


实例的背景说明
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
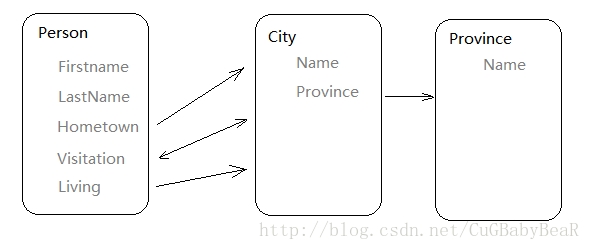
Models.py 内容如下:
from django.db import models class Province(models.Model): name = models.CharField(max_length=10) def __unicode__(self): return self.name class City(models.Model): name = models.CharField(max_length=5) province = models.ForeignKey(Province) def __unicode__(self): return self.name class Person(models.Model): firstname = models.CharField(max_length=10) lastname = models.CharField(max_length=10) visitation = models.ManyToManyField(City, related_name = "visitor") hometown = models.ForeignKey(City, related_name = "birth") living = models.ForeignKey(City, related_name = "citizen") def __unicode__(self): return self.firstname + self.lastname
注1:创建的app名为“QSOptimize”
注2:为了简化起见,`qsoptimize_province` 表中只有2条数据:湖北省和广东省,`qsoptimize_city`表中只有三条数据:武汉市、十堰市和广州市
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。或许你会说,没有一个叫OneToManyField的东西啊。实际上 ,ForeignKey就是一个多对一的字段,而被ForeignKey关联的字段就是一对多字段了。
作用和方法
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。继续以上边的例子进行说明,如果我们要获得张三所有去过的城市,使用prefetch_related()应该是这么做:
>>> zhangs = Person.objects.prefetch_related('visitation').get(firstname=u"张",lastname=u"三")
>>> for city in zhangs.visitation.all() :
... print city
...
上述代码触发的SQL查询如下:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张'); SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`QSOptimize_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表。
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | +----+-----------+----------+-------------+-----------+ 1 row in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 3 rows in set (0.00 sec)
显然张三武汉、广州、十堰都去过。
又或者,我们要获得湖北的所有城市名,可以这样:
>>> hb = Province.objects.prefetch_related('city_set').get(name__iexact=u"湖北省")
>>> for city in hb.city_set.all():
... city.name
...
触发的SQL查询:
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`name` LIKE '湖北省' ; SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` WHERE `QSOptimize_city`.`province_id` IN (1);
得到的表:
+----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | +----+-----------+ 1 row in set (0.00 sec) +----+-----------+-------------+ | id | name | province_id | +----+-----------+-------------+ | 1 | 武汉市 | 1 | | 3 | 十堰市 | 1 | +----+-----------+-------------+ 2 rows in set (0.00 sec)
我们可以看见,prefetch使用的是 IN 语句实现的。这样,在QuerySet中的对象数量过多的时候,根据数据库特性的不同有可能造成性能问题。
使用方法
*lookups 参数
prefetch_related()在Django
>>> zhangs = Person.objects.prefetch_related('visitation__province').filter(firstname__iexact=u'张')
>>> for i in zhangs:
... for city in i.visitation.all():
... print city.province
...
触发的SQL:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person` WHERE `QSOptimize_person`.`firstname` LIKE '张' ; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 4); SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name` FROM `QSOptimize_province` WHERE `QSOptimize_province`.`id` IN (1, 2);
获得的结果:
+----+-----------+----------+-------------+-----------+ | id | firstname | lastname | hometown_id | living_id | +----+-----------+----------+-------------+-----------+ | 1 | 张 | 三 | 3 | 1 | | 4 | 张 | 六 | 2 | 2 | +----+-----------+----------+-------------+-----------+ 2 rows in set (0.00 sec) +-----------------------+----+-----------+-------------+ | _prefetch_related_val | id | name | province_id | +-----------------------+----+-----------+-------------+ | 1 | 1 | 武汉市 | 1 | | 1 | 2 | 广州市 | 2 | | 4 | 2 | 广州市 | 2 | | 1 | 3 | 十堰市 | 1 | +-----------------------+----+-----------+-------------+ 4 rows in set (0.00 sec) +----+-----------+ | id | name | +----+-----------+ | 1 | 湖北省 | | 2 | 广东省 | +----+-----------+ 2 rows in set (0.00 sec)
值得一提的是,链式prefetch_related会将这些查询添加起来,就像1.7中的select_related那样。
要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
举个例子,要获取所有人访问过的城市中带有“市”字的城市,这样做会导致大量的SQL查询:
plist = Person.objects.prefetch_related('visitation')
[p.visitation.filter(name__icontains=u"市") for p in plist]
因为数据库中有4人,导致了2+4次SQL查询:
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id` FROM `QSOptimize_person`; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 2, 3, 4); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE(`QSOptimize_person_visitation`.`person_id` = 1 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 2 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 3 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city` INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`) WHERE (`QSOptimize_person_visitation`.`person_id` = 4 AND `QSOptimize_city`.`name` LIKE '%市%' );
详细分析一下这些请求事件。
众所周知,QuerySet是lazy的,要用的时候才会去访问数据库。运行到第二行Python代码时,for循环将plist看做iterator,这会触发数据库查询。最初的两次SQL查询就是prefetch_related导致的。
虽然已经查询结果中包含所有所需的city的信息,但因为在循环体中对Person.visitation进行了filter操作,这显然改变了数据库请求。因此这些操作会忽略掉之前缓存到的数据,重新进行SQL查询。
但是如果有这样的需求了应该怎么办呢?在Django >= 1.7,可以通过下一节的Prefetch对象来实现,如果你的环境是Django
plist = Person.objects.prefetch_related('visitation')
[[city for city in p.visitation.all() if u"市" in city.name] for p in plist]
Prefetch 对象
在Django >= 1.7,可以用Prefetch对象来控制prefetch_related函数的行为。
注:由于我没有安装1.7版本的Django环境,本节内容是参考Django文档写的,没有进行实际的测试。
Prefetch对象的特征:
- 一个Prefetch对象只能指定一项prefetch操作。
- Prefetch对象对字段指定的方式和prefetch_related中的参数相同,都是通过双下划线连接的字段名完成的。
- 可以通过 queryset 参数手动指定prefetch使用的QuerySet。
- 可以通过 to_attr 参数指定prefetch到的属性名。
- Prefetch对象和字符串形式指定的lookups参数可以混用。
继续上面的例子,获取所有人访问过的城市中带有“武”字和“州”的城市:
wus = City.objects.filter(name__icontains = u"武")
zhous = City.objects.filter(name__icontains = u"州")
plist = Person.objects.prefetch_related(
Prefetch('visitation', queryset = wus, to_attr = "wu_city"),
Prefetch('visitation', queryset = zhous, to_attr = "zhou_city"),)
[p.wu_city for p in plist]
[p.zhou_city for p in plist]
注:这段代码没有在实际环境中测试过,若有不正确的地方请指正。
顺带一提,Prefetch对象和字符串参数可以混用。
None
可以通过传入一个None来清空之前的prefetch_related。就像这样:
>>> prefetch_cleared_qset = qset.prefetch_related(None)
小结
- prefetch_related主要针一对多和多对多关系进行优化。
- prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
- 可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
- 在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
- 作为prefetch_related的参数,Prefetch对象和字符串可以混用。
- prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
- 可以通过传入None来清空之前的prefetch_related。

 What data types can be stored in a Python array?Apr 27, 2025 am 12:11 AM
What data types can be stored in a Python array?Apr 27, 2025 am 12:11 AMPythonlistscanstoreanydatatype,arraymodulearraysstoreonetype,andNumPyarraysarefornumericalcomputations.1)Listsareversatilebutlessmemory-efficient.2)Arraymodulearraysarememory-efficientforhomogeneousdata.3)NumPyarraysareoptimizedforperformanceinscient
 What happens if you try to store a value of the wrong data type in a Python array?Apr 27, 2025 am 12:10 AM
What happens if you try to store a value of the wrong data type in a Python array?Apr 27, 2025 am 12:10 AMWhenyouattempttostoreavalueofthewrongdatatypeinaPythonarray,you'llencounteraTypeError.Thisisduetothearraymodule'sstricttypeenforcement,whichrequiresallelementstobeofthesametypeasspecifiedbythetypecode.Forperformancereasons,arraysaremoreefficientthanl
 Which is part of the Python standard library: lists or arrays?Apr 27, 2025 am 12:03 AM
Which is part of the Python standard library: lists or arrays?Apr 27, 2025 am 12:03 AMPythonlistsarepartofthestandardlibrary,whilearraysarenot.Listsarebuilt-in,versatile,andusedforstoringcollections,whereasarraysareprovidedbythearraymoduleandlesscommonlyusedduetolimitedfunctionality.
 What should you check if the script executes with the wrong Python version?Apr 27, 2025 am 12:01 AM
What should you check if the script executes with the wrong Python version?Apr 27, 2025 am 12:01 AMThescriptisrunningwiththewrongPythonversionduetoincorrectdefaultinterpretersettings.Tofixthis:1)CheckthedefaultPythonversionusingpython--versionorpython3--version.2)Usevirtualenvironmentsbycreatingonewithpython3.9-mvenvmyenv,activatingit,andverifying
 What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AM
What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AMPythonarrayssupportvariousoperations:1)Slicingextractssubsets,2)Appending/Extendingaddselements,3)Insertingplaceselementsatspecificpositions,4)Removingdeleteselements,5)Sorting/Reversingchangesorder,and6)Listcomprehensionscreatenewlistsbasedonexistin
 In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AM
In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AMNumPyarraysareessentialforapplicationsrequiringefficientnumericalcomputationsanddatamanipulation.Theyarecrucialindatascience,machinelearning,physics,engineering,andfinanceduetotheirabilitytohandlelarge-scaledataefficiently.Forexample,infinancialanaly
 When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AM
When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AMUseanarray.arrayoveralistinPythonwhendealingwithhomogeneousdata,performance-criticalcode,orinterfacingwithCcode.1)HomogeneousData:Arrayssavememorywithtypedelements.2)Performance-CriticalCode:Arraysofferbetterperformancefornumericaloperations.3)Interf
 Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AM
Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AMNo,notalllistoperationsaresupportedbyarrays,andviceversa.1)Arraysdonotsupportdynamicoperationslikeappendorinsertwithoutresizing,whichimpactsperformance.2)Listsdonotguaranteeconstanttimecomplexityfordirectaccesslikearraysdo.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver Mac version
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

