
Heim >Technologie-Peripheriegeräte >KI >Können Online-Karten noch so sein? MapTracker: Nutzen Sie Tracking, um das neue SOTA von Online-Karten zu realisieren!
Können Online-Karten noch so sein? MapTracker: Nutzen Sie Tracking, um das neue SOTA von Online-Karten zu realisieren!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-25 17:01:171165Durchsuche
Vorab geschrieben und nach persönlichem Verständnis des Autors
Dieser Algorithmus ermöglicht eine hochpräzise Online-Kartenerstellung. Unsere Methode, MapTracker, sammelt Sensorströme in Speicherpuffern von zwei Displays: 1) Rasterlatenten im BEV-Raum (Bird's Eye View) und 2) Vektorlatenten auf Straßenelementen (d. h. Zebrastreifen, Fahrspurlinien und Straßengrenzen). Die Methode stützt sich auf das Abfrageausbreitungsparadigma bei der Objektverfolgung, das die verfolgten Straßenelemente des vorherigen Frames explizit mit dem aktuellen Frame verknüpft und gleichzeitig eine Teilmenge von Speicherlatenzen mit Distanzschritten verschmilzt, um
Open-Source-Link zu erreichen: https ://map-tracker.github.io/
Zusammenfassend sind die Hauptbeiträge dieses Artikels wie folgt:
- Ein neuer Vektor-HD-Mapping-Algorithmus, der HD-Mapping als Tracking-Aufgabe formuliert und den Speicherverlauf ausnutzt Latente in beiden Darstellungen, um zeitliche Konsistenz zu erreichen
- Ein verbesserter Vektor-HD-Mapping-Benchmark mit zeitkonsistenter GT und konsistenzbewusster
- SOTA-Leistung! Erhebliche Verbesserungen gegenüber den derzeit besten Methoden für traditionelle und neue Metriken.
Überprüfung verwandter Arbeiten
Dieses Papier verwendet zwei Möglichkeiten, um über das konsistente Vektor-HD-Mapping-Problem nachzudenken und es zu lösen. Wir besprechen zunächst die neuesten Trends bei der visuellen Objektverfolgung mithilfe von Transformer- und Speicherdesigns beim visionsbasierten autonomen Fahren. Abschließend diskutieren wir konkurrierende Vektor-HD-Mapping-Methoden.
Verwenden Sie Transformatoren zur visuellen Objektverfolgung. Die visuelle Objektverfolgung hat eine lange Geschichte, wobei End-to-End-Transformer-Methoden aufgrund ihrer Einfachheit zu einem aktuellen Trend geworden sind. TrackFormer, TransTrack und MOTR nutzen Aufmerksamkeitsmechanismen und Tracking-Abfragen, um Instanzen über Frames hinweg explizit zu korrelieren. MeMOT und MeMOTR erweitern den Tracking-Transformator zusätzlich um einen Speichermechanismus für eine bessere Langzeitkonsistenz. In diesem Artikel wird die Vektor-HD-Zuordnung als Tracking-Aufgabe formuliert, indem Tracking-Abfragen mit einem robusteren Speichermechanismus kombiniert werden.
Speicherdesign beim autonomen Fahren. Autonome Fahrsysteme mit einem Einzelbild haben Schwierigkeiten, mit Verdeckungen, Sensorausfällen oder komplexen Umgebungen umzugehen. Eine vielversprechende Ergänzung bietet die zeitliche Modellierung mit Memory. Es gibt viele Speicherdesigns zum Grating von BEV-Funktionen, die die Grundlage für die meisten autonomen Fahraufgaben bilden. BEVDet4D und BEVFormerv2 überlagern die Merkmale mehrerer vergangener Frames im Speicher, die Berechnung wächst jedoch linear mit der Verlaufslänge, was die Erfassung langfristiger Informationen erschwert. VideoBEV verbreitet BEV-Rasterabfragen über Frames hinweg, um Informationen in einer Schleife zu sammeln. Im Vektorbereich verwendet Sparse4Dv2 einen ähnlichen Speicher im RNN-Stil für Zielabfragen, während Sparse4Dv3 darüber hinaus zeitliche Rauschunterdrückung für robustes zeitliches Lernen verwendet. Diese Ideen wurden teilweise in Vektor-HD-Mapping-Methoden integriert. In diesem Artikel wird ein neues Speicherdesign für die Gitter-BEV-Latenz und Vektorlatenz von Straßenelementen vorgeschlagen.
Vektor-HD-Mapping. Traditionell werden hochpräzise Karten offline mit SLAM-basierten Methoden rekonstruiert und anschließend manuell verwaltet, was einen hohen Wartungsaufwand erfordert. Mit der Verbesserung der Genauigkeit und Effizienz haben hochpräzise Online-Vektorkartenalgorithmen mehr Aufmerksamkeit auf sich gezogen als Offline-Kartenalgorithmen, die den Produktionsprozess vereinfachen und Kartenänderungen bewältigen. HDMapNet wandelt Rasterbildsegmentierungen durch Nachbearbeitung in Vektorbildinstanzen um und etablierte den ersten Vektor-HD-Mapping-Benchmark. Sowohl VectorMapNet als auch MapTR nutzen DETR-basierte Transformatoren für eine End-to-End-Vorhersage. Ersteres sagt die Scheitelpunkte jeder erkannten Kurve autoregressiv voraus, während letzteres hierarchische Abfragen und Matching-Verluste verwendet, um alle Scheitelpunkte gleichzeitig vorherzusagen. MapTRv2 ergänzt MapTR zusätzlich durch Hilfsaufgaben und Netzwerkmodifikationen. Kurvendarstellung, Netzwerkdesign und Trainingsparadigmen stehen im Mittelpunkt weiterer Arbeiten. StreamMapNet macht einen Schritt in Richtung einer konsistenten Zuordnung, indem es auf die Flow-Idee in der BEV-Wahrnehmung zurückgreift. Die Idee besteht darin, vergangene Informationen in Gedächtnislatenzen zu sammeln und sie als Bedingungen (d. h. als Zustandserkennungsrahmen) zu übergeben. SQD MapNet imitiert DN-DETR und schlägt die Entrauschung zeitlicher Kurven vor, um das zeitliche Lernen zu fördern.
MapTracker
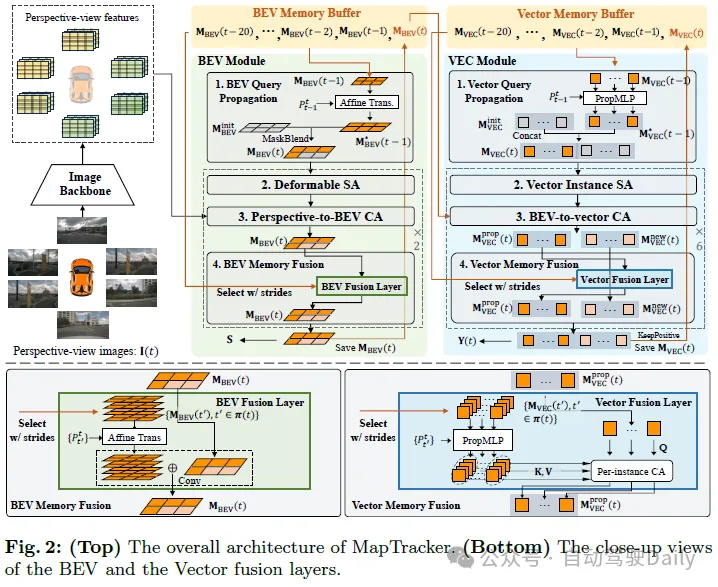
Der robuste Speichermechanismus ist der Kern von MapTracker, der Sensorströme in latenten Speichern sammelt, die durch zwei Darstellungen dargestellt werden: 1) Eine Vogelperspektive von oben nach unten auf den Bereich um das Fahrzeug herum BEV-Koordinatensystemspeicher (BEV) als latentes Bild und 2) Vektorspeicher (VEC) von Straßenelementen (d. h. Fußgängerkreuzungen, Fahrspurlinien und Straßengrenzen) als Satz latenter Größen.
Zwei einfache Ideen und der Speichermechanismus sorgen für eine konsistente Zuordnung. Die erste Idee besteht darin, einen historischen Speicherpuffer anstelle eines einzelnen Speichers für den aktuellen Frame zu verwenden. Ein einziger Speicher sollte Informationen für den gesamten Verlauf enthalten, es kann jedoch leicht passieren, dass der Speicher verloren geht, insbesondere in unübersichtlichen Umgebungen mit einer großen Anzahl von Fahrzeugen, die Straßenstrukturen blockieren. Aus Effizienz- und Abdeckungsgründen wählen wir insbesondere eine Teilmenge vergangener latenter Erinnerungen zur Fusion in jedem Frame basierend auf der Fahrzeugbewegung aus. Die zweite Idee besteht darin, Online-HD-Karten als Tracking-Aufgaben zu formulieren. Der VEC-Speichermechanismus verwaltet die Reihenfolge der Speicherlatenzen für jedes Straßenelement und vereinfacht diese Formulierung, indem er das Abfrageausbreitungsparadigma aus der Tracking-Literatur übernimmt. Der Rest dieses Abschnitts erklärt unsere neuronale Architektur (siehe Abbildungen 2 und 3), einschließlich BEV- und VEC-Speicherpuffer und ihrer entsprechenden Netzwerkmodule, und stellt dann die Trainingsdetails vor.
Speicherpuffer
BEV-Speicher ist ein 2D-Latent im BEV-Koordinatensystem, zentriert auf das Fahrzeug und ausgerichtet auf den t-ten Rahmen. Die räumliche Dimension (also 50×100) umfasst eine rechteckige Fläche, 15m links/rechts und 30m vorne/hinten. Jede Speicherlatenz akkumuliert die gesamten vergangenen Informationen, und der Puffer behält diese Speicherlatenz in den letzten 20 Frames bei, wodurch der Speichermechanismus redundant, aber robust ist.
VECmemory ist eine Reihe von Vektorlatenzzeiten. Jede Vektorlatenzzeit sammelt Informationen über aktive Straßenelemente bis zum Frame t. Die Anzahl der aktiven Elemente ändert sich von Rahmen zu Rahmen. Der Puffer enthält die latenten Vektoren der letzten 20 Frames und ihre Entsprechung zwischen Frames (d. h. die latente Folge von Vektoren, die demselben Straßenelement entsprechen).
BEV-Modul

Die Eingaben sind 1) CNN-Merkmale des luftgestützten Surround-Bildes und seiner vom Bild-Backbone verarbeiteten Kameraparameter; 2) BEV-Speicherpuffer und 3) Fahrzeugbewegung. Im Folgenden werden die vier Komponenten der BEV-Modularchitektur und ihre Ergebnisse erläutert.
- BEV-Abfrageweitergabe: Der BEV-Speicher ist ein latentes 2D-Bild im Fahrzeugkoordinatensystem. Affine Transformation und bilineare Interpolation initialisieren den aktuellen BEV-Speicher mit dem vorherigen BEV-Speicher. Für Pixel, die sich nach der Transformation außerhalb des latenten Bildes befinden, wird der lernbare Einbettungsvektor jedes Pixels initialisiert und seine Operation wird in Abbildung 3 als „MaskBlend“ dargestellt.
- Verformbare Selbstaufmerksamkeit: Die verformbare Selbstaufmerksamkeitsschicht bereichert das BEV-Gedächtnis.
- Perspektiv-zu-BEV-Cross-Attention: Ähnlich wie StreamMapNet fügt die räumlich verformbare Cross-Attention-Schicht von BEVFormer Perspektiveninformationen in MBEV(t) ein.
- BEV-Gedächtnisfusion: Die Speicherlatenten im Puffer werden fusioniert, um MBEV(t) anzureichern. Die Nutzung aller Speicher ist rechenintensiv und überflüssig.
Die Ausgabe ist 1) der endgültige Speicher-MBEV(t), der im Puffer gespeichert und an das VEC-Modul übergeben wird, und 2) die gerasterte Straßenelementgeometrie S(t), die vom Segmentierungskopf abgeleitet und für Verlustberechnungen verwendet wird. Der Segmentierungskopf ist ein lineares Projektionsmodul, das jedes Pixel im latenten Speicher auf eine 2×2-Segmentierungsmaske projiziert, was zu einer 100×200-Maske führt.
VEC-Modul
Die Eingabe ist BEV-Speicher MBEV(t) und Vektorspeicherpuffer und Fahrzeugbewegung.
- Vektorabfrageausbreitung: Der Vektorspeicher ist ein Satz potenzieller Vektoren aktiver Straßenelemente.
- Vector Instance Self Attention: Standard-Selbstaufmerksamkeitsschicht;
- BEV-to-Vector Cross Attention: Mehrpunktaufmerksamkeit;
- Vector Memory Fusion: Für jeden potenziellen Vektor im aktuellen Speicher MVEC(t), zugeordnete latente Vektoren mit den gleichen Straßenelementen im Puffer werden fusioniert, um ihre Darstellung zu bereichern. Die gleiche Stride-Frame-Auswahl wählt vier potenzielle Vektoren aus, wobei für einige Straßenelemente mit kurzer Tracking-Historie die ausgewählten Frames π(t) unterschiedlich und kleiner sein werden. Beispielsweise verfügt ein über zwei Frames verfolgtes Element nur über zwei Latentdaten im Puffer.
Die Ausgabe ist 1) die endgültige Erinnerung an „positive“ Straßenelemente, die durch Klassifizierung aus einer einzelnen vollständig verbundenen Schicht aus MVEC(t) getestet wurden, und 2) durch eine Regression durch ein 3-schichtiges MLP aus der MVEC(t)-Vektorstraßengeometrie mit positiven Straßenelementen.
Training
BEV-Verlust:
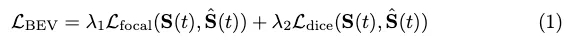
VEC-Verlust. Inspiriert von MOTR, einem End-to-End-Transformator für die Verfolgung mehrerer Objekte, erweitern wir den Matching-basierten Verlust, um die GT-Verfolgung explizit zu berücksichtigen. Die optimale Labelzuweisung auf Instanzebene für neue Elemente ist definiert als:
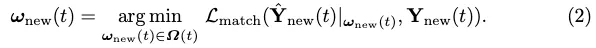
Dann wird die Labelzuweisung ω(t) zwischen allen Ausgaben und GT induktiv definiert:
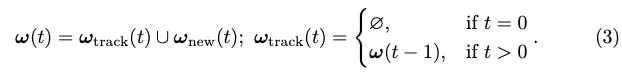
Der Tracking-Stilverlust für die Vektorausgabe ist:
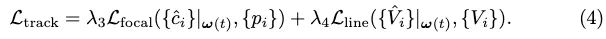
Conversion-Verlust. Wir leihen uns den Transformationsverlust Ltrans von StreamMapNet aus, um PropMLP zu trainieren, der Abfragetransformationen im latenten Raum erzwingt, um Vektorgeometrie und Klassentypen beizubehalten. Der endgültige Trainingsverlust ist:
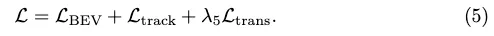
Konsistente Vektor-HD-Mapping-Benchmarks
Konsistente Grundwahrheit
MapTR hat Vektor-HD-Mapping-Benchmarks aus nuScenes- und Agroverse2-Datensätzen erstellt, die von vielen nachfolgenden Studien übernommen wurden. Zebrastreifen werden jedoch auf naive Weise miteinander verschmolzen und sind über die einzelnen Frames hinweg inkonsistent. Die Trennlinie steht auch im Widerspruch zum Scheitern des Graph-Tracking-Prozesses (für Argoverse2).
StreamMapNet erbt den Code von VectorMapNet und erstellt einen Benchmark mit besserem Realismus, der in der Workshop-Challenge verwendet wurde. Es bleiben jedoch einige Probleme bestehen. Bei Argoverse2 werden Teiler manchmal in kürzere Segmente aufgeteilt. Bei nuScenes segmentieren große Zebrastreifen manchmal kleine Schleifen, deren Inkonsistenzen in jedem Frame zufällig auftreten, was zu vorübergehend inkonsistenten Darstellungen führt. Im Anhang stellen wir Visualisierungen bestehender Benchmark-Probleme zur Verfügung.
Wir haben den Verarbeitungscode der bestehenden Basislinie verbessert, um (1) die GT-Geometrie jedes Frames zu verbessern und dann (2) ihre Entsprechung zwischen Frames zu berechnen, um eine GT-„Trajektorie“ zu bilden.
(1) Verbessern Sie jede Rahmengeometrie. Wir haben die in der Community beliebte MapTR-Codebasis übernommen und verbessert und gleichzeitig zwei Änderungen vorgenommen: Wir haben die Verarbeitung von Laufflächen durch die Verarbeitung in StreamMapNet ersetzt und die Qualität durch mehr geometrische Einschränkungen verbessert Teilerverarbeitung (nur Argoverse2).
(2) Spuren bilden. Angesichts der Geometrie der Straßenelemente in jedem Rahmen lösen wir das optimale bipartite Matching-Problem zwischen jedem Paar benachbarter Rahmen, um die Entsprechung zwischen Straßenelementen herzustellen. Korrespondenzpaare werden verknüpft, um Trajektorien von Straßenelementen zu bilden. Der Übereinstimmungswert zwischen einem Paar von Straßenelementen wird wie folgt definiert. Die Straßenelementgeometrie ist eine polygonale Kurve oder Schleife. Wir konvertieren die Elementgeometrie vom alten Rahmen in den neuen Rahmen basierend auf der Fahrzeugbewegung und rastern dann zwei Kurven/Schleifen mit einer bestimmten Dicke in Instanzmasken. Ihr Schnittpunkt auf der Vereinigung ist der Matching-Score.
Konsistenzbewusste mAP-Metrik
mAP-Metrik bestraft keine vorübergehend inkonsistenten Rekonstruktionen. Wir gleichen die rekonstruierten Straßenelemente und die Bodenwahrheit in jedem Frame unabhängig mit Fasenabständen ab, wie im Standard-mAP-Verfahren, und beseitigen dann vorübergehend inkonsistente Übereinstimmungen durch die folgenden Prüfungen. Erstens verwenden wir für die Basismethode, die keine Tracking-Informationen vorhersagt, denselben Algorithmus, der zum Erhalten der zeitlichen GT-Korrespondenz verwendet wird, um Trajektorien rekonstruierter Straßenelemente zu bilden (wir erweitern den Algorithmus auch, um fehlende Elemente durch Abwägen der Geschwindigkeit neu zu identifizieren; siehe für Einzelheiten im Anhang). Als nächstes seien die „Vorfahren“ die Straßenelemente, die zur gleichen Trajektorie im vorherigen Frame gehören. Vom Beginn der Sequenz an entfernen wir jede Frame-Übereinstimmung (rekonstruiertes Element und Ground-Truth-Element) als vorübergehend inkonsistent, wenn einer ihrer Vorgänger nicht übereinstimmt. Die verbleibenden zeitlich konsistenten Übereinstimmungen werden dann zur Berechnung des Standard-mAP verwendet.
Experimente
Wir haben unser System auf Basis der StreamMapNet-Codebasis aufgebaut und dabei unser Modell auf nuScenes für 72 Epochen und Argoverse2 für 35 Epochen mit 8 NVIDIA RTX A5000 GPUs trainiert. Die Chargengrößen für die drei Trainingsstufen betragen jeweils 16, 48 und 16. Das Training dauert etwa drei Tage und die Inferenzgeschwindigkeit beträgt etwa 10 FPS. Nach der Erläuterung des Datensatzes, der Metriken und der Basismethoden liefert dieser Abschnitt experimentelle Ergebnisse.
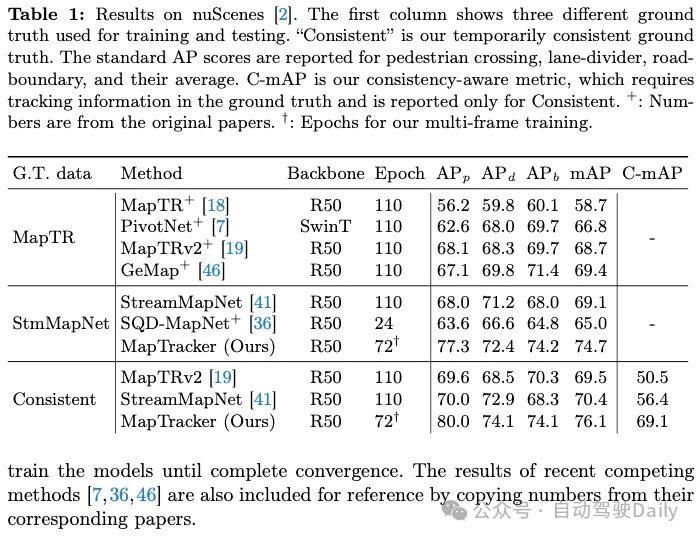
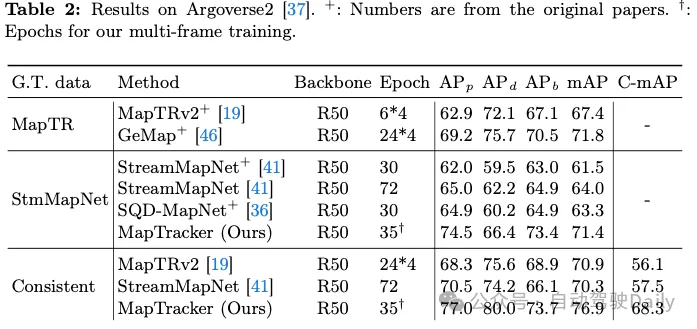
Einer unserer Beiträge besteht darin, eine zeitlich konsistente Grundwahrheit (GT) auf zwei vorhandenen Gegenstücken zu erreichen, nämlich MapTR und StreamMapNet. Die Tabellen 1 und 2 zeigen die Ergebnisse des Trainings und Testens des Systems an einem der drei GTs (in der ersten Spalte dargestellt). Da unsere Codebasis auf StreamMapNet basiert, evaluieren wir unser System auf StreamMapNet GT und unserem Ad-hoc-konsistenten GT.
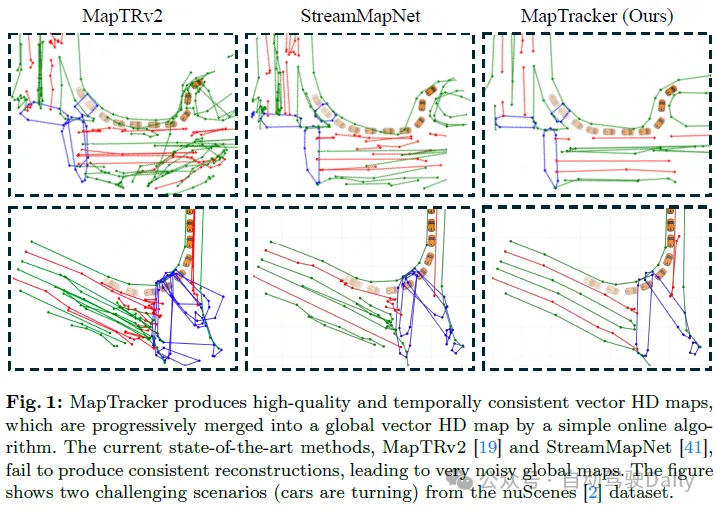
nuScenes-Ergebnisse. Tabelle 1 zeigt, dass sowohl MapTRv2 als auch StreamMapNet mit unserem GT einen besseren mAP erzielen, was wir erwarten würden, wenn wir die Inkonsistenz in ihrem ursprünglichen GT beheben würden. Die Verbesserung von StreamMapNet ist etwas höher, da es über eine zeitliche Modellierung verfügt (im Gegensatz zu MapTR) und die zeitliche Konsistenz der Daten ausnutzt. MapTracker übertrifft konkurrierende Methoden deutlich, insbesondere da sich unsere konsistente GT bei den rohen und konsistenzbewussten mAP-Scores um mehr als 8 % bzw. 22 % verbessert. Beachten Sie, dass MapTracker das einzige System ist, das explizite Tracking-Informationen erzeugt (d. h. die Korrespondenz von Elementen zwischen Frames rekonstruiert), die für die Konsistenzregion-MAP erforderlich sind. Ein einfacher Matching-Algorithmus erstellt Trajektorien für die Basislinienmethode.
Argoverse2 Ergebnisse. Tabelle 2 zeigt, dass sowohl MapTRv2 als auch StreamMapNet mit unserer konsistenten GT bessere mAP-Werte erzielen, die nicht nur zeitlich konsistent ist, sondern auch eine höhere GT-Qualität (für Zebrastreifen und Trennwände) aufweist, was allen Methoden zugute kommt. MapTracker übertrifft alle anderen Baselines in allen Einstellungen deutlich (d. h. 11 % bzw. 8 %). Der Consistency Awareness Score (C-mAP) ist ein weiterer Beleg für unsere überlegene Konsistenz und hat sich im Vergleich zu StreamMapNet um über 18 % verbessert.
Ergebnisse mit geografisch nicht überlappenden Daten
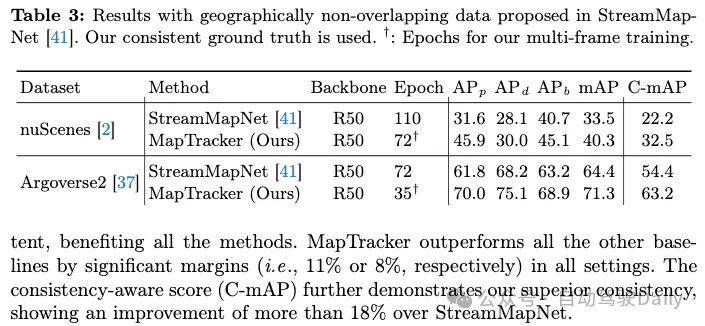
Die offizielle Zug-/Testaufteilung von nuScenes- und Agroverse2-Datensätzen weist geografische Überschneidungen auf (d. h. dieselben Straßen erscheinen im Zug/Test), was eine Überanpassung ermöglicht. Tabelle 3 vergleicht die besten von StreamMapNet und MapTracker vorgeschlagenen Basismethoden basierend auf einer geografisch nicht überlappenden Segmentierung. MapTracker schneidet durchweg deutlich gut ab und demonstriert starke szenarioübergreifende Generalisierungsfähigkeiten. Beachten Sie, dass die Leistung bei nuScenes-Datensätzen bei beiden Methoden verringert wird. Nach sorgfältiger Prüfung ist die Erkennung von Straßenelementen erfolgreich, die Koordinatenfehler der Regression sind jedoch groß, was zu einer schlechten Leistung führt. Der Anhang enthält zusätzliche Analysen.
Ablationsstudien
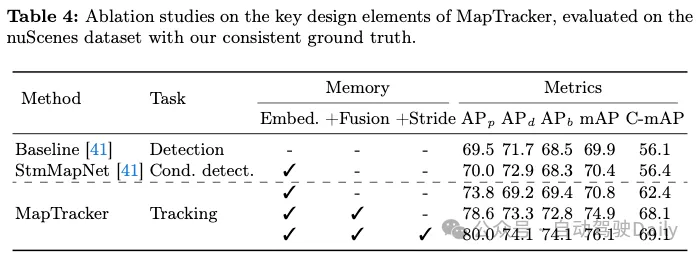
Ablationsstudien in Tabelle 4 zeigen den Beitrag wichtiger Designelemente in MapTracker. Der erste „Basis“-Eintrag ist StreamMapNet, das über keine zeitlichen Inferenzfunktionen verfügt (d. h. keinen BEV- und Vektorflussspeicher und keine Module). Der zweite Eintrag ist StreamMapNet. Beide Methoden wurden über 110 Epochen bis zur vollständigen Konvergenz trainiert. Die letzten drei Einträge sind Variationen von MapTracker, mit oder ohne wichtige Designelemente. Die erste Variante verwirft die Speicherfusionskomponente im BEV/VEC-Modul. Diese Variante verwendet Tracking-Formeln, ist jedoch auf einen einzelnen BEV/VEC-Speicher angewiesen, um vergangene Informationen zu speichern. Die zweite Variante fügt einen Speicherpuffer und eine Speicherfusionskomponente hinzu, jedoch ohne Schrittweite, d. h. es werden die letzten 4 Frames für die Fusion verwendet. Diese Variante verbessert die Leistung und demonstriert die Wirksamkeit unseres Speichermechanismus. Die letzte Variante fügt Speicherschritte hinzu, wodurch der Speichermechanismus effizienter genutzt und die Leistung verbessert wird.
Qualitative Auswertungen

Abbildung 4 zeigt den qualitativen Vergleich von MapTracker und Baseline-Methoden für nuScenes- und Argoverse2-Datensätze. Zur besseren Visualisierung verwenden wir einen einfachen Algorithmus, um jede Frame-Vektor-HD-Karte zu einer globalen Vektor-HD-Karte zusammenzuführen. Einzelheiten zum Zusammenführungsalgorithmus und zur Visualisierung jeder Frame-Rekonstruktion finden Sie im Anhang. MapTracker lieferte genauere und sauberere Ergebnisse und zeigte eine überlegene Gesamtqualität und zeitliche Konsistenz. In Szenarien, in denen das Fahrzeug abbiegt oder sich nicht leicht vorwärts bewegt (einschließlich der beiden Beispiele in Abbildung 1), können StreamMapNet und MapTRv2 instabile Ergebnisse liefern, was zu fehlerhaften und verrauschten zusammengeführten Ergebnissen führt. Dies liegt vor allem daran, dass erkennungsbasierte Formulierungen Schwierigkeiten haben, bei komplexen Fahrzeugbewegungen eine zeitlich kohärente Rekonstruktion aufrechtzuerhalten.
Fazit
In diesem Artikel wird MapTracker vorgestellt, der die Online-HD-Kartierung als Tracking-Aufgabe formuliert und den Verlauf von Raster- und Vektorlatenzen nutzt, um die zeitliche Konsistenz aufrechtzuerhalten. Wir verwenden einen Abfrageausbreitungsmechanismus, um verfolgte Straßenelemente über Frames hinweg zuzuordnen und eine ausgewählte Teilmenge von Speichereinträgen mit Entfernungsschritten zu verschmelzen, um die Konsistenz zu verbessern. Wir verbessern auch bestehende Baselines, indem wir mithilfe von Tracking-Labels konsistente GTs generieren und die rohe mAP-Metrik durch Timing-Konsistenzprüfungen verbessern. MapTracker übertrifft bestehende Methoden für nuScenes- und Agroverse2-Datensätze deutlich, wenn es mit herkömmlichen Metriken ausgewertet wird, und zeigt eine überlegene zeitliche Konsistenz, wenn es mit unseren konsistenzbewussten Metriken ausgewertet wird.
Einschränkungen: Wir haben zwei Einschränkungen von MapTracker festgestellt. Erstens unterstützt die aktuelle Tracking-Formulierung nicht das Zusammenführen und Teilen von Straßenelementen (z. B. wird eine U-förmige Grenze in zukünftigen Frames in zwei gerade Linien aufgeteilt und umgekehrt). Auch grundlegende Fakten stellen sie nicht angemessen dar. Zweitens liegt unser System immer noch bei 10 FPS und die Echtzeitleistung lässt etwas zu wünschen übrig, insbesondere bei kritischen Absturzereignissen. Die Optimierung der Effizienz und der Umgang mit komplexeren realen Straßenstrukturen sind unsere zukünftigen Aufgaben.
Das obige ist der detaillierte Inhalt vonKönnen Online-Karten noch so sein? MapTracker: Nutzen Sie Tracking, um das neue SOTA von Online-Karten zu realisieren!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So überprüfen Sie, wie das Git-Passwort lautet
- So löschen Sie einen Zweig in Git
- So machen Sie einen Git-Commit rückgängig
- Wie installiere ich Git auf einem Mac? Ausführliche Erläuterung zweier Methoden
- Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!