
Home >Database >Mysql Tutorial >Mysql-detailed explanation of index sorting rows
Mysql-detailed explanation of index sorting rows

- 黄舟Original
- 2017-03-02 16:33:561632browse
The previous article briefly introduced several structures and storage methods of B-TREE, but the relationship between index and data still does not feel connected.
So in this article, through an actual example of a data row, after creating the index, what is the order in which they are sorted on B+TREE.
1. Simulate and create original data
In the figure below, the left side is the simulated data for my own convenience. The engine is mysiam~
The right side is a normal simulation data table after randomly arranging them using EXCEL. The primary keys are then arranged according to 1-27 (if it is not random, I will originally simulate the data. It is written in order, and the index sorting process cannot be clearly seen after adding the index)
That is to say, the data on the right of makes the original data we want to test The data was sorted like this before the index was built. All subsequent data will be based on this. This will make it easier to see the sorting effect after the index is generated.
The table has 4 fields (id, a, b, c) and a total of 27 rows of data

# 2. Create index a
As shown below, when index a is created, the index structure changes from the original sorting according to the primary key ID to a new rule. We say that the index is actually a data structure. Then create index a, which is to create a new structure, sort according to the rules of field a, the first data row represented by the primary key ID is 1, the second data row represented by ID=3, and the third data row represented by ID=5 data row. . .
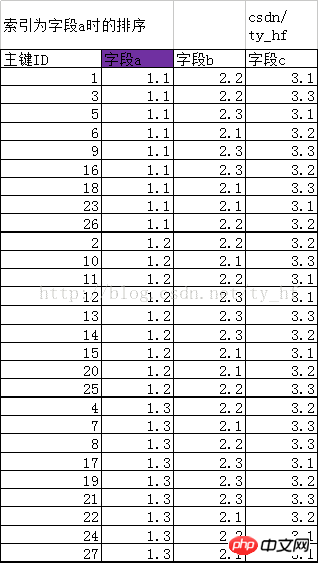
New sorting primary key IDIt is not difficult to find that when field a is the same, their arrangement Sort by primary key ID before and after. For example, the same value is a=1.1, but their order is that the ID value is 1, 3, 5, 6. . The corresponding rows are sorted in a similar order to the primary key ID.(ID represents their row of data):1 3 5 6 9 16 18 23 26 2 10 11 12 13 14 15 20 25 4 7 8 17 19 21 22 24 27
(That is, the sorting when the values are the same, the smaller ID is in front)
3. Create index (a,b)
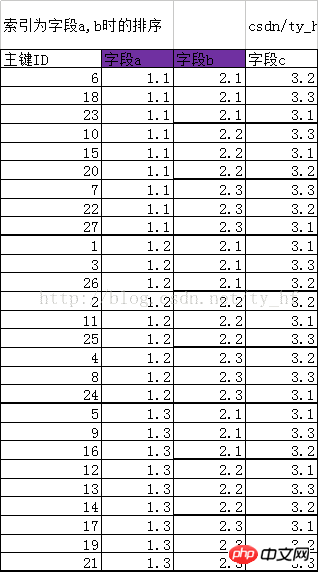
As shown below, after creating the joint index (a,b), in the index In the structure, the original sorting according to the primary key ID has been changed to a new rule. The sorting rule first sorts according to field a, and then sorts according to field b based on a. That is, based on index a, field b is also sorted.
New sorting primary key ID (ID represents their row of data): 6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
It is not difficult to find that when the values of fields a and b are the same, their arrangement The before and after are also determined by the primary key ID. For example, the same row (18, 6, 23) with a=1.1, b=2.1, but their order is 6, 18, 23.
Field (a,b) index, first sort by a index, and then based on a, sort by b
6 18 23 10 15 20 7 22 27 1 3 26 2 11 25 4 8 24 5 9 16 12 13 14 17 19 21
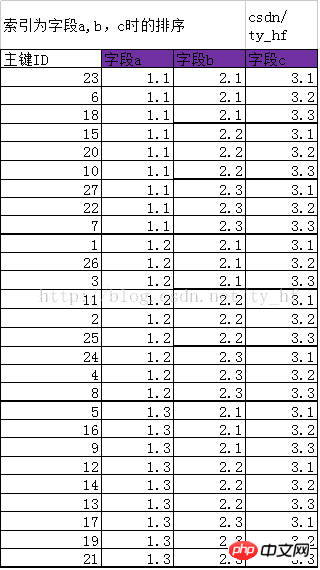
IV. Create index (a,b,c)
field (a,b,c) index, first sort by a,b index, and then On the basis of (a, b), sort according to c
##New sorting primary key ID (Use ID to represent their row data): 23 6 18 15 20 10 27 22 7 1 26 3 11 2 25 24 4 8 5 16 9 12 14 13 17 19 21
5. Conclusion:
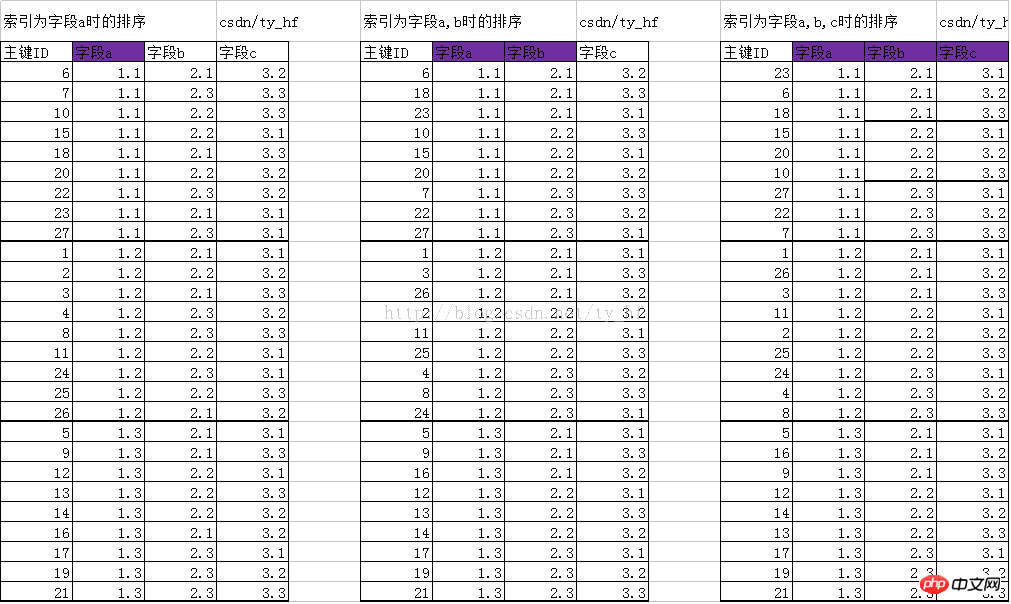

##and The previous article
is the same as what I said. The last row of leaf nodes in the B-TREE tree is arranged from left to right in this order. Different indexes are in different orders. With the order, wouldn't the search be much more convenient and faster?
We know that the process of reading data (quite (for the process of finding a room), if there is an index (room registration table), first read the data structure of the index (because it is small and fast to read), and find the storage location of the real physical disk (equivalent to the leaf node of its structure). After finding the house number), then take the house number to get the data directly from the disk. This is a process of reading data. If there is no index, it means you don’t know the destination. Just search from room to room.
When there is no index, the primary key ID is actually their index, arranged according to the rules of primary key ID from small to large;When there is something During indexing, index a, joint index (a, b), and joint index (a, b, c) correspond to three B+TREE structures, and the physical disks pointed to by the end of the leaf nodes are different.
in conclusion: 1. If no index is created, it is arranged in ascending order according to the ID primary key 2. When index a is created, a new structural index (B+TREE) will be generated ) is used to record a new structural rule to facilitate quick search 3. When creating index a, index ab, and index abc, the corresponding data sorting of the three of them is different 4. Index abc takes into account both index ab and index a, so when the former is available, the latter two do not need to be created ##5. When an index is established, non-indexed columns are sorted by increasing ID by default