
Home >Technology peripherals >AI >Without heaping parameters or relying on time, Meta accelerates the ViT training process and increases the throughput by 4 times.
Without heaping parameters or relying on time, Meta accelerates the ViT training process and increases the throughput by 4 times.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2023-04-09 09:21:071040browse
At this stage, the visual transformer (ViT) model has been widely used in various computer vision tasks such as image classification, target detection and segmentation, and can achieve SOTA results in visual representation and recognition. . Since the performance of computer vision models is often positively correlated with the number of parameters and training time, the AI community has experimented with increasingly large-scale ViT models.
But it should be noted that as models begin to exceed the scale of teraflops, the field has encountered some major bottlenecks. Training a single model can take months and require thousands of GPUs, increasing accelerator requirements and resulting in large-scale ViT models that exclude many practitioners.
In order to expand the scope of use of the ViT model, Meta AI researchers have developed more efficient training methods. It is very important to optimize training for optimal accelerator utilization. However, this process is time-consuming and requires considerable expertise. To set up an orderly experiment, researchers must choose from countless possible optimizations: any one of the millions of operations performed during a training session may be hampered by inefficiencies.
Meta AI has found that it can improve computational and storage efficiency by applying a series of optimizations to its implementation of ViT in PyCls, its image classification code library. For ViT models trained using PyCIs, Meta AI’s approach can improve training speed and throughput per accelerator (TFLOPS).
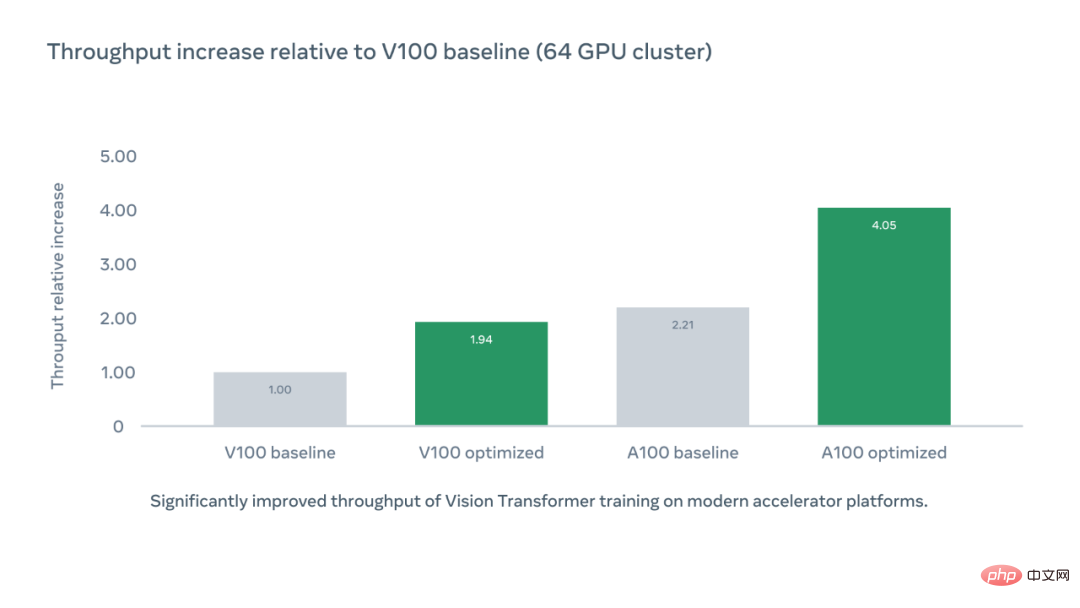
The following figure shows the relative increase in per chip accelerator throughput compared to the V100 benchmark using the optimized code library PyCIs, while the A100 optimized accelerator throughput is the V100 benchmark 4.05 times.
Operation Principle
Meta AI first analyzes the PyCIs code base to identify low training efficiency potential sources, ultimately focusing on the choice of digital format. By default, most applications use a 32-bit single-precision floating point format to represent neural network values. Converting to a 16-bit half-precision format (FP16) can reduce a model's memory footprint and execution time, but often also reduces accuracy.
The researchers adopted a compromise solution, namely mixed precision. With it, the system performs calculations in a single-precision format to speed up training and reduce memory usage, while storing results in single-precision to maintain accuracy. Rather than manually converting parts of the network to half-precision, they experimented with different modes of automated mixed-precision training, which automatically switches between numeric formats. More advanced modes' automatic mixed precision relies primarily on half-precision operations and model weights. The balanced settings used by the researchers can significantly speed up training without sacrificing accuracy.
