
Home >Backend Development >Python Tutorial >Pandas Tips: Basic DataFrame Operations and Null Value Filling
Pandas Tips: Basic DataFrame Operations and Null Value Filling

- coldplay.xixiforward
- 2020-09-16 16:20:364662browse

Related learning recommendations: python tutorial
pandas data processing In the fourth article of the topic, let’s talk about indexes in DataFrame.
In the previous article, we introduced the use of some commonly used indexes in the DataFrame data structure, such as iloc, loc, logical indexes, etc. In today's article, let's take a look at somebasic operations of DataFrame.
Data alignment
We can calculate the sum of two DataFrames,pandas will automatically Two DataFrames perform data alignment. If the data does not match, it will be set to Nan (not a number).
First we create two DataFrames:import numpy as npimport pandas as pddf1 = pd.DataFrame(np.arange(9).reshape((3, 3)), columns=list('abc'), index=['1', '2', '3'])df2 = pd.DataFrame(np.arange(12).reshape((4, 3)), columns=list('abd'), index=['2', '3', '4', '5'])复制代码The result is consistent with what we imagined. In fact, it is just create the DataFrame through the numpy array, and then specify the index and columns. , this should be considered a very basic usage.
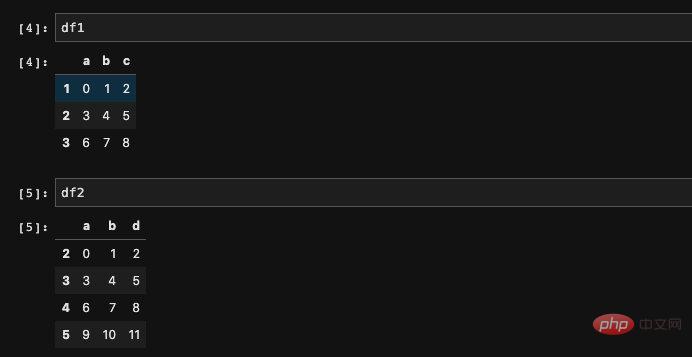
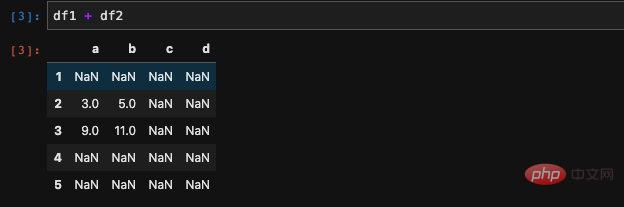
any position that does not appear in both DataFrames will be set to Nan. This actually makes sense. In fact, not just addition, we can calculate the four arithmetic operations of addition, subtraction, multiplication and division of two DataFrames. If you calculate the division of two DataFrames, in addition to the data that does not correspond to it will be set to Nan, The act of dividing by zero will also lead to the occurrence of outliers (may not necessarily be Nan, but is inf).
fill_value
If we are going to operate on two DataFrames, then of course we don’t want null values to appear . At this time, we need to fill in the null values. If we directly use operators to perform operations, we cannot pass parameters for filling. At this time, we need to use thearithmetic method provided for us in the DataFrame.
There are several commonly used operators in DataFrame: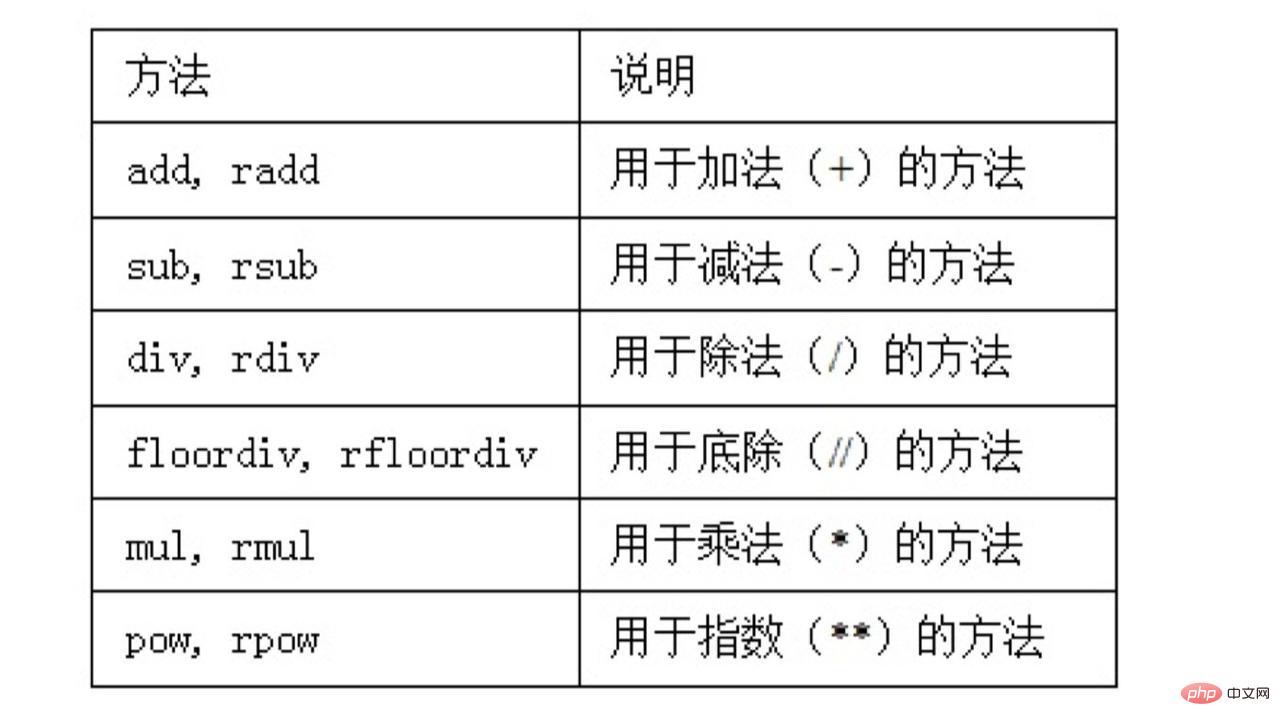
We all understand add, sub, and p very well, so what do the radd and rsub methods here mean? Why is there an r in front?
It seems confusing, but to put it bluntly, radd is used to flip parameters. For example, if we want to get the reciprocal of all elements in the DataFrame, we can write it as 1/df. Since 1 itself is not a DataFrame, we cannot use 1 to call methods in the DataFrame, and we cannot pass parameters. In order to solve this situation, wecan write 1/df as df.rp(1), so we can pass parameters in it.
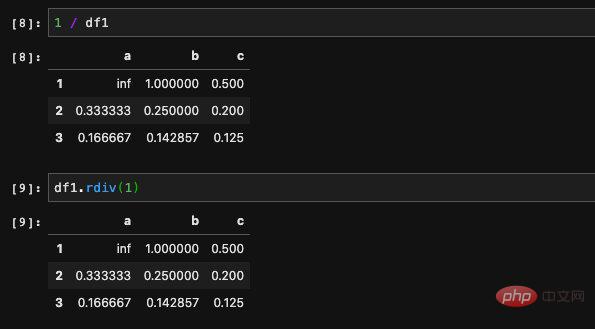
Since division by zero occurs during the division calculation, we get an inf, which represents infinity.
We can pass in a fill_value parameter in the add and p methods. This parameter can fill in the case of missing values on one side before calculation. That is to say, positions that are missing in only one DataFrame will be replaced with the value we specify. If it is missing in both DataFrames, it will still be Nan.
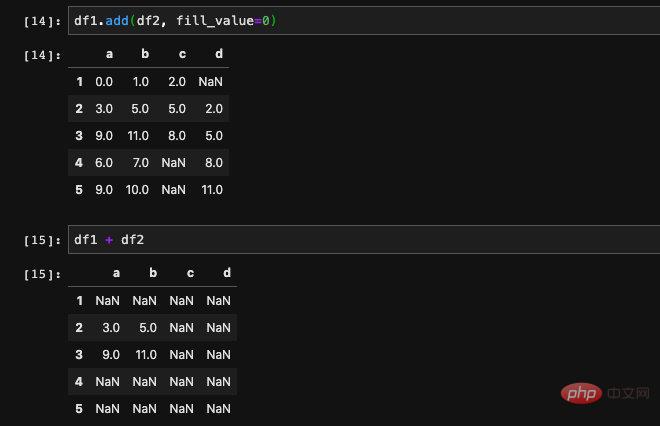
We can compare the results and find that the positions of (1, d), (4, c) and (5, c) after addition are all Nan , because these positions in the two DataFrames df1 and df2 are empty values, so they are not filled.
#fill_value This parameter appears in many APIs, such as reindex, etc. The usage is the same. We can pay attention to it when checking the API documentation.
So what should we do with this kind of empty value that still appears after filling? Can I only manually find these locations and fill them in? Of course it is unrealistic. Pandas also provides us with an API that specifically solves null values.
null value api
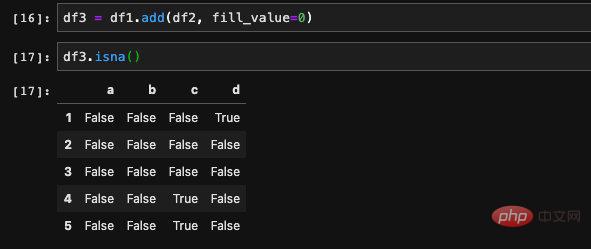
#Before filling the null value, the first thing we have to do is find the null value. To solve this problem, we have the isna API, which will return a bool DataFrame. Each position in the DataFrame indicates whether the corresponding position of the original DataFrame is a null value.
dropna
Of course, just finding out whether it is a null value is definitely not enough, we Sometimes we hope that null values will not appear. At this time, we can choose drop the null values. For this situation, we can use the dropna method in DataFrame.
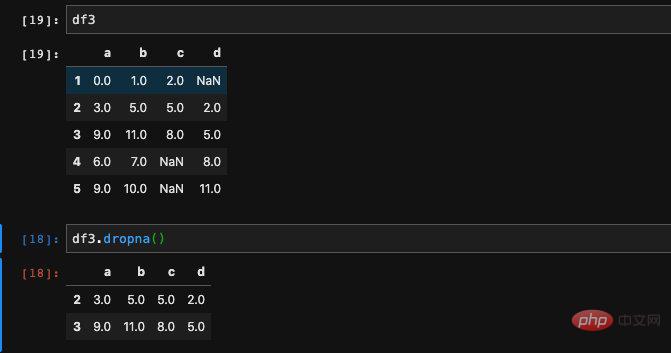
We found that after using dropna, rows with null values were discarded. Only rows without null values are retained. Sometimes we want to discard the columns instead of rows. At this time, we can control it by passing in the axis parameter.
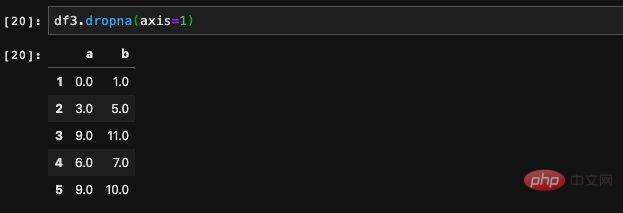
In this way, what we get is a column that does not contain null values. In addition to controlling the rows and columns, we can also control the strictness of executing drop . We can judge by the how parameter. How supports two values to be passed in, one is 'all' and the other is 'any'. All means that it will be discarded only when a certain row or column is all null values, and corresponding to any, it will be discarded as long as null values appear. If it is not filled in by default, it is considered to be any. Under normal circumstances, we do not use this parameter, and it is enough to have an impression.
fillna
In addition to dropping data containing null values, pandas can also be used Fill empty values, in fact this is also the most commonly used method.
We can simply pass in a specific value for filling:
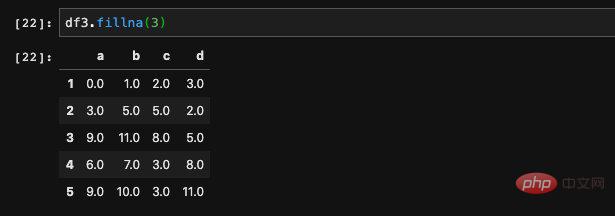
fillna will return a new DataFrame, All Nan values will be replaced with the values we specify. If we do not want it to return a new DataFrame, but directly modify the original data, we can use the inplace parameter to indicate that this is an inplace operation, then pandas will modify the original DataFrame.
df3.fillna(3, inplace=True)复制代码
除了填充具体的值以外,我们也可以和一些计算结合起来算出来应该填充的值。比如说我们可以计算出某一列的均值、最大值、最小值等各种计算来填充。fillna这个函数不仅可以使用在DataFrame上,也可以使用在Series上,所以我们可以针对DataFrame中的某一列或者是某些列进行填充:
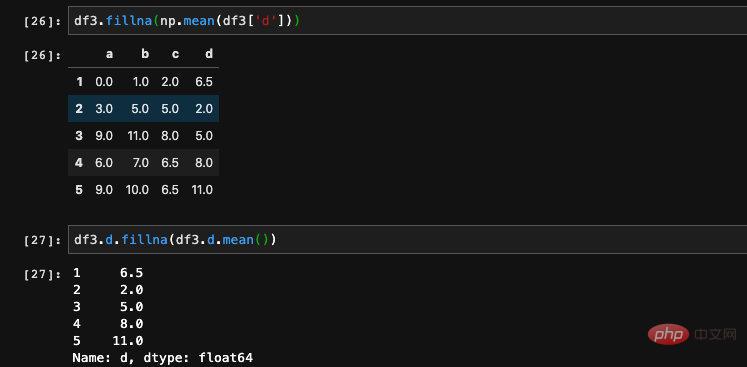
除了可以计算出均值、最大最小值等各种值来进行填充之外,还可以指定使用缺失值的前一行或者是后一行的值来填充。实现这个功能需要用到method这个参数,它有两个接收值,ffill表示用前一行的值来进行填充,bfill表示使用后一行的值填充。
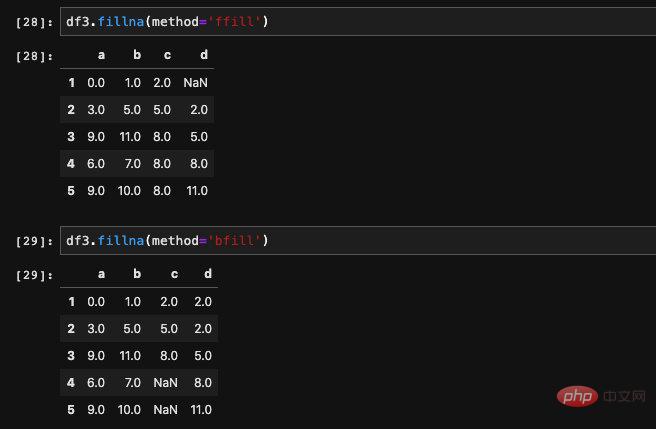
我们可以看到,当我们使用ffill填充的时候,对于第一行的数据来说由于它没有前一行了,所以它的Nan会被保留。同样当我们使用bfill的时候,最后一行也无法填充。
总结
今天的文章当中我们主要介绍了DataFrame的一些基本运算,比如最基础的四则运算。在进行四则运算的时候由于DataFrame之间可能存在行列索引不能对齐的情况,这样计算得到的结果会出现空值,所以我们需要对空值进行处理。我们可以在进行计算的时候通过传入fill_value进行填充,也可以在计算之后对结果进行fillna填充。
在实际的运用当中,我们一般很少会直接对两个DataFrame进行加减运算,但是DataFrame中出现空置是家常便饭的事情。因此对于空值的填充和处理非常重要,可以说是学习中的重点,大家千万注意。
想了解更多编程学习,敬请关注php培训栏目!
The above is the detailed content of Pandas Tips: Basic DataFrame Operations and Null Value Filling. For more information, please follow other related articles on the PHP Chinese website!