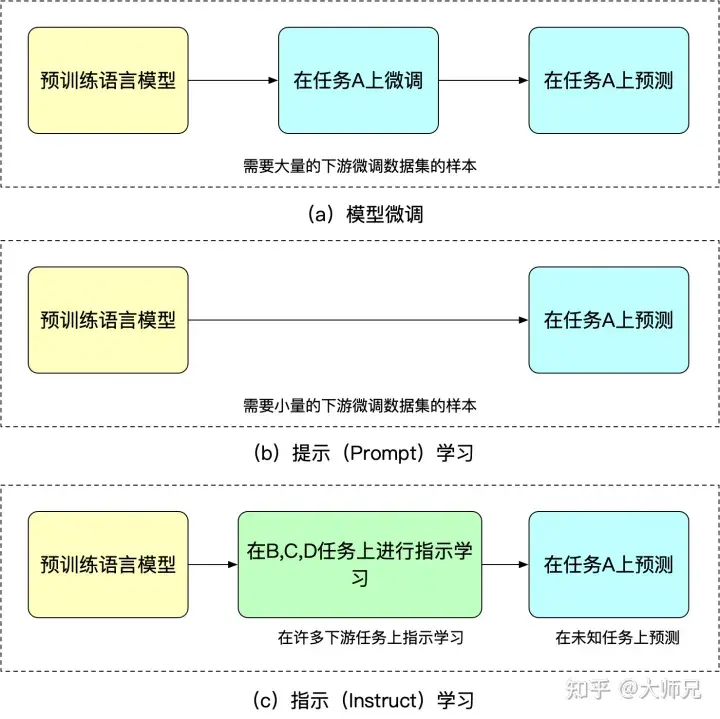
Figure 2: Similarities and differences among model fine-tuning, prompt learning, and instructed learning
1.3 Reinforcement learning with artificial feedback
Because the trained model is not very controllable, the model can be regarded as a fitting of the training set distribution. Then when fed back into the generative model, the distribution of training data is the most important factor affecting the quality of generated content. Sometimes we hope that the model is not only affected by the training data, but also artificially controllable, so as to ensure the usefulness, authenticity and harmlessness of the generated data. The issue of alignment is mentioned many times in the paper. We can understand it as the alignment of the output content of the model and the output content that humans like. What humans like includes not only the fluency and grammatical correctness of the generated content, but also the quality of the generated content. Usefulness, authenticity and harmlessness.
We know that reinforcement learning guides model training through a reward (Reward) mechanism. The reward mechanism can be regarded as the loss function of the traditional model training mechanism. The calculation of rewards is more flexible and diverse than the loss function (the reward of AlphaGO is the outcome of the game). The cost of this is that the calculation of rewards is not differentiable, so it cannot be used directly for backpropagation. The idea of reinforcement learning is to fit the loss function through a large number of samples of rewards to achieve model training. Similarly, human feedback is also non-derivable, so we can also use artificial feedback as a reward for reinforcement learning, and reinforcement learning based on artificial feedback emerged as the times require.
RLHF can be traced back to "Deep Reinforcement Learning from Human Preferences" [6] published by Google in 2017. It uses manual annotation as feedback to improve the performance of reinforcement learning in simulated robots and Atari games. performance effect.
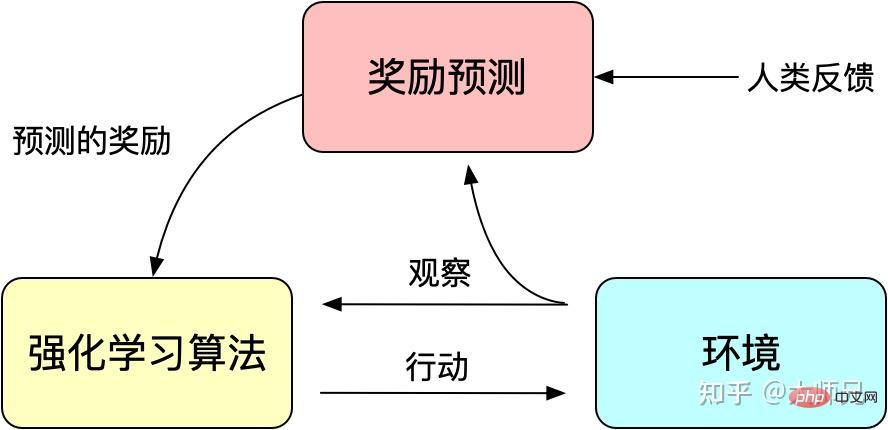
Figure 3: Basic principles of reinforcement learning with artificial feedback
InstructGPT/ChatGPT also uses a classic algorithm in reinforcement learning: the one proposed by OpenAI Proximal Policy Optimization (PPO) [7]. The PPO algorithm is a new type of Policy Gradient algorithm. The Policy Gradient algorithm is very sensitive to the step size, but it is difficult to choose an appropriate step size. During the training process, if the difference in changes between the old and new policies is too large, it will be detrimental to learning. PPO proposed a new objective function that can achieve small batch updates in multiple training steps, solving the problem of difficult to determine the step size in the Policy Gradient algorithm. In fact, TRPO is also designed to solve this idea, but compared to the TRPO algorithm, the PPO algorithm is easier to solve.
2. Interpretation of InstructGPT/ChatGPT principles
With the above basic knowledge, it will be much simpler for us to understand InstructGPT and ChatGPT. To put it simply, InstructGPT/ChatGPT both adopt the network structure of GPT-3, and construct training samples through instruction learning to train a reward model (RM) that reflects the effect of predicted content. Finally, the score of this reward model is used to guide the reinforcement learning model. training. The training process of InstructGPT/ChatGPT is shown in Figure 4.
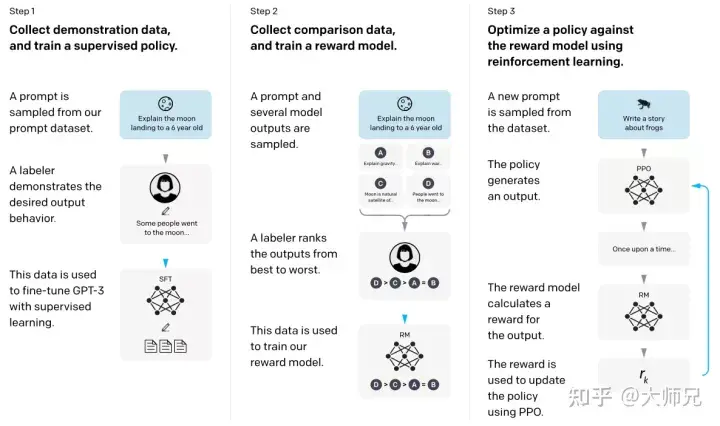
Figure 4: Calculation process of InstructGPT: (1) Supervised fine-tuning (SFT); (2) Reward model (RM) training; (3) Based on rewards through PPO The model performs reinforcement learning.
We can see from Figure 4 that the training of InstructGPT/ChatGPT can be divided into 3 steps, in which the reward model and the reinforcement learning SFT model can be iteratively optimized in steps 2 and 3.
- Perform supervised fine-tuning (Supervised FineTune, SFT) of GPT-3 based on the collected SFT data set;
- Collect manually labeled comparison data and train the reward model (Reword Model) , RM);
- Use RM as the optimization goal of reinforcement learning, and use the PPO algorithm to fine-tune the SFT model.
According to Figure 4, we will introduce the two aspects of data set collection and model training of InstructGPT/ChatGPT respectively.
2.1 Data set collection
As shown in Figure 4, the training of InstructGPT/ChatGPT is divided into 3 steps, and the data required for each step is slightly different. We will introduce them separately below.
2.1.1 SFT data set
The SFT data set is used to train the supervised model in the first step, that is, using the new data collected, GPT-3 is trained according to the GPT-3 training method. 3 Make fine adjustments. Because GPT-3 is a generative model based on prompt learning, the SFT dataset is also a sample composed of prompt-reply pairs. Part of the SFT data comes from users of OpenAI’s PlayGround, and the other part comes from the 40 labelers employed by OpenAI. And they trained the labeler. In this data set, the annotator's job is to write instructions based on the content, and the instructions are required to meet the following three points:
- Simple task: labeler gives any simple task, while ensuring the diversity of tasks;
- Few-shot task: labeler gives an instruction, and multiple queries for the instruction -Corresponding pair;
- User-related: Get use cases from the interface, and then let the labeler write instructions based on these use cases.
2.1.2 RM data set
The RM data set is used to train the reward model in step 2. We also need to set a reward target for the training of InstructGPT/ChatGPT. This reward goal does not have to be differentiable, but it must align as comprehensively and realistically as possible with what we need the model to generate. Naturally, we can provide this reward through manual annotation. Through artificial pairing, we can give lower scores to the generated content involving bias to encourage the model not to generate content that humans do not like. The approach of InstructGPT/ChatGPT is to first let the model generate a batch of candidate texts, and then use the labeler to sort the generated content according to the quality of the generated data.
2.1.3 PPO data set
The PPO data of InstructGPT is not annotated. It comes from GPT-3 API users. There are different types of generation tasks provided by different users, with the highest proportion including generation tasks (45.6%), QA (12.4%), brainstorming (11.2%), dialogue (8.4%), etc.
2.1.4 Data Analysis
Because InstructGPT/ChatGPT is fine-tuned on the basis of GPT-3, and because it involves manual annotation, their total data volume is not large, as shown in Table 2 The sources of the three data and their data volumes are described.
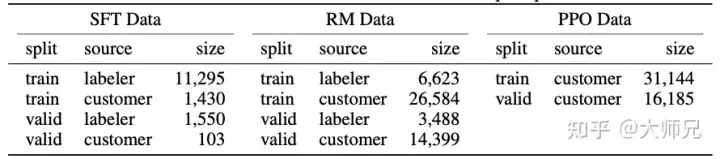
Table 2: Data distribution of InstructGPT
Appendix A of the paper discusses the distribution of data in more detail. Here I list a few possibilities Several factors that affect the model effect:
- More than 96% of the data is in English, and the other 20 languages such as Chinese, French, Spanish, etc. add up to less than 4%, which may cause InstructGPT/ChatGPT to fail. Generate other languages, but the effect should be far inferior to English;
- There are 9 types of prompts, and most of them are generation tasks, which may lead to task types that are not covered by the model;
- The 40 outsourcing employees are from the United States and Southeast Asia. They are relatively concentrated and have a small number. The goal of InstructGPT/ChatGPT is to train a pre-training model with correct values. Its values are a combination of the values of these 40 outsourcing employees. And this relatively narrow distribution may generate some discrimination and prejudice issues that other regions are more concerned about.
In addition, ChatGPT's blog mentioned that the training methods of ChatGPT and InstructGPT are the same. The only difference is that they collect data, but there is no more information on data collection. What details are different. Considering that ChatGPT is only used in the field of dialogue, here I guess ChatGPT has two differences in data collection: 1. It increases the proportion of dialogue tasks; 2. It converts the prompt method into a Q&A method. Of course, this is just a guess. A more accurate description will not be known until more detailed information such as ChatGPT’s papers and source code is released.
2.2 Training Task
We just introduced that InstructGPT/ChatGPT has a three-step training method. These three steps of training will involve three models: SFT, RM and PPO. We will introduce them in detail below.
2.2.1 Supervised fine-tuning (SFT)
The training in this step is consistent with GPT-3, and the author found that allowing the model to appropriately overfit is helpful for the next two steps of training.
2.2.2 Reward Model (RM)
Because the data for training RM is in the form of a labeler sorted according to the generated results, it can be regarded as a regression model. The RM structure is a model that removes the final embedding layer of the SFT-trained model. Its inputs are prompt and Response, and its output is the reward value. Specifically, for each prompt, InstructGPT/ChatGPT will randomly generate K outputs (4≤K≤9), and then they display the output results in pairs to each labeler, that is, each prompt displays a total of CK2 results. The user then selects the better output among them. During training, InstructGPT/ChatGPT treats the CK2 response pairs of each prompt as a batch. This training method of batching by prompt is less likely to overfit than the traditional method of batching by sample, because this method Each prompt will be entered into the model only once.
The loss function of the reward model is expressed as formula (1). The goal of this loss function is to maximize the difference between the response that the labeler prefers and the response that it dislikes.
(1)loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)) )]
where rθ(x,y) is the reward value of prompt x and response y under the reward model with parameter θ, yw is the response result that the labeler prefers, and yl is the response result that the labeler does not like. D is the entire training data set.
2.2.3 Reinforcement Learning Model (PPO)
Reinforcement learning and pre-training models are two of the hottest AI directions in the past two years. Many scientific researchers have previously said that reinforcement learning is not One is well suited to be applied to pre-trained models because it is difficult to build a reward mechanism from the output content of the model. InstructGPT/ChatGPT achieves this counter-intuitively. It introduces reinforcement learning into the pre-trained language model by combining manual annotation, which is the biggest innovation of this algorithm.
As shown in Table 2, the training set of PPO comes entirely from API. It uses the reward model obtained in step 2 to guide the continued training of the SFT model. Many times reinforcement learning is very difficult to train. InstructGPT/ChatGPT encountered two problems during the training process:
- Question 1: As the model is updated, the data and training generated by the reinforcement learning model The differences in data for reward models will become larger and larger. The author's solution is to add the KL penalty term βlog(πϕRL(y∣x)/πSFT(y∣x)) to the loss function to ensure that the output of the PPO model and the output of SFT are not very different.
- Problem 2: Using only the PPO model for training will lead to a significant decline in the model's performance on general NLP tasks. The author's solution is to add a general language model target γEx∼Dpretrain [ log(πϕRL(x))], this variable is called PPO-ptx in the paper.
To sum up, the training goal of PPO is formula (2). (2) objective (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))] γEx∼Dpretrain [log(πϕRL (x))]
3. Performance analysis of InstructGPT/ChatGPT
It is undeniable that the effect of InstructGPT/ChatGPT is very good, especially after the introduction of manual annotation, the model The "values", correctness and "authenticity" of human behavior patterns have been greatly improved. So, just based on the technical solutions and training methods of InstructGPT/ChatGPT, we can analyze what effect improvements it can bring?
3.1 Advantages
- The effect of InstructGPT/ChatGPT is more realistic than GPT-3: This is easy to understand, because GPT-3 itself has very strong generalization and generation capabilities, plus On InstructGPT/ChatGPT, different labelers are introduced for prompt writing and generating result sorting, and they are also fine-tuned on top of GPT-3, which allows us to have higher rewards for more realistic data when training the reward model. The author also compared their performance with GPT-3 on the TruthfulQA data set. The experimental results show that even the 1.3 billion small size PPO-ptx performs better than GPT-3.
- InstructGPT/ChatGPT is slightly more harmless than GPT-3 in terms of model harmlessness: the principle is the same as above. However, the author found that InstructGPT did not significantly improve on discrimination, prejudice and other data sets. This is because GPT-3 itself is a very effective model, and the probability of generating problematic samples with harmful, discriminatory, biased, etc. conditions is very low. Data collected and annotated by only 40 labelers is likely to be unable to fully optimize the model in these aspects, so the improvement in model performance will be little or unnoticeable.
- InstructGPT/ChatGPT has strong coding capabilities: First of all, GPT-3 has strong coding capabilities, and APIs based on GPT-3 have also accumulated a large amount of coding code. And some internal employees of OpenAI also participated in the data collection work. Through the large amount of data related to coding and manual annotation, it is not surprising that the trained InstructGPT/ChatGPT has very strong coding capabilities.
3.2 Disadvantages
- InstructGPT/ChatGPT will reduce the effect of the model on general NLP tasks: We discussed this during the training of PPO, although the loss function is modified It can be mitigated, but the problem is not completely solved.
- Sometimes InstructGPT/ChatGPT will give some ridiculous output: Although InstructGPT/ChatGPT uses human feedback, it is limited by limited human resources. What affects the model the most is the supervised language model task, where humans only play a corrective role. Therefore, it is very likely that it is limited by the limited correction data, or the misleading of the supervised task (only considering the output of the model, not what humans want), resulting in the unrealistic content it generates. Just like a student, although there is a teacher to guide him, it is not certain that the student can learn all the knowledge points.
- The model is very sensitive to instructions: This can also be attributed to the insufficient amount of data annotated by the labeler, because instructions are the only clues for the model to produce output. If the number and type of instructions are not adequately trained, it may cause The model has this problem.
- The model over-interprets simple concepts: This may be because the labeler tends to give higher rewards to longer output content when comparing generated content.
- Harmful instructions may output harmful replies: for example, InstructGPT/ChatGPT will also give an action plan for the "AI Destruction of Humanity Plan" proposed by the user (Figure 5). This is because InstructGPT/ChatGPT assumes that the instructions written by the labeler are reasonable and have correct values, and does not make more detailed judgments on the instructions given by the user, which will cause the model to give a reply to any input. Although the later reward model may give a lower reward value to this type of output, when the model generates text, it must not only consider the values of the model, but also consider the matching of the generated content and instructions. Sometimes there are problems with generating some values. Output is also possible.

#Figure 5: Plan for the destruction of humanity written by ChatGPT.
3.3 Future work
We have analyzed the technical solution of InstrcutGPT/ChatGPT and its problems, then we can also see the optimization angles of InstrcutGPT/ChatGPT.
- Cost reduction and efficiency increase of manual annotation: InstrcutGPT/ChatGPT employs a 40-person annotation team, but judging from the performance of the model, this 40-person team is not enough. How to enable humans to provide more effective feedback methods and organically and skillfully combine human performance and model performance is very important.
- The model's ability to generalize/error correct instructions: Instructions are the only clue for the model to produce output, and the model relies heavily on them. How to improve the model's generalization ability of instructions and error instructions Display error correction capability is a very important task to improve the model experience. This not only allows the model to have a wider range of application scenarios, but also makes the model more "smart".
- Avoid general task performance degradation: It may be necessary to design a more reasonable way of using human feedback, or a more cutting-edge model structure. Because we discussed that many problems of InstrcutGPT/ChatGPT can be solved by providing more labeler-labeled data, but this will lead to more serious performance degradation of general NLP tasks, so solutions are needed to improve the performance of 3H and general NLP tasks that generate results. Achieve balance.
3.4 Answers to the hot topics of InstrcutGPT/ChatGPT
- Will the emergence of ChatGPT cause low-level programmers to lose their jobs? Judging from the principles of ChatGPT and the generated content leaked on the Internet, many of the codes generated by ChatGPT can run correctly. But the job of a programmer is not only to write code, but more importantly to find solutions to problems. Therefore, ChatGPT will not replace programmers, especially high-level programmers. On the contrary, it will become a very useful tool for programmers to write code, like many code generation tools today.
- Stack Overflow announces temporary rule: Ban ChatGPT. ChatGPT is essentially a text generation model. Compared with generating code, it is better at generating fake text. Moreover, the code or solution generated by the text generation model is not guaranteed to be runnable and can solve the problem, but it will confuse many people who query this problem by pretending to be real text. In order to maintain the quality of the forum, Stack Overflow has banned ChatGPT and is also cleaning up.
- The chatbot ChatGPT was induced to write a "plan to destroy humanity" and provide the code. What issues need attention in the development of AI? ChatGPT's "Plan to Destroy Humanity" is a generated content that it forcibly fitted based on massive data under unforeseen instructions. Although the content looks very real and the expression is very fluent, it only shows that ChatGPT has a very strong generative effect, but it does not mean that ChatGPT has the idea of destroying mankind. Because it is only a text generation model, not a decision-making model.
4. Summary
Just like many people when the algorithm was first born, ChatGPT has attracted widespread attention in the industry and human beings due to its usefulness, authenticity, and harmless effects. Thoughts on AI. But after we looked at the principles of its algorithm, we found that it is not as scary as advertised in the industry. On the contrary, we can learn a lot of valuable things from its technical solutions. The most important contribution of InstrcutGPT/ChatGPT in the AI industry is the clever combination of reinforcement learning and pre-training models. Moreover, artificial feedback improves the usefulness, authenticity and harmlessness of the model. ChatGPT has also further increased the cost of large models. Before, it was just a competition of data volume and model scale. Now it even introduces the expense of hiring outsourcing, making individual workers even more prohibitive.
Reference
- ^Ouyang, Long, et al. "Training language models to follow instructions with human feedback." *arXiv preprint arXiv:2203.02155* (2022). https:/ /arxiv.org/pdf/2203.02155.pdf
- ^Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training. https: //www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei, D . and Sutskever, I., 2019. Language models are unsupervised multitask learners. *OpenAI blog*, *1*(8), p.9. https://life-extension.github.io/2020/05/27/ A preliminary study on GPT technology/language-models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners ." *arXiv preprint arXiv:2005.14165* (2020). https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei, Jason, et al. "Finetuned language models are zero-shot learners." *arXiv preprint arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
- ^Christiano, Paul F., et al. " Deep reinforcement learning from human preferences." *Advances in neural information processing systems* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
- ^Schulman, John, et al. "Proximal policy optimization algorithms." *arXiv preprint arXiv:1707.06347* (2017). https://arxiv.org/pdf/1707.06347.pdf
The above is the detailed content of ChatGPT/InstructGPT detailed explanation. For more information, please follow other related articles on the PHP Chinese website!