


Iconfinder 是一个图标搜索引擎,为设计师、开发者和其他创意工作者提供精美图标,目前托管超过 34 万枚图标,是全球最大的付费图标库。用户也可以在 Iconfinder 的交易板块上传出售原创作品。每个月都有成千上万的图标上传到Iconfinder,同时也伴随而来大量的盗版图。Iconfinder 工程师 Silviu Tantos 在本文中提出一个新颖巧妙的图像查重技术,以杜绝盗版。
我们将在未来几周之内推出一个检测上传图标是否重复的功能。例如,如果用户下载了一个图标然后又试图通过上传它来获利(曾发生过类似案例),那么通过我们的方法,就可以检测出该图标是否已存在,并且标记该账户欺诈。在大量文件中检测某文件是否已经存在的一个常用方法是,通过计算数据集中每一个文件的哈希值,并将该哈希值存储在数组库中。当想要查找某特定文件时,首先计算该文件哈希值,然后在数据库中查找该哈希值。
选择一个哈希算法
加密哈希算法是一个常用的哈希算法。类似MD5,SHA1,SHA256这种在任何一种语言都可以找到可调用的标准库,它们对于简单的用例非常有效。
例如,在Python中先导入hashlib模块,然后调用函数就可以生成某一个字符串或者文件的哈希值。
>>> import hashlib
# Calculating the hash value of a string.
>>> hashlib.md5('The quick brown fox jumps over the lazy dog').hexdigest()
'9e107d9d372bb6826bd81d3542a419d6'
# Loading an image file into memory and calculating it's hash value.
>>> image_file = open('data/cat_grumpy_orig.png').read()
>>> hashlib.md5(image_file).hexdigest()
'3e1f6e9f2689d59b9ed28bcdab73455f'
这个算法对于未被篡改的上传文件非常有效,如果输入数据有细微变化,加密哈希算法都会导致雪崩效应,从而造成新文件的哈希值完全不同于原始文件哈希值。
比如下面这个例子,它在句子的结尾多加了一个句号。
# Original text.
>>> hashlib.md5('The quick brown fox jumps over the lazy dog').hexdigest()
'9e107d9d372bb6826bd81d3542a419d6'
# Slight modification of the text.
>>> hashlib.md5('The quick brown fox jumps over the lazy dog.').hexdigest()
'e4d909c290d0fb1ca068ffaddf22cbd0'
如果图像背景色被改变,图像被裁剪,旋转或者某一个像素被修改,那么都无法在图像哈希库中匹配。可见传统哈希算法并不具有实用性。正如你在上面例子中看到的,哈希值9 e107d9d372bb6826bd81d3542a419d6 和e4d909c290d0fb1ca068ffaddf22cbd0几乎是不同的(除了几个字符)。
例如,修改图像中猫咪鼻子的颜色后,图像的哈希值将改变。

# Load the original image into memory and calculate it's hash value.
>>> image_file = open('data/cat_grumpy_orig.png').read()
>>> hashlib.md5(image_file).hexdigest()
'3e1f6e9f2689d59b9ed28bcdab73455f'
# Load the modified image into memory and calculate it's hash value.
>>> image_file_modified = open('data/cat_grumpy_modif.png').read()
>>> hashlib.md5(image_file_modified).hexdigest()
'12d1b9409c3e8e0361c24beaee9c0ab1'
目前已有许多感知哈希算法,本文将要提出一个新的dhash(差异哈希)算法,该算法计算相邻像素之间的亮度差异并确定相对梯度。对于以上的用例,感知哈希算法将非常有效。感知哈希算法从文件内容的各种特征中获得一个能够灵活分辨不同文件微小区别的多媒体文件指纹。
dHash
深入学习dHash算法前,先介绍一些基础知识。一个彩色图像是由RGB三原色组成,可以看成一个红绿蓝三原色的颜色集。比如利用用Python图像库(PIL)加载一个图像,并打印像素值。

Test image
>>> from PIL import Image
>>> test_image = Image.open('data/test_image.jpg')
# The image is an RGB image with a size of 8x8 pixels.
>>> print 'Image Mode: %s' % test_image.mode
Image Mode: RGB
>>> print 'Width: %s px, Height: %s px' % (test_image.size[0], test_image.size[1])
Width: 4 px, Height: 4 px
# Get the pixel values from the image and print them into rows based on
# the image's width.
>>> width, height = test_image.size
>>> pixels = list(test_image.getdata())
>>> for col in xrange(width):
... print pixels[col:col+width]
...
[(255, 0, 0), (0, 255, 0), (0, 0, 255), (255, 255, 255)]
[(0, 0, 0), (212, 45, 45), (51, 92, 154), (130, 183, 47)]
[(206, 210, 198), (131, 78, 8), (131, 156, 180), (117, 155, 201)]
[(104, 133, 170), (215, 130, 20), (153, 155, 155), (104, 142, 191)]
现在我们回到dHash算法,该算法有四个步骤,本文详细说明每一步并验证它在原始图像和修改后图像的效果。前三个像素的红绿蓝颜色强度值分别为255,其余两个颜色强度值分别为0,纯黑色像素三原色为0,纯白色像素三原色为255。其它颜色像素则是由不同强度三原色值组成的。
1.图像灰度化
通过灰度化图像,将像素值减少到一个发光强度值。例如,白色像素(255、255、255)成为255而黑色像素(0,0,0)强度值将成为0。
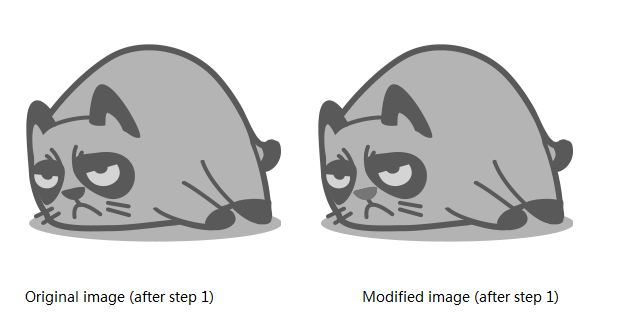
2.将图像缩小到一个常见大小
将图像缩减到一个常见基础尺寸,比如宽度大高度一个像素值的9*8像素大小(到第三步你就能明白为什么是这个尺寸)。通过这个方法将图像中的高频和细节部分移除,从而获得一个有72个强度值的样本。由于调整或者拉伸图像并不会改变它的哈希值,所以将所有图像归一化到该大小。

3.比较邻域像素
前两步实现后得到一个强度值列表,比较该二进制值数组的每一行的相邻像素。
>>> from PIL import Image
>>> img = Image.open('data/cat_grumpy_orig_after_step_2.png')
>>> width, height = img.size
>>> pixels = list(img.getdata())
>>> for col in xrange(width):
... print pixels[col:col+width]
...
[254, 254, 255, 253, 248, 254, 255, 254, 255]
[254, 255, 253, 248, 254, 255, 254, 255, 255]
[253, 248, 254, 255, 254, 255, 255, 255, 222]
[248, 254, 255, 254, 255, 255, 255, 222, 184]
[254, 255, 254, 255, 255, 255, 222, 184, 177]
[255, 254, 255, 255, 255, 222, 184, 177, 184]
[254, 255, 255, 255, 222, 184, 177, 184, 225]
[255, 255, 255, 222, 184, 177, 184, 225, 255]
第一个值254和第二个254做比较,第二个值和第三个值比,以此类推,从而每行得到8个布尔值。
>>> difference = [] >>> for row in xrange(height): ... for col in xrange(width): ... if col != width: ... difference.append(pixels[col+row] > pixels[(col+row)+1]) ... >>> for col in xrange(width-1): ... print difference[col:col+(width-1)] ... [False, False, True, True, False, False, True, False] [False, True, True, False, False, True, False, False] [True, True, False, False, True, False, False, False] [True, False, False, True, False, False, False, True] [False, False, True, False, False, False, True, True] [False, True, False, False, False, True, True, False] [True, False, False, False, True, True, False, False] [False, False, False, True, True, False, False, True]
4.转换为二值
为了方便哈希值存储和使用,将8个布尔值转换为16进制字符串。Ture变成1,而False变成0。
Python实现
下面是完整Python实现的完成算法:
def dhash(image, hash_size = 8):
# Grayscale and shrink the image in one step.
image = image.convert('L').resize(
(hash_size + 1, hash_size),
Image.ANTIALIAS,
)
pixels = list(image.getdata())
# Compare adjacent pixels.
difference = []
for row in xrange(hash_size):
for col in xrange(hash_size):
pixel_left = image.getpixel((col, row))
pixel_right = image.getpixel((col + 1, row))
difference.append(pixel_left > pixel_right)
# Convert the binary array to a hexadecimal string.
decimal_value = 0
hex_string = []
for index, value in enumerate(difference):
if value:
decimal_value += 2**(index % 8)
if (index % 8) == 7:
hex_string.append(hex(decimal_value)[2:].rjust(2, '0'))
decimal_value = 0
return ''.join(hex_string)
最常见情况,图片稍有不同,哈希值很可能是相同的,所以我们可以直接比较。
>>> from PIL import Image
>>> from utility import dhash, hamming_distance
>>> orig = Image.open('data/cat_grumpy_orig.png')
>>> modif = Image.open('data/cat_grumpy_modif.png')
>>> dhash(orig)
'4c8e3366c275650f'
>>> dhash(modif)
'4c8e3366c275650f'
>>> dhash(orig) == dhash(modif)
True
如果有一
个保存哈希值的SQL数据库, 可以这样简单判断哈希值“4 c8e3366c275650f ”是否存在:
SELECT pk, hash, file_path FROM image_hashes WHERE hash = '4c8e3366c275650f';
现在,对于一些有较大差别的图像,它们的哈希值可能是不相同的,那么需要计算由一个字符串变成另一个字符串所需替换的最少字符数,即汉明距离。
维基百科上有一些计算两个字符串之间的汉明距离的Python示例代码。但是也可以直接基于MySQL数据库上的计算和查询来实现。
SELECT pk, hash, BIT_COUNT(
CONV(hash, 16, 10) ^ CONV('4c8e3366c275650f', 16, 10)
) as hamming_distance
FROM image_hashes
HAVING hamming_distance < 4
ORDER BY hamming_distance ASC;
对所查询的值与数据库中的哈希值进行异或操作,计数不同位数。由于BIT_COUNT只能操作整数,所以要将所有十六进制的哈希值转成十进制。
结束语
本文使用Python实现了所介绍的算法,当然了读者可以使用任何编程语言实现算法。
在简介中提过,本文算法将应用到Iconfinder上去防止重复提交图标,可以预想,感知哈希算法还有更多实际应用。因为有相似特征的图像的哈希值也是相似的,所以它可以帮助图像推荐系统寻找相似图像。

 What data types can be stored in a Python array?Apr 27, 2025 am 12:11 AM
What data types can be stored in a Python array?Apr 27, 2025 am 12:11 AMPythonlistscanstoreanydatatype,arraymodulearraysstoreonetype,andNumPyarraysarefornumericalcomputations.1)Listsareversatilebutlessmemory-efficient.2)Arraymodulearraysarememory-efficientforhomogeneousdata.3)NumPyarraysareoptimizedforperformanceinscient
 What happens if you try to store a value of the wrong data type in a Python array?Apr 27, 2025 am 12:10 AM
What happens if you try to store a value of the wrong data type in a Python array?Apr 27, 2025 am 12:10 AMWhenyouattempttostoreavalueofthewrongdatatypeinaPythonarray,you'llencounteraTypeError.Thisisduetothearraymodule'sstricttypeenforcement,whichrequiresallelementstobeofthesametypeasspecifiedbythetypecode.Forperformancereasons,arraysaremoreefficientthanl
 Which is part of the Python standard library: lists or arrays?Apr 27, 2025 am 12:03 AM
Which is part of the Python standard library: lists or arrays?Apr 27, 2025 am 12:03 AMPythonlistsarepartofthestandardlibrary,whilearraysarenot.Listsarebuilt-in,versatile,andusedforstoringcollections,whereasarraysareprovidedbythearraymoduleandlesscommonlyusedduetolimitedfunctionality.
 What should you check if the script executes with the wrong Python version?Apr 27, 2025 am 12:01 AM
What should you check if the script executes with the wrong Python version?Apr 27, 2025 am 12:01 AMThescriptisrunningwiththewrongPythonversionduetoincorrectdefaultinterpretersettings.Tofixthis:1)CheckthedefaultPythonversionusingpython--versionorpython3--version.2)Usevirtualenvironmentsbycreatingonewithpython3.9-mvenvmyenv,activatingit,andverifying
 What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AM
What are some common operations that can be performed on Python arrays?Apr 26, 2025 am 12:22 AMPythonarrayssupportvariousoperations:1)Slicingextractssubsets,2)Appending/Extendingaddselements,3)Insertingplaceselementsatspecificpositions,4)Removingdeleteselements,5)Sorting/Reversingchangesorder,and6)Listcomprehensionscreatenewlistsbasedonexistin
 In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AM
In what types of applications are NumPy arrays commonly used?Apr 26, 2025 am 12:13 AMNumPyarraysareessentialforapplicationsrequiringefficientnumericalcomputationsanddatamanipulation.Theyarecrucialindatascience,machinelearning,physics,engineering,andfinanceduetotheirabilitytohandlelarge-scaledataefficiently.Forexample,infinancialanaly
 When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AM
When would you choose to use an array over a list in Python?Apr 26, 2025 am 12:12 AMUseanarray.arrayoveralistinPythonwhendealingwithhomogeneousdata,performance-criticalcode,orinterfacingwithCcode.1)HomogeneousData:Arrayssavememorywithtypedelements.2)Performance-CriticalCode:Arraysofferbetterperformancefornumericaloperations.3)Interf
 Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AM
Are all list operations supported by arrays, and vice versa? Why or why not?Apr 26, 2025 am 12:05 AMNo,notalllistoperationsaresupportedbyarrays,andviceversa.1)Arraysdonotsupportdynamicoperationslikeappendorinsertwithoutresizing,whichimpactsperformance.2)Listsdonotguaranteeconstanttimecomplexityfordirectaccesslikearraysdo.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