In order to make the process more efficient, the researchers made full use of the Fully Sharder Data Parallel (FSDP) training algorithm in the FairScale library, which compares parameters, Gradient and optimizer state are sharded. Through the FSDP algorithm, researchers can build larger-scale models using fewer GPUs. Additionally, we used the MTA optimizer, a pooled ViT classifier, and a batch-second input tensor layout to skip redundant transpose operations.
The X-axis of the figure below shows possible optimizations, and the Y-axis shows the relative increase in accelerator throughput compared to the distributed data parallel (DDP) benchmark when training with ViT-H/16.
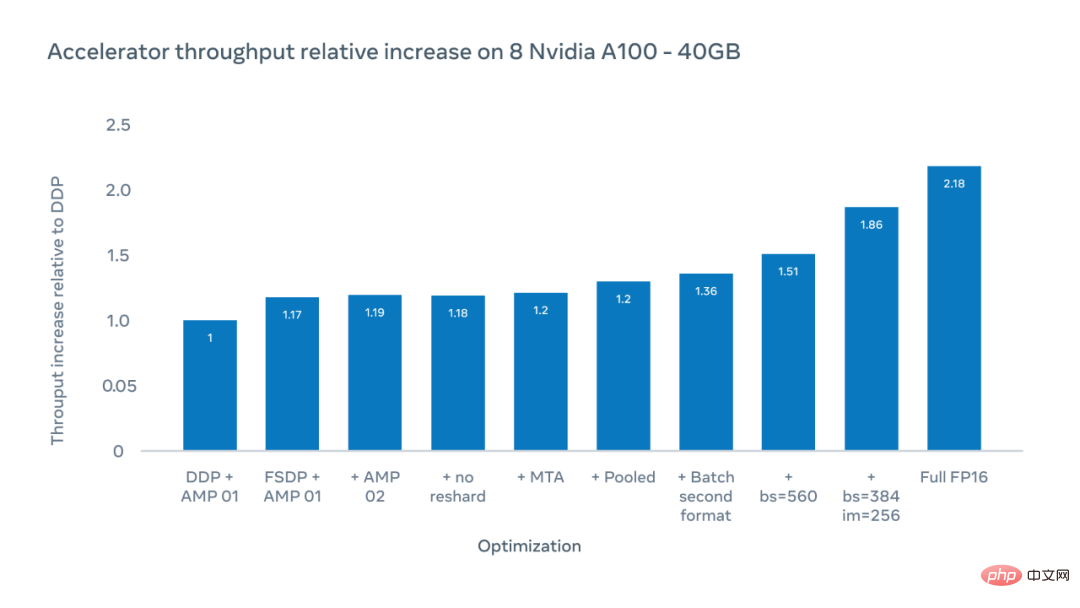
The researchers achieved a 1.51x increase in accelerator throughput when the total patch size was 560, in terms of execution times per second on each accelerator chip. Measured by the number of floating point operations. By increasing the image size from 224 to 256 pixels, they were able to increase the throughput to 1.86x. However, changing the image size means changing the hyperparameters, which will have an impact on the accuracy of the model. When training in full FP16 mode, the relative throughput increases to 2.18x. Although accuracy was sometimes reduced, in experiments the accuracy was reduced by less than 10%.
The Y-axis of the figure below is the epoch time, the duration of the last training in the entire ImageNet-1K data set. Here we focus on actual training times for existing configurations, which typically use an image size of 224 pixels.
