
Heim >Technologie-Peripheriegeräte >KI >Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!
Fügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!

- WBOYnach vorne
- 2024-03-14 23:50:021057Durchsuche
Oben geschrieben & das persönliche Verständnis des Autors
Im autonomen Fahrsystem ist die Wahrnehmungsaufgabe ein entscheidender Bestandteil des gesamten autonomen Fahrsystems. Das Hauptziel der Wahrnehmungsaufgabe besteht darin, autonome Fahrzeuge in die Lage zu versetzen, Umgebungselemente wie auf der Straße fahrende Fahrzeuge, Fußgänger am Straßenrand, während der Fahrt angetroffene Hindernisse, Verkehrszeichen auf der Straße usw. zu verstehen und wahrzunehmen und so flussabwärts zu helfen Module Treffen Sie richtige und vernünftige Entscheidungen und Handlungen. Ein Fahrzeug mit autonomen Fahrfähigkeiten ist in der Regel mit verschiedenen Arten von Informationserfassungssensoren ausgestattet, wie z. B. Rundumsichtkamerasensoren, Lidar-Sensoren, Millimeterwellenradarsensoren usw., um sicherzustellen, dass das autonome Fahrzeug die Umgebung genau wahrnehmen und verstehen kann Elemente, die es autonomen Fahrzeugen ermöglichen, beim autonomen Fahren die richtigen Entscheidungen zu treffen.
Derzeit haben rein bildbasierte visuelle Wahrnehmungsmethoden geringere Hardwarekosten und Bereitstellungskosten als Lidar-basierte Wahrnehmungsalgorithmen und haben daher große Aufmerksamkeit in Industrie und Wissenschaft erhalten. Es sind viele hervorragende visuelle Wahrnehmungsalgorithmen entstanden, um 3D-Objektwahrnehmungsaufgaben und semantische Segmentierungsaufgaben in BEV-Szenen zu erfüllen. Obwohl bestehende 3D-Zielwahrnehmungsalgorithmen erhebliche Fortschritte bei der Erkennungsleistung gemacht haben, gibt es in praktischen Anwendungen immer noch einige Probleme, die nach und nach aufgedeckt werden:
- Der ursprüngliche 3D-Zielwahrnehmungsalgorithmus kann die im Datensatz vorhandenen Long-Tail-Probleme nicht gut lösen , sowie Objekte, die in der realen Welt existieren, aber möglicherweise nicht im aktuellen Trainingsdatensatz gekennzeichnet sind (z. B. große Steine auf der Straße, umgestürzte Fahrzeuge usw.)
- Ursprüngliche 3D-Objekterkennungsalgorithmen geben normalerweise direkt ein grobes 3D aus Der stereoskopische Begrenzungsrahmen kann ein beliebig geformtes Zielobjekt nicht genau beschreiben, und der Ausdruck der Form und geometrischen Struktur des Objekts ist nicht feinkörnig genug. Obwohl dieses Ausgabeergebnisfeld die meisten Objektszenen erfüllen kann, beispielsweise verbundene Busse oder Baufahrzeuge mit langen Haken, kann der aktuelle 3D-Wahrnehmungsalgorithmus keine genaue und klare Beschreibung liefern Es wurde ein Erfassungsalgorithmus für das Belegungsnetzwerk (Occupancy Network) vorgeschlagen. Im Wesentlichen handelt es sich bei dem Wahrnehmungsalgorithmus des Occupancy Network um eine semantische Segmentierungsaufgabe, die auf räumlichen 3D-Szenen basiert. Der auf reinem Sehen basierende Occupancy-Network-Wahrnehmungsalgorithmus unterteilt den aktuellen 3D-Raum in 3D-Voxelgitter und sendet die gesammelten Umgebungsbilder über den im autonomen Fahrzeug ausgestatteten Umgebungskamerasensor nach der Verarbeitung und Vorhersage des Algorithmusmodells an das Netzwerkmodell den Belegungsstatus jedes 3D-Voxelgitters im aktuellen Raum und die möglichen Zielsemantikkategorien, wodurch eine umfassende Wahrnehmung der aktuellen 3D-Raumszene erreicht wird.
Vergleich der Genauigkeit und Inferenzgeschwindigkeit zwischen dem FastOcc-Algorithmus und anderen SOTA-Algorithmen
Link zum Papier: https://arxiv.org/pdf/2403.02710.pdf
Gesamtarchitektur und Details des Netzwerkmodells
In Ordnung Um die Belegung zu verbessern, haben wir Experimente aus vier Teilen für die Inferenzgeschwindigkeit des Netzwerkwahrnehmungsalgorithmus durchgeführt: der Auflösung des Eingabebildes, dem Merkmalsextraktions-Backbone-Netzwerk, der Methode der perspektivischen Konvertierung und der Struktur des Gittervorhersagekopfes Experimentelle Ergebnisse haben ergeben, dass die dreidimensionale Struktur des Gittervorhersagekopfes durch Faltung oder Entfaltung viel zeitaufwändigen Optimierungsraum aufweist. Auf dieser Grundlage haben wir die Netzwerkstruktur des FastOcc-Algorithmus entworfen, wie in der folgenden Abbildung dargestellt.
Netzwerkstrukturdiagramm des FastOcc-Algorithmus
Insgesamt umfasst der vorgeschlagene FastOcc-Algorithmus drei Untermodule, nämlich 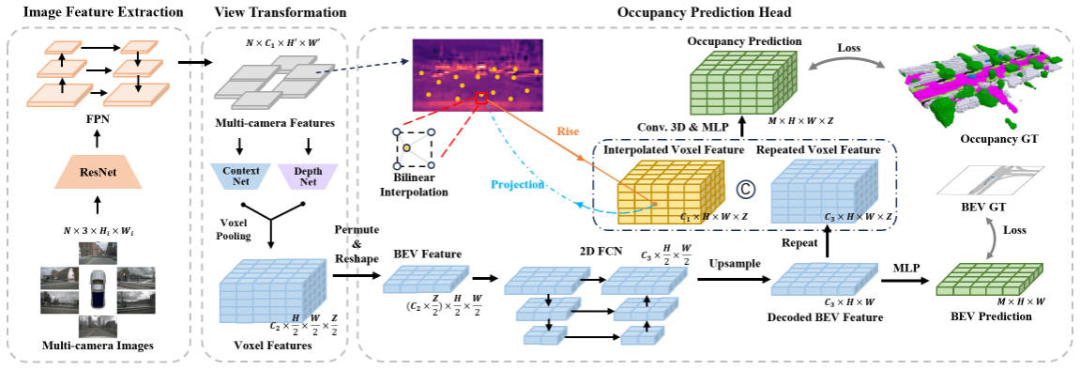 Image Feature Extraction
Image Feature Extraction
View Transformation für die perspektivische Konvertierung, Occupancy Prediction Head Gewohnt Um eine Wahrnehmungsleistung zu erzielen, werden wir die Details dieser drei Teile separat vorstellen.
Bildmerkmalsextraktion
Für den vorgeschlagenen FastOcc-Algorithmus ist die Netzwerkeingabe immer noch das gesammelte Surround-Bild. Hier verwenden wir die ResNet-Netzwerkstruktur, um den Feature-Extraktionsprozess des Surround-Bildes abzuschließen. Gleichzeitig verwenden wir auch die FPN-Merkmalspyramidenstruktur, um die vom Backbone-Netzwerk ausgegebenen mehrskaligen Bildmerkmale zu aggregieren. Zur Vereinfachung des nachfolgenden Ausdrucks stellen wir hier das Eingabebild als und die Merkmale nach der Merkmalsextraktion als dar.
Ansichtstransformation
Die Hauptfunktion des Ansichtstransformationsmoduls besteht darin, den Konvertierungsprozess von 2D-Bildmerkmalen in 3D-Raummerkmale abzuschließen und gleichzeitig die Kosten des Algorithmusmodells, normalerweise der Merkmale, zu senken In den 3D-Raum konvertiert wird ein grober Ausdruck. Zur Vereinfachung des Ausdrucks markieren wir hier die in den 3D-Raum konvertierten Merkmale als, wobei die Dimension des eingebetteten Merkmalsvektors und die Länge, Breite und Höhe des Wahrnehmungsraums dargestellt werden. Unter den aktuellen Wahrnehmungsalgorithmen umfasst der gängige Perspektivkonvertierungsprozess zwei Kategorien:
- Eine davon ist die von BEVFormer dargestellte Rückwärtskoordinatentransformationsmethode. Diese Art von Methode generiert normalerweise zuerst eine Voxelabfrage im 3D-Raum und interagiert dann mithilfe von Cross-View Attention mit der Voxelabfrage im 3D-Raum und 2D-Bildmerkmalen, um die Konstruktion des endgültigen 3D-Voxelmerkmals abzuschließen.
- Ein Typ ist die durch LSS dargestellte Vorwärtskoordinatentransformationsmethode. Diese Art von Methode verwendet das Tiefenschätzungsnetzwerk im Netzwerk, um gleichzeitig die semantischen Merkmalsinformationen und die diskrete Tiefenwahrscheinlichkeit jeder Merkmalspixelposition abzuschätzen, das semantische Kegelstumpfmerkmal durch die äußere Produktoperation zu konstruieren und schließlich die VoxelPooling-Schicht zu verwenden, um dies zu erreichen letztes 3D-Voxel-Feature der Konstruktion.
Angesichts der Tatsache, dass der LSS-Algorithmus eine bessere Argumentationsgeschwindigkeit und Effizienz aufweist, übernehmen wir in diesem Artikel den LSS-Algorithmus als unser Perspektivenkonvertierungsmodul. Wenn man bedenkt, dass die diskrete Tiefe jeder Pixelposition geschätzt wird, schränkt ihre Unsicherheit gleichzeitig die endgültige Wahrnehmungsleistung des Modells in gewissem Maße ein. Daher nutzen wir in unserer spezifischen Implementierung Punktwolkeninformationen zur Überwachung in Tiefenrichtung, um bessere Wahrnehmungsergebnisse zu erzielen.
Raster Prediction Head (Occupancy Prediction Head)
Im oben gezeigten Netzwerkstrukturdiagramm enthält der Raster Prediction Head auch drei Unterteile, nämlich BEV-Feature-Extraktion, Bild-Feature-Interpolationsabtastung, Feature-Integration . Als nächstes werden wir nacheinander die Details der dreiteiligen Methode vorstellen.
BEV-Merkmalsextraktion
Derzeit verarbeiten die meisten Occupancy-Network-Algorithmen die vom Perspektivenkonvertierungsmodul erhaltenen 3D-Voxelmerkmale. Die Verarbeitungsform ist im Allgemeinen ein dreidimensionales, vollständig gefaltetes Netzwerk. Insbesondere ist für jede Schicht des dreidimensionalen, vollständig Faltungsnetzwerks der erforderliche Rechenaufwand zum Falten der eingegebenen dreidimensionalen Voxelmerkmale wie folgt:
wobei und die Anzahl der Kanäle des Eingabemerkmals bzw. des Ausgabemerkmals darstellen und stellen die Größe des Feature-Map-Bereichs dar. Im Vergleich zur direkten Verarbeitung von Voxel-Features im 3D-Raum verwenden wir ein leichtes 2D-BEV-Feature-Faltungsmodul. Insbesondere für die Ausgabe-Voxel-Merkmale des Perspektivenkonvertierungsmoduls verschmelzen wir zunächst Höheninformationen und semantische Merkmale, um 2D-BEV-Merkmale zu erhalten, und verwenden dann ein 2D-Vollfaltungsnetzwerk, um eine Merkmalsextraktion durchzuführen, um die Merkmalsextraktion dieser 2D-Merkmale zu erhalten Prozess Der Berechnungsbetrag des Prozesses kann in der folgenden Form ausgedrückt werden
Beim Vergleich des Berechnungsbetrags der 3D- und 2D-Verarbeitungsprozesse ist ersichtlich, dass durch die Verwendung des leichten 2D-BEV-Merkmalsfaltungsmoduls die ursprüngliche 3D-Voxel-Merkmalsextraktion ersetzt wird , es kann stark reduziert werden Der Berechnungsaufwand des Modells. Gleichzeitig ist in der folgenden Abbildung das visuelle Flussdiagramm der beiden Verarbeitungsarten dargestellt:
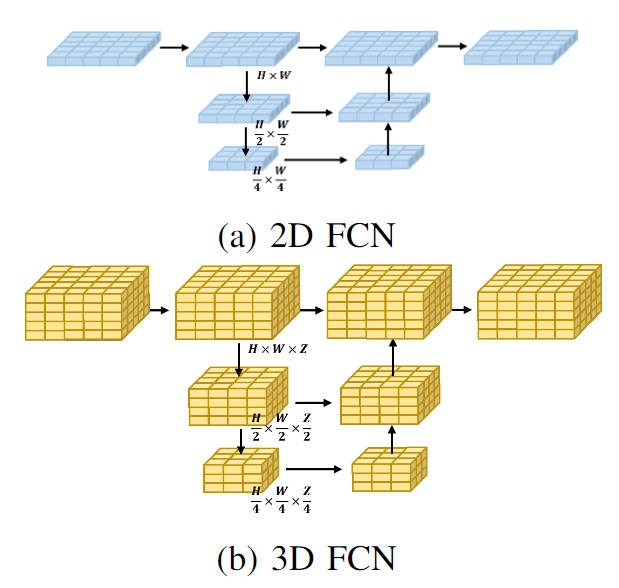
Visualisierung von 2D-FCN- und 3D-FCN-Netzwerkstrukturen
Bildmerkmals-Interpolationsabtastung
Um zu reduzieren Der Berechnungsbetrag des Rastervorhersagekopfmoduls komprimieren wir die Höhe der vom Perspektivenkonvertierungsmodul ausgegebenen 3D-Voxelmerkmale und verwenden das 2D-BEV-Faltungsmodul zur Merkmalsextraktion. Um jedoch die fehlenden Informationen zu Z-Achsen-Höhenmerkmalen zu erhöhen und an der Idee festzuhalten, die Menge an Modellberechnungen zu reduzieren, haben wir eine Bildmerkmals-Interpolations-Abtastmethode vorgeschlagen.
Konkret legen wir zunächst den entsprechenden dreidimensionalen Voxelraum entsprechend dem zu erfassenden Bereich fest und weisen ihn dem Ego-Koordinatensystem zu, das als bezeichnet wird. Zweitens werden die extrinsischen und intrinsischen Koordinatentransformationsmatrizen der Kamera verwendet, um die Koordinatenpunkte im Ego-Koordinatensystem auf das Bildkoordinatensystem zu projizieren, das zum Extrahieren von Bildmerkmalen an den entsprechenden Positionen verwendet wird.
Darunter stellen sie die intrinsische und extrinsische Koordinatentransformationsmatrize der Kamera dar und repräsentieren die Position des Raumpunkts im Ego-Koordinatensystem, projiziert auf das Bildkoordinatensystem. Nachdem wir die entsprechenden Bildkoordinaten erhalten haben, filtern wir Koordinatenpunkte heraus, die den Bildbereich überschreiten oder eine negative Tiefe haben. Anschließend verwenden wir eine bilineare Interpolationsoperation, um die entsprechenden semantischen Bildmerkmale basierend auf der projizierten Koordinatenposition zu erhalten, und mitteln die aus allen Kamerabildern gesammelten Merkmale, um das endgültige Interpolationsabtastergebnis zu erhalten.
Feature-Integration
Um die erhaltenen planaren BEV-Features mit den durch Interpolationsabtastung erhaltenen 3D-Voxel-Features zu integrieren, verwenden wir zunächst eine Upsampling-Operation, um die räumlichen Dimensionen der BEV-Features und die räumlichen Dimensionen der 3D-Voxel-Features auszurichten , und Der Wiederholungsvorgang wird entlang der Z-Achsenrichtung ausgeführt und die nach dem Vorgang erhaltenen Merkmale werden als aufgezeichnet. Anschließend verknüpfen wir die durch Interpolationsabtastung von Bildmerkmalen erhaltenen Merkmale und integrieren sie über eine Faltungsschicht, um das endgültige Voxelmerkmal zu erhalten.
Der oben erwähnte Gesamtprozess der Bildmerkmalsinterpolationsabtastung und Merkmalsintegration kann durch die folgende Abbildung dargestellt werden:
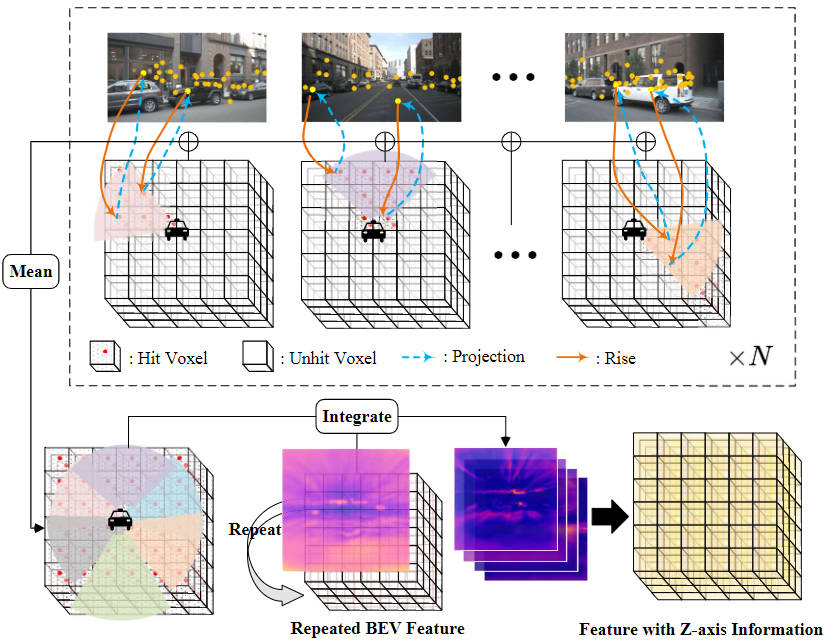
Bildmerkmalsinterpolationsabtastung und Merkmalsintegrationsprozess
Zusätzlich, um die BEV-Funktion weiter sicherzustellen Extraktionsmodul Die ausgegebenen BEV-Merkmale enthalten genügend Merkmalsinformationen, um den nachfolgenden Wahrnehmungsprozess abzuschließen. Wir wenden eine zusätzliche Überwachungsmethode an, d Die semantische Segmentierung vervollständigt den gesamten Überwachungsprozess.
Experimentelle Ergebnisse und Bewertungsindikatoren
Quantitativer Analyseteil
Zunächst zeigen wir den Vergleich zwischen unserem vorgeschlagenen FastOcc-Algorithmus und anderen SOTA-Algorithmen im Occ3D-nuScenes-Datensatz In der Tabelle unten wird angezeigt
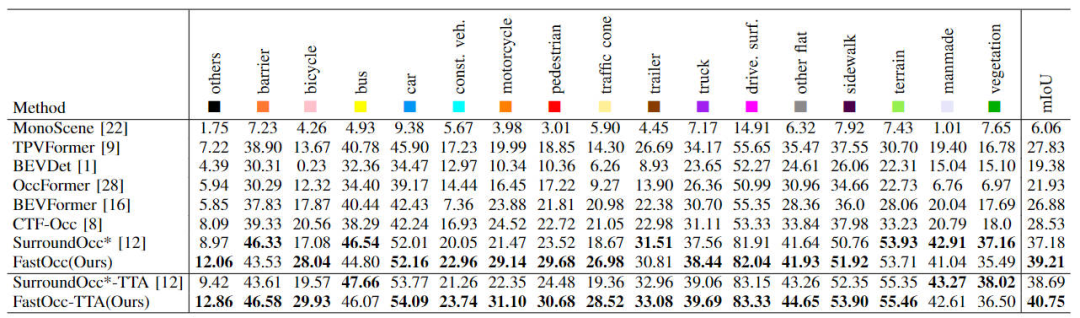
Der Vergleich der einzelnen Algorithmusindizes im Occ3D-nuScenes-Datensatz
Aus den Ergebnissen in der Tabelle ist ersichtlich, dass der von uns vorgeschlagene FastOcc-Algorithmus im Vergleich zu anderen Algorithmen eine bessere Leistung aufweist Die meisten Kategorien haben mehr Vorteile als andere Algorithmen, und der gesamte mIoU-Indikator erzielt auch den SOTA-Effekt.
Darüber hinaus haben wir auch die Auswirkungen verschiedener Perspektivenkonvertierungsmethoden und des im Rastervorhersagekopf verwendeten Decodierungsfunktionsmoduls auf die Wahrnehmungsleistung und die Argumentationszeit verglichen (die experimentellen Daten basieren auf der Eingabebildauflösung von 640 × 1600, dem Rückgrat). Das Netzwerk verwendet das ResNet-101-Netzwerk.) Die relevanten experimentellen Ergebnisse werden wie in der folgenden Tabelle gezeigt verglichen -view Die Perspektivkonvertierungsmethode „Attention“ und die 3D-Faltung werden zum Extrahieren von 3D-Voxelmerkmalen verwendet, was die höchste Argumentationszeit hat. Nachdem wir die ursprüngliche Cross-View-Attention-Perspektivkonvertierungsmethode durch die LSS-Konvertierungsmethode ersetzt haben, wurde die mIoU-Genauigkeit verbessert und der Zeitverbrauch reduziert. Auf dieser Basis kann durch Ersetzen der ursprünglichen 3D-Faltung durch eine 3D-FCN-Struktur die Genauigkeit weiter erhöht werden, aber auch die Argumentationszeit wird deutlich erhöht. Schließlich haben wir uns für die Koordinatenkonvertierungsmethode der Abtastung von LSS und die 2D-FCN-Struktur entschieden, um ein Gleichgewicht zwischen Erkennungsleistung und Inferenzzeitverbrauch zu erreichen.
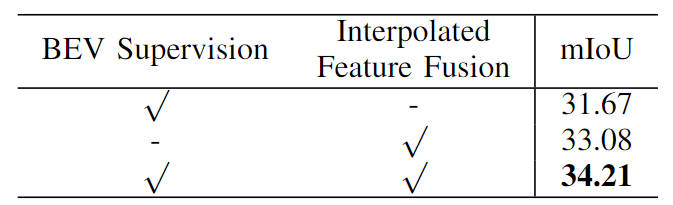
Darüber hinaus haben wir auch die Wirksamkeit unserer vorgeschlagenen semantischen Segmentierungsüberwachungsaufgabe basierend auf BEV-Merkmalen und Bildmerkmalsinterpolationsstichproben überprüft. Die spezifischen Ergebnisse der Ablationsexperimente sind in der folgenden Tabelle aufgeführt: 
Vergleich von Ablationsexperimenten verschiedener Module Situation
Darüber hinaus führten wir auch Skalenexperimente mit dem Modell durch und erstellten eine Reihe von Wahrnehmungsalgorithmusmodellen für das Belegungsnetzwerk (FastOcc, FastOcc-Small, FastOcc-Tiny), indem wir die Größe des Backbone-Netzwerks und die Auflösung steuerten Eingabebild. Die spezifische Konfiguration ist in der folgenden Tabelle dargestellt:
Vergleich der Modellfunktionen unter verschiedenen Backbone-Netzwerk- und Auflösungskonfigurationen
Qualitativer Analyseteil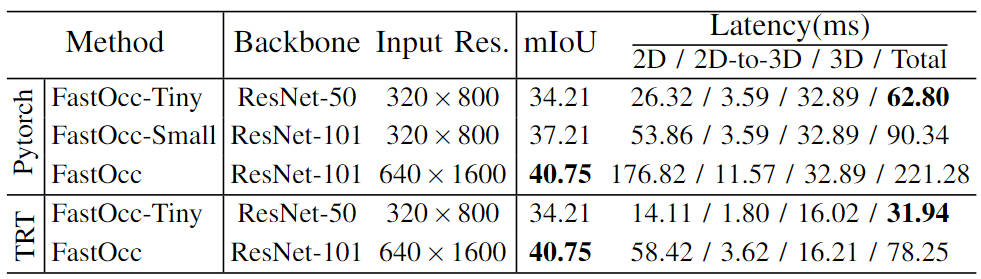
Vergleich der visuellen Ergebnisse zwischen dem FastOcc-Algorithmus und dem SurroundOcc-Algorithmus
Fazit
In diesem Artikel haben wir das FastOcc-Algorithmusmodell vorgeschlagen, um das Problem zu lösen, dass die Erkennung des vorhandenen Occupancy Network-Algorithmusmodells lange dauert und sich nur schwer im Fahrzeug implementieren lässt. Durch Ersetzen des ursprünglichen 3D-Faltungsmoduls, das 3D-Voxel verarbeitet, durch 2D-Faltung wird die Argumentationszeit erheblich verkürzt und im Vergleich zu anderen Algorithmen werden SOTA-Wahrnehmungsergebnisse erzielt.
Das obige ist der detaillierte Inhalt vonFügen Sie SOTA in Echtzeit hinzu und explodieren Sie! FastOcc: Schnellere Inferenz und ein einsatzfreundlicher Occ-Algorithmus sind da!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!