
Home >Web Front-end >JS Tutorial >NodeJS Encyclopedia Crawler Example Tutorial
NodeJS Encyclopedia Crawler Example Tutorial

- 小云云Original
- 2017-12-18 09:21:261704browse
This article mainly explains to you how to use NodeJS to learn crawlers, and explains the usage and effects by crawling the Encyclopedia of Embarrassing Things. Let's learn together. I hope it can help everyone.
1. Preface Analysis
We usually use Python/.NET language to implement crawlers, but now as a front-end developer, we naturally need to be proficient in NodeJS. Let's use NodeJS language to implement a crawler for Encyclopedia of Embarrassing Things. In addition, some of the codes used in this article are es6 syntax.
The dependent libraries required to implement this crawler are as follows.
request: Use get or post methods to obtain the source code of the web page. cheerio: Parse the web page source code and obtain the required data.
This article first introduces the dependency libraries required by the crawler and their use, and then uses these dependency libraries to implement a web crawler for Encyclopedia of Embarrassing Things.
2. request library
request is a lightweight http library that is very powerful and easy to use. You can use it to implement Http requests, and supports HTTP authentication, custom request headers, etc. Below is an introduction to some of the functions in the request library.
Install the request module as follows:
npm install request
After request is installed, it can be used. Now use request to request Baidu web pages.
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
When the options parameter is not set, the request method defaults to a get request. The specific method I like to use the request object is as follows:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
However, many times, we often do not get the information we need by directly requesting the html source code obtained from a URL. In general, request headers and web page encoding need to be taken into consideration.
Web page request header web page encoding
The following describes how to add a web page request header and set the correct encoding when requesting.
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
Set the options parameter, add the headers attribute to set the request header; add the encoding attribute to set the encoding of the web page. It should be noted that if encoding: null , then the content obtained by the get request is a Buffer object, that is, the body is a Buffer object.
The functions introduced above are enough to meet the following needs
3. cheerio library
cheerio is a server-side Jquery, which is light, fast, simple and easy to learn, etc. Features loved by developers. It is very easy to learn the cheerio library after having a basic knowledge of Jquery. It can quickly locate elements in web pages, and its rules are the same as Jquery's method of locating elements; it can also modify the content of elements in html and obtain their data in a very convenient form. The following mainly introduces cheerio to quickly locate elements in web pages and obtain their contents.
First install the cheerio library
npm install cheerio
The following is a piece of code, and then explains the usage of the cheerio library. Analyze the homepage of the blog park, and then extract the titles of the articles on each page.
First analyze the home page of the blog park. As shown below:
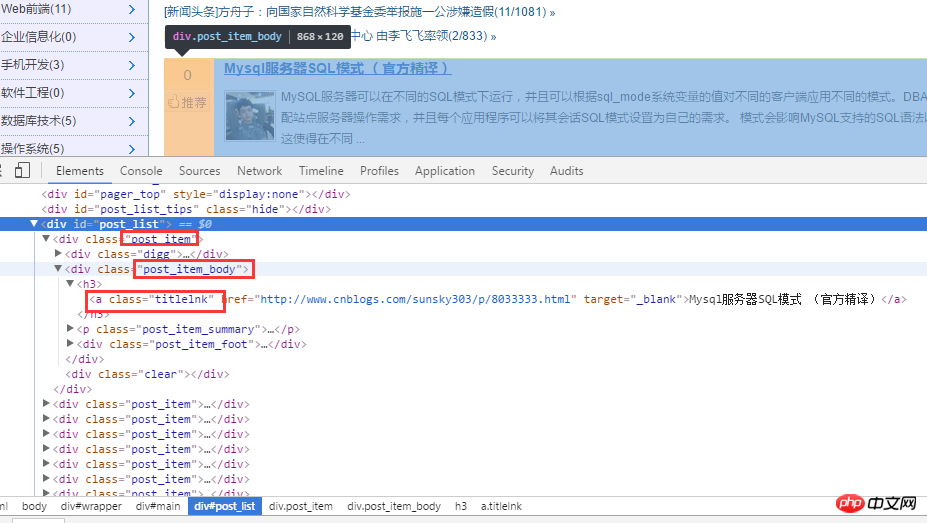
After analyzing the html source code, first obtain all titles through .post_item, then analyze each .post_item, and use a.titlelnk to match a tag for each title. The following is implemented through code.
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
Of course, the cheerio library also supports chain calls, and the above code can also be rewritten as:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
The above code is very simple, so I won’t elaborate on it in words. Below I summarize some of the points that I think are more important.
Use the find() method to obtain the node set A. If you use the element in the A set as the root node again to locate its child nodes and obtain the content and attributes of the child elements, you need to compare the child elements in the A set. Wrap $(A[i]) like $(ele) above. In the above code, $(ele) is used. In fact, $(this) can also be used. However, since I am using the arrow function of es6, the this pointer of the callback function in the each method is changed. Therefore, I use $(ele); The cheerio library also supports chain calls, such as $('.post_item').find('a.titlelnk') above. It should be noted that the cheerio object A calls the method find(). If A is a collection, then A The find() method is called for each child element in the collection and a resulting union is put back. If A calls text() , then each child element in A's collection calls text() and returns a string that is the union of the contents of all child elements (direct union, no delimiters).
Finally, I will summarize some of my more commonly used methods.
first() last() children([selector]): This method is similar to find, except that this method only searches child nodes, while find searches the entire descendant nodes.
4. Embarrassing Encyclopedia Crawler
Through the above introduction to the request and cheerio class libraries, let’s use these two libraries to crawl the pages of Embarrassing Encyclopedia.
1. In the project directory, create a new httpHelper.js file, and obtain the web page source code of Encyclopedia of Embarrassing Things through the URL. The code is as follows:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2. In the project directory, create a new Splider.js file, analyze the web code of Encyclopedia of Embarrassing Things, extract the information you need, and build a logic to crawl data from different pages by changing the id of the URL.
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
The above is the detailed content of NodeJS Encyclopedia Crawler Example Tutorial. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills