
Home >Technology peripherals >AI >'Location Embedding”: The Secret Behind Transformer
'Location Embedding”: The Secret Behind Transformer

- 王林forward
- 2023-04-10 10:01:031035browse
Translator | Cui Hao
Reviewer | Sun Shujuan
Table of Contents
- Introduction
- Embedding concept in NLP
- Need position embedding in Transformers
- Various types of initial trial-and-error experiments
- Frequency-based location embedding
- Summary
- References
Introduction
The introduction of the Transformer architecture in the field of deep learning undoubtedly paved the way for a silent revolution. Smoothing the road is especially important for branches of NLP. The most indispensable part of the Transformer architecture is "position embedding", which gives the neural network the ability to understand the order of words in long sentences and the dependencies between them.
We know that RNN and LSTM have been introduced before Transformer, and they have the ability to understand the ordering of words even without using positional embedding. Then, you will have an obvious question why this concept was introduced into Transformer and the advantages of this concept are so emphasized. This article will explain these causes and consequences to you.
The concept of embedding in NLPEmbedding is a process in natural language processing that is used to convert raw text into mathematical vectors. This is because the machine learning model will not be able to handle the text format directly and use it for various internal computing processes.
The embedding process for algorithms such as Word2vec and Glove is called word embedding or static embedding.
In this way, a text corpus containing a large number of words can be passed into the model for training. The model will assign a corresponding mathematical value to each word, assuming that those words that occur more frequently are similar. After this process, the resulting mathematical values are used for further calculations.
For example, consider that our text corpus has 3 sentences, as follows:
- The British government annually sends an annual The king and queen issued large subsidies and claimed some control over the administration.
- In addition to the king and queen, the royal family members also include their daughter Marie-Theresa Charlotte (Madame Royale), the king's sister Lady Elizabeth, and the valet Clay ri and others.
- This was interrupted by the news of Mordred's betrayal, Lancelot did not participate in the final fatal conflict, he survived both the king and the queen, and the Round Table So does decline.
Here, we can see that the words "king" and "queen" appear frequently. Therefore, the model will assume that there may be some similarity between these words. When these words are converted into mathematical values, they are placed at a small distance when represented in a multidimensional space.
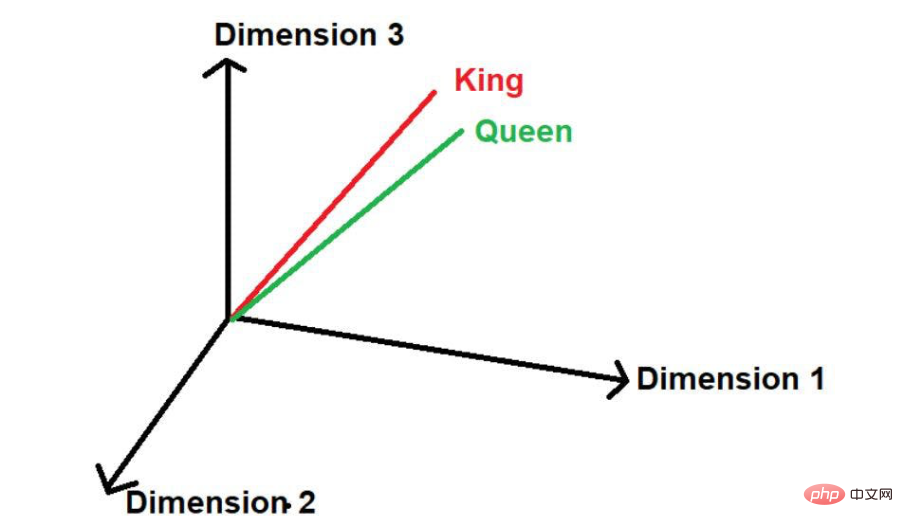
Assuming there is another word "road", then logically speaking, it does not appear as frequently in this large text corpus as "king" and "queen". Therefore, the word would be far away from "King" and "Queen" and placed far away somewhere else in space.
