
Home >Technology peripherals >AI >Performance Evaluation of Small Language Models
Performance Evaluation of Small Language Models

- Christopher NolanOriginal
- 2025-03-17 09:16:15994browse
This article explores the advantages of Small Language Models (SLMs) over their larger counterparts, focusing on their efficiency and suitability for resource-constrained environments. SLMs, with fewer than 10 billion parameters, offer speed and resource efficiency crucial for edge computing and real-time applications. This article details their creation, applications, and implementation using Ollama on Google Colab.
This guide covers:
- Understanding SLMs: Learn the defining characteristics of SLMs and their key differences from LLMs.
- SLM Creation Techniques: Explore knowledge distillation, pruning, and quantization methods used to create efficient SLMs from LLMs.
- Performance Evaluation: Compare the performance of various SLMs (LLaMA 2, Microsoft Phi, Qwen 2, Gemma 2, Mistral 7B) through a comparative analysis of their outputs.
- Practical Implementation: A step-by-step guide to running SLMs on Google Colab using Ollama.
- Applications of SLMs: Discover the diverse applications where SLMs excel, including chatbots, virtual assistants, and edge computing scenarios.
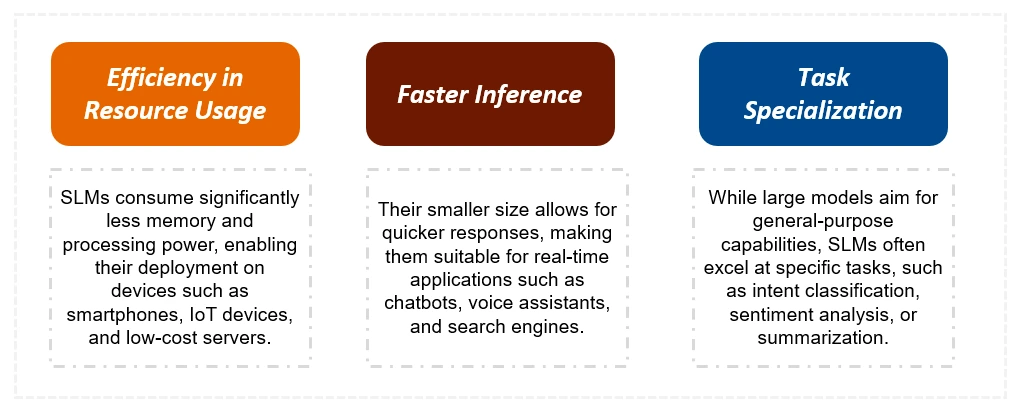
Key Differences: SLMs vs. LLMs
SLMs are significantly smaller than LLMs, requiring less training data and computational resources. This results in faster inference times and lower costs. While LLMs excel at complex, general tasks, SLMs are optimized for specific tasks and are better suited for resource-limited devices. The table below summarizes the key distinctions:
| Feature | Small Language Models (SLMs) | Large Language Models (LLMs) |
|---|---|---|
| Size | Significantly smaller (under 10 billion parameters) | Much larger (hundreds of billions or trillions of parameters) |
| Training Data | Smaller, focused datasets | Massive, diverse datasets |
| Training Time | Shorter (weeks) | Longer (months) |
| Resources | Low computational requirements | High computational requirements |
| Task Proficiency | Specialized tasks | General-purpose tasks |
| Inference | Can run on edge devices | Typically requires powerful GPUs |
| Response Time | Faster | Slower |
| Cost | Lower | Higher |
Building SLMs: Techniques and Examples
This section details the methods used to create SLMs from LLMs:
- Knowledge Distillation: A smaller "student" model learns from the outputs of a larger "teacher" model.
- Pruning: Removes less important connections or neurons in the larger model.
- Quantization: Reduces the precision of model parameters, lowering memory requirements.
The article then presents a detailed comparison of several state-of-the-art SLMs, including LLaMA 2, Microsoft Phi, Qwen 2, Gemma 2, and Mistral 7B, highlighting their unique features and performance benchmarks.

Running SLMs with Ollama on Google Colab
A practical guide demonstrates how to use Ollama to run SLMs on Google Colab, providing code snippets for installation, model selection, and prompt execution. The article showcases the outputs from different models, allowing for a direct comparison of their performance on a sample task.
Conclusion and FAQs
The article concludes by summarizing the advantages of SLMs and their suitability for various applications. A frequently asked questions section addresses common queries about SLMs, knowledge distillation, and the differences between pruning and quantization. The key takeaway emphasizes the balance SLMs achieve between efficiency and performance, making them valuable tools for developers and businesses.
The above is the detailed content of Performance Evaluation of Small Language Models. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology