
Home >Technology peripherals >AI >Tan Zhongyi: From Model-Centric to Data-Centric MLOps helps AI to be implemented faster, more cost-effectively
Tan Zhongyi: From Model-Centric to Data-Centric MLOps helps AI to be implemented faster, more cost-effectively

- PHPzforward
- 2023-04-09 19:51:111492browse
Guest: Tan Zhongyi
Compiled by: Qianshan
Ng Enda has expressed on many occasions that AI has changed from a model-centered research paradigm to a data-centered research paradigm. , data is the biggest challenge for the implementation of AI. How to ensure the high-quality supply of data is a key issue. To solve this problem, we need to use MLOps practices and tools to help AI implement quickly, efficiently and cost-effectively.
Recently, at the AISummit Global Artificial Intelligence Technology Conference hosted by 51CTO, Tan Zhongyi, Vice Chairman of TOC of the Open Atomic Foundation, gave a keynote speech "From Model-Centric to Data-Centric - MLOps helps AI implement faster, easier and more cost-effectively", which focused on sharing with participants the definition of MLOps, what problems MLOps can solve, common MLOps projects, and how to evaluate the MLOps capabilities and level of an AI team. The content of the speech is now organized as follows, hoping to inspire you.
From Model-Centric to Data-Centric
Currently, there is a trend in the AI industry - "from Model-Centric to Data-Centric". What exactly does it mean? Let’s start with some analysis from science and industry.
AI scientist Andrew NG analyzed that the key to the current implementation of AI is how to improve data quality.- Industry engineers and analysts have reported that AI projects often fail. The reasons for the failure deserve further exploration.
- Andrew Ng once shared his speech "MLOps: From Model-centric to Data-centric", which caused great repercussions in Silicon Valley. In his speech, he believed that "AI = Code Data" (where Code includes models and algorithms), and improves the AI system by improving Data rather than Code.
Specifically, the Model-Centric method is adopted, which means keeping the data unchanged and constantly adjusting the model algorithm, such as using more network layers, adjusting more hyperparameters, etc.; and using the Data-Centric method , that is, keeping the model unchanged and improving data quality, such as improving data labels, improving data annotation quality, etc.
For the same AI problem, the effect is completely different whether improving the code or improving the data.
Empirical evidence shows that the accuracy can be effectively improved through the Data-centric approach, but the extent to which the accuracy can be improved by improving the model or replacing the model is extremely limited. For example, in the following steel plate defect detection task, the baseline accuracy rate was 76.2%. After various operations of changing models and adjusting parameters, the accuracy rate was almost not improved. However, optimization of the data set increased the accuracy by 16.9%. The experience of other projects also proves this.
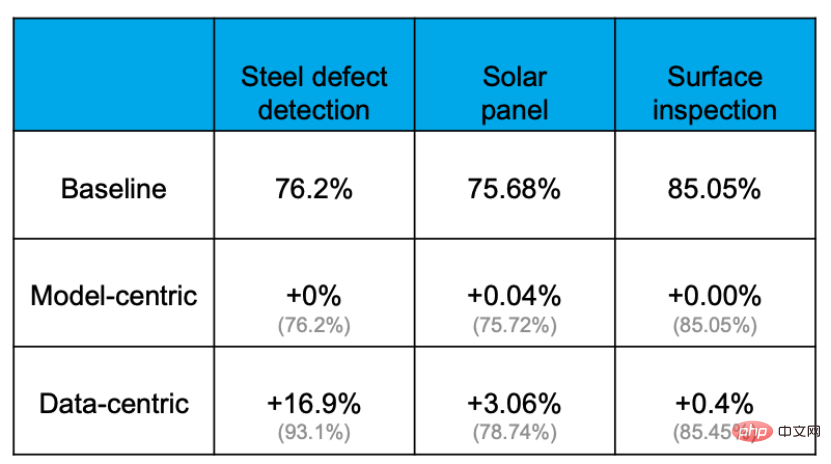 The reason for this is because data is more important than imagined. Everyone knows that "Data is Food for AI". In a real AI application, about 80% of the time is spent processing data-related content, and the remaining 20% is used to adjust the algorithm. This process is like cooking. 80% of the time is spent preparing ingredients, processing and adjusting various ingredients, but the actual cooking may only take a few minutes when the chef puts the pot in the pot. It can be said that the key to determining whether a dish is delicious lies in the ingredients and their processing.
The reason for this is because data is more important than imagined. Everyone knows that "Data is Food for AI". In a real AI application, about 80% of the time is spent processing data-related content, and the remaining 20% is used to adjust the algorithm. This process is like cooking. 80% of the time is spent preparing ingredients, processing and adjusting various ingredients, but the actual cooking may only take a few minutes when the chef puts the pot in the pot. It can be said that the key to determining whether a dish is delicious lies in the ingredients and their processing.
In Ng’s view, the most important task of MLOps (ie “Machine learning Engineering for Production”) is at all stages of the machine learning life cycle, including data preparation, model training, model online, and model development. High-quality data supply is always maintained during various stages such as monitoring and retraining.
The above is the understanding of MLOps by AI scientists. Next, let’s take a look at some opinions from AI engineers and industry analysts.
First of all, from the perspective of industry analysts, the current failure rate of AI projects is astonishingly high. A survey by Dimensional Research in May 2019 found that 78% of AI projects did not eventually go online; in June 2019, a VentureBeat report found that 87% of AI projects were not deployed in the production environment. In other words, although AI scientists and AI engineers have done a lot of work, they ultimately did not generate business value.
Why does this result occur? The paper "Hidden Technical Debt in Machine Learning Systems" published at NIPS in 2015 mentioned that a real online AI system includes data collection, verification, resource management, feature extraction, process management, monitoring and many other contents. . But the code actually related to machine learning only accounts for 5% of the entire AI system, and 95% is engineering-related content and data-related content. Therefore, data is both the most important and the most error-prone.
The challenge of data to a real AI system mainly lies in the following points:
- Scale: Reading massive data is a challenge;
- Low Latency: How to meet the requirements of high QPS and low latency during serving;
- Data change cause model decay : The real world is constantly changing, how to deal with the attenuation of model effects;
- Time Travel: Time series feature data processing is prone to problems;
- Training/Serving skew: The data used for training and prediction is inconsistent .
Listed above are some challenges related to data in machine learning. Additionally, in real life, real-time data poses greater challenges.
So, for an enterprise, how can AI be implemented at scale? Taking a large enterprise as an example, it may have more than 1,000 application scenarios and more than 1,500 models running online at the same time. How to support so many models? How can we technically achieve “more, faster, better, and cheaper” implementation of AI?
Many: Multiple scenarios need to be implemented around key business processes, which may be on the order of 1,000 or even tens of thousands for large enterprises.
Fast: The implementation time of each scene should be short, and the iteration speed should be fast. For example, in recommended scenarios, it is often necessary to do full training once a day and incremental training every 15 minutes or even every 5 minutes.
Good: The landing effect of each scene must meet expectations, at least better than before it was implemented.
Saving: The implementation cost of each scenario is relatively economical, in line with expectations.
To truly achieve “more, faster, better, and cheaper”, we need MLOps.

In the traditional software development field, we use DevOps to solve similar problems such as slow rollout and unstable quality. DevOps has greatly improved the efficiency of software development and launch, and promoted the rapid iteration and development of modern software. When facing problems with AI systems, we can learn from the mature experience in the DevOps field to develop MLOps. So as shown in the figure, "Machine learning development Modern software development" becomes MLOps.
What exactly is MLOps
There is currently no standard definition in the industry for what MLOps is.
- Definition from wikipedia: MLOps is a set of practices that aims to deploy and
maintain machine learning models in production reliable and efficiently. - Definition from Google cloud: MLOps is a machine learning engineering culture and practice designed to unify machine learning system development and operation.
- Definition from Microsoft Azure: MLOps can help data scientists and application engineers make machine learning models more effective in production.
The above statements are quite convoluted. My personal understanding of this is relatively simple: MLOps is the continuous integration, continuous deployment, continuous training and continuous monitoring of "Code Model Data".
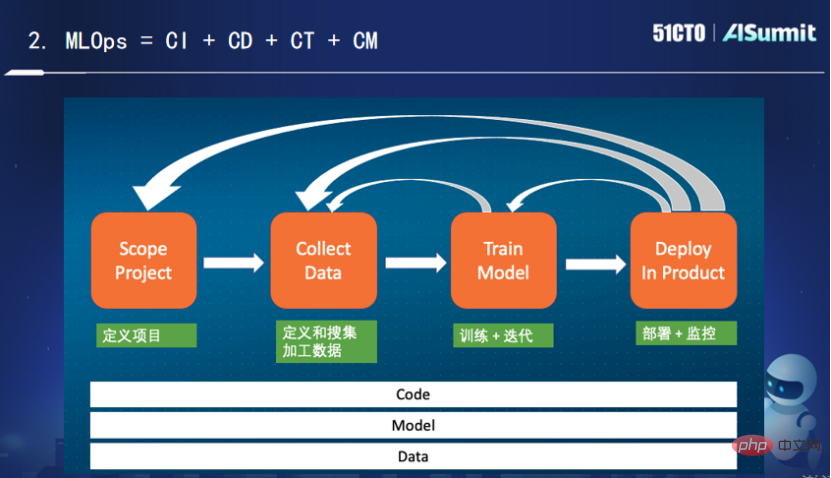
The above picture shows a typical machine learning life scene. After defining the project phase, we begin to define and collect processing data. We need to observe what data is helpful in solving the current problem? How to process, how to do feature engineering, how to convert and store.
After collecting the data, we start to train and iterate the model. We need to continuously adjust the algorithm and then continue to train, and finally get a result that meets the expectations. If you are not satisfied with the result, you need to return to the upper layer. At this time, you need to obtain more data, perform more conversions on the data, and then train again, repeating the cycle until you get a more satisfactory model algorithm, and then start again. Deploy online.
In the deployment and monitoring process, if the model effect is inconsistent, it is necessary to observe what problems occurred in the training and deployment. After being deployed for a period of time, you may face the problem of model decay, and you need to retrain. Sometimes there are even problems with the data during the deployment process, and you need to return to the data processing layer. What's more, the deployment effect is far from meeting the project expectations, and it may be necessary to return to the original starting point.
As you can see, the entire process is a cyclic and iterative process. For engineering practice, we need continuous integration, continuous deployment, continuous training, and continuous monitoring. Among them, continuous training and continuous monitoring are unique to MLOps. The role of continuous training is that even if the code model does not change, it still needs to be continuously trained for changes in its data. The role of continuous monitoring is to constantly monitor whether there are problems with the matching between the data and the model. Monitoring here refers to not only monitoring the online system, but also monitoring some indicators related to the system and machine learning, such as recall rate, accuracy rate, etc. To sum up, I think MLOps is actually the continuous integration, continuous deployment, continuous training and continuous monitoring of code, models and data.
Of course, MLOps is not just a process and Pipeline, it also includes bigger and more content. For example:
(1) Storage platform: Storage and reading of features and models
(2) Computing platform: Streaming and batch processing for feature processing
(3) Message queue: used to receive real-time data
(4) Scheduling tool: scheduling of various resources (computing/storage)
(5) Feature Store: registration, Discover and share various features
(6) Model Store: Features of the model
(7) Evaluation Store: Monitoring/AB testing of the model
Feature Store, Model store and Evaluation store are emerging applications and platforms in the field of machine learning, because sometimes multiple models are run online at the same time. To achieve rapid iteration, good infrastructure is needed to retain this information, so as to make iteration more efficient. These New applications and new platforms emerge as the times require.
MLOps’ unique project—Feature Store
The following is a brief introduction to Feature Store, which is the feature platform. As a unique platform in the field of machine learning, Feature Store has many features.
First, it is necessary to meet the requirements of model training and prediction at the same time. Feature data storage engines have completely different application requirements in different scenarios. Model training requires good scalability and large storage space; real-time prediction needs to meet high performance and low latency requirements.
Second, the problem of inconsistency between feature processing during training and prediction stages must be solved. During model training, AI scientists generally use Python scripts, and then use Spark or SparkSQL to complete feature processing. This kind of training is not sensitive to delays and is less efficient when dealing with online business. Therefore, engineers will use a higher-performance language to translate the feature processing process. However, the translation process is extremely cumbersome, and engineers have to repeatedly check with scientists to see if the logic meets expectations. As long as it is slightly inconsistent with expectations, it will bring about the problem of inconsistency between online and offline.
Third, the problem of reuse in feature processing needs to be solved to avoid waste and share efficiently. In an enterprise's AI applications, this situation often occurs: the same feature is used by different business departments, the data source comes from the same log file, and the extraction logic done in the middle is also similar, but because it is in different departments Or used in different scenarios, it cannot be reused, which is equivalent to the same logic being executed N times, and the log files are massive, which is a huge waste of storage resources and computing resources.
In summary, Feature Store is mainly used to solve high-performance feature storage and services, model training and model prediction, feature data consistency, feature reuse and other issues. Data scientists can use Feature Store for deployment. and share.
The mainstream feature platform products currently on the market can be roughly divided into three categories.
- Each AI company conducts its own research. As long as the business requires real-time training, these companies will basically develop a similar feature platform to solve the above three problems. But this feature platform is deeply bound to the business.
- SAAS products or part of the machine learning platform provided by cloud vendors. For example, SageMaker provided by AWS, Vertex provided by Google, and Azure machine learning platform provided by Microsoft. They will have a feature platform built into the machine learning platform to facilitate users to manage various complex features.
- Some open source and commercial products. To give a few examples, Feast, an open source Feature Store product; Tecton provides a complete open source commercial feature platform product; OpenMLDB, an open source Feature Store product.
MLOps Maturity Model
The maturity model is used to measure the capability goals of a system and a set of rules. In the field of DevOps, the maturity model is often used to evaluate a company's capabilities. DevOps capabilities. There is also a corresponding maturity model in the field of MLOps, but it has not yet been standardized. Here is a brief introduction to Azure's maturity model about MLOps.
According to the degree of automation of the entire machine learning process, the mature model of MLOps is divided into (0, 1, 2, 3, 4) levels, of which 0 means no automation. (1,2,3) is partial automation, and 4 is highly automated.

The maturity level is 0, that is, there is no MLOps. This stage means that data preparation is manual, model training is also manual, and model training deployment is also manual. All work is done manually, which is suitable for some business departments that carry out innovative pilot projects on AI.
The maturity level is 1, that is, there is DevOps but no MLOps. Its data preparation is done automatically, but model training is done manually. After scientists get the data, they make various adjustments and training before completing it. Deployment of the model is also done manually.
The maturity level is 2, which is automated training. The model training is completed automatically. In short, after the data is updated, a similar pipeline is immediately started for automated training. However, the evaluation and launch of the training results are still done manually.
The maturity level is 3, which is automated deployment. After the automatic training of the model is completed, the evaluation and launch of the model are completed automatically without manual intervention.
The maturity level is 4, which means automatic retraining and deployment. It continuously monitors the online model. When it is found that the online model capabilities of Model DK have deteriorated, it will automatically trigger repeated training. The entire process is fully automated, which can be called the most mature system.
For more exciting content, please see the official website of the conference:Click to view
The above is the detailed content of Tan Zhongyi: From Model-Centric to Data-Centric MLOps helps AI to be implemented faster, more cost-effectively. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology