
Heim >Technologie-Peripheriegeräte >KI >Mambas hochentwickelte Form untergräbt Transformer auf einen Schlag! Einzelner A100 mit 140 KB-Kontext
Mambas hochentwickelte Form untergräbt Transformer auf einen Schlag! Einzelner A100 mit 140 KB-Kontext

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-29 15:11:18884Durchsuche
Die Mamba-Architektur, die zuvor den KI-Kreis zum Explodieren gebracht hat, hat heute eine Supervariante auf den Markt gebracht!
Das Einhorn der künstlichen Intelligenz AI21 Labs hat gerade Jamba als Open Source veröffentlicht, das weltweit erste Mamba-Großmodell in Produktionsqualität!

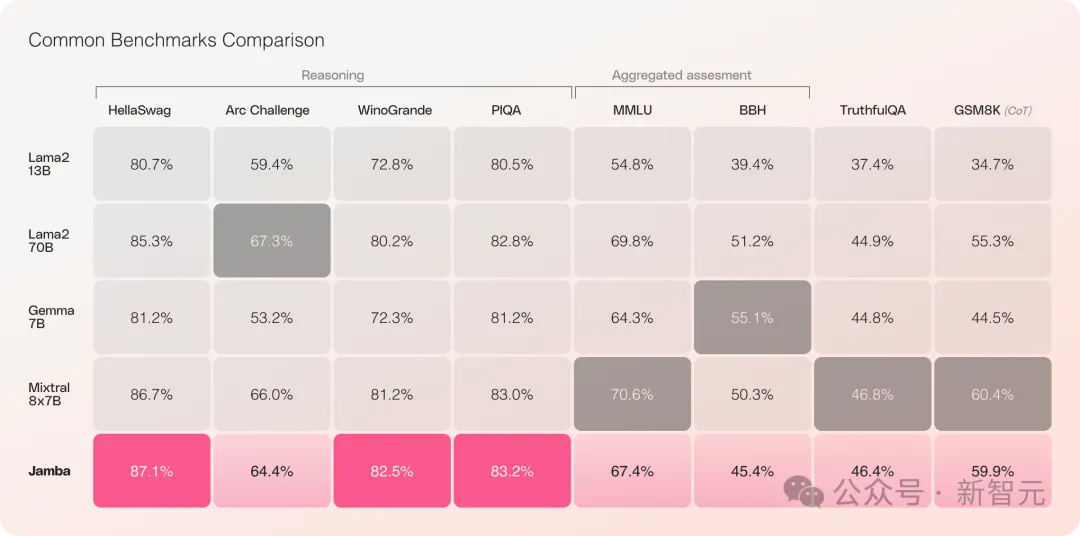
Jamba hat in mehreren Benchmark-Tests gut abgeschnitten und liegt auf Augenhöhe mit einigen der derzeit stärksten Open-Source-Transformer.
Gerade beim Vergleich von Mixtral 8x7B, der die beste Leistung hat und zudem eine MoE-Architektur ist, gibt es auch Gewinner und Verlierer.
Konkret:
- ist das erste Mamba-Modell in Produktionsqualität, das auf der neuen SSM-Transformer-Hybridarchitektur basiert.
- Im Vergleich zu Mixtral 8x7B ist der Durchsatz bei der Langtextverarbeitung um das Dreifache erhöht
- Erreicht 256K ultralanges Kontextfenster
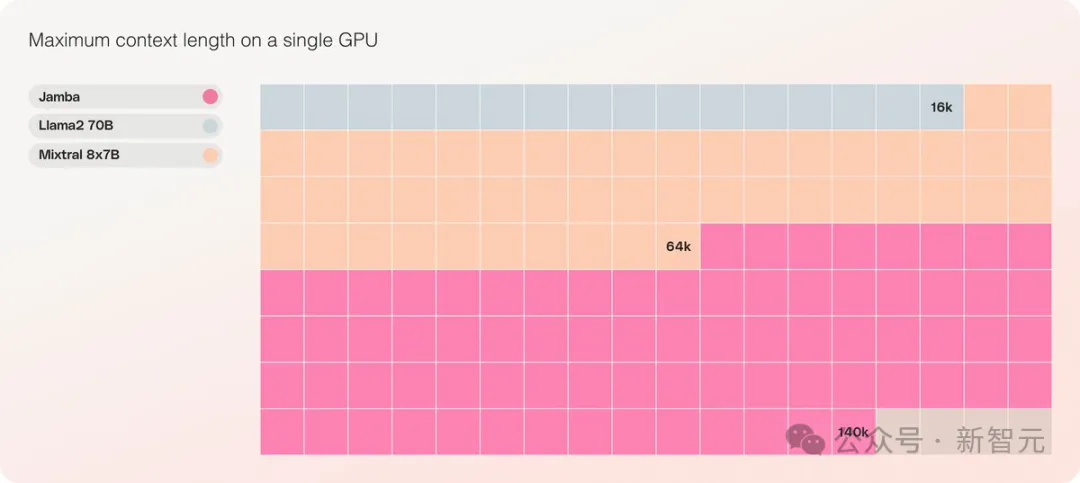
- Es ist das einzige Modell der gleichen Größenordnung, das 140K Kontext auf einer einzigen GPU verarbeiten kann
- Veröffentlicht unter der Open-Source-Lizenzvereinbarung Apache 2.0, mit offenen Rechtenschwer
Aufgrund verschiedener Einschränkungen konnte der bisherige Mamba nur 3B erreichen. Es wurde auch in Frage gestellt, ob er das Banner von Transformer RWKV, Griffin usw. übernehmen konnte, die ebenfalls lineare RNN-Familien sind erweitert auf 14B.
——Jamba ging dieses Mal direkt zu 52B, wodurch die Mamba-Architektur zum ersten Mal direkt mit dem Transformer auf Produktionsebene konkurrieren konnte.

Jamba basiert auf der ursprünglichen Mamba-Architektur und integriert die Vorteile von Transformer, um die inhärenten Einschränkungen des State Space Model (SSM) auszugleichen.
Man kann davon ausgehen, dass es sich tatsächlich um eine neue Architektur handelt – einen Hybrid aus Transformer und Mamba, und das Wichtigste ist, dass sie auf einem einzigen A100 laufen kann.
Es bietet ein extrem langes Kontextfenster von bis zu 256 KB, eine einzelne GPU kann 140 KB Kontext ausführen und der Durchsatz ist dreimal so hoch wie der von Transformer!
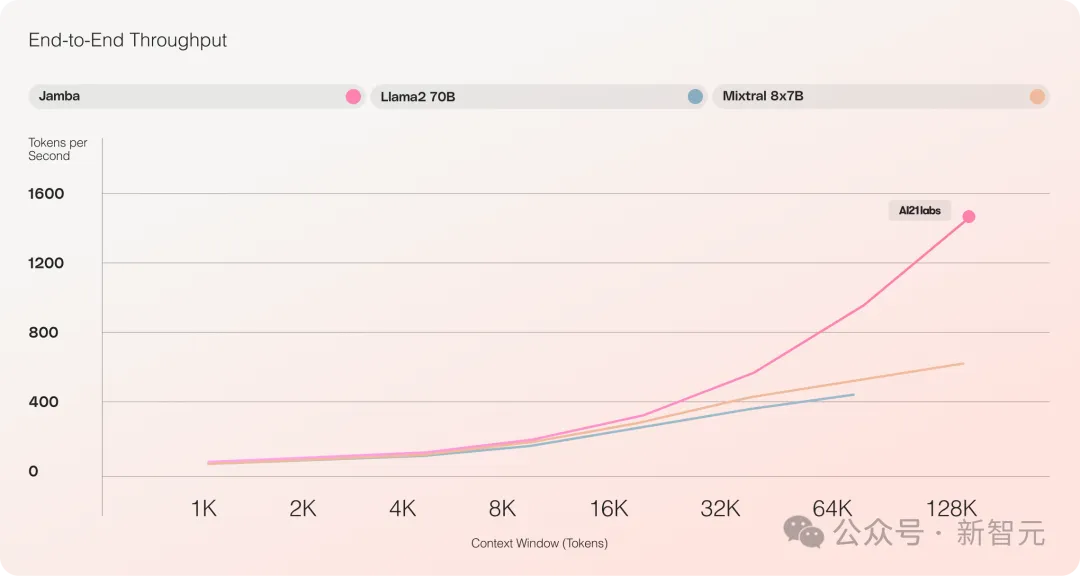
Im Vergleich zu Transformer ist es sehr schockierend zu sehen, wie Jamba auf große Kontextlängen skaliert.
Jamba übernimmt die MoE-Lösung, 12B von 52B sind aktive Parameter und das Modell ist derzeit unter Apache 2.0 geöffnet Gewichte können von Huggingface heruntergeladen werden.

Modell-Download: https://huggingface.co/ai21labs/Jamba-v0.1
Neuer LLM-Meilenstein
Die Veröffentlichung von Jamba markiert zwei wichtige Meilensteine für LLM:
Erstens wurde Mamba erfolgreich mit der Transformer-Architektur kombiniert und zweitens wurde die neue Modellform (SSM-Transformer) erfolgreich auf Produktionsmaßstab und -qualität aktualisiert.
Die aktuellen großen Modelle mit der stärksten Leistung basieren alle auf Transformer, obwohl jeder auch die beiden Hauptmängel der Transformer-Architektur erkannt hat:
Großer Speicherbedarf: Der Speicherbedarf von Transformer variiert mit der Kontextlänge Und expandieren. Das Ausführen langer Kontextfenster oder eine massiv parallele Stapelverarbeitung erfordert viele Hardwareressourcen, was umfangreiche Experimente und Bereitstellungen einschränkt.
Wenn der Kontext wächst, verlangsamt sich die Inferenzgeschwindigkeit: Der Aufmerksamkeitsmechanismus von Transformer führt dazu, dass die Inferenzzeit im Verhältnis zur Sequenzlänge quadratisch zunimmt und der Durchsatz immer langsamer wird. Da jedes Token von der gesamten Sequenz davor abhängt, wird es ziemlich schwierig, sehr lange Kontexte zu erreichen.
Vor ein paar Jahren schlugen zwei große Jungs aus Carnegie Mellon und Princeton Mamba vor, was sofort die Hoffnungen der Menschen weckte.
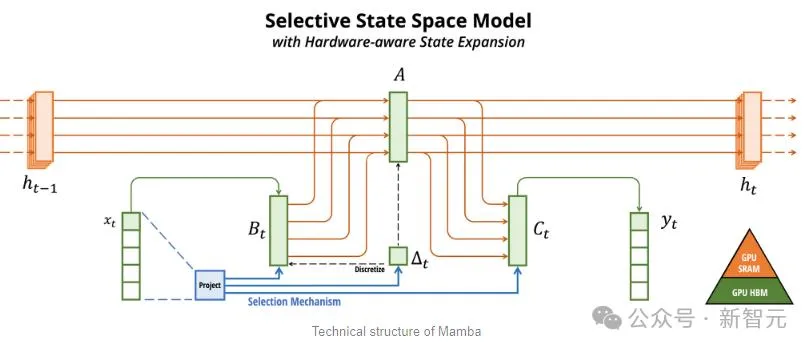
Mamba basiert auf SSM, bietet die Möglichkeit, Informationen selektiv zu extrahieren, und effiziente Algorithmen auf der Hardware, wodurch die Probleme von Transformer auf einen Schlag gelöst werden.
Dieses neue Gebiet zog sofort eine große Anzahl von Forschern an, und auf arXiv entstanden zahlreiche Mamba-Anwendungen und -Verbesserungen, wie beispielsweise Vision Mamba, das Mamba für das Sehen verwendet.
Ich muss sagen, dass das aktuelle wissenschaftliche Forschungsfeld wirklich zu beschäftigt ist. Es hat drei Jahre gedauert, Transformer in Vision (ViT) einzuführen, aber von Mamba bis Vision Mamba hat es nur einen Monat gedauert.
