
Home >Database >Mysql Tutorial >[MySQL database] Interpretation of Chapter 4: Schema and data type optimization (Part 1)
[MySQL database] Interpretation of Chapter 4: Schema and data type optimization (Part 1)
- php是最好的语言Original
- 2018-08-07 13:53:421830browse
Foreword:
The cornerstone of high performance: good logical and physical design, and schema design based on the query statements to be executed by the system
This chapter focuses on MySQL database design and introduces the difference between mysql database design and other relational database management systems
schema: [Source]
Schema is A collection of database objects. This collection contains various objects such as tables, views, stored procedures, indexes, etc. In order to distinguish different collections, you need to give different names to different collections. By default, one user corresponds to one collection , and the user's schema name is equal to the user name, and is used as the user's default schema. So the schema collection looks like usernames.
If you think of the database as a warehouse, the warehouse has many rooms (schema), one schema represents a room, the table can be seen as a locker in each room, and the user is the owner of each schema. Has the right to operate each room in the database, which means that each user mapped in the database has the key to each schema (room). There are differences between SQL server and Oracle mysql
4.1 Select the optimized data type
Principle:
1, Smaller passes are better, try to use them The smallest data type that can store data correctly (occupies less disk memory and CPU cache, requires fewer CPU cycles for processing: faster), but can cover the data, and it will be embarrassing if it cannot be stored
2 , Simple is good: simple type (less CPU cycles), use MySQL built-in type storage time, integer type storage IP, integer type is cheaper than characters (character set and collation rules make characters more complex)
3. Try to avoid null: It is best to specify not null
*) Null columns use more storage space and require special processing in mysql
*) Null makes index, index statistics and Value comparison is more complex; when nullable columns are indexed, each index record requires additional bytes
Exception: InnoDB uses a separate bit to store null, so for sparse data (many values are null) there are Very good space efficiency, not suitable for MyISAM
4.1.1 Integer type [Reference]
Integer whole number
tinyint (8-bit storage space) smallint(16) mediumint (24) int(32) bigint(64)
1. Range of stored values: 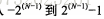 , N is the number of digits in the storage space
, N is the number of digits in the storage space
2. unsigned: optional, not allowed Negative values can double the upper limit of positive numbers: tinyint unsigned 0~255, tinyint-128~127
3. Use the same storage space and the same performance with or without signs
The width can be specified for an integer, such as INT(11), which is meaningless for most applications. It does not limit the legal range of values. It only specifies the number of characters displayed by interactive tools. For storage and calculation, int(1) and int (20) is the same;
real number real number: with decimal
float and double, mysql uses duble as the type of internal floating point calculation
decimal: stores precise Decimal, implemented by the mysql server itself, decimal(18,9)18 digits, 9 decimal digits, 9 bytes (first 4 and last 4 points 1)
Try to only use it when calculating decimals accurately ( Additional space and computational overhead), such as financial data
When the amount of data is large, consider using bigint instead, multiply the number of decimal places in the monetary unit data that needs to be stored by the corresponding multiple
float Point:
Suggestion: Only specify the type and indefinite precision (mysql). These precisions are non-standard. MySQL will silently select the type or round off the value when saving.
When storing values in the same range, Less space than decimal, float4 bytes store double8 bytes (higher precision range)
4.1.3 String type
varchar and char:
Prerequisite: Innodb and myisam engines, the most important string type
Disk storage: The storage method of the storage engine must be different from that in memory and disk, so the mysql server needs to convert the value from the engine to the format
varchar:
1. Storage of variable strings saves space compared to fixed length (only uses necessary space), but if the table uses row_format=fixed, the rows will be stored in fixed length
2. 1/2 extra bytes need to be used to record the string length; 1) column max length
3. Saves storage space and is beneficial to performance; but the row may change during update It is longer than the original and requires additional work
Suitable situations:
1) The maximum length of the string column is much larger than the average length; 2) Column update Less (no worries about fragmentation); 3) Use UTF-8 strings, each character is stored using a different number of bytes
#char:
1. Fixed length, allocate space according to the length, delete the spaces at the end of all; if the length is not enough, fill in the spaces
2. More efficient in storage space, char(1) can store only 1 value of Y N Bytes, varchar2 bytes, and a record length
Suitable situations:
1) Suitable for storing very short strings; 2) Or the all value is close to The same length; 3) Frequently changed data is not easily fragmented when stored.
corresponds to spaces and storage:
When the char type is stored, the trailing spaces are deleted; how the data is stored depends on Regarding the storage engine, the Memory engine only supports fixed-length lines (maximum length allocated space)
binary, varbinary: store binary string , bytecode, length Not enough, \0 to make up (not spaces) will not be used when retrieving
It is not wise to be generous: varchar(5) and varchar(100) have the same space overhead for storing 'hell', and long columns consume more memory
blob and text: big data
are stored in binary and character modes respectively, and belong to two different data types: character type: tinytext, smalltext, text, mediumtext, longtext, corresponding The binary types are tinyblob, smallblob, blob, mediumblob, and longblob. The only difference between the two types is that the blob type stores binary data without collation rules or character sets, while text has string collation rules;
MySQL will Each blob and text are treated as independent objects. The storage engine will perform special processing when storing. When the value is too large, innoDB uses a dedicated external storage area for storage. At this time, each value requires 1 in the row. ~4 bytes store a pointer, and then store the actual value externally;
Mysql sorts their columns: only the first max_sort_length bytes of each column are sorted; and strings with the full length of the column cannot be sorted Indexes cannot be used to eliminate sorting;
If the extra of the explain execution plan contains using temporary: this query uses an implicit temporary table
Use enum instead of string type
Specify the value range when defining. An enumeration of 1 to 255 members requires 1 byte of storage; for 256 to 65535 members, 2 bytes of storage are required. There can be up to 65535 members. The ENUM type can only select one from the members; is similar to set
You can change without Repeated fixed strings are stored in a predefined set. When MySQL stores enumerations, it will be compressed into 1/2 bytes according to the number of list values, and internally the position of each value in the list will be stored. Save as an integer (starting from 1, must be searched to convert to a string, the overhead and list are small and controllable ) , and keep the "number-character" in the .frm file of the table "Lookup table" of "string" mapping relationship;
Store a number into a ENUM, the number is treated as an index value, and the stored value is the corresponding index value Enumeration members: It is unwise to store numbers in a ENUM string because it may clutter your mind; ENUM values are as specified in the column specification Sort the list order. (ENUM values are sorted by their index number.) For example, for ENUM("a", "b") "a" is ranked "b" , but for ENUM("b", "a"), "b" is ranked "a" Before. Empty strings are sorted before non-empty strings, and NULL values are sorted before all other enumeration values. In order to prevent unexpected results, it is recommended that define the ENUMlist in alphabetical order. You can also use GROUP BY CONCAT(col) to determine whether to sort alphabetically rather than by index value. [Source]
first timestamp column is not specified when inserting, and is set to At the current time, when inserting a record, the value of the first timestamp column is updated by default. The timestamp class is not null. Try to use timestamp (high space efficiency);
You can use the bigint type to store subtleties. Level timestamp, or double to store the decimal part after seconds, or use MariaDB instead of MySQL;4.1.5 bit
bit: mysql5.0
Formerly synonymous with tinyint, new feature
bit(1) single-bit field, bit(2) 2 bits, the maximum length is 64 bits
The behavior varies depending on the storage engine. MyISAM packages and stores all BIT columns (17 separate bit columns only require 17 bits to store, myisam3 Bytes ok), other engines Memory and innoDB use the smallest integer type that is enough to store each bit column, which does not save storage space;
Mysql treats bit as a string type, retrieval The bit(1) value and result are strings containing binary 0/1. Scenario retrieval of numeric context converts strings into numbers. Most applications, best avoid using;
![[MySQL database] Interpretation of Chapter 4: Schema and data type optimization (Part 1)](https://img.php.cn//upload/image/636/907/440/1533621119495187.png "1533621119495187.png")
one element or a combination of multiple elements in the list. When fetching multiple elements, separate them with commas. The value of the SET type can only be a combination of up to 64 elements. Depending on the members, the storage is also different: [Reference, same as enum]
1~8成员的集合,占1个字节。 9~16成员的集合,占2个字节。 17~24成员的集合,占3个字节。 25~32成员的集合,占4个字节。 33~64成员的集合,占8个字节。Need to maintain a lot of true and false values, you can consider Merge these columns into set types, which are represented internally by mysql as a series of
packed bit sets (effective use of storage space) and mysql has find_in_set and field functions to facilitate querying Used in;
Disadvantages: Changing the definition of a column is expensive, requires alter table, and cannot be searched through the index via set Bitwise operation on integer columns: Instead of set The method: use integers to wrap a series of bits: 8 bits can be packed into tinyint and used in bitwise operations. Define name constants for the bits to simplify this work, but this way the query statement is difficult to write and understand 4.1.6 Select identifierIdentification column: self-increasing column [Source] 1) You don’t need to manually insert the value, the system provides a default sequence value; 2) Not required Matched with the primary key; 3) It is required to be a unique key; 4) At most one per table; 5) The type can only be numerical; 5) It can be set auto_increment_increment=3;When selecting the identity column type
Consider the storage type and how mysql performs calculations and comparisons on this type. After determining, make sure to use the same type in all related tables, and the types must match accurately;
Tips:
1. Integer type: Integer is usually the best choice, it is fast and can use auto_increment2. Enum and set types, fixed storage Information3. String: avoid, space consumption is slower than numbers, be especially careful with myisam tables (default string compression, slow query) 1) Completely "random" string MD5 The new values generated by the /SHA1/UUID function will be arbitrarily distributed in a large space, causing insert and some selects to slow down:Insert values are randomly written to different positions in the index, insert becomes slower (page Split disk random access clustered index fragments); select slows down, logically adjacent rows are distributed in different places on the disk and memory; random values cause the cache to become less effective for all type query statements ( Invalidate the access locality principle on which the cache relies)
Clustered index , the actual stored sequential structure and the physical structure of data storage Consistent. Generally speaking, there is only one physical sequence structure, and there can only be one clustered index for a table. Usually the default is the primary key. If you set the primary key, the system will add a clustered index for you by default; [Source]
Non-clustered indexThe physical order of records is not necessarily related to the logical order, and has nothing to do with the physical structure of data storage; there can be multiple non-clustered indexes corresponding to a table. Non-clustered indexes with different requirements can be established according to the constraints of different columns;
2) Store the uuid, remove the - symbol, or use unhex to convert the uuid value into a 16-byte number, and store it in binary (16 ) column, format it into hexadecimal format through the hex function during retrieval; The value generated by UUID is different from the value generated by the encrypted hash function (sha1): uuid is unevenly distributed and has a certain order. It is better to increment the integerBeware of automatically generated schema: Serious performance problems, large varchar, related columns of different types;orm will store any type of data in any type of back-end data storage. It is not designed to use a better type of storage. Sometimes it uses a separate row for each attribute of each object. Set using Timestamp-based version control results in multiple versions of a single attribute; trade-off
4.1.7 Special type of data: empty
Related articles:
[MySQL Database] Interpretation of Chapter 3: Server Performance Analysis (Part 1)
[MySQL Database] Interpretation of Chapter 3: Server Performance Analysis (Part 2)
The above is the detailed content of [MySQL database] Interpretation of Chapter 4: Schema and data type optimization (Part 1). For more information, please follow other related articles on the PHP Chinese website!