
Heim >Technologie-Peripheriegeräte >KI >Zu vollständig! Ein Rückblick auf multimodales Deep Learning!
Zu vollständig! Ein Rückblick auf multimodales Deep Learning!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-04-08 09:10:021090Durchsuche
1. Einführung
Unsere Erfahrung der Welt ist multimodal – wir sehen Objekte, hören Geräusche, fühlen Texturen, riechen und schmecken. Modalität bezieht sich auf die Art und Weise, wie ein bestimmter Zustand auftritt oder erlebt wird. Wenn eine Forschungsfrage mehrere Modalitäten enthält, wird sie als multimodal bezeichnet. Damit die KI Fortschritte beim Verständnis der Welt um uns herum machen kann, muss sie in der Lage sein, diese multimodalen Signale gleichzeitig zu interpretieren.
Zum Beispiel werden Bilder oft mit Tags und Texterklärungen verknüpft, und Text enthält Bilder, um die zentrale Idee des Artikels klarer auszudrücken. Verschiedene Modalitäten haben sehr unterschiedliche statistische Eigenschaften. Diese Daten werden als multimodale Big Data bezeichnet und enthalten umfangreiche multimodale und modalübergreifende Informationen, was herkömmliche Datenfusionsmethoden vor große Herausforderungen stellt.
In dieser Rezension stellen wir einige bahnbrechende Deep-Learning-Modelle vor, um diese multimodalen Big Data zusammenzuführen. Da multimodale Big Data zunehmend erforscht werden, gibt es noch einige Herausforderungen, die angegangen werden müssen. Daher bietet dieser Artikel einen Überblick über Deep Learning für die Fusion multimodaler Daten mit dem Ziel, den Lesern (unabhängig von ihrer ursprünglichen Community) die Grundprinzipien multimodaler Deep-Learning-Fusion-Methoden zu vermitteln und neue Arten multimodaler Daten für die Deep-Learning-Fusion-Technologie zu inspirieren.
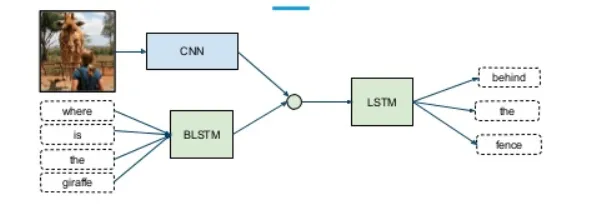
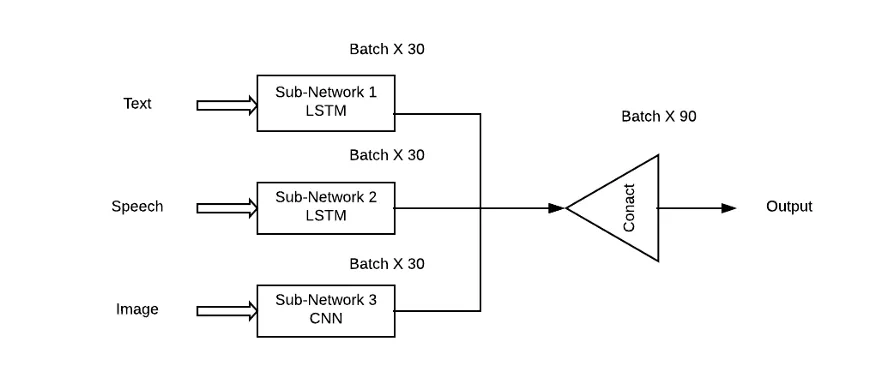
Das Problem bei diesem Ansatz besteht darin, dass er allen Subnetzwerken/Mustern die gleiche Bedeutung beimisst, was in realen Situationen sehr unwahrscheinlich ist. Hier muss eine gewichtete Kombination von Teilnetzwerken verwendet werden, damit jede Eingabemodalität einen Lernbeitrag (Theta) zur Ausgabevorhersage leisten kann. 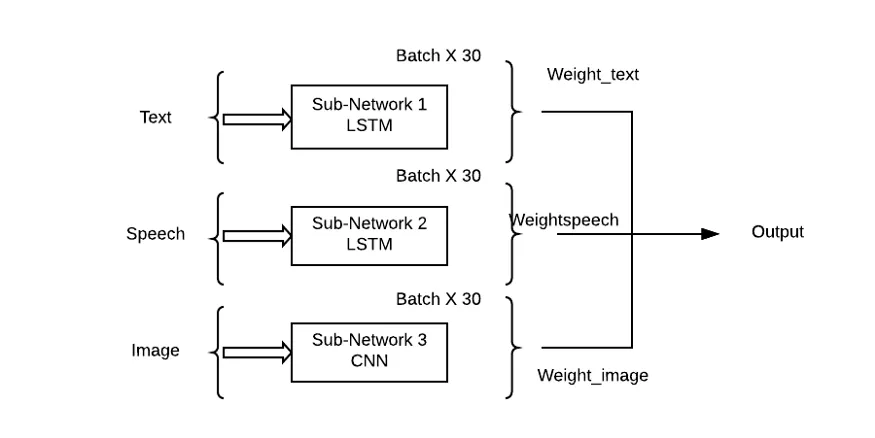
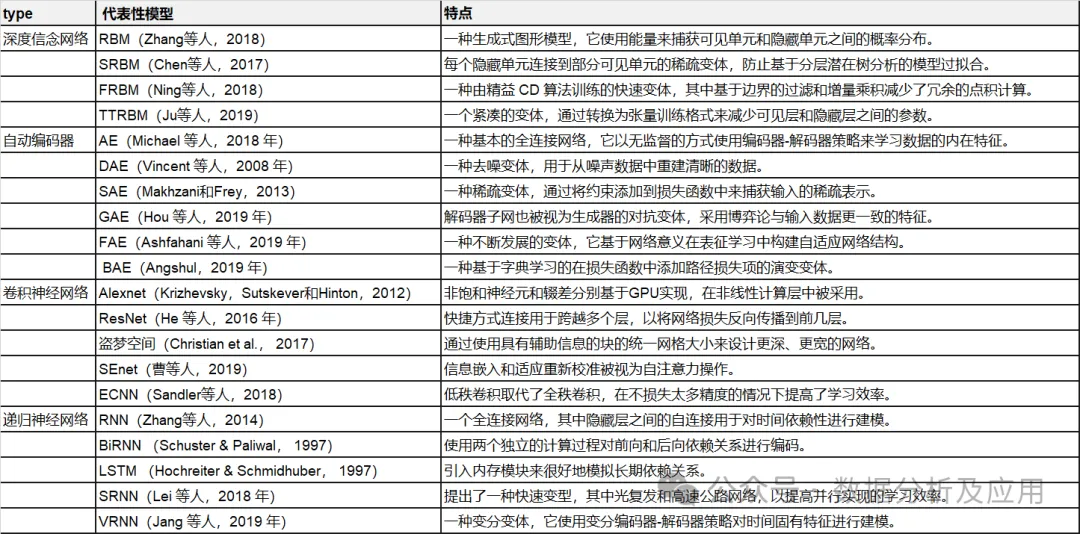
2. Repräsentative Deep-Learning-Architektur
In diesem Abschnitt stellen wir die repräsentative Deep-Learning-Architektur des multimodalen Datenfusions-Deep-Learning-Modells vor. Insbesondere werden die Definition von tiefer Architektur, Feedforward-Berechnung und Backpropagation-Berechnung sowie typische Variationen gegeben. Repräsentative Modelle werden zusammengefasst.
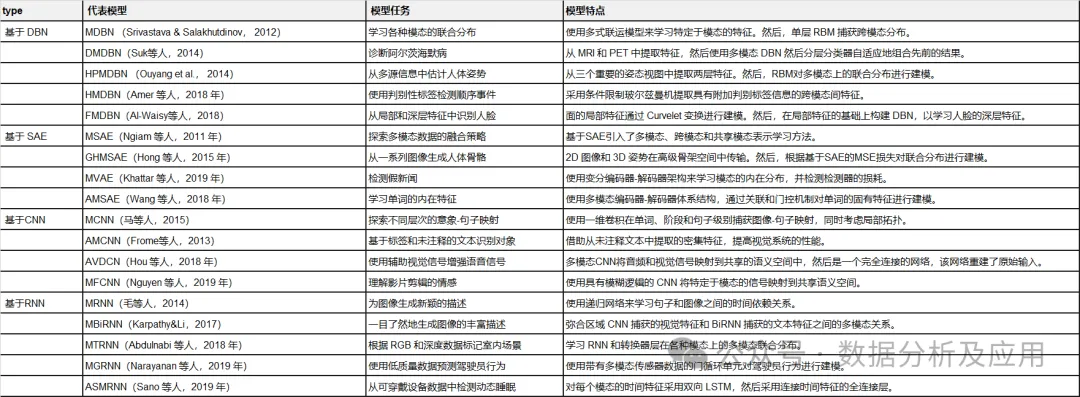
Tabelle 1: Zusammenfassung repräsentativer Deep-Learning-Modelle.
2.1 Deep Belief Network (DBN)
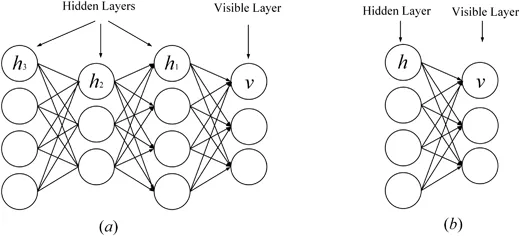
Restricted Boltzmann Machine (RBM) ist der Grundblock des Deep Belief Network (Zhang, Ding, Zhang, & RBM ist eine spezielle Variante der Boltzmann-Maschine (siehe Abbildung 1), die aus einer sichtbaren Schicht und einer verborgenen Schicht besteht. Es besteht eine vollständige Verbindung zwischen der sichtbaren Schicht und der verborgenen Schicht, es gibt jedoch keine Verbindung zwischen Einheiten in derselben Schicht. RBM ist auch ein generatives Modell, das eine Energiefunktion verwendet, um die Wahrscheinlichkeitsverteilung zwischen sichtbaren und verborgenen Einheiten zu erfassen. Mithilfe der Ableitung der Energiefunktion kann die Wahrscheinlichkeitsverteilung der Einheiten zwischen sichtbaren und verborgenen Einheiten berechnet werden. RBM kann die Wahrscheinlichkeitsverteilung zwischen einzelnen Elementen und verborgenen Einheiten erfassen. In RBM gibt es keine Verbindungen zwischen Zellen, außer dass es keine Verbindungen zwischen Zellen innerhalb derselben Schicht gibt und alle Zellen über vollständige Verbindungen verbunden sind. RBM verwendet die Energiefunktion auch, um die Wahrscheinlichkeitsverteilung zwischen sichtbaren und verborgenen Einheiten zu berechnen. Mithilfe der Wahrscheinlichkeitsfunktion von RBM kann die Wahrscheinlichkeitsverteilung zwischen Einheiten erfasst werden.
Kürzlich wurden einige fortschrittliche RBMs vorgeschlagen, um die Leistung zu verbessern. Um beispielsweise eine Netzwerküberanpassung zu vermeiden, haben Chen, Zhang, Yeung und Chen (2017) eine spärliche Boltzmann-Maschine entworfen, die die Netzwerkstruktur auf der Grundlage hierarchischer latenter Bäume lernt. Ning, Pittman und Shen (2018) führten den schnellen kontrastiven Divergenzalgorithmus in RBM ein, bei dem grenzenbasierte Filterung und Delta-Produkt verwendet werden, um redundante Skalarproduktberechnungen in der Berechnung zu reduzieren. Um die interne Struktur mehrdimensionaler Daten zu schützen, schlugen Ju et al. (2019) Tensor-RBM vor, um in mehrdimensionalen Daten verborgene Verteilungen auf hoher Ebene zu lernen, wobei Tensorzerlegung verwendet wird, um den Fluch der Dimensionalität zu vermeiden.
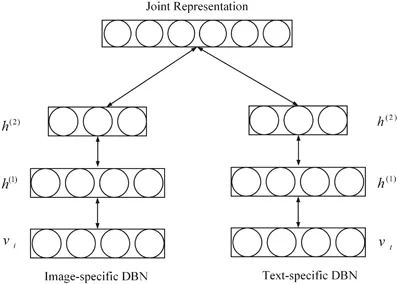
DBM ist eine typische tiefe Architektur, die aus mehreren RBMs gestapelt ist (Hinton & Salakhutdinov, 2006). Es handelt sich um ein generatives Modell, das auf Trainingsstrategien vor dem Training und der Feinabstimmung basiert und Energie nutzen kann, um die Verteilung von Verbindungen zwischen sichtbaren Objekten und entsprechenden Beschriftungen zu erfassen. Im Vortraining wird jede verborgene Schicht gierig als RBM modelliert, das in einer unbeaufsichtigten Richtlinie trainiert wird. Anschließend wird jede verborgene Schicht durch die diskriminierenden Informationen der Trainingsetiketten in der überwachten Strategie weiter trainiert. DBNs wurden zur Lösung von Problemen in vielen Bereichen verwendet, beispielsweise zur Reduzierung der Datendimensionalität, zum Repräsentationslernen und zum semantischen Hashing. Ein repräsentatives DBM ist in Abbildung 1 dargestellt.
Abbildung 1:
2.2 Stapeled AutoCoder (SAE)
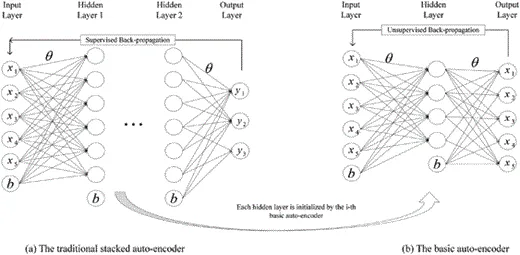
stacked AutoCoder (SAE) ist ein typisches Deep-Learning-Modell für die Architektur der Encoder-Decoderin (Michael, Olivier und Mario, 2018; Weng; Weng; , Lu, Tan und Zhou, 2016). Es kann die prägnanten Merkmale der Eingabe erfassen, indem es die ursprüngliche Eingabe auf unüberwachte und überwachte Weise in eine Zwischendarstellung umwandelt. SAE ist in vielen Bereichen weit verbreitet, darunter Dimensionsreduktion (Wang, Yao & Zhao, 2016), Bilderkennung (Jia, Shao, Li, Zhao & Fu, 2018) und Textklassifizierung (Chen & Zaki, 2017). Abbildung 2 zeigt ein repräsentatives SAE.
Abbildung 2:
2.3 Convolutional Neural Network (CNN)
DBN und SAE sind vollständig verbundene neuronale Netze. In beiden Netzwerken ist jedes Neuron in der verborgenen Schicht mit jedem Neuron in der vorherigen Schicht verbunden, und diese Topologie erzeugt eine große Anzahl von Verbindungen. Um die Gewichte dieser Verbindungen zu trainieren, benötigen vollständig verbundene neuronale Netze eine große Anzahl von Trainingsobjekten, um eine rechenintensive Über- und Unteranpassung zu vermeiden. Darüber hinaus berücksichtigt die vollständig verbundene Topologie nicht die Positionsinformationen von Merkmalen, die zwischen Neuronen enthalten sind. Daher können vollständig verbundene tiefe neuronale Netze (DBN, SAE und ihre Varianten) keine hochdimensionalen Daten verarbeiten, insbesondere keine großen Bilder und großen Audiodaten.
Faltungsneuronales Netzwerk ist ein spezielles tiefes Netzwerk, das die lokale Topologie der Daten berücksichtigt (Li, Xia, Du, Lin & Samat, 2017; Sze, Chen, Yang & Emer, 2017). Faltungs-Neuronale Netze umfassen vollständig verbundene Netze und eingeschränkte Netze, die Faltungsschichten und Pooling-Schichten enthalten. Eingeschränkte Netzwerke verwenden Faltungs- und Pooling-Operationen, um lokale Empfangsfelder und eine Parameterreduzierung zu erreichen. Faltungs-Neuronale Netze werden wie DBN und SAE über den stochastischen Gradientenabstiegsalgorithmus trainiert. Es hat große Fortschritte bei der medizinischen Bilderkennung (Magiori, Tarabalka, Charpiat & Alliez, 2017) und der semantischen Analyse (Hu, Lu, Li & Chen, 2014) gemacht. Ein repräsentatives CNN ist in Abbildung 3 dargestellt. Abbildung 3:
2.4 Recurrent Neural Network (RNN) 2011). Im Gegensatz zu Deep-Forward-Architekturen (d. h. DBN, SAE und CNN) ordnet es nicht nur Eingabemuster den Ausgabeergebnissen zu, sondern überträgt auch verborgene Zustände auf die Ausgabe, indem es Verbindungen zwischen verborgenen Einheiten nutzt (Graves & Schmidhuber, 2008). Mithilfe dieser verborgenen Verbindungen modellieren RNNs zeitliche Abhängigkeiten und teilen so Parameter zwischen Objekten in der zeitlichen Dimension. Es wurde in verschiedenen Bereichen wie der Sprachanalyse (Mulder, Bethard & Moens, 2015), der Bildunterschrift (Xu et al., 2015) und der Sprachübersetzung (Graves & Jaitly, 2014) angewendet und erzielte hervorragende Leistungen. Ähnlich wie bei der Deep-Forward-Architektur umfasst ihre Berechnung auch Vorwärtspass- und Backpropagation-Stufen. Bei der Vorwärtsdurchlaufberechnung erhält das RNN gleichzeitig den Eingabe- und den verborgenen Zustand. Bei der Backpropagation-Berechnung wird der zeitliche Backpropagation-Algorithmus verwendet, um den Verlust für den Zeitschritt zurückzupropagieren. Abbildung 4 zeigt ein repräsentatives RNN. 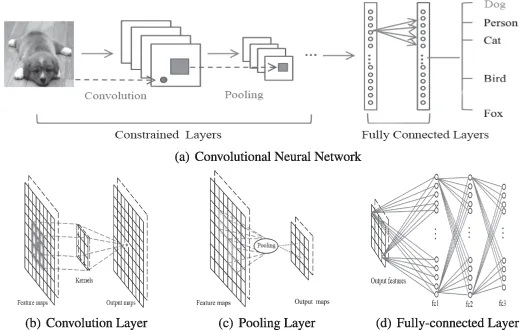
Abbildung 4:
3. Deep Learning für multimodale Datenfusion
In diesem Abschnitt überprüfen wir die neuesten Forschungsergebnisse aus der Perspektive von Modellaufgaben, Modellrahmen und Bewertungsdatensätzen Multimodales Deep-Learning-Modell zur Datenfusion. Sie sind basierend auf der verwendeten Deep-Learning-Architektur in vier Kategorien unterteilt. Tabelle 2 fasst repräsentative multimodale Deep-Learning-Modelle zusammen. 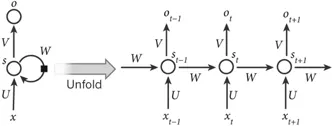
Tabelle 2:
Zusammenfassung repräsentativer multimodaler Deep-Learning-Modelle.
3.1 Netzwerkbasierte Deep-Believe-Multimodal-Datenfusion Das Generierungsmodell lernt multimodale Darstellungen, indem es die gemeinsame Verteilung multimodaler Daten über verschiedene Modalitäten (wie Bilder, Text und Audio) anpasst.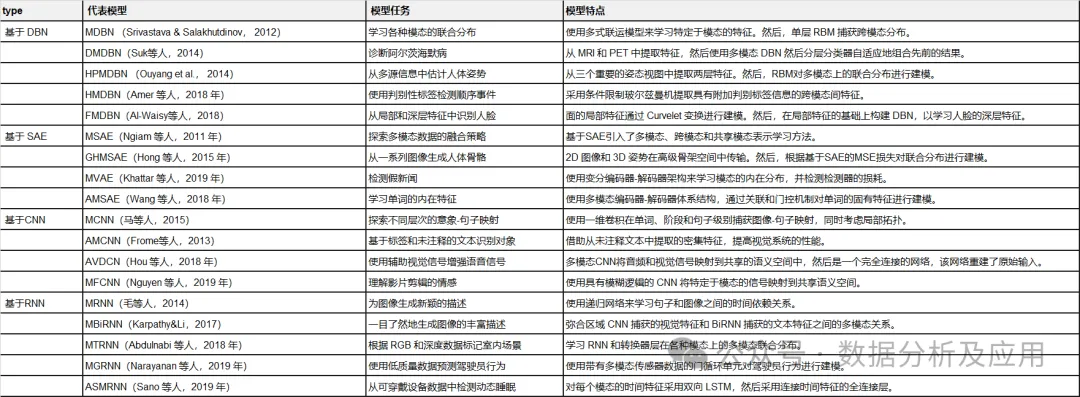
Jedes Modul des vorgeschlagenen multimodalen DBN wird unüberwacht Schicht für Schicht initialisiert, und für das Modelltraining wird eine MCMC-basierte Näherungsmethode verwendet.
Um die erlernte multimodale Darstellung zu bewerten, wird eine große Anzahl von Aufgaben ausgeführt, z. B. das Generieren fehlender modaler Aufgaben, das Ableiten gemeinsamer Darstellungsaufgaben und diskriminierende Aufgaben. Experimente überprüfen, ob die erlernte multimodale Darstellung die erforderlichen Eigenschaften erfüllt.
3.1.2 Beispiel 2
Um die Alzheimer-Krankheit effektiv in einem frühen Stadium zu diagnostizieren, haben Suk, Lee, Shen und die Alzheimer’s Disease Neuroimaging Initiative (2014) ein multimodales Glas-Erzmann-Modell vorgeschlagen, das komplementäres Wissen zusammenführen kann in multimodalen Daten. Um insbesondere die durch Methoden zum Lernen flacher Merkmale verursachten Einschränkungen zu beseitigen, wird DBN verwendet, um tiefe Darstellungen jeder Modalität zu lernen, indem domänenspezifische Darstellungen in hierarchische abstrakte Darstellungen übertragen werden. Anschließend wird ein einschichtiges RBM auf verketteten Vektoren erstellt, bei denen es sich um lineare Kombinationen hierarchischer abstrakter Darstellungen jeder Modalität handelt. Es wird verwendet, um multimodale Darstellungen zu lernen, indem eine gemeinsame Verteilung verschiedener multimodaler Merkmale erstellt wird. Abschließend wird das vorgeschlagene Modell umfassend anhand des ADNI-Datensatzes auf der Grundlage von drei typischen Diagnosen evaluiert, wodurch eine Diagnosegenauigkeit auf dem neuesten Stand der Technik erreicht wird. 3.1.3 Beispiel 3 Lernen Sie multimodale Darstellungen aus gemischten Typen, Darstellungswerten und deformierten Modalitäten. Im Multi-Source-Tiefenmodell der menschlichen Pose werden drei weit verbreitete Modalitäten aus Bildstrukturmodellen extrahiert, die Körperteile basierend auf der bedingten Zufallsfeldtheorie kombinieren. Um multimodale Daten zu erhalten, wird das grafische Strukturmodell über eine lineare Support-Vektor-Maschine trainiert. Jedes der drei Merkmale wird dann in ein zweischichtiges eingeschränktes Boltzmann-Modell eingespeist, um aus einer merkmalsspezifischen Darstellung eine abstrakte Darstellung des Posenraums höherer Ordnung zu erfassen. Durch unbeaufsichtigte Initialisierung erfasst jedes modalitätsspezifische eingeschränkte Boltzmann-Modell eine intrinsische Darstellung des globalen Raums. Anschließend wird RBM verwendet, um die Darstellung menschlicher Posen basierend auf verketteten Vektoren von Mischtypen auf hoher Ebene, Darstellungswerten und Verformungsdarstellungen weiter zu erlernen. Um das vorgeschlagene Multi-Source-Deep-Learning-Modell zu trainieren, wird eine aufgabenspezifische Zielfunktion entworfen, die sowohl die Körperposition als auch die Erkennung von Menschen berücksichtigt. Das vorgeschlagene Modell ist auf LSP, PARSE und UIUC validiert und führt zu Verbesserungen von bis zu 8,6 %.
Kürzlich wurden einige neue DBN-basierte multimodale Feature-Lernmodelle vorgeschlagen. Beispielsweise schlugen Amer, Shields, Siddiquie und Tamrakar (2018) einen Hybridansatz für die sequentielle Ereigniserkennung vor, bei dem bedingtes RBM eingesetzt wurde, um modale und modalübergreifende Merkmale mit zusätzlichen diskriminierenden Label-Informationen zu extrahieren. Al-Waisy, Qahwaji, Ipson und Al-Fahdawi (2018) führten einen multimodalen Ansatz zur Gesichtserkennung ein. Bei diesem Ansatz wird ein DBN-basiertes Modell verwendet, um die multimodale Verteilung lokaler handgefertigter Features zu modellieren, die durch Curvelet-Transformation erfasst werden, wodurch die Vorteile lokaler Features und tiefer Features kombiniert werden können (Al-Waisy et al., 2018).
3.1.4 Zusammenfassung
Diese DBN-basierten multimodalen Modelle verwenden probabilistische Graphnetzwerke, um modalitätsspezifische Darstellungen in semantischen Merkmalen in einem gemeinsamen Raum umzuwandeln. Anschließend wird die gemeinsame Verteilung über die Modalitäten basierend auf den Eigenschaften des gemeinsam genutzten Raums modelliert. Diese DBN-basierten multimodalen Modelle sind flexibler und robuster bei unbeaufsichtigten, halbüberwachten und überwachten Lernstrategien. Sie eignen sich ideal zur Erfassung informativer Merkmale von Eingabedaten. Sie ignorieren jedoch die räumliche und zeitliche Topologie multimodaler Daten.
3.2 Multimodale Datenfusion basierend auf gestapelten Autoencodern
3.2.1 Beispiel 4
Ngiam et al. (2011) schlugen multimodales Deep Learning basierend auf gestapelten Autoencodern (SAE) vor. Das repräsentativste Deep Learning Modell zur multimodalen Datenfusion. Dieses Deep-Learning-Modell zielt darauf ab, zwei Datenfusionsprobleme zu lösen: modalübergreifendes und gemeinsam genutztes modales Repräsentationslernen. Ersteres zielt darauf ab, Wissen aus anderen Modalitäten zu nutzen, um bessere Einzelmodaldarstellungen zu erfassen, während letzteres komplexe Korrelationen zwischen Modalitäten auf mittlerer Ebene erlernt. Um diese Ziele zu erreichen, werden drei Lernszenarien – multimodales, modalübergreifendes und gemeinsam genutztes modales Lernen – entworfen, wie in Tabelle 3 und Abbildung 6 dargestellt.
Abbildung 6:
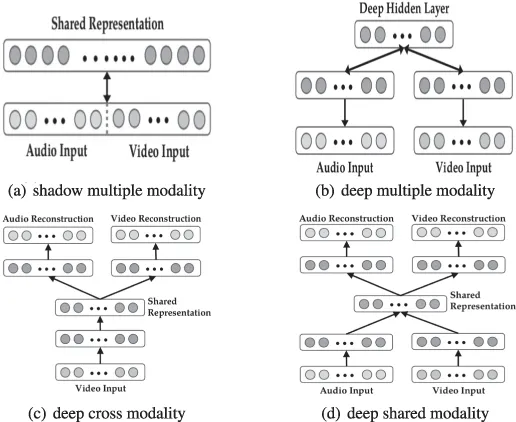 Architektur für multimodales, modalübergreifendes und gemeinsames modales Lernen.
Architektur für multimodales, modalübergreifendes und gemeinsames modales Lernen.
Tabelle 3: Einstellungen für multimodales Lernen.
In multimodalen Lernszenarien werden Audiospektrogramme und Videobilder linear zu Vektoren verbunden. Die verketteten Vektoren werden in eine Sparse Restricted Boltzmann Machine (SRBM) eingespeist, um die Korrelation zwischen Audio und Video zu lernen. Dieses Modell kann nur Schattengelenkdarstellungen mehrerer Modalitäten lernen, da die Korrelationen in der hochdimensionalen Darstellung der ursprünglichen Ebene implizit sind und einschichtiges SRBM sie nicht modellieren kann. Davon inspiriert werden verkettete Vektoren von Darstellungen mittlerer Ebene in SRBM eingegeben, um die Korrelation mehrerer Modalitäten zu modellieren und so eine bessere Leistung zu erzielen.
Im modalübergreifenden Lernszenario wird ein tief gestapelter multimodaler Autoencoder vorgeschlagen, um die Korrelation zwischen Modalitäten explizit zu lernen. Insbesondere werden sowohl Audio als auch Video als Eingaben beim Feature-Learning präsentiert, und nur eine davon wird beim überwachten Training und Testen in das Modell eingegeben. Das Modell wird auf multimodale Lernweise initialisiert und kann modalübergreifende Beziehungen gut simulieren.
In der geteilten Modaldarstellung, motiviert durch Entrauschen von Autoencodern, werden modalitätsspezifische, tief gestapelte multimodale Autoencoder eingeführt, um gemeinsame Darstellungen zwischen Modalitäten zu untersuchen, insbesondere wenn ein Modal fehlt. Der durch Ersetzen einer der Modalitäten durch Null vergrößerte Trainingsdatensatz wird zum Feature-Learning in das Modell eingespeist.
Abschließend werden detaillierte Experimente mit CUAVE- und AVLetters-Datensätzen durchgeführt, um die Leistung von multimodalem Deep Learning beim aufgabenspezifischen Feature-Learning zu bewerten.
3.2.2 Beispiel 5
Um aus einer Reihe von Bildern (insbesondere Videos) visuell und semantisch wirksame menschliche Skelette zu generieren, schlugen Hong, Yu, Wan, Tao und Wang (2015) einen multimodalen tiefen Autoencoder vor Erfassen Sie die Fusionsbeziehung zwischen Bildern und Posen. Insbesondere wird der vorgeschlagene multimodale Deep-Autoencoder durch eine dreistufige Strategie trainiert, um eine nichtlineare Zuordnung zwischen 2D-Bildern und 3D-Posen zu erstellen. In der Feature-Fusion-Phase wird die Multi-View-Hypergraph-Low-Rank-Darstellung genutzt, um auf der Grundlage vielfältigen Lernens eine interne 2D-Darstellung aus einer Reihe von Bildmerkmalen (z. B. orientierten Gradientenhistogrammen und Formkontext) zu erstellen. In der zweiten Stufe wird ein einschichtiger Autoencoder darauf trainiert, eine abstrakte Darstellung zu lernen, die zur Wiederherstellung der 3D-Pose durch Rekonstruktion von 2D-Zwischenbildmerkmalen verwendet wird. In der Zwischenzeit wird ein einschichtiger Autoencoder auf ähnliche Weise trainiert, um abstrakte Darstellungen von 3D-Posen zu lernen. Nachdem die abstrakte Darstellung jeder einzelnen Modalität erhalten wurde, wird ein neuronales Netzwerk verwendet, um die multimodale Korrelation zwischen 2D-Bildern und 3D-Posen zu lernen, indem der quadrierte euklidische Abstand zwischen den beiden modalen gegenseitigen Darstellungen minimiert wird. Das Lernen des vorgeschlagenen multimodalen Deep-Autoencoders besteht aus Initialisierungs- und Feinabstimmungsphasen. Bei der Initialisierung werden die Parameter jedes Unterteils des multimodalen tiefen Autoencoders vom entsprechenden Autoencoder und neuronalen Netzwerk kopiert. Anschließend werden die Parameter des gesamten Modells durch einen stochastischen Gradientenabstiegsalgorithmus weiter verfeinert, um aus dem entsprechenden zweidimensionalen Bild eine dreidimensionale Pose zu erstellen.
3.2.3 Zusammenfassung
Das auf SAE basierende multimodale Modell verwendet eine Encoder-Decoder-Architektur, um intrinsische modale Merkmale und modalübergreifende Merkmale durch Rekonstruktionsmethoden auf unbeaufsichtigte Weise zu extrahieren. Da sie auf SAE basieren, einem vollständig vernetzten Modell, müssen viele Parameter trainiert werden. Darüber hinaus ignorieren sie die räumliche und zeitliche Topologie in multimodalen Daten.
3.3 Multimodale Datenfusion basierend auf einem Faltungs-Neuronalen Netzwerk
3.3.1 Beispiel 6
Um die semantische Zuordnungsverteilung zwischen Bildern und Sätzen zu simulieren, haben Ma, Lu, Shang und Li (2015) schlug ein multimodales Faltungs-Neuronales Netzwerk vor. Um die semantische Relevanz vollständig zu erfassen, wird in der End-to-End-Architektur eine dreistufige Fusionsstrategie – Wortebene, Bühnenebene und Satzebene – entworfen. Die Architektur besteht aus einem Imaging-Subnetz, einem passenden Subnetz und einem multimodalen Subnetz. Das Bildsubnetz ist ein repräsentatives tiefes Faltungs-Neuronales Netzwerk wie Alexnet und Inception, das Bildeingaben effizient in prägnante Darstellungen kodiert. Das passende Teilnetzwerk modelliert gemeinsame Darstellungen, die Bildinhalte mit Wortfragmenten von Sätzen im semantischen Raum in Beziehung setzen.
3.3.2 Beispiel 7
Um das visuelle Erkennungssystem auf eine unbegrenzte Anzahl diskreter Kategorien zu erweitern, schlugen Frome et al. (2013) ein multimodales Faltungs-Neuronales Netzwerk vor, indem sie die semantischen Informationen in Textdaten ausnutzten . Netzwerk. Das Netzwerk besteht aus einem Sprachuntermodell und einem visuellen Untermodell. Das Sprachuntermodell basiert auf dem Skip-Gram-Modell, das Textinformationen in eine dichte Darstellung des semantischen Raums übertragen kann. Das visuelle Untermodell ist ein repräsentatives Faltungs-Neuronales Netzwerk wie Alexnet, das auf dem ImageNet-Datensatz der 1000er-Klasse vorab trainiert wurde, um visuelle Merkmale zu erfassen. Um die semantische Beziehung zwischen Bildern und Text zu modellieren, werden Sprache und visuelle Teilmodelle durch lineare Projektionsebenen kombiniert. Jedes Untermodell wird mit Parametern für jede Modalität initialisiert. Um dieses visuell-semantische multimodale Modell zu trainieren, wird anschließend eine neue Verlustfunktion vorgeschlagen, die hohe Ähnlichkeitswerte für korrekte Bild- und Etikettenpaare liefern kann, indem sie Skalarproduktähnlichkeit und Scharnierrangverlust kombiniert. Das Modell bietet eine hochmoderne Leistung für den ImageNet-Datensatz und vermeidet semantisch unplausible Ergebnisse.
3.3.3 Zusammenfassung
Auf CNN basierende multimodale Modelle können lokale multimodale Merkmale zwischen Modalitäten durch lokale Felder und Pooling-Operationen lernen. Sie modellieren explizit die räumliche Topologie multimodaler Daten. Und es handelt sich nicht um vollständig verbundene Modelle mit einer stark reduzierten Anzahl von Parametern.
3.4 Multimodale Datenfusion basierend auf einem wiederkehrenden neuronalen Netzwerk
3.4.1 Beispiel 8
Um Bildunterschriften zu generieren, schlugen Mao et al. (2014) eine multimodale wiederkehrende neuronale Architektur vor. Dieses multimodale rekurrente neuronale Netzwerk kann probabilistische Korrelationen zwischen Bildern und Sätzen überbrücken. Es behebt die Einschränkung früherer Arbeiten, die keine neuen Bildunterschriften generieren können, da sie entsprechende Bildunterschriften in einer Satzdatenbank auf der Grundlage erlernter Bild-Text-Zuordnungen abrufen. Im Gegensatz zu früheren Arbeiten lernen multimodale rekurrente neuronale Modelle (MRNN) gemeinsame Verteilungen über den semantischen Raum anhand von Wörtern und Bildern. Wenn ein Bild präsentiert wird, generiert es wörtlich Sätze basierend auf der erfassten gemeinsamen Verteilung. Insbesondere besteht das multimodale rekurrente neuronale Netzwerk aus einem Sprachsubnetz, einem visuellen Subnetz und einem multimodalen Subnetz, wie in Abbildung 7 dargestellt. Das Sprachsubnetzwerk besteht aus einem zweischichtigen Worteinbettungsteil, der effiziente aufgabenspezifische Darstellungen erfasst, und einem einschichtigen wiederkehrenden neuronalen Teil, der die zeitliche Abhängigkeit von Sätzen modelliert. Das Vision-Subnetz ist im Wesentlichen ein tiefes Faltungs-Neuronales Netzwerk wie Alexnet, Resnet oder Inception, das hochdimensionale Bilder in kompakte Darstellungen kodiert. Schließlich ist das multimodale Subnetzwerk ein verstecktes Netzwerk, das die gemeinsame semantische Verteilung gelernter Sprache und visueller Darstellungen modelliert.
Abbildung 7:
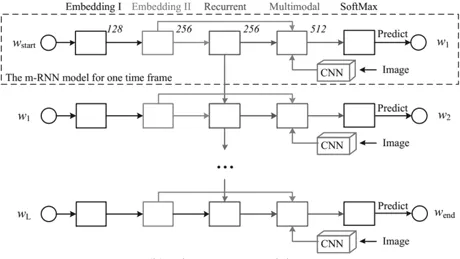
3.4.2 Beispiel 9
Um die Einschränkung aktueller visueller Erkennungssysteme zu lösen, die keine umfassenden Beschreibungen von Bildern auf einen Blick generieren können, haben wir ein Modell von vorgeschlagen Um das Modell zwischen visuellen und textuellen Daten zu überbrücken, wird ein multimodales Ausrichtungsmodell vorgeschlagen (Karpathy & Li, 2017). Um dies zu erreichen, wurde ein duales System vorgeschlagen. Zunächst wird ein visuelles semantisches Einbettungsmodell entwickelt, um multimodale Trainingsdatensätze zu generieren. Anhand dieses Datensatzes wird dann ein multimodales RNN trainiert, um ausführliche Bildbeschreibungen zu generieren.
Im visuellen semantischen Einbettungsmodell werden regionale Faltungs-Neuronale Netze verwendet, um reichhaltige Bilddarstellungen zu erhalten, die ausreichend Informationen für den den Sätzen entsprechenden Inhalt enthalten. Anschließend wird ein bidirektionales RNN verwendet, um jeden Satz in einen dichten Vektor mit den gleichen Abmessungen wie die Bilddarstellung zu kodieren. Darüber hinaus wird eine multimodale Bewertungsfunktion vorgestellt, um die semantische Ähnlichkeit zwischen Bildern und Sätzen zu messen. Schließlich wird die Markov-Zufallsfeldmethode zur Generierung multimodaler Datensätze verwendet.
Im multimodalen RNN wird ein effektiveres erweitertes Modell vorgeschlagen, das auf Textinhalten und Bildeingaben basiert. Das multimodale Modell besteht aus einem Faltungs-Neuronalen Netzwerk, das Bildeingaben kodiert, und einem RNN, das Bildmerkmale und Sätze kodiert. Das Modell wird auch über den stochastischen Gradientenabstiegsalgorithmus trainiert. Beide multimodalen Modelle werden umfassend anhand der Flickr- und Mscoco-Datensätze evaluiert und erreichen eine Leistung auf dem neuesten Stand der Technik.
3.4.3 Zusammenfassung
Das auf RNN basierende multimodale Modell kann die in multimodalen Daten verborgene Zeitabhängigkeit mithilfe der expliziten Zustandsübertragung in der Berechnung versteckter Einheiten analysieren. Sie verwenden einen zeitlichen Backpropagation-Algorithmus, um die Parameter zu trainieren. Da die Berechnung in versteckten Zustandsübertragungen erfolgt, ist eine Parallelisierung auf Hochleistungsgeräten schwierig.
4. Zusammenfassung und Ausblick
Wir fassen das Modell in vier Gruppen multimodaler Daten-Deep-Learning-Modelle basierend auf DBN, SAE, CNN und RNN zusammen. Diese bahnbrechenden Modelle haben bereits zu einigen Fortschritten geführt. Allerdings befinden sich diese Modelle noch im Anfangsstadium, sodass weiterhin Herausforderungen bestehen.
Erstens gibt es im multimodalen Datenfusions-Deep-Learning-Modell eine große Anzahl freier Gewichte, insbesondere redundante Parameter, die kaum Einfluss auf die Zielaufgabe haben. Um diese Parameter zu trainieren, die die charakteristische Struktur der Daten erfassen, wird eine große Datenmenge in ein multimodales Deep-Learning-Modell zur Datenfusion eingegeben, das auf dem Backpropagation-Algorithmus basiert, was rechenintensiv und zeitaufwändig ist. Daher ist auch die Gestaltung neuer multimodaler Deep-Learning-Komprimierungsmethoden in Kombination mit bestehenden Komprimierungsstrategien eine mögliche Forschungsrichtung.
Zweitens enthalten multimodale Daten nicht nur modalübergreifende Informationen, sondern auch umfangreiche modalübergreifende Informationen. Daher könnte die Kombination von Deep-Learning- und semantischen Fusionsstrategien eine Möglichkeit sein, die Herausforderungen zu bewältigen, die sich aus der Erforschung multimodaler Daten ergeben. Drittens werden multimodale Daten aus dynamischen Umgebungen gesammelt, was zeigt, dass die Daten unsicher sind. Daher muss mit dem explosionsartigen Wachstum dynamischer multimodaler Daten das Designproblem von Online- und inkrementellen multimodalen Deep-Learning-Modellen für die Datenfusion gelöst werden.
Das obige ist der detaillierte Inhalt vonZu vollständig! Ein Rückblick auf multimodales Deep Learning!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Winziges maschinelles Lernen verspricht, Deep Learning in Mikroprozessoren zu integrieren
- Die richtige Art, Deep Learning aus Bausteinen zu spielen! Die National University of Singapore veröffentlicht DeRy, ein neues Transfer-Lernparadigma, das den Wissenstransfer in den Druck mit beweglichen Lettern umwandelt
- wie man LSP repariert
- Was ist eine Subnetzmaske?