
Heim >Technologie-Peripheriegeräte >KI >Wie können industrielle Anwendungen durch maschinelles Lernen unterstützt werden?
Wie können industrielle Anwendungen durch maschinelles Lernen unterstützt werden?

- 王林nach vorne
- 2024-03-26 12:16:02958Durchsuche
Geräteausfälle stellen den Industriesektor vor ernsthafte Probleme und führen zu Produktionsausfällen und ungeplanten Ausfallzeiten. Diese Situation stellt für Prozesshersteller weltweit eine ernsthafte Herausforderung dar und verursacht Verluste, die sich jährlich auf Milliarden von Dollar belaufen können. Wenn beispielsweise eine wichtige Produktionsanlage plötzlich ausfällt, kann dies dazu führen, dass die gesamte Produktionslinie für mehrere Stunden stillsteht und somit der Betrieb der gesamten Lieferkette beeinträchtigt wird.

Glücklicherweise bietet modernes maschinelles Lernen (ML) eine bahnbrechende Lösung. Durch die Analyse großer Mengen an Sensordaten können ML-Algorithmen Ausfälle und Rückstände vorhersagen, bevor sie auftreten, was proaktive Reparaturen ermöglicht und Ausfallzeiten erheblich reduziert. Aber das ist noch nicht alles: ML deckt auch verborgene Muster in Produktionsdaten auf, optimiert Prozesse, reduziert Verschwendung und verbessert die Gesamteffizienz.
Bevor Unternehmen das volle Potenzial des maschinellen Lernens ausschöpfen können, müssen sie zunächst damit beginnen, die grundlegenden Elemente der Teamzusammenarbeit zu stärken. Um genaue und aussagekräftige Modelle zu erstellen, müssen Datenwissenschaftler und Fachexperten eine enge Zusammenarbeit und ein tiefes Verständnis für die Komplexität industrieller Anlagen entwickeln. Ihre Zusammenarbeit wird das Fachwissen aus der Werkstatt in die Sprache der Daten übersetzen und so die erfolgreiche Anwendung von Lösungen für maschinelles Lernen vorantreiben.
Überwinden Sie die Mängel traditioneller Industriedaten
Die Nutzung von ML-Erkenntnissen zur Verbesserung der betrieblichen Effizienz ist nicht etwas, das über Nacht erreicht werden kann. Die erste Herausforderung besteht darin, industrielle Rohdaten zu verstehen.
In seinem nativen Format sind Industriedaten umfangreich, vielfältig und oft mit fehlerhaften oder irrelevanten Informationen, wie etwa Ausfallprotokollen, gefüllt. Ohne Anleitung verschwenden Datenwissenschaftler oft wertvolle Zeit und Ressourcen mit der Durchsicht irrelevanter Komplexität, verschwenden wertvolle Zeit und erstellen oft irreführende Modelle. Aus diesem Grund sind Fachexperten, darunter Prozessingenieure und Bediener, bei der Datenaufbereitung für genaue Modelle von entscheidender Bedeutung. Ihre umfassenden Prozesskenntnisse helfen dabei, die richtigen Daten und relevanten Zeiträume zu bestimmen.
Die Identifizierung der richtigen Daten ist jedoch nur der erste Schritt. Industrielle Rohdaten sind oft unübersichtlich und erfordern zum Verständnis einen Kontext. Stellen Sie sich ein Modell vor, bei dem die Temperaturmesswerte während der Wartung mit den Temperaturmesswerten während des Betriebs vermischt werden: Das würde ein Vorhersagemodell ins Chaos stürzen. Das Einfügen von Daten in ein Modell ohne Ahnung kann verheerende Folgen haben, was darauf hindeutet, dass es bei der Analyse wichtig ist, Daten zu bereinigen und zu kontextualisieren vorweg. Prozessexperten können dabei helfen, solche Überlegungen zu identifizieren, Algorithmusfehler zu reduzieren, Konsistenz sicherzustellen und die spezifischen Betriebsbedingungen zu identifizieren, die für den Modellerfolg am wichtigsten sind.
Nachdem die Daten bereinigt wurden, gibt es noch viel zu tun, um sie für ML vorzubereiten. Feature Engineering schließt diese Lücke und erfordert eine kontinuierliche Zusammenarbeit zwischen Datenwissenschaftlern und Prozessexperten, um Rohdaten in kontextbezogene Erkenntnisse umzuwandeln, die sich direkt mit dem jeweiligen Problem befassen. Zu diesen Informationseinblicken oder „Signaturen“ gehören statistische Zusammenfassungen, Häufigkeitsmuster und andere clevere Kombinationen von Sensordaten, die ML-Algorithmen dabei helfen, versteckte Muster zu entdecken, die Modellgenauigkeit zu verbessern und bei komplexen betrieblichen Entscheidungen zu helfen.
Der Einsatz von ML-Modellen in industriellen Umgebungen erfordert mehr als nur Genauigkeit. Um wirklich Wert zu generieren, müssen Modelle für den Einsatz im Produktionsprozess leicht auf Bediener übertragbar sein. Das bedeutet, dass die Benutzeroberfläche einfach zu lesen sein und Prognosen, Warnungen und Echtzeitdaten klar und prägnant darstellen muss. Darüber hinaus schafft die Einbeziehung von Erläuterungen in die Bedienoberfläche, sofern möglich, Vertrauen und Verständnis bei den Endbenutzern.
Industrielle Prozesse ändern sich im Laufe der Zeit, daher erfordert der erfolgreiche Einsatz von maschinellem Lernen, dass Modelle regelmäßig mit neuen Daten neu trainiert werden, um ihre Genauigkeit sicherzustellen. Dies erfordert eine enge Zusammenarbeit zwischen Datenwissenschaftlern und Betriebsteams, um die Leistung zu überwachen und Modelle kontinuierlich zu iterieren.
Advanced Analytics verbessert industrielle Initiativen für maschinelles Lernen
Die vielen Schritte zum Erstellen und Implementieren von ML-Modellen in betrieblichen Arbeitsabläufen sind nicht einfach, aber moderne fortschrittliche Analyselösungen rationalisieren den Prozess und bieten eine ganzheitliche Lösung für die Integration von ML in industrielle Prozesse.
Diese Lösungen durchbrechen das übliche industrielle Datenchaos, indem sie mehrere Datenquellen in Echtzeit verbinden. Zusätzlich zur Aggregation können diese Softwaretools die Datenbereinigung automatisieren und so einen Großteil der manuellen Datenverarbeitung und -aufbereitung überflüssig machen (Abbildung 1).
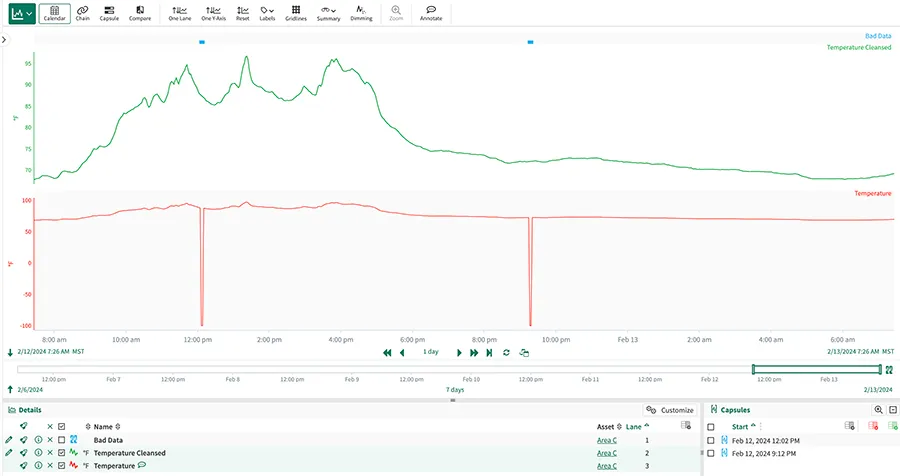
Abbildung 1: Seeq automatisiert die Datenbereinigung mithilfe einer Reihe integrierter Glättungsmethoden, um ein kontextualisiertes Bild der Anlagenleistung zu liefern. Beispielsweise werden zwei schlechte Temperaturwerte automatisch aus den gereinigten Prozessvariablen entfernt, die zur Modellierung und Erstellung von Prozesserkenntnissen verwendet werden.
Diese Anpassungsfähigkeit ist von entscheidender Bedeutung, wenn sich Prozesse ändern, da sie ML-Modelle auf dem neuesten Stand hält und relevante Informationen bereitstellt, um die aktuellen Betriebsbedingungen widerzuspiegeln. Bei Ausfallszenarien von Förderbändern beispielsweise ermöglichen fortschrittliche Analyselösungen den Ingenieuren, Anomalien schnell zu erkennen, Inkonsistenzen zu beheben und sofort aussagekräftige Informationen zu extrahieren. Diese hochwertigen Daten können dann als Grundlage für Fehlerbehebungsschritte dienen, umsetzbare ML-Erkenntnisse liefern und das Vertrauen in betriebliche Entscheidungen erhöhen.
Feature Engineering ist entscheidend für den Erfolg des maschinellen Lernens in industriellen Umgebungen, erfordert jedoch Zusammenarbeit. Fortschrittliche Analyselösungen tragen dazu bei, diese benötigte Synergie durch klar kuratierte Benutzerprofile zu ermöglichen, die für verschiedene Expertenrollen erstellt wurden, zusammen mit den Tools, die für den nahtlosen Austausch von Erkenntnissen zwischen den Betriebsteams erforderlich sind (Abbildung 2).
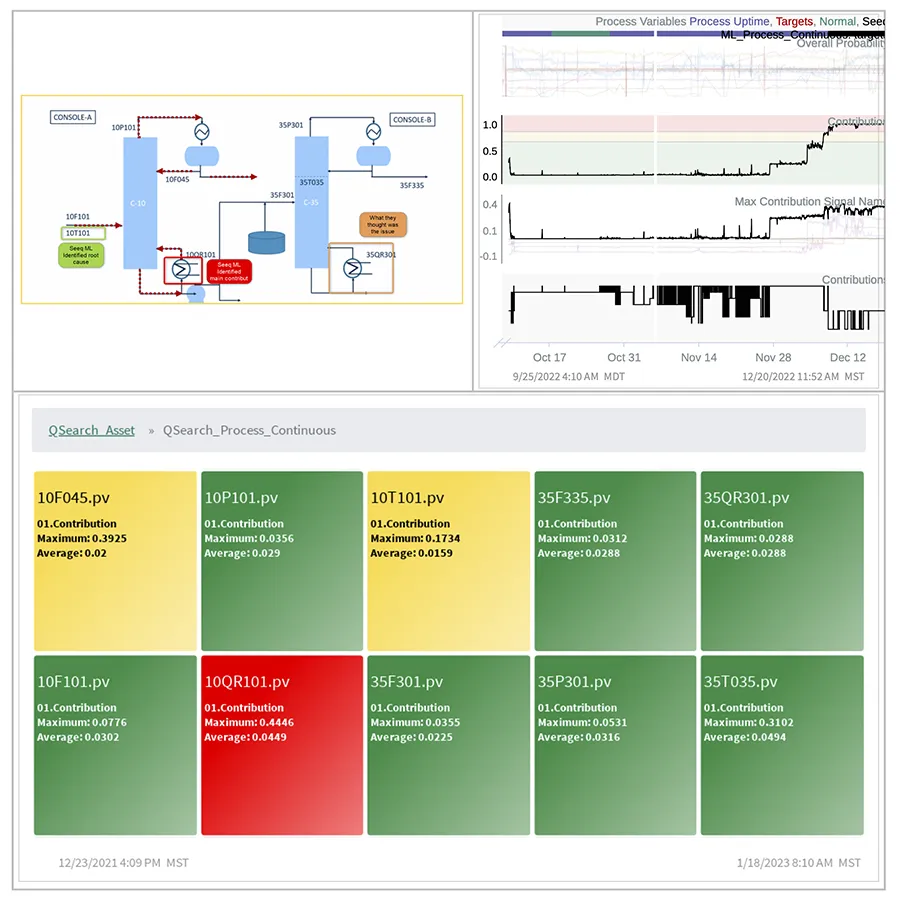
Abbildung 2: Seeq macht es einfach, automatisierte Berichte und Dashboards zu erstellen, in denen Ingenieure und Datenwissenschaftler ihre Analysen mit Branchen- und Betriebsteams teilen und ML implementieren können, um den täglichen Wert zu steigern.
Zum Beispiel erleichtert das Data Lab von Seeq Datenwissenschaftlern die Bereitstellung von Modellen für die direkte Verwendung durch Technik- und Betriebsteams, die Feedback geben können, um zur Verbesserung der Modelle beizutragen. Vorhersagen und Warnungen fließen dann an Workbench, Organizer und externe Visualisierungstools, auf die normalerweise Administratoren zugreifen können. Fortschrittliche Analyselösungen verbinden diese historisch getrennten Abteilungen und verwandeln Modelle in leistungsstarke Tools, die eine strengere Prozesskontrolle, Betriebsoptimierung und intelligentere Entscheidungsfindung im gesamten Unternehmen ermöglichen.
Kompressorausfälle mit vorausschauender Analyse kontrollieren
Reale Ergebnisse zeigen, dass fortschrittliche Analyselösungen kostspielige Ausfallzeiten wirksam reduzieren können. Beispielsweise nutzte ein großer Chemiehersteller, der unter unerwarteten Ausfällen kritischer Kompressoren litt, die Seeq-Lösung, um subtile Abweichungen bei Kompressoren von einem Betriebszyklus zum anderen zu identifizieren. Angesichts der geschätzten Verluste von 1 Million US-Dollar pro Vorfall wurde die Suche nach einer Möglichkeit, diese Ausfälle vorherzusagen und zu verhindern, schnell zur Priorität.
Das Unternehmen begann mit der Erfassung großer Mengen an Prozessdaten, diese waren jedoch mit über 170 Variablen so groß und komplex, dass es schwierig war, aus dem Rauschen echte Muster zu erkennen. Herkömmliche Analysemethoden können die Kombination von Faktoren, die den Fehler verursacht haben könnten, nicht identifizieren.
Der Hersteller wandte sich an Seeq und nutzte die integrierten ML-Tools der Software, um seinen Fachexperten die Lösung von Modellentwicklungsproblemen zu ermöglichen, ohne sich ausschließlich auf Datenwissenschaftler verlassen zu müssen. Die benutzerfreundliche Oberfläche der Lösung legt die Leistungsfähigkeit von ML direkt in die Hände von Prozessingenieuren mit umfassendem Kompressor-Know-how und trägt dazu bei, die Wissenslücke zwischen KMUs und Datenwissenschaftlern zu schließen, die mit herkömmlichen Analysen schwieriger zu erreichen ist. Dadurch wird sichergestellt, dass Vorhersagemodelle das richtige Domänenverständnis und die richtige Entwicklung berücksichtigen.
Durch die Nutzung speziell entwickelter Funktionen in fortschrittlichen Analyselösungen wandelt das Unternehmen Modellergebnisse nahezu in Echtzeit in betriebliche Erkenntnisse um. Die Modelle konzentrieren sich auf subtile Abweichungen der Kompressorparameter, die auf Probleme hinweisen, und visuelle Dashboards helfen dabei, Betriebs- und Technikteams frühzeitig zu alarmieren, um vorbeugende Maßnahmen zu ergreifen und kostspielige Ausfälle zu vermeiden. Dieser prädiktive Ansatz ermöglicht es Teams, reaktive Wartung in eine proaktive Strategie umzuwandeln.
Durch die Behebung von Problemen, bevor sie ausfallen, reduziert das Unternehmen kostspielige Ausfallzeiten erheblich. Fortschrittliche Analyselösungen bilden nicht nur das technische Rückgrat, sondern sorgen auch für neue Datenflüsse und geben Ingenieuren eine bessere Kontrolle über den Gerätezustand.
Lösen Sie Probleme mit eingefrorenen Messgeräten und optimieren Sie die Gaslieferung.
Eingefrorene Messgeräte gefährden die Rentabilität von Öl- und Gaslieferanten und führen zu Messfehlern und kostspieligem Produktabfall. Das Ausmaß des Problems wird durch das riesige Netzwerk eines Betreibers verschärft, das sich über 32.000 Meilen Pipeline erstreckt und täglich 7,4 Milliarden Kubikfuß Erdgas befördert. Unübersichtliche Daten und die Abhängigkeit von regelbasierten Ansätzen zur Identifizierung von Einfrierereignissen erwiesen sich als zeitaufwändig und unzuverlässig, und die Pflege von Regeln verbrauchte neben der Filterung vieler Fehlalarme und verpasster Erkennungen wertvolle Ressourcen.
Das Unternehmen brauchte eine neue Möglichkeit, die Reinigung zu optimieren und auf seine riesigen Mengen an Zählerdaten zuzugreifen. Fachexperten nutzen Softwaretools, um die Datenqualität zu verbessern und vergangene eingefrorene Ereignisse zu kommentieren, während Datenwissenschaftler mit Ingenieuren zusammenarbeiten, um genaue Modelle zu entwickeln, über starre Regeln hinauszugehen und ML zu nutzen.
In fortschrittlichen Analