
Home >Technology peripherals >AI >Leading the commercialization of AIGC with a 'vertical model', what is FancyTech's technical path?
Leading the commercialization of AIGC with a 'vertical model', what is FancyTech's technical path?

- 王林Original
- 2024-08-16 16:36:31576browse
We are witnessing another round of technological innovation. This time, AIGC provides individuals with tools to express themselves, making creation easier and more popular, but the driving force behind it is not the "big" model.
In the past two years, AIGC technology has developed faster than everyone imagined, sweeping into all fields from text, images to videos. Discussions on the commercialization path of AIGC have never stopped. Among them, there are consensus and divergence of routes.
On the one hand, the powerful capabilities of the general model are amazing, showing application potential in all walks of life. In particular, the introduction of architectures such as DiT and VAR has enabled Scaling Law to leapfrog from text to visual generation. Under the guidance of this rule, many large model manufacturers continue to move forward in the direction of increasing training data, computing power investment, and accumulating parameters.
On the other hand, we have also seen that a universal model does not mean "kill all". In the face of many subdivided track tasks, a "well-trained" vertical model can achieve better results.
As large model technology enters a period of accelerated implementation, the latter commercialization path has received rapid growth in attention.
In this evolution process, a startup company from China, FancyTech, stands out: It has rapidly expanded the market with standardized products for commercial visual content generation, and has verified the superiority of the "vertical model" at the industrial implementation level earlier than its peers. sex.
Looking around the domestic large-model entrepreneurial circle, FancyTech’s commercialization record is obvious to all. But what is less known is the vertical model and technological advantages that this company, which was born only a few years ago, is at the forefront of the track.
In an exclusive interview, this website talked with FancyTech about the technological exploration they are doing.
FancyTech releases video vertical model DeepVideo
How to break through industry barriers?
Generally speaking, after the zero-sample generalization ability of a general model reaches a certain level, fine-tuning it can be used for downstream tasks. This is also the way many large model products are launched today. But from the actual effect, just "fine-tuning" cannot meet the needs of industrial applications, because the content generation tasks of each industry have their own specific and complex set of standards.
A general model may be able to complete 70% of conventional tasks, but what customers really need is a "vertical model" that can meet 100% of their needs. Take commercial visual design as an example. In the past, related work was completed by professionals with long-term accumulation, and it needed to be designed and adjusted according to the specific needs of the brand, which involved a lot of manual experience. Compared with indicators such as aesthetics and instruction compliance, "product restoration" is a point that brands pay more attention to in this task, and it is also the deciding factor in whether brands are willing to pay.
In the process of self-developing a vertical model for commercial images/videos, FancyTech disassembled the core challenge: how to make the product sufficiently restored and blended into the background, especially in the generated video, to achieve controllable and inconsistent movement of the product. deformation.



With the development of large model technology today, for the application layer, taking the open source or closed source route is no longer the core issue. FancyTech's vertical model is based on the open source underlying algorithm framework, superimposed with its own data annotation and re-training, and only requires a few hundred GPUs for continuous training iterations to achieve good generation results. In contrast, the two factors of "product data" and "training methods" are more critical to the final implementation effect.
FancyTech has introduced the idea of spatial intelligence to guide the 2D content generation of the model on the premise of accumulating massive 3D training data. Specifically, in terms of image content generation, the team proposed a "multi-modal feature device" to ensure the restoration of the product, and used special data collection to ensure the natural integration of the product and the background; in terms of video content generation, the team reconstructed the video The generated underlying links are designed to directionally design the framework and perform data engineering to achieve product-centered video generation.
True dimensionality reduction attack: How does "spatial intelligence" guide 2D content generation?
The core reason why many visual generation products are unsatisfactory is that current image and video generation models often learn based on 2D training data and do not understand the real physical world.
This has reached a consensus in the field, and some researchers even believe that under the autoregressive learning paradigm, the model’s understanding of the world is always shallow.
But in the subdivision task of commercial visual generation, it is not completely unsolvable to enhance the understanding of the 3D physical world of the model and better generate 2D content.
FancyTech has migrated research ideas in the field of "spatial intelligence" to the construction of visual generative models. Different from general generative models, the idea of spatial intelligence is to learn from the original signals obtained by a large number of sensors and accurately calibrate the original signals obtained by the sensors to give the model the ability to perceive and understand the real world.
Therefore, FancyTech uses lidar scanning instead of traditional studio shooting, and has accumulated a large number of high-quality 3D data pairs that reflect the differences before and after product integration, and combines 3D point cloud data with 2D data as model training data to enhance the model understanding of the real world.
We know that in the generation of any visual content, the shaping of light and shadow effects is a very challenging task. Elements such as lighting, luminous bodies, backlighting, and light spots can make the spatial layering of the picture stronger, but this is a "knowledge point" that is difficult to understand for generative models.
In order to collect as much natural light and shadow data as possible, FancyTech established dozens of lights with adjustable brightness and color temperature in each environment, which means that each pair in the massive data can be superimposed with multiple lights and different brightnesses. and changes in color temperature.

This high-intensity data collection simulates the lighting of real shooting scenes, making it more in line with the characteristics of e-commerce scenes.

Combined with high-quality 3D data accumulation, FancyTech has made a series of innovations in the algorithm framework, organically combining spatial algorithms with image and video algorithms to allow the model to better understand the interaction between core objects and the environment.
During the training process, the model can "emerge" to a certain extent with an understanding of the physical world, and have a deeper understanding of three-dimensional space, depth, reflection and refraction of light, and the results of light operating in different media and different materials. cognition, and finally achieved the "strong reduction" and "hyper-fusion" of the products in the generated results.
What are the algorithm innovations behind “strong reduction” and “hyper-fusion”?
For common product scene image generation tasks, the mainstream method at this stage mainly uses textures to ensure the restoration of the product part, and then implements the editing of image scenes based on Inpainting technology. The user selects the area that needs to be changed, enters Prompt or provides a reference image to guide the product scene generation. The fusion effect of this method is better, but the disadvantage is that the controllability of the scene generation results is not high. For example, it is not clear enough or too simple, and it cannot guarantee the high availability rate of a single output.
In response to problems that cannot be solved by current methods, FancyTech proposes a proprietary "multi-modal feature generator" that extracts product features in multiple dimensions, and then uses these features to generate integrated scene graphs.
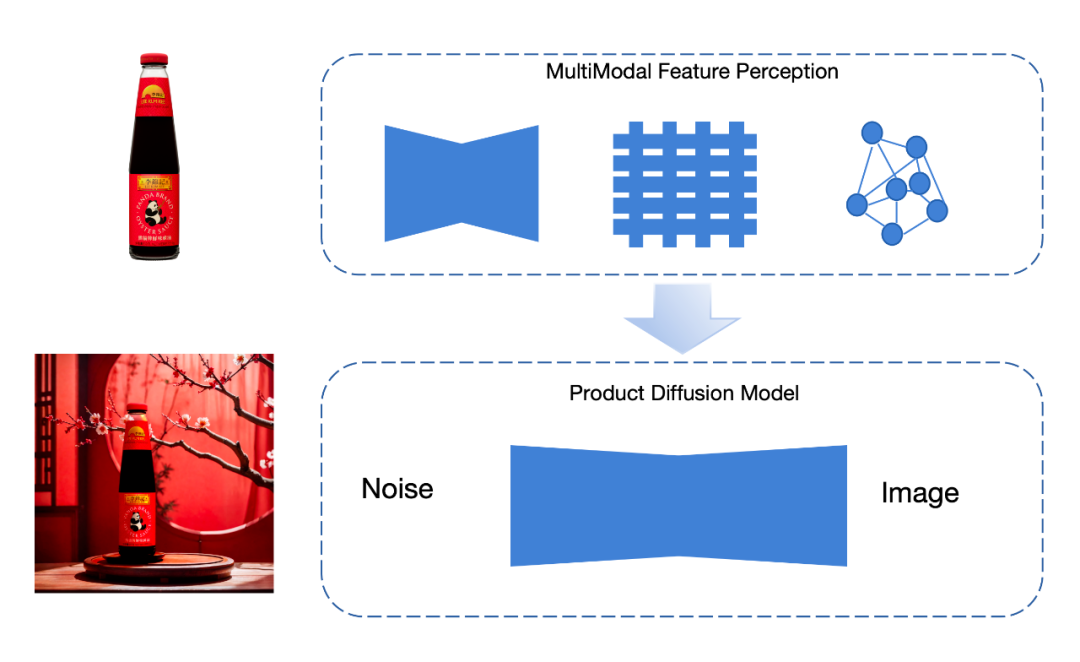
The work of extracting features can be divided into "global features" and "local features". Global features include the outline, color and other elements of the product, which are extracted using VAE encoders; local features include product details everywhere, using graph neural Network extraction. One of the great benefits of the graph neural network is that it can extract the information of each key pixel in the product and the relationship between the key pixels, and improve the restoration of details inside the product.
In the content generation of flexible material products, the effect obtained by this method is significantly improved: 
Compared with images, video generation also involves the motion control of the product itself and the changes in light and shadow it brings. For general video generation models, the difficulty lies in the inability to independently protect a certain part of the video. In order to solve this problem, FancyTech split the task into two branches: "product movement generation" and "video scene integration".
In the first step, FancyTech designed some targeted motion planning solutions to control the movement of the product in the screen, which is equivalent to "fixing" the product in each frame of the video in advance;
Step 2 , achieving controllable video generation through the control module. The control module adopts a flexible design and is compatible with different architectures such as U-net and DiT, making it easy to expand and optimize.
At the data level, in addition to using FancyTech’s unique product data resources to provide control training and product protection, multiple open source data sets are also added to ensure scene generalization capabilities. The training plan combines comparative learning and course learning, and ultimately achieves the protection effect of goods.
Let the dividends of the AIGC era
start from the vertical model and move towards more ordinary people
Whether it is "universal" or "vertical", the end point of both routes is commercialization.
The most direct beneficiary of the implementation of FancyTech’s vertical model is the brand. In the past, the production cycle of an advertising video could be as long as several weeks from planning, shooting, and editing. But in the AIGC era, it only takes ten minutes to create such an advertising video, and the cost is only one-fifth of the original cost.
With the advantages of massive unique data and industry know-how, FancyTech has won wide recognition at home and abroad through the advantages of vertical model. It has signed contracts with Samsung and LG with Korean partners; it has started cooperation with Lazada, a well-known e-commerce platform in Southeast Asia. ; In the United States, it has been favored by local brands such as Kate Sommerville and Solawave; in Europe, it has won the LVMH Innovation Award and is in-depth cooperation with European customers.
In addition to the core vertical model, FancyTech also provides full-link automatic publishing and data feedback capabilities for AI short videos, driving continued growth in product sales.
What’s more important is that the vertical model visualizes the path for the general public to use AIGC technology to improve productivity. For example, a traditional street photo studio can complete the business transformation from simple portrait shooting to professional-level commercial visual material production without adding professional equipment and professionals with the help of FancyTech's products. 
Now just by picking up a mobile phone, almost everyone can shoot videos, record music, and share their creations with the world. Imagine a future where AIGC once again unleashes personal creativity -
allowing ordinary people to cross professional thresholds and turn ideas into reality more easily, thus allowing the productivity of each industry to leap forward and generate more emerging industries, AIGC From this moment on, the dividends of the times brought by technology begin to truly reach ordinary people.
The above is the detailed content of Leading the commercialization of AIGC with a 'vertical model', what is FancyTech's technical path?. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Technology trends to watch in 2023
- How Artificial Intelligence is Bringing New Everyday Work to Data Center Teams
- Can artificial intelligence or automation solve the problem of low energy efficiency in buildings?
- OpenAI co-founder interviewed by Huang Renxun: GPT-4's reasoning capabilities have not yet reached expectations
- Microsoft's Bing surpasses Google in search traffic thanks to OpenAI technology