
Home >Backend Development >Python Tutorial >Series of data processing using pandas
Series of data processing using pandas

- coldplay.xixiforward
- 2020-09-15 16:10:372471browse

Related learning recommendations: python tutorial
Pandas.
The full name of Pandas is Python Data Analysis Library, which is ascientific computing tool based on Numpy. Its biggest feature is that it can operate structured data just like operating tables in a database, so it supports many complex and advanced operations and can be considered an enhanced version of Numpy. It can easily construct complete data from a csv or excel table, and supports many table-level batch data calculation interfaces.
Installation usingLike almost all Python packages, pandas can also be installed through pip. If you have installed the Anaconda suite, libraries such as numpy and pandas have been installed automatically. If you have not installed it, it does not matter. We can complete the installation with one line of commands. pip install pandas复制代码
Like Numpy, we usually give it an alias when using pandas. The alias of pandas is pd. Therefore, the convention for using pandas is:
import pandas as pd复制代码If you run this line without an error, it means that your pandas has been installed. There are two other packages that are generally used together with pandas. One of them is also a scientific computing package called Scipy, and the other is a tool package for visualizing data, called Matplotlib. We can also use pip to install these two packages together. In subsequent articles, when these two packages are used, their usage will be briefly introduced.
pip install scipy matplotlib复制代码
Series indexThere are two most commonly used data structures in pandas, one is Series and the other One is a DataFrame. Among them, series is a one-dimensional data structure
, which can be simply understood as a one-dimensional array or a one-dimensional vector. DataFrame is naturally a two-dimensional data structure, which can be understood as a table or a two-dimensional array.Let’s take a look at Series first. There are two main types of data stored in Series. One is an array composed of a set of data, and the other is the index or label of this set of data. We simply create a Series and print it out to understand.
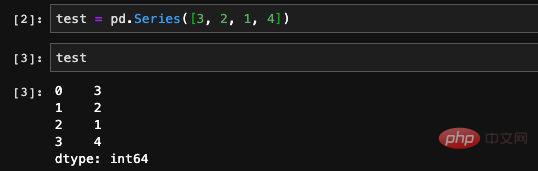 The first column is its index
The first column is its index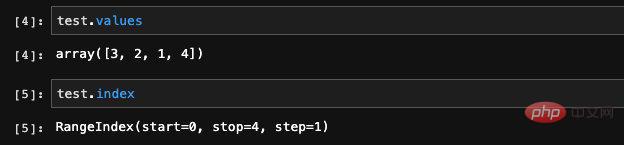
The values output here are a Numpy array. This is not surprising, because as we said earlier, pandas is a scientific computing library developed based on Numpy. Numpy is its underlying layer. From the printed index information, we can see that this is a Range type index, its range and step size.
The index is a default parameter in the Series construction function. If we do not fill it in, it will generate a Range index for us by default, which is actually the row number of the data. We can also specify the index of the data ourselves. For example, if we add the index parameter to the code just now, we can specify the index ourselves.

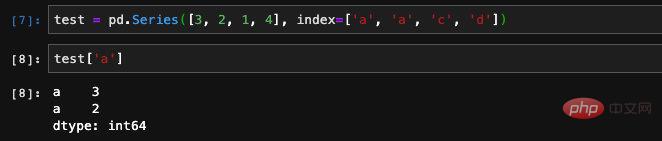
When we specify the index of the character type, the result returned by index is no longer RangeIndex but Index. Note that pandas internally distinguishes between numeric indexes and character indexes.
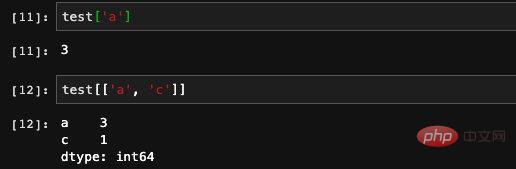
With the index, it is naturally used to find elements. We can directly use the index as the subscript of the array, and the effect of the two is the same. Not only that, index arrays are also acceptable, and we can directly query the values of several indexes.
duplicate indexes are also allowed. Similarly, when we use index queries, we will also get multiple results.

Series calculation
addition, subtraction, multiplication and division operations Perform operations on the entire Series: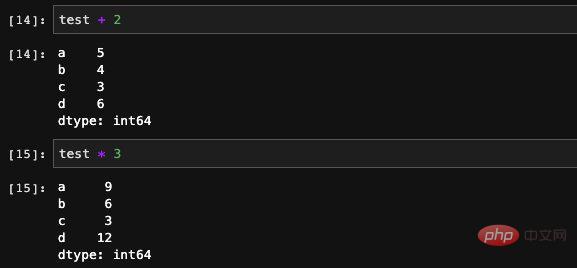
You can also use the operation function in Numpy to perform some complex mathematical operations, but the result of this calculation will be a Numpy array.
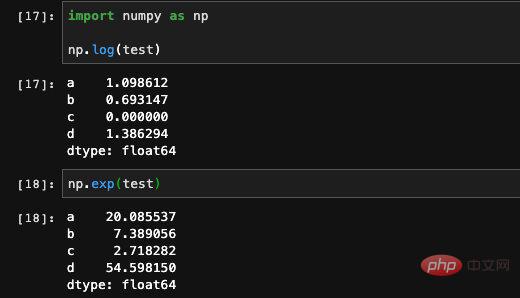
Because there is an index in the Series, we can also use dict to determine whether the index is in the Series:
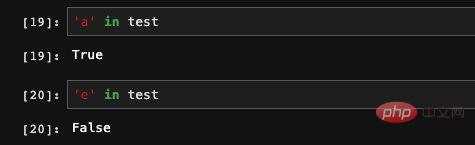
Series has indexes and values. In fact, the storage structure is the same as dict, so Seires also supports initialization through a dict:
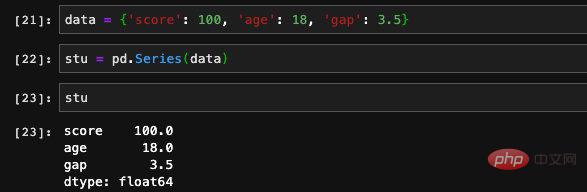
Through this The order created in this way is the order in which the keys are stored in the dict. We canspecify index when creating, so that we can control its order.
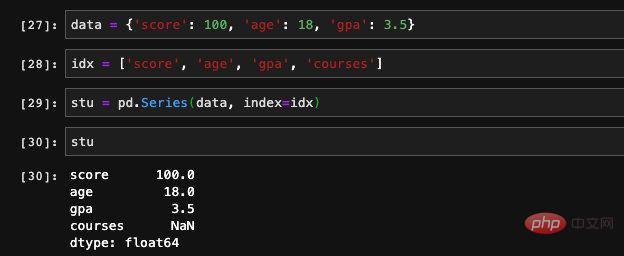
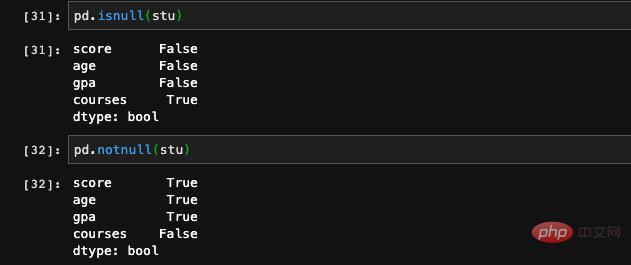
We passed in an additional key that did not appear in the dict when specifying the index. Since the corresponding value cannot be found in the dict, Series will Record it as NAN (Not a number). It can be understood as illegal value or null value. When we process features or training data, we often encounter situations where a certain feature of the data with some entries is blank. We can use pandas The isnull and notnull functions check for vacancies.
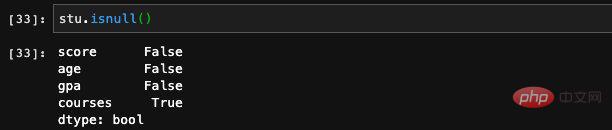
Of course, there is also an isnull function in Series, which we can also call.
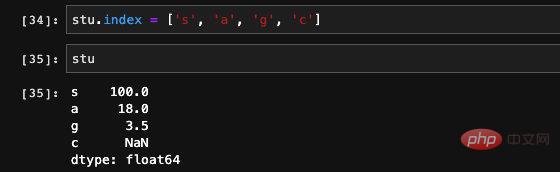
Finally, the index in the Series can also be modified, we can directly assign a new value to it:
Summary
At its core, Series in pandas isA layer of encapsulation on Numpy one-dimensional array, adding some related functions such as indexing. So we can imagine that DataFrame is actually an encapsulation of a Series array, with more data processing-related functions added. Once we have grasped the core structure, it is much more useful to understand the entire function of pandas than to memorize these APIs one by one.
pandas is a great tool for Python data processing. As a qualified algorithm engineer, it is almost a must-know. It is also the basis for us to use Python for machine learning and deep learning. According to survey data, 70% of the daily work of algorithm engineers is invested in data processing, and less than 30% is actually used to implement and train models. Therefore, we can see the importance of data processing. If you want to develop in the industry, it is not just enough to learn the model. This article uses mdnice for typesetting
php training
The above is the detailed content of Series of data processing using pandas. For more information, please follow other related articles on the PHP Chinese website!