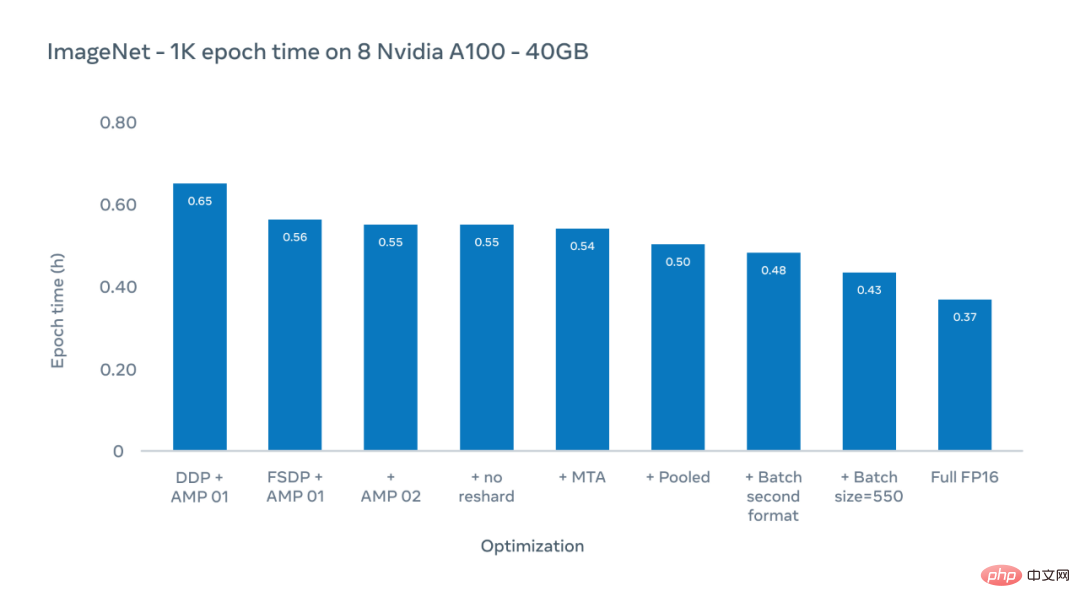
Meta AI researchers used an optimization scheme to reduce the epoch time (the duration of one training session on the entire ImageNet-1K dataset) from 0.65 hours to 0.43 hours.
The X-axis of the figure below represents the number of A100 GPU accelerator chips in a specific configuration, and the Y-axis represents the absolute throughput in TFLOPS per chip.
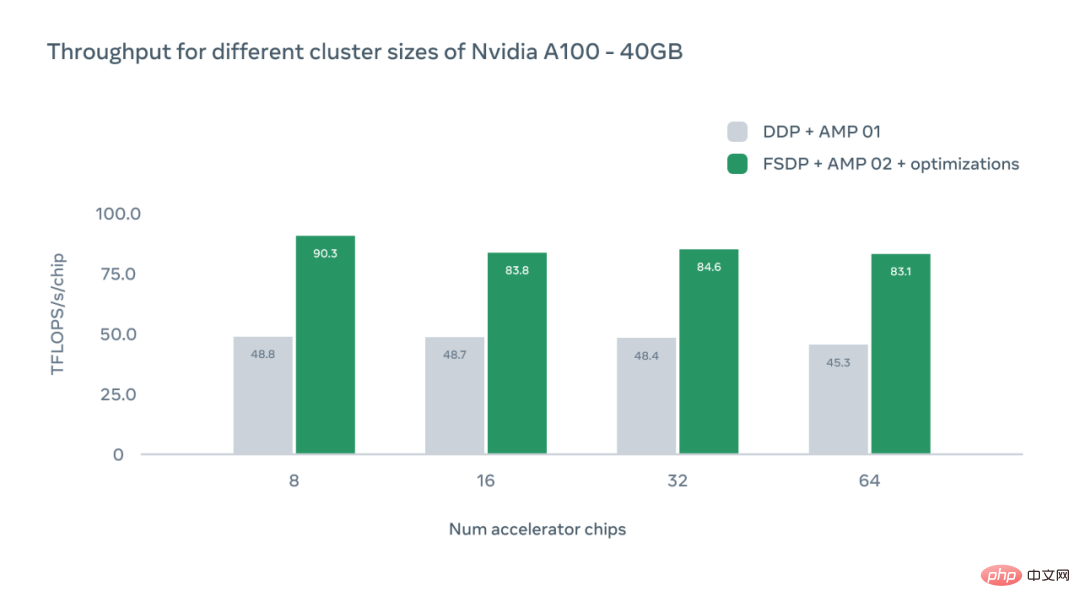
The study also discusses the impact of different GPU configurations. In each case, the system achieved higher throughput than the distributed data parallel (DDP) baseline level. As the number of chips increases, we can observe a slight decrease in throughput due to the overhead of inter-device communication. However, even with 64 GPUs, Meta's system is 1.83x faster than the DDP benchmark.
Significance of new research
Doubling the achievable throughput in ViT training can effectively double the size of the training cluster and improve the accelerator Utilization directly reduces the carbon emissions of AI models. Since the recent development of large models has brought about the trend of larger models and longer training times, this optimization is expected to help the research field further push the state-of-the-art technology, shorten the turnaround time, and increase productivity.
The above is the detailed content of Without heaping parameters or relying on time, Meta accelerates the ViT training process and increases the throughput by 4 times.. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology