
Home >Web Front-end >JS Tutorial >Implementation code for finding the nearest common ancestor element in js_javascript skills
Implementation code for finding the nearest common ancestor element in js_javascript skills

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-05-16 18:12:561425browse
Let’s look at the concept first. First of all, DOM is a tree, and its root node is Document. It can be roughly represented by the following figure: 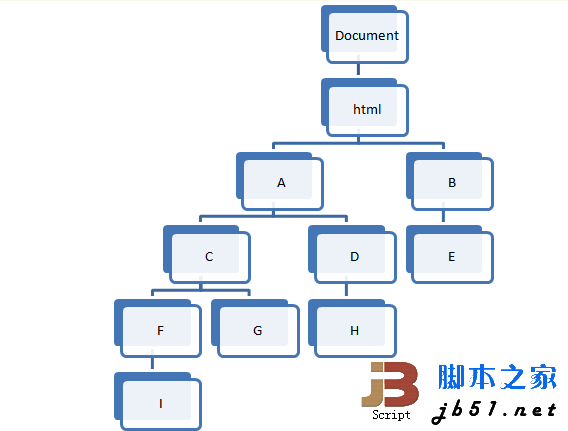
The so-called "recent common ancestor element" refers to a given series of Element, find the element that has the greatest depth in the tree, but is also the ancestor of all these elements.
For example, in the picture above, the result of I and G is C, the result of G and H is A, the result of D and E is html, the result of C and B is html, etc.
Test-driven
For logical questions, I am not completely sure that the function is correct, so I still construct the test function first and strive to make the function pass the test.
This time, the structure in the above picture is used as the DOM structure. A represents body, B represents head, and other nodes use div elements. At the same time, the input and output of the test are used as the input and output of the test. First, construct the test:
function test() {
var result;
result = find('i', 'g');
result.id !== 'c' && alert('fail (i, g)');
result = find('g' , 'h');
result.id !== 'a' && alert('fail (g, h)');
result = find('d', 'e');
result.nodeName.toLowerCase() !== 'html' && alert('fail (d, e)');
result = find('c', 'b');
result.nodeName.toLowerCase () !== 'html' && alert('fail (c, b)');
}
Basic logic
The logic this time is roughly like this:
1. For each given element, traverse upward from the parent element to the document.
2. Save each element passed during the traversal process into an ordered map, with the element as the key and the number of times traversed as the value.
2. Finally, traverse the map and find the item whose first value is the same as the number of given elements. It is the first element that has been passed by all elements in the traversal, that is, the most recent common ancestor element.
Detailed issues
In the actual process, the construction of the map is more important. There are two issues involved here:
1. The map cannot directly use elements as keys and must be converted into appropriate primitives. Type (such as number, string, Regex, etc.).
2. Chrome will automatically sort the keys in the object, so try to avoid using number type as the key.
For the first question, an appropriate field must be bound to the element to serve as a unique identifier. Fortunately, HTML5 provides data-* attributes, which greatly improves the metadata carrying capacity of DOM, and you can boldly add desired attributes.
As for the second question, it is not difficult in itself. Just avoid number in the generated identifier. The convenient method is to add an underscore or use String.fromCharCode to convert it into a character. No matter what, it doesn't matter.
Implementation code
The code is a bit long, mainly because I prefer the JAVA style. Every statement and every branch is clear. I don’t like to use && or || to handle conditional branches, so there are many lines with only In a case like braces, the really effective code is actually streamlined. I'm too lazy to install plug-ins like toggle, and I don't want to see the scroll bar, so I just threw it here.
function find() {
var length = arguments .length,
i = 0,
node, //Current node
parent, //Parent node
counter = 0,
uuid, //Unique identifier for DOM
hash = {}; //The map of the final result
//For each element, traverse upward to the document
//This double-layer loop is inevitable
for (; i < length; i ) {
//Get node
node = arguments[i];
if (typeof node == 'string') {
node = document.getElementById(node);
}
//Traverse upward
while (parent = node.parentElement || node.parentNode) {
//Stop when you reach the document, otherwise it will be an infinite loop
if (parent. nodeType == 9) {
break;
}
//Get or add an identifier
uuid = parent.getAttribute('data-find');
if (!uuid) {
uuid = '_' (counter); //Avoid chrome reordering hashes
parent.setAttribute('data-find', uuid);
}
//Increase the count
if (hash[uuid]) {
hash[uuid].count ;
}
else {
hash[uuid] = {node: parent, count: 1};
}
node = parent;
}
}
//The hash only contains the parent nodes that each node has traversed upwards and should not be very large
//So this loop is relatively fast
for (i in hash) {
if (hash[i].count == length) {
return hash[i].node;
}
}
};
Comments
There is no problem with the test, but it is hard to say whether the test cases are perfect. I hope netizens can help me find the problem. For the logical type, I really don’t have much confidence to say that it is 100% ok.
To get the parent element, it is customary to write parentElement || parentNode for compatibility with IE. This is because of a BUG in IE. When an element is just created but has not entered the DOM, the parentNode does not exist. However, this function ensures that the node is in the DOM tree. In fact, parentElement is not necessary. Therefore, sometimes habitually compatible code is not necessarily a good thing. The code that is most suitable for the current environment is good code.
Although it is said that double loops are inevitable, I still have a vague feeling that there are still ways to do less in certain situations. For example, when traversing upward, I find that a certain element cannot be the common ancestor of all elements, then Don't increment the count value anymore.
Is there any way to omit the last for..in loop? In the above double loop, is there any way to always save the most appropriate node through a variable in real time?
Related articles
See more- An in-depth analysis of the Bootstrap list group component
- Detailed explanation of JavaScript function currying
- Complete example of JS password generation and strength detection (with demo source code download)
- Angularjs integrates WeChat UI (weui)
- How to quickly switch between Traditional Chinese and Simplified Chinese with JavaScript and the trick for websites to support switching between Simplified and Traditional Chinese_javascript skills