Snowflake schließt sich dem LLM-Nahkampf an.
Snowflake veröffentlicht das hochmoderne „Enterprise Intelligence“-Modell Arctic, das sich auf unternehmensinterne Anwendungen konzentriert. Soeben gab der Datenmanagement- und Warehouse-Anbieter Snowflake bekannt, dass er sich dem LLM-Melee angeschlossen hat und ein großes Sprachmodell (LLM) der Spitzenklasse veröffentlicht hat, das sich auf Anwendungen auf Unternehmensebene konzentriert – Snowflake Arctic. Als LLM, das von einem Cloud-Computing-Unternehmen ins Leben gerufen wurde, bietet Arctic vor allem die folgenden zwei Vorteile:
- Effiziente Intelligenz: Arctic schneidet bei Unternehmensaufgaben wie SQL-Generierung, Programmierung und Befehlsverfolgung gut ab. , sogar vergleichbar mit Open-Source-Modellen, die mit höheren Rechenkosten trainiert wurden. Arctic setzt neue Maßstäbe für kostengünstige Schulungen und ermöglicht es Snowflake-Kunden, qualitativ hochwertige, maßgeschneiderte Modelle zu geringen Kosten für ihre Unternehmensanforderungen zu erstellen.
- Open Source: Arctic übernimmt die Apache 2.0-Lizenz und bietet offenen Zugriff auf Gewichte und Code, und Snowflake wird auch alle Datenlösungen und Forschungsergebnisse als Open Source bereitstellen.
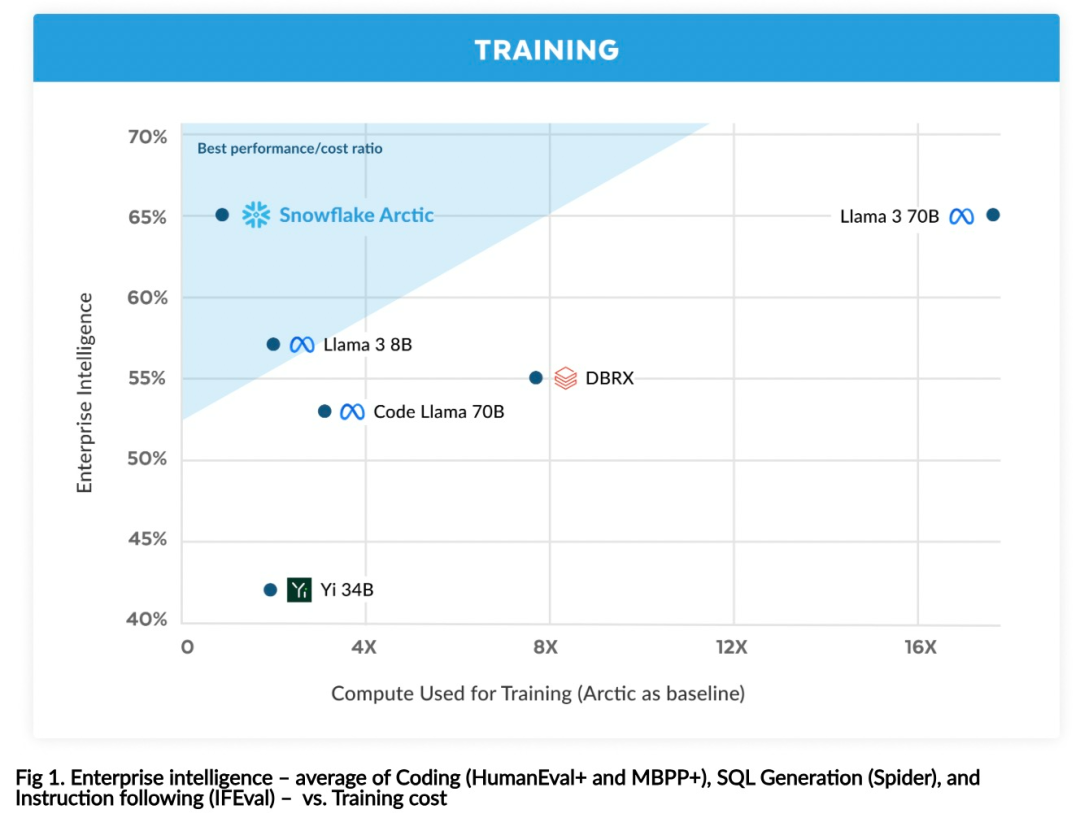
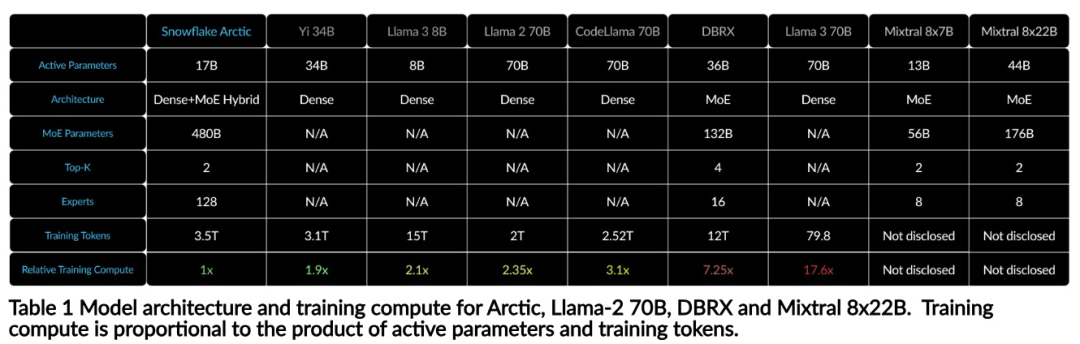
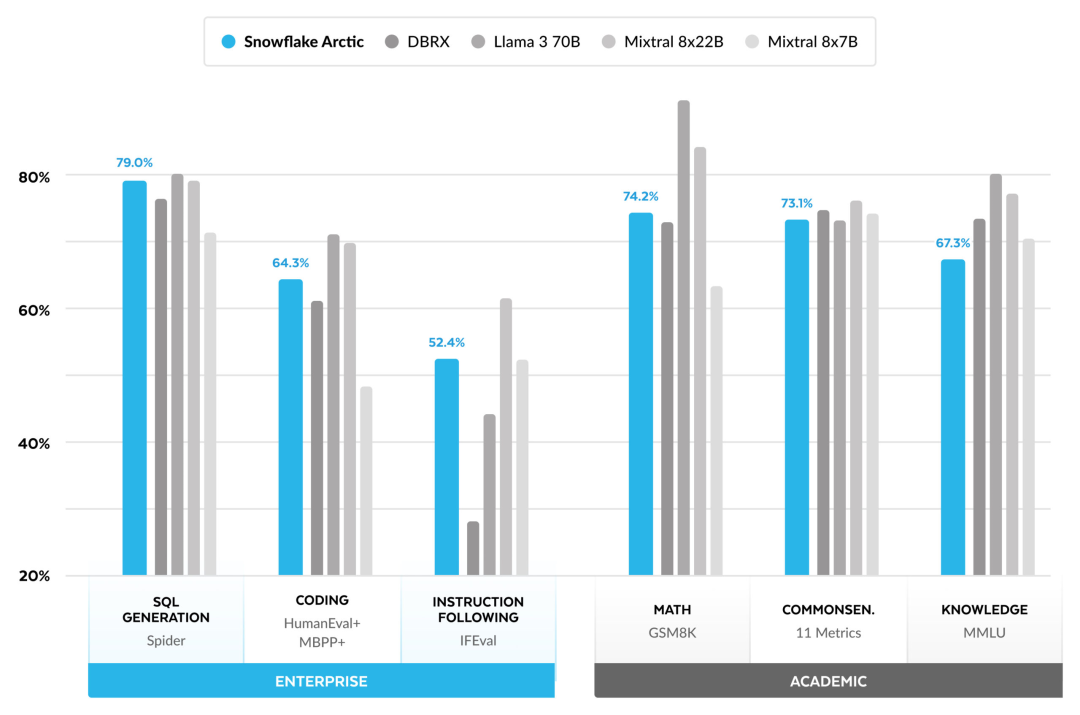
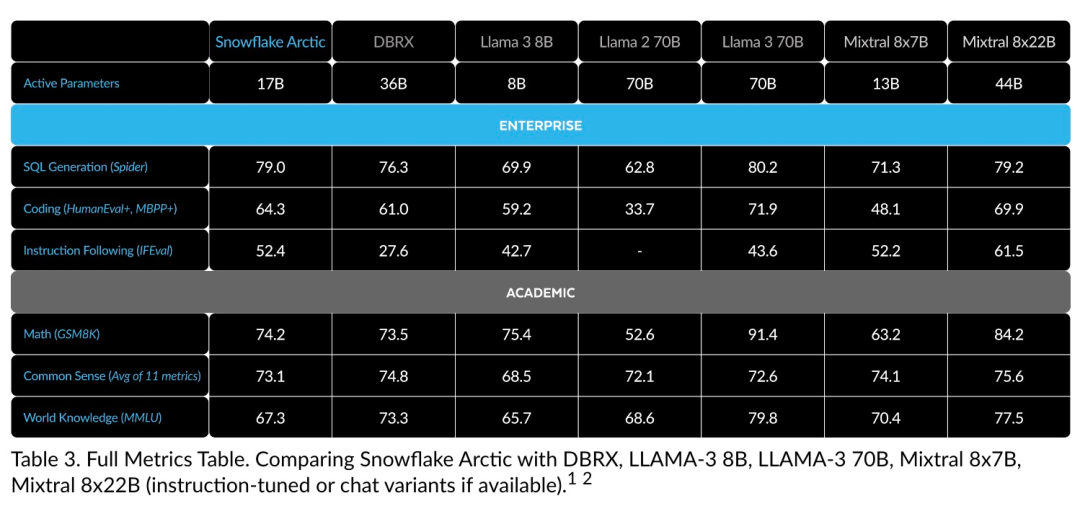
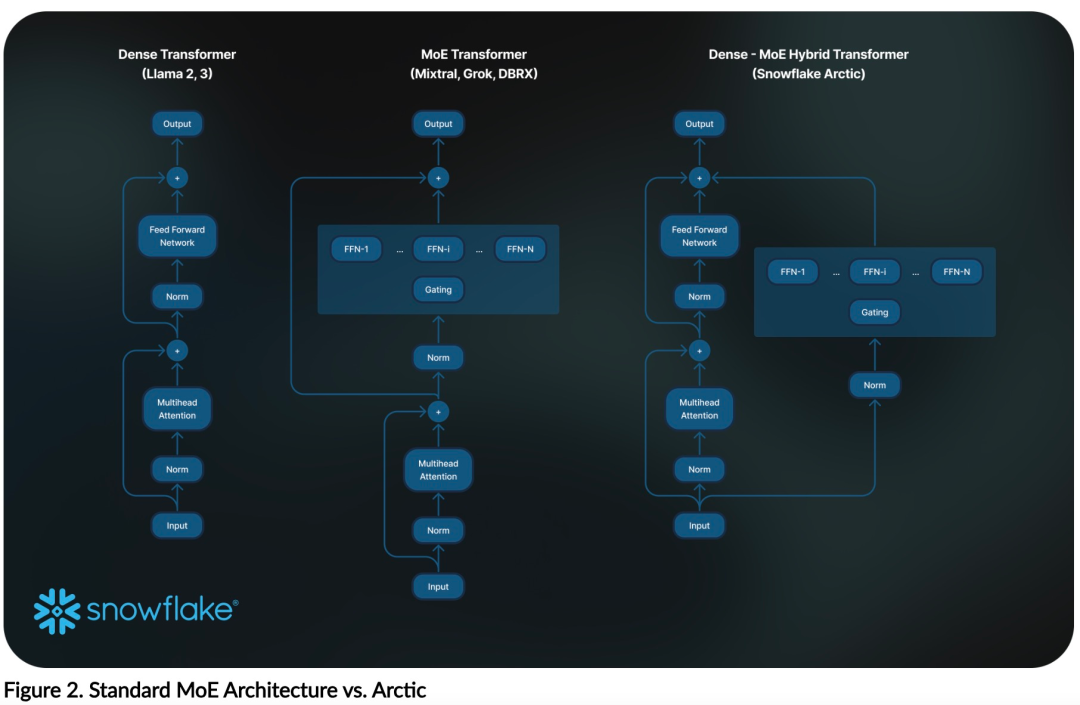
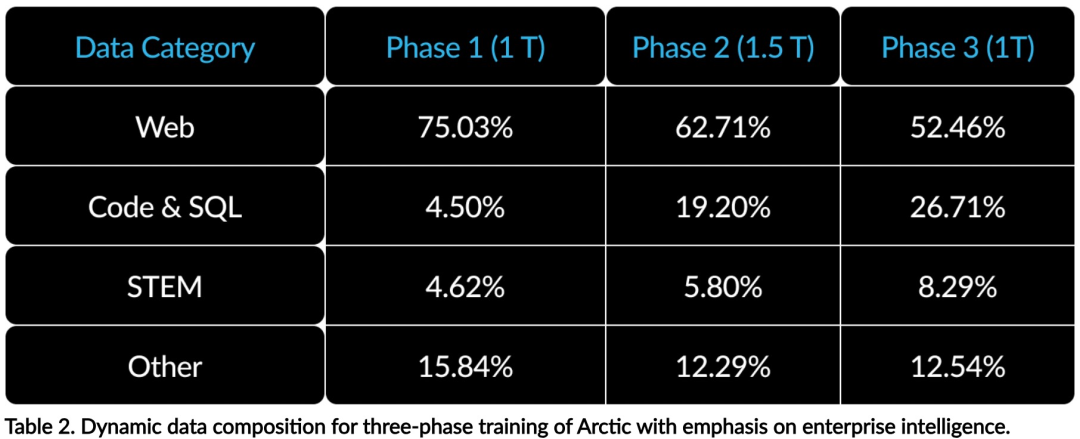
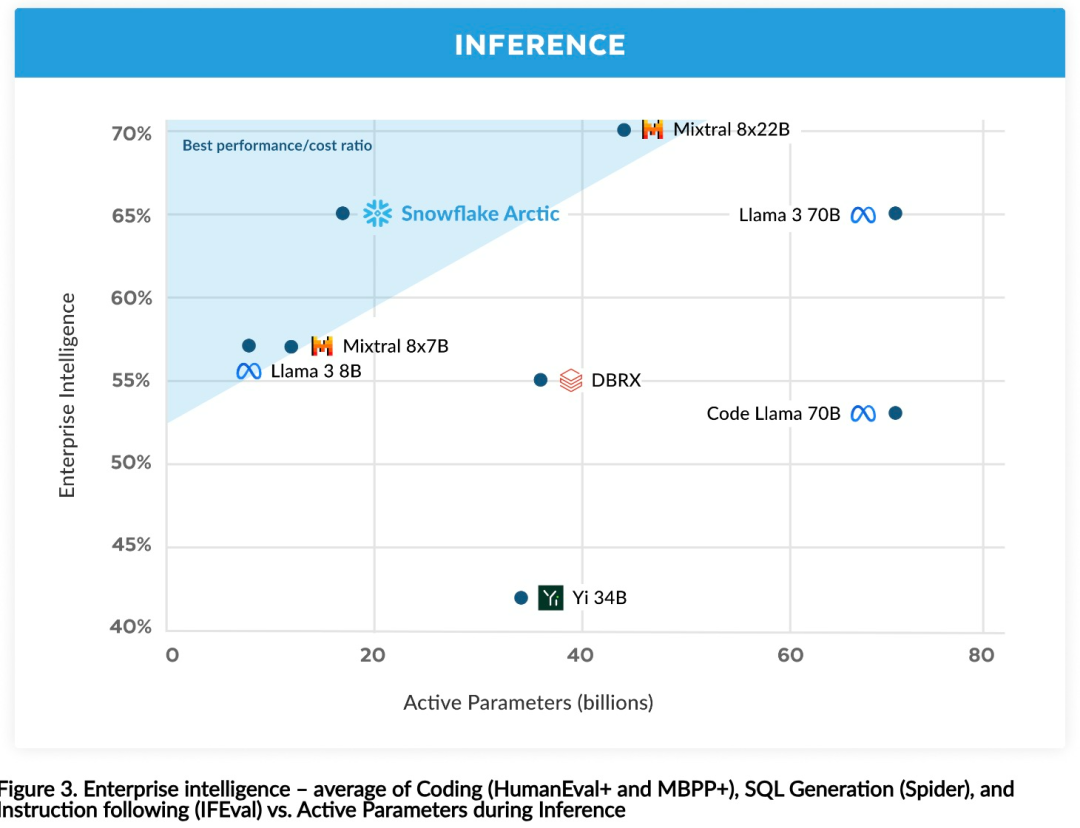
Jetzt können Sie auf Hugging Face auf das Arktis-Modell zugreifen. Snowflake sagte: Benutzer werden es bald über eine Reihe von Modellbibliotheken erhalten können, darunter Snowflake Cortex, AWS, Microsoft Azure, NVIDIA API, Lamini, Perplexity, Replicate und Together usw. Hugging Face: https://huggingface.co/Snowflake/snowflake-arctic-instructArctics Kontextfenster ist auf 4K eingestellt und das Forschungsteam entwickelt ein auf Aufmerksamkeitssenken basierendes Schiebefenster Die Implementierung wird in den kommenden Wochen eine unbegrenzte Sequenzgenerierung unterstützen und in naher Zukunft auf 32.000 Aufmerksamkeitsfenster erweitert werden. Hohe Leistung, niedrige KostenDas Forschungsteam von Snowflake erkannte ein konsistentes Muster bei den KI-Anforderungen und Anwendungsfällen von Unternehmenskunden: Unternehmen möchten LLM verwenden, um Konversations-SQL-Daten-Copilot und -Code zu erstellen Copilot und RAG-Chatbots. Das bedeutet, dass der LLM über hervorragende SQL- und Codekenntnisse, das Befolgen komplexer Anweisungen und das Generieren konkreter Antworten verfügen muss. Snowflake kombiniert diese Fähigkeiten in einer einzigen Metrik namens „Enterprise Intelligence“, indem es die Leistungsniveaus von Codierung (HumanEval+ und MBPP+), SQL-Generierung (Spider) und Befehlsfolge (IFEval) mittelt. Arctic erreicht die höchste Stufe der „Enterprise Intelligence“ im Open-Source-LLM und erreicht dies bei etwa weniger als 2 Millionen US-Dollar an Trainingsrechenkosten (weniger als 3.000 GPU-Wochen). Dies bedeutet, dass Arctic leistungsfähiger ist als andere Open-Source-Modelle, die mit ähnlichen Rechenkosten trainiert wurden. Noch wichtiger ist, dass sich Arctic im Bereich Enterprise Intelligence auszeichnet, selbst im Vergleich zu Modellen, die mit viel höheren Rechenkosten trainiert wurden. Die hohe Trainingseffizienz von Arctic bedeutet, dass Snowflake-Kunden und die KI-Community insgesamt benutzerdefinierte Modelle kostengünstiger trainieren können. Wie in Abbildung 1 dargestellt, liegt Arctic in Bezug auf Enterprise-Intelligence-Metriken auf Augenhöhe mit LLAMA 3 8B und LLAMA 2 70B und verbraucht dabei weniger als die Hälfte der Trainingsrechenkosten. Und obwohl Arctic nur 1/17 der Rechenkosten verbraucht, ist es bei Indikatoren wie Kodierung (HumanEval+ und MBPP+), SQL (Spider) und Befehlsfolge (IFEval) mit Llama3 70B vergleichbar, d. h. Arctic behält seine Wettbewerbsfähigkeit bei der Gesamtleistung bei habe das gleichzeitig gemacht. Darüber hinaus bewertete Snowflake Arctic auch nach akademischen Maßstäben, wobei Weltwissen, gesunder Menschenverstand und mathematische Fähigkeiten einbezogen wurden. Die vollständigen Bewertungsergebnisse sind in der folgenden Abbildung dargestellt: Um die oben genannte Trainingseffizienz zu erreichen, verwendet Arctic eine einzigartige Dense-MoE-Hybridtransformatorarchitektur. Es kombiniert ein 10B-Dense-Transformer-Modell mit einem 128×3,66B Rest-MoE-MLP mit insgesamt 480B Parametern und 17B aktiven Parametern, wobei Top-2-Gating zur Auswahl verwendet wird.Beim Entwurf und Training von Arctic nutzte das Forschungsteam die folgenden drei wichtigen Erkenntnisse und Innovationen: MoE-Experten und Kompressionstechnologie Ende 2021 hat das DeepSpeed-Team It wird gezeigt, dass MoE auf autoregressives