Allerdings ist die Kontextlänge der ursprünglichen Mamba kürzer und das Modell selbst wird nicht vergrößert, sodass es schwierig ist, das SOTA Transformer-Modell zu schlagen, insbesondere bei Aufgaben im Zusammenhang mit dem Rückruf.
Jamba geht dann noch einen Schritt weiter und integriert die Vorteile von Transformer, Mamba und Mix of Experts (MoE) durch die Joint Attention- und Mamba-Architektur und optimiert gleichzeitig Speicher, Durchsatz und Leistung.

Jamba ist die erste Hybridarchitektur, die den Produktionsmaßstab erreicht (52B-Parameter).
Wie in der folgenden Abbildung dargestellt, verfolgt die Jamba-Architektur von AI21 einen Block-und-Schichten-Ansatz, der es Jamba ermöglicht, die beiden Architekturen erfolgreich zu integrieren.
Jeder Jamba-Block besteht aus einer Aufmerksamkeitsschicht oder einer Mamba-Schicht, gefolgt von einem mehrschichtigen Perzeptron (MLP).
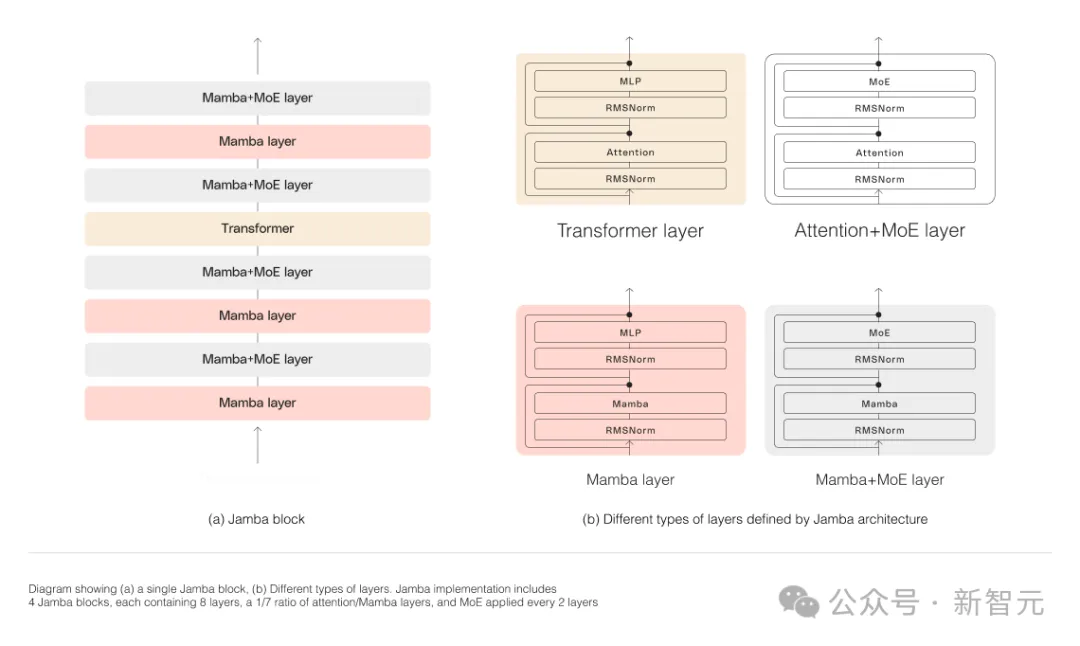
Die zweite Funktion von Jamba besteht darin, MoE zu verwenden, um die Gesamtzahl der Modellparameter zu erhöhen und gleichzeitig die Anzahl der aktiven Parameter, die in der Inferenz verwendet werden, zu vereinfachen, wodurch die Modellkapazität erhöht wird, ohne den Rechenaufwand zu erhöhen.
Um die Modellqualität und den Durchsatz auf einer einzelnen 80-GB-GPU zu maximieren, optimierten die Forscher die Anzahl der verwendeten MoE-Schichten und Experten, sodass genügend Speicher für gängige Inferenz-Workloads übrig blieb.
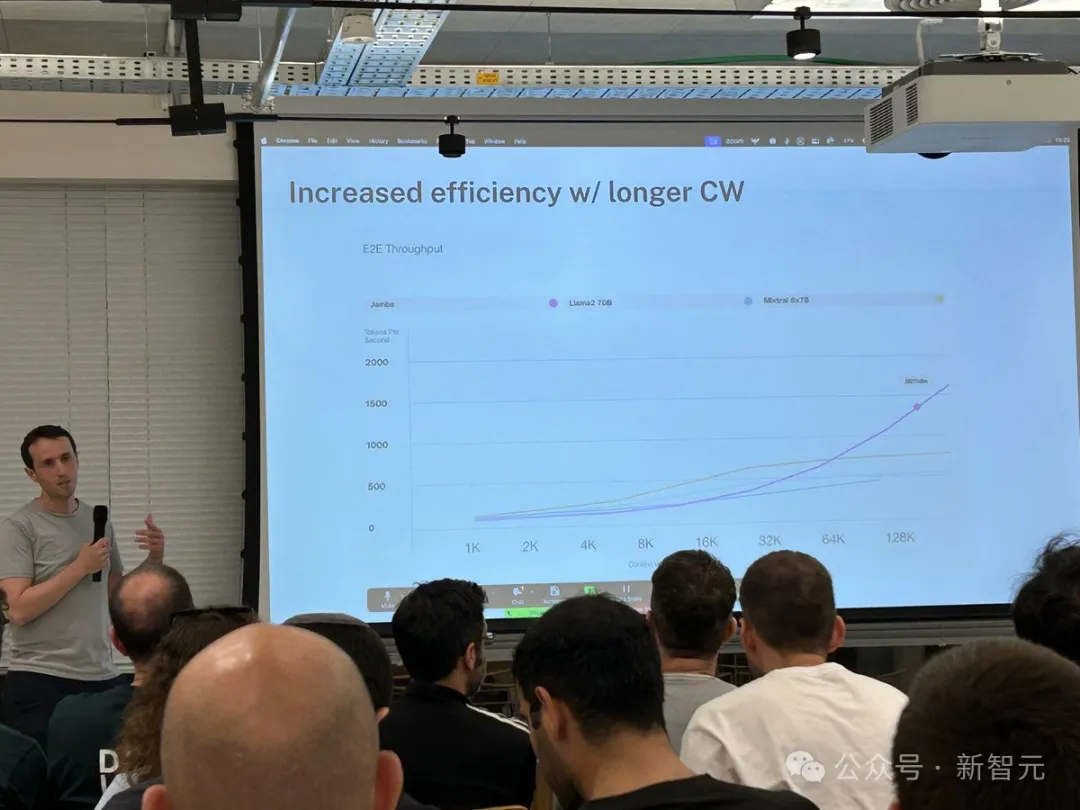
Im Vergleich zu Transformer-basierten Modellen ähnlicher Größe wie Mixtral 8x7B erreichte Jamba bei langen Kontexten eine dreifache Beschleunigung.
Jamba wird bald zum NVIDIA API-Verzeichnis hinzugefügt.
Es gibt einen neuen Player im Long-Context
Vor kurzem führen große Unternehmen Long-Context ein.
Modelle mit kleineren Kontextfenstern neigen dazu, den Inhalt aktueller Gespräche zu vergessen, während Modelle mit größerem Kontext diese Falle vermeiden und den Datenstrom, den sie empfangen, besser erfassen können.
Modelle mit langen Kontextfenstern sind jedoch tendenziell rechenintensiv.
Das generative Modell des Startups AI21 Labs beweist, dass dies nicht der Fall ist.

Jamba kann bis zu 140.000 Token verarbeiten, wenn es auf einer einzelnen GPU (z. B. einer A100) mit mindestens 80 GB Videospeicher ausgeführt wird.
Das entspricht etwa 105.000 Wörtern oder 210 Seiten, was der Länge eines mittellangen Romans entspricht.
Im Vergleich dazu verfügt das Kontextfenster von Meta Llama 2 nur über 32.000 Token und erfordert 12 GB GPU-Speicher.
Nach heutigen Maßstäben ist dieses Kontextfenster offensichtlich klein.
In diesem Zusammenhang sagten einige Internetnutzer sofort, dass die Leistung nicht wichtig sei. Der Schlüssel sei, dass Jamba einen 256-KByte-Kontext habe, außer Gemini sei niemand so lang – und Jamba sei Open Source.
Was Jamba wirklich einzigartig macht
Oberflächlich betrachtet mag Jamba unscheinbar wirken.
Ob DBRX oder Llama 2, das gestern im Rampenlicht stand, mittlerweile gibt es eine große Anzahl kostenloser und herunterladbarer generativer KI-Modelle.
Die Einzigartigkeit von Jamba verbirgt sich unter dem Modell: Es kombiniert zwei Modellarchitekturen gleichzeitig – Transformer und State Space Model SSM.
Einerseits ist Transformer die bevorzugte Architektur für komplexe Argumentationsaufgaben. Sein zentrales definierendes Merkmal ist der „Aufmerksamkeitsmechanismus“. Für jedes Eingabedatenelement wägt der Transformer die Relevanz aller anderen Eingaben ab und extrahiert daraus, um die Ausgabe zu generieren.
Andererseits kombiniert SSM viele Vorteile früherer KI-Modelle, wie etwa rekurrente neuronale Netze und Faltungs-Neuronale Netze, sodass es lange Sequenzdaten mit höherer Recheneffizienz verarbeiten kann.
Obwohl SSM seine eigenen Einschränkungen hat. Aber einige frühe Vertreter, wie z. B. Mamba, vorgeschlagen von Princeton und CMU, können größere Ausgaben verarbeiten als das Transformer-Modell und sind bei Sprachgenerierungsaufgaben besser.
In diesem Zusammenhang sagte Dagan, Produktleiter von AI21 Labs:
Obwohl es einige vorläufige Beispiele für SSM-Modelle gibt, ist Jamba das erste kommerzielle Modell im Produktionsmaßstab.
Jamba ist seiner Ansicht nach nicht nur innovativ und interessant für die Community, um es weiter zu studieren, sondern bietet auch enorme Effizienz- und Durchsatzmöglichkeiten.
Derzeit wird Jamba unter der Apache 2.0-Lizenz veröffentlicht, die weniger Nutzungsbeschränkungen hat, aber nicht kommerziell genutzt werden kann. Nachfolgende, verfeinerte Versionen werden voraussichtlich innerhalb weniger Wochen auf den Markt kommen.
Auch wenn die Forschung noch am Anfang steht, versichert Dagan, dass Jamba zweifellos das große Versprechen der SSM-Architektur zeigt.
„Der Mehrwert dieses Modells – sowohl aufgrund der Größe als auch der architektonischen Innovation – lässt sich problemlos auf einer einzigen GPU unterbringen
Das obige ist der detaillierte Inhalt vonMambas hochentwickelte Form untergräbt Transformer auf einen Schlag! Einzelner A100 mit 140 KB-Kontext. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Praktisches Schulungsvideo-Tutorial zum funktionalen Design von Java-Softwaresystemen
- Die offizielle Ankündigung des Haimo Supercomputing Center: ein großes Modell mit 100 Milliarden Parametern, einer Datenskala von 1 Million Clips und einer 200-fachen Reduzierung der Trainingskosten
- Bei der diesjährigen Aufnahmeprüfung für das Englische College nutzte die CMU ein Rekonstruktions-Vortraining, um eine hohe Punktzahl von 134 zu erreichen und damit GPT3 deutlich zu übertreffen
- Zurück in die Zukunft! Dieser Programmierer nutzte Kindheitstagebücher zum Trainieren der KI und nutzte GPT-3, um einen Dialog mit seinem „vergangenen Ich' zu erreichen.
- Nutzen Sie die Vision, um zu motivieren! Shen Xiangyang stellte das neue Modell des IDEA Research Institute vor, das weder Schulung noch Feinabstimmung erfordert und sofort einsatzbereit ist.