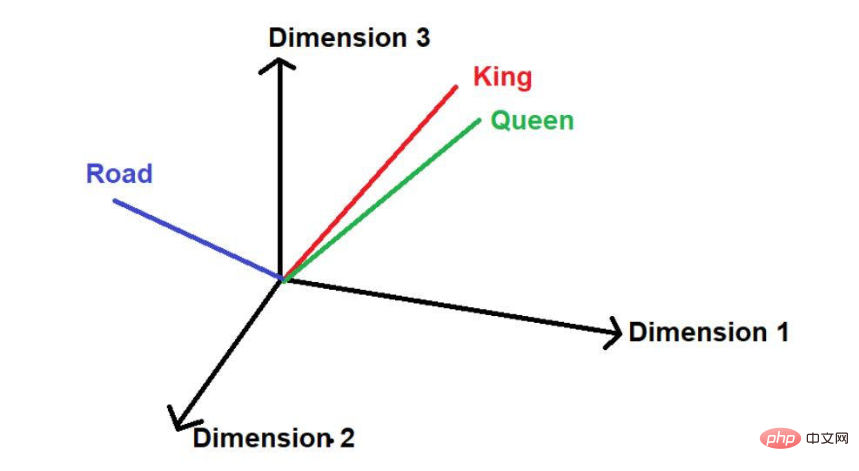 Image source: Illustration provided by the author
Image source: Illustration provided by the author
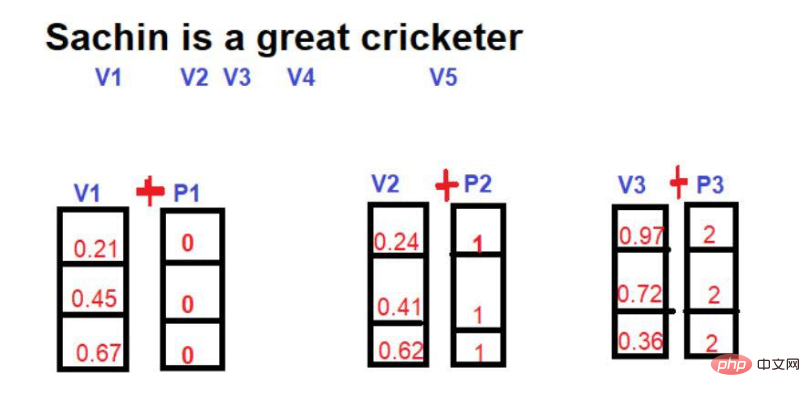
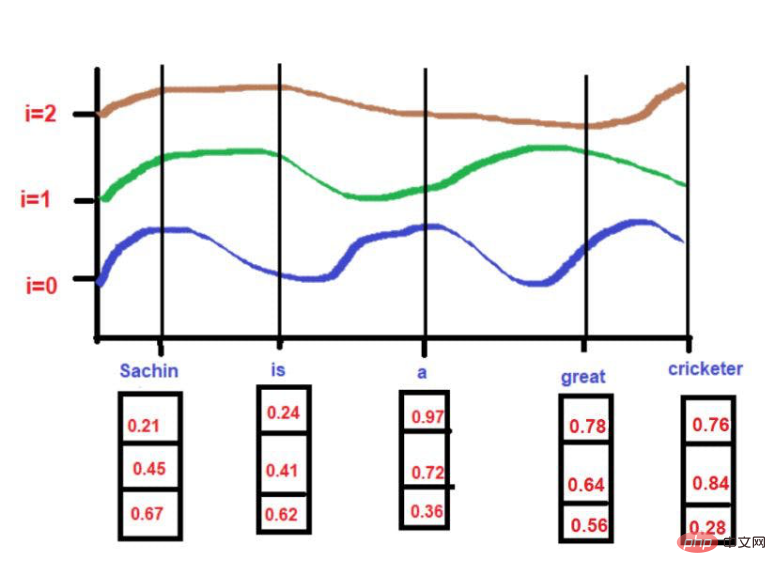
In mathematics, a vector is represented by a series of numbers, where each number represents the word size in a particular dimension. For example: We put
here. Therefore, "king" is expressed in the form of [0.21, 0.45, 0.67] in three-dimensional space.
The word "Queen" can be expressed as [0.24,0.41,0.62].
The word "Road" can be expressed as [0.97,0.72,0.36].
Need for positional embeddings in Transformer
As we discussed in the introduction section, the need for positional embeddings is for neural networks to understand ordering and positional dependencies in sentences.
For example, let us consider the following sentences:
Sentence 1--"Although Sachin Tendulkar did not score 100 runs today, he led the team to victory".
Sentence 2--"Although Sachin Tendulkar scored 100 runs today, he failed to lead the team to victory."
The two sentences look similar because they share most of the words, but their underlying meanings are very different. The ordering and placement of words like "no" has changed the context in which the message is conveyed.
Therefore, in NLP projects, understanding location information is very critical. If a model simply uses numbers in a multidimensional space and misunderstands the context, this can have serious consequences, especially in predictive models.
To overcome this challenge, neural network architectures such as RNN (Recurrent Neural Network) and LSTM (Long-Term Short-Term Memory) were introduced. To some extent, these architectures are very successful in understanding location information. The main secret behind their success is learning long sentences by preserving the order of words. In addition to this, they also have information about words that are close to the "word of interest" and words that are far from the "word of interest".
For example, consider the following sentence--
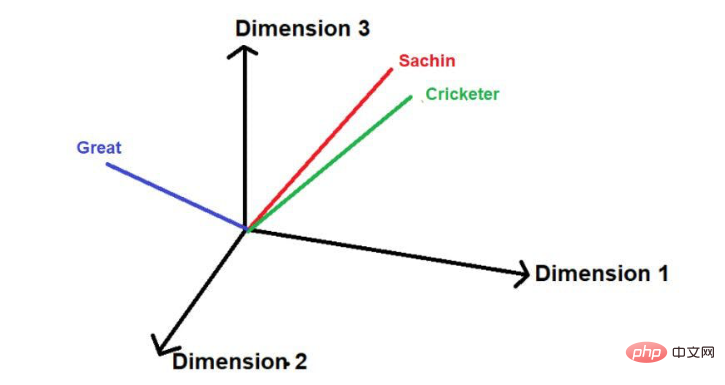
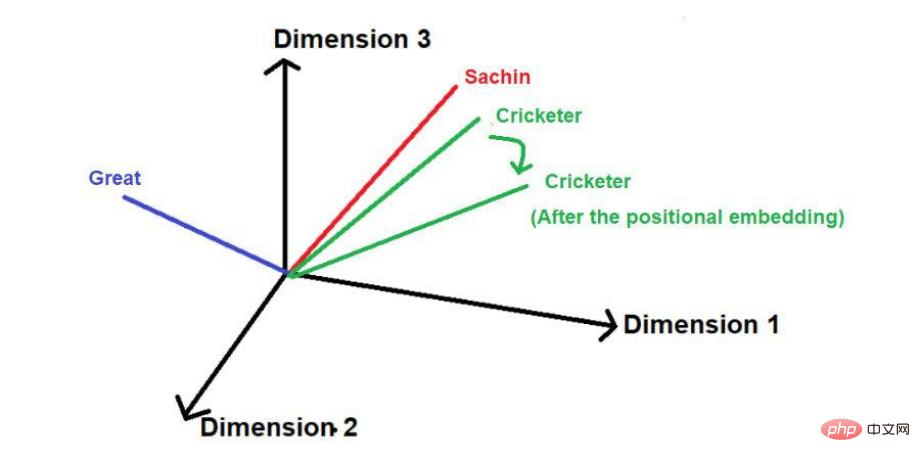
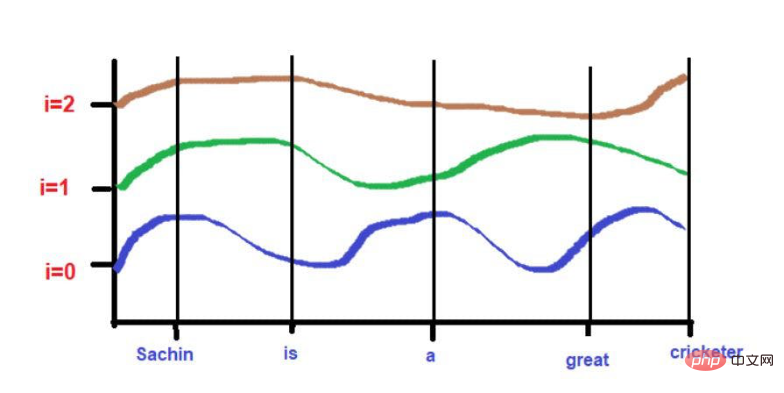
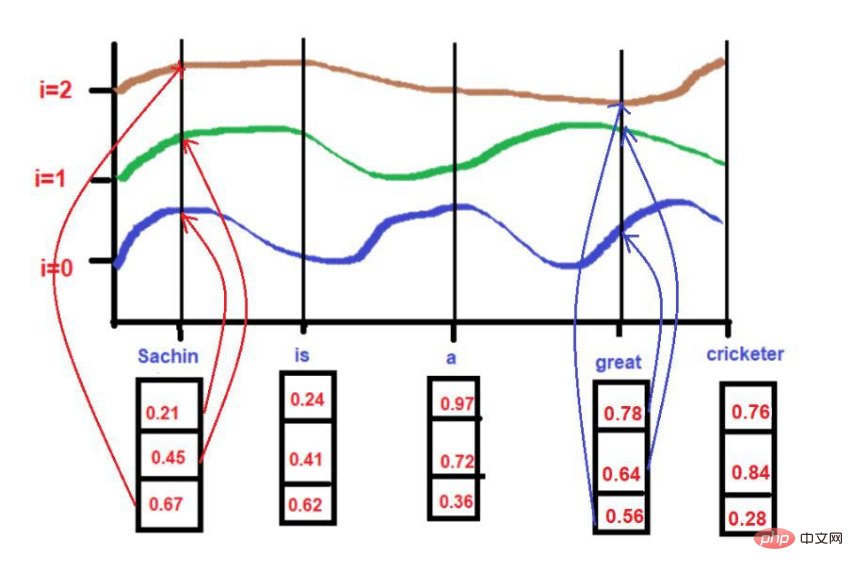
"Sachin is the greatest cricketer of all time".

Image source: Illustrations provided by the author
The words underlined in red are these. You can see here that the "words of interest" are traversed in the order of the original text.
Furthermore, they can also learn by remembering

Image source: Illustration provided by the author
Although, through these techniques, RNN/ LSTM can understand location information in large text corpora. However, the real problem is performing a sequential traversal of words in a large corpus of text. Imagine that we have a very large text corpus with 1 million words, and it would take a very long time to go through each word in sequence. Sometimes it is not feasible to commit so much computational time to training a model.
To overcome this challenge, a new advanced architecture - "Transformer" is introduced.
An important feature of the Transformer architecture is that a text corpus can be learned by processing all words in parallel. Whether the text corpus contains 10 words or 1 million words, the Transformer architecture does not care.

Image source: Illustrations provided by the author

For example, let us consider the example shown below--
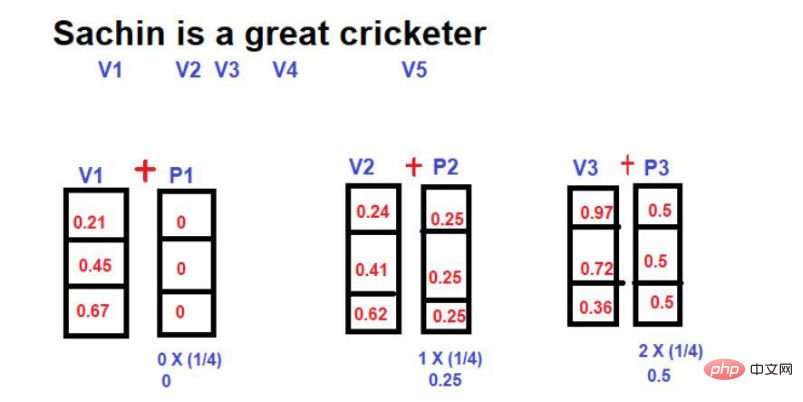
#Image source: Illustration provided by the author
In this technique, no matter Regardless of the length of the sentence, the maximum magnitude of the position vector can be limited to 1. However, there is a big loophole. If you compare two sentences of different lengths, the embedding value of a word at a specific position will be different. A specific word or its corresponding position should have the same embedding value throughout the text corpus to facilitate understanding of its context. If the same word in different sentences has different embedding values, representing the information of the text corpus in a multi-dimensional space becomes a very complex task. Even if such a complex space is implemented, it is very likely that the model will collapse at some point due to excessive information distortion. Therefore, this technique has been excluded from the development of Transformer positional embedding.
Finally, the researchers proposed a Transformer architecture and mentioned in the famous white paper-"Attention is everything you need".
Frequency-based position embedding
According to this technology, the researchers recommend a wave frequency-based text embedding method, using the following formula---
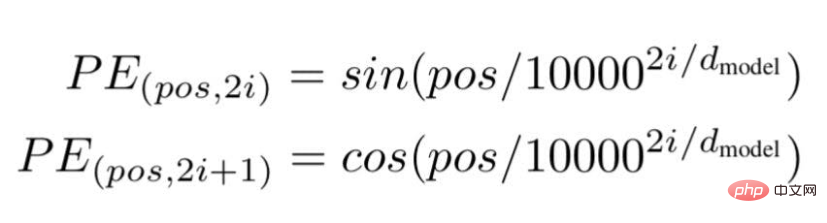
Image source: Illustration provided by the author
"pos" is the position or index value of a specific word in the sentence.
"d " is the maximum length/dimension of the vector representing a specific word in the sentence.
"i " represents the index of the embedding dimension of each position. It also means frequency. When i=0 it is considered to be the highest frequency, for subsequent values the frequency is considered to be of decreasing magnitude.
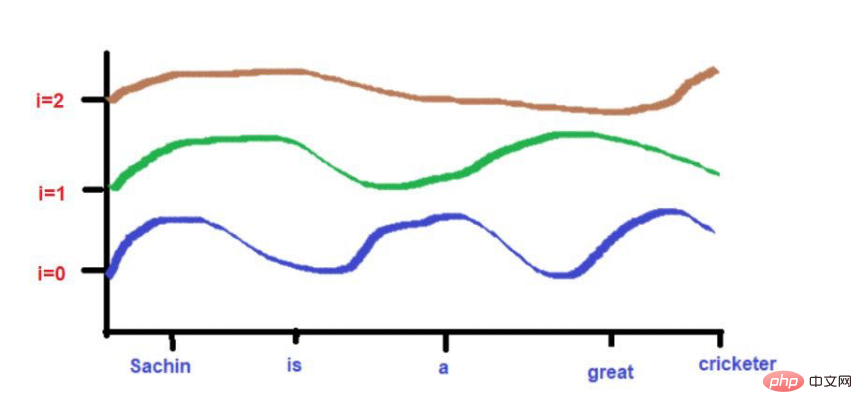
Image source: Illustrations provided by the author
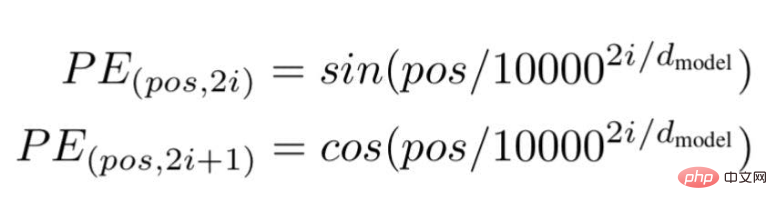
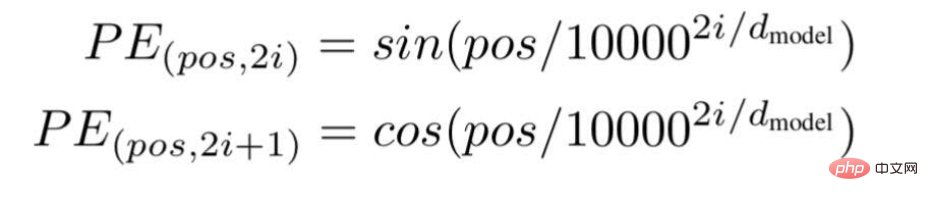
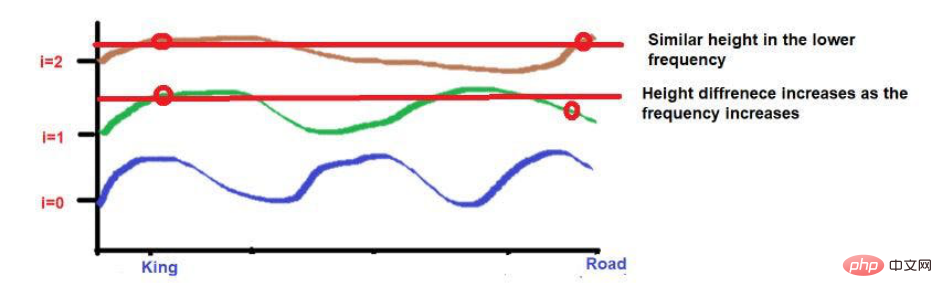
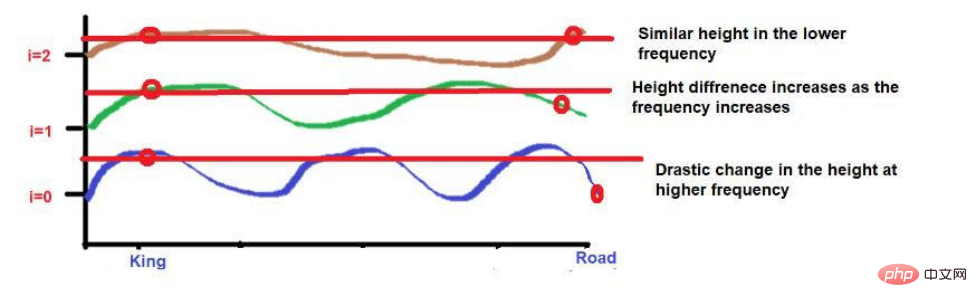
Additionally, words that are highly close to each other may fall at similar heights at lower frequencies, while their heights will be a little different at higher frequencies.
If words are very close together, their heights will be very different even at lower frequencies, and their height differences will increase with frequency. .
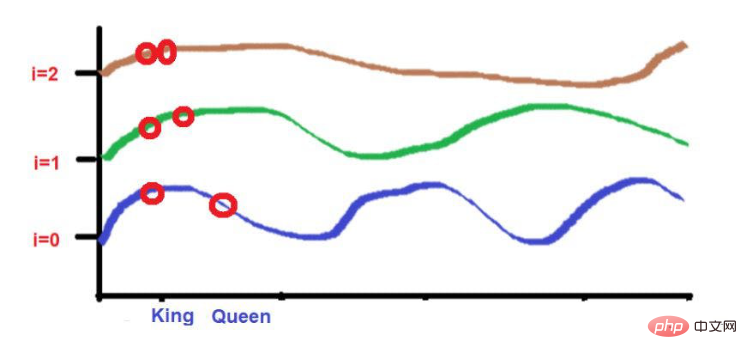
For example, consider this sentence--"The king and the queen were walking on the road."
The words "King" and "Road" are placed further away.
Consider that after applying the wave frequency formula, the two words are roughly similar in height. As we get to higher frequencies (like 0), their heights will become more different.
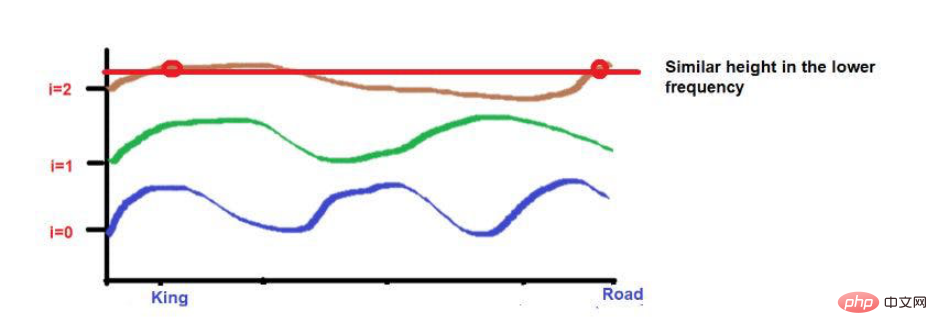
Image source: Illustrations provided by the author
Original title: Positional Embedding: The Secret behind the Accuracy of Transformer Neural Networks , Author: Sanjay Kumar
The above is the detailed content of 'Location Embedding”: The Secret Behind Transformer. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology