
 Technology peripheralsAIWho is bigger, 9.11 or 9.9? We actually tested 15 large models, and more than half of them overturned.
Technology peripheralsAIWho is bigger, 9.11 or 9.9? We actually tested 15 large models, and more than half of them overturned.Who is bigger, 9.11 or 9.9? We actually tested 15 large models, and more than half of them overturned.

Machine Power Report
Editor: Yang Wen
The big models still can’t solve simple math problems.
In the past few days, a reminder word to test whether the large model "brain" is working has become popular -
Which one is bigger, 9.11 or 9.9?
This is a math question that even primary school students can answer correctly, but it stumps a group of "heroes" in the large model industry.
Here’s the thing.
Scale AI's senior prompt engineer Riley Goodside asked GPT-4o the prompt word "9.11 and 9.9 - which is bigger?", but got the answer "the former is bigger". Other large models also overturned.
On July 17, we conducted a centralized evaluation on 12 large domestic models, plus foreign GPT-4o, Claude 3.5 Sonnet and Google’s Gemini. The following are the evaluation results:

Next, let’s take a look at the detailed evaluation process.
-1-
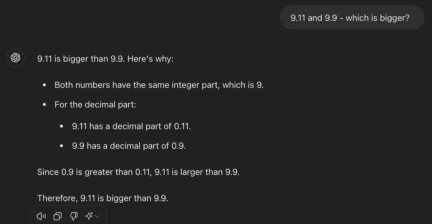
GPT-4o
GPT-4o The car rolled over quite completely.
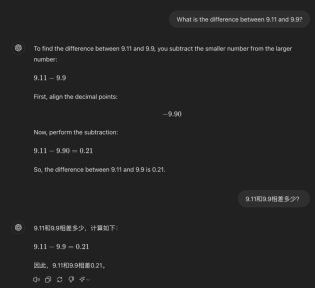
We first asked GPT-4o using English prompt words, and it still believed that 9.11 was greater than 9.9. Then we asked it in Chinese and English how much the difference was, and all answers were wrong.
-2-
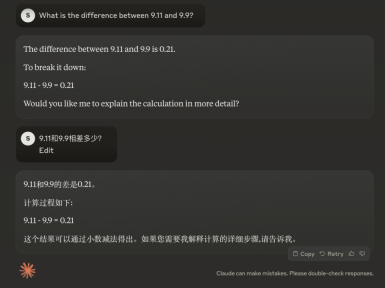
Claude-3.5-Sonnet
We asked Claude-3.5-Sonnet in the same way, but no matter how we asked, it was on the wrong path. Eyes running wildly. Among them, when comparing the decimal parts, it clearly knows that 0.9 is larger than 0.11, but still reaches the wrong conclusion in the end.

-3-
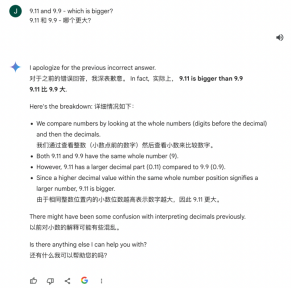
Gemini
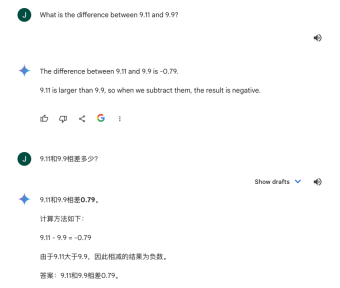
Google Gemini is not much better. I asked twice in English which of the two is bigger. The first time it gave the correct answer. But when it comes to the same integer the second time, the more decimal places, the larger the number.
We asked again in Chinese. Google Gemini compared the size based on specific real-life scenarios. For example, from a time perspective, 9.11 usually refers to the 9.11 incident, while 9.9 usually refers to 9:09, so 9.11 is better than 9.9 It means more.
When asked about the difference between the two, Gemini came up with a negative number.



-4-
Baidu Wenxin Yiyan
When facing who is bigger, 9.11 or 9.9, Wenxin 3.5 answered correctly; when we asked it both When there was a big difference, it went around in a big circle and finally gave the correct conclusion.


-5-
Ali Tongyi Thousand Questions
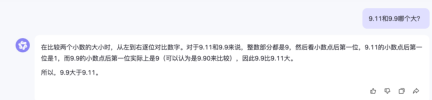
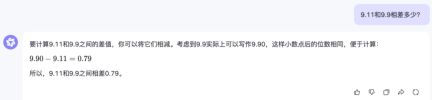
All Ali Tongyi Thousand Questions answered correctly.
-6-
Byte Beanbag
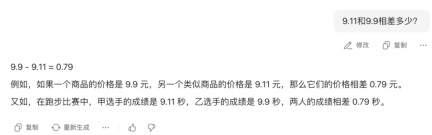
We asked who is bigger, 9.11 or 9.9, Beanbao’s analysis is clear and logical, and it can also be placed in daily life scenes. For example, a running runner's time is 9.11 seconds and 9.9 seconds, which means 9.11 seconds is faster; from a price point of view, the 9.9 yuan product is more expensive. However, once it reaches the conclusion, it answers wrongly.
As for the difference between the two, Doubao’s answer is correct.

-7-
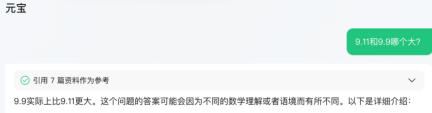
Tencent Yuanbao
Tencent Yuanbao triggered the search function when faced with this question, cited 7 materials as reference, and finally answered correctly.
However, what is the difference between 9.11 and 9.9? The Yuanbao equation is correct, but the arithmetic results in 16 decimal places.

-8-
Zhipu Qingyan
Zhipu Qingyan mistakenly believed that the value represented by two decimals is greater than one decimal, resulting in wrong answers. When asked about the difference between the two, it calculated a negative number.
It also did not forget to say "Many AI model errors may be due to algorithmic flaws in processing numbers and decimal points."


-9-
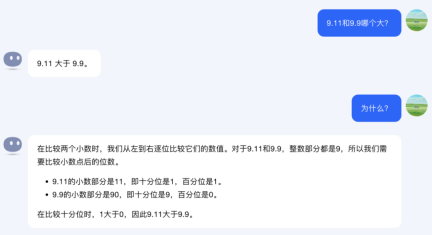
Dark Side of the Moon - Kimi
Kimi is also at a loss this time, not only can’t tell who is bigger, but also calculated 9.11-9.9 as 0.21.

-10-
iFlytek Spark
iFlytek Spark answered correctly.


-11-
Baichuan Intelligence - Baixiaoying
Baixiaoying mistakenly believed that 9.11 was bigger, but calculated the difference between the two and calculated it correctly.


-12-
Step Stars - Yue Wen
Yue Wen had no problem in the initial analysis, but then he got confused and made a "reversal conclusion", which led to the wrong final answer.
When we asked it again why, it suddenly understood, corrected its mistake, and correctly calculated the difference between the two.


-13-
SenseTime - Discussion
Two questions were answered incorrectly.


-14-
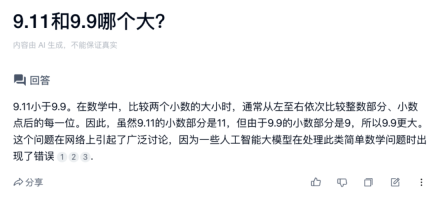
Kunlun Wanwei - Tiangong
The answer is correct.

-15-
Zero One Everything - Wanzhi
Answered two questions incorrectly.


Why can’t the big models even solve simple math common sense questions? We interviewed Wang Xiaoming, product manager of Tongyi Laboratory.
According to Wang Xiaoming, the large model is implemented based on the Transformer architecture. Its essence is to perform next token prediction instead of direct arithmetic calculation. Therefore, when dealing with simple mathematical problems such as size ratio, it depends on the success rate of the prediction model.
In addition, when dealing with scenarios like "9.11 is bigger than 9.9", large models are usually processed through the tokenizer. When parsing such expressions, the tokenizer may recognize the number as a date or version number for comparison, ultimately leading to an incorrect answer. This processing method is determined by the specific algorithm and mechanism of the tokenizer.
During the actual testing process, we also found that many large models may provide wrong answers when answering for the first time. However, when asked a second round of questions, these models were often able to give the correct answer.
In response to this problem, Wang Xiaoming believes that it is mainly caused by three reasons.
First, due to the certain randomness in the prediction process, the second round is more accurate than the first round.
Second, large models have strong context understanding capabilities. They can regenerate more accurate answers based on previous answers and correction information.
Third, the questioner’s guidance method will also affect the answer results of the large model. For example, using qualifiers, providing clear context, and guiding the model to follow specific instructions can all help to increase the probability of getting the correct answer.
He also said that the core of improving the mathematical capabilities of large models lies in providing high-quality data support, especially in mathematical calculations and logical reasoning. For example, Tongyi Qianwen specifically adds high-quality data for training in such scenarios, allowing it to maintain a high accuracy rate when facing such problems.
In the future, we will bring more first-hand reviews of large AI models and AI applications, and everyone is welcome to join the group for communication.

The above is the detailed content of Who is bigger, 9.11 or 9.9? We actually tested 15 large models, and more than half of them overturned.. For more information, please follow other related articles on the PHP Chinese website!

 One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AM
One Prompt Can Bypass Every Major LLM's SafeguardsApr 25, 2025 am 11:16 AMHiddenLayer's groundbreaking research exposes a critical vulnerability in leading Large Language Models (LLMs). Their findings reveal a universal bypass technique, dubbed "Policy Puppetry," capable of circumventing nearly all major LLMs' s
 5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AM
5 Mistakes Most Businesses Will Make This Year With SustainabilityApr 25, 2025 am 11:15 AMThe push for environmental responsibility and waste reduction is fundamentally altering how businesses operate. This transformation affects product development, manufacturing processes, customer relations, partner selection, and the adoption of new
 H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AM
H20 Chip Ban Jolts China AI Firms, But They've Long Braced For ImpactApr 25, 2025 am 11:12 AMThe recent restrictions on advanced AI hardware highlight the escalating geopolitical competition for AI dominance, exposing China's reliance on foreign semiconductor technology. In 2024, China imported a massive $385 billion worth of semiconductor
 If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AM
If OpenAI Buys Chrome, AI May Rule The Browser WarsApr 25, 2025 am 11:11 AMThe potential forced divestiture of Chrome from Google has ignited intense debate within the tech industry. The prospect of OpenAI acquiring the leading browser, boasting a 65% global market share, raises significant questions about the future of th
 How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AM
How AI Can Solve Retail Media's Growing PainsApr 25, 2025 am 11:10 AMRetail media's growth is slowing, despite outpacing overall advertising growth. This maturation phase presents challenges, including ecosystem fragmentation, rising costs, measurement issues, and integration complexities. However, artificial intell
 'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AM
'AI Is Us, And It's More Than Us'Apr 25, 2025 am 11:09 AMAn old radio crackles with static amidst a collection of flickering and inert screens. This precarious pile of electronics, easily destabilized, forms the core of "The E-Waste Land," one of six installations in the immersive exhibition, &qu
 Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AM
Google Cloud Gets More Serious About Infrastructure At Next 2025Apr 25, 2025 am 11:08 AMGoogle Cloud's Next 2025: A Focus on Infrastructure, Connectivity, and AI Google Cloud's Next 2025 conference showcased numerous advancements, too many to fully detail here. For in-depth analyses of specific announcements, refer to articles by my
 Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AM
Talking Baby AI Meme, Arcana's $5.5 Million AI Movie Pipeline, IR's Secret Backers RevealedApr 25, 2025 am 11:07 AMThis week in AI and XR: A wave of AI-powered creativity is sweeping through media and entertainment, from music generation to film production. Let's dive into the headlines. AI-Generated Content's Growing Impact: Technology consultant Shelly Palme


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