LLM angewendet werden kann, wodurch die Modellqualität erheblich verbessert wird, ohne den Rechenaufwand zu erhöhen. Beim Entwurf von Arctic stellte das Forschungsteam fest, dass die Verbesserung der Modellqualität basierend auf dieser Idee hauptsächlich von der Anzahl der Experten und der Gesamtzahl der Parameter im MoE-Modell sowie der Anzahl der Kombinationen dieser Experten abhängt. Auf dieser Grundlage ist Arctic darauf ausgelegt, 480B Parameter auf 128 feinkörnige Experten zu verteilen und mithilfe von Top-2-Gating 17B aktive Parameter auszuwählen. Architektur- und System-Co-DesignDas Training einer grundlegenden MoE-Architektur mit einer großen Anzahl von Experten auf leistungsstarker KI-Trainingshardware ist aufgrund des hohen Overheads der vollständig vernetzten Kommunikation zwischen Experten sehr ineffizient. Snowflake hat herausgefunden, dass dieser Overhead eliminiert werden könnte, wenn sich die Kommunikation mit der Berechnung überschneiden könnte. Daher kombiniert Arctic einen dichten Transformator mit einer verbleibenden MoE-Komponente (Abbildung 2), um Überlappungen durch Kommunikation zu berechnen, wodurch das Trainingssystem eine gute Trainingseffizienz erreichen und den größten Teil des Kommunikationsaufwands verbergen kann. Curriculum-Lernen mit Fokus auf UnternehmensdatenHervorragende Leistung bei Metriken auf Unternehmensebene wie Codegenerierung und SQL erfordert Daten-Curriculum-Lernen (Curriculum Learning), das sich völlig von allgemeinen Metriken unterscheidet. Durch Hunderte von kleinen Ablationsexperimenten lernte das Team, dass allgemeine Fähigkeiten, wie etwa gesundes Denken, in der Anfangsphase erlernt werden können, während komplexere Metriken, wie etwa Codierung, Mathematik und SQL, später effektiv erlernt werden können in der Ausbildung. Dies kann mit der menschlichen Lebenserziehung verglichen werden, bei der nach und nach Fähigkeiten von einfach bis schwierig erworben werden. Daher verwendet Arctic einen dreistufigen Lehrplan, wobei jede Stufe eine andere Datenzusammensetzung aufweist, wobei sich die erste Stufe auf allgemeine Fähigkeiten (1T-Token) und die letzten beiden Stufen auf unternehmerische Fähigkeiten (1,5T- und 1T-Token) konzentriert. Inferenzeffizienz ist auch ein wichtiger Aspekt der Modelleffizienz, der sich darauf auswirkt, ob das Modell tatsächlich zu geringen Kosten eingesetzt werden kann. Arctic stellt einen Größensprung von MoE-Modellen dar, da es mehr Experten und Gesamtparameter verwendet als jedes andere Open-Source-Regressions-MoE-Modell. Daher benötigt Snowflake mehrere innovative Ideen, um sicherzustellen, dass Arctic effizient schließen kann: a) Bei interaktiver Inferenz mit einer kleinen Batch-Größe, beispielsweise einer Batch-Größe von 1, wird die Inferenzlatenz des MoE-Modells durch das Lesen aller begrenzt Aktive Parameter Die Zeitinferenz ist durch die Speicherbandbreite begrenzt. Bei dieser Stapelgröße beträgt das Speicherlesevolumen von Arctic (17B aktive Parameter) nur 1/4 von Code-Llama 70B und 2/5 von Mixtral 8x22B (44B aktive Parameter), was zu schnelleren Inferenzraten führt. b) Wenn die Stapelgröße erheblich zunimmt, beispielsweise Tausende von Token pro Vorwärtsdurchlauf, geht Arctic von einer begrenzten Speicherbandbreite zu einer rechnerisch begrenzten Bewegung über, wobei die Inferenz durch die aktiven Parameter jedes Tokens begrenzt wird. In dieser Hinsicht beträgt der Rechenaufwand für Arctic ein Viertel des Rechenaufwands von CodeLlama 70B und Llama 3 70B. Um eine rechengebundene Inferenz und einen hohen Durchsatz zu erreichen, der der geringen Anzahl aktiver Parameter in der Arktis entspricht, ist eine größere Batchgröße erforderlich. Um dies zu erreichen, ist ausreichend KV-Cache erforderlich, um dies zu unterstützen, sowie genügend Speicher, um die fast 500 B-Parameter des Modells zu speichern. Obwohl es eine Herausforderung darstellt, erreicht Snowflake dies durch die Verwendung von zwei Knoten für die Inferenz und die Kombination von Systemoptimierungen wie FP8-Gewichten, Split-Fuse und kontinuierlichem Batching, Intra-Node-Tensor-Parallelität und Inter-Node-Pipeline-Parallelität. Das Forschungsteam hat eng mit NVIDIA zusammengearbeitet, um die Inferenz für NVIDIA NIM-Mikrodienste zu optimieren, die von TensorRT-LLM gesteuert werden. Gleichzeitig arbeitet das Forschungsteam auch mit der vLLM-Community zusammen, und interne Entwicklungsteams werden in den kommenden Wochen auch die effiziente Inferenz von Arctic für Unternehmensanwendungsfälle implementieren. Referenzlink: https://www.snowflake.com/blog/arctic-open-efficient-foundation-lingual-models-snowflake/Das obige ist der detaillierte Inhalt vonMit nur 1/17 der Schulungskosten von Llama3, Snowflake Open-Source-128x3B-MoE-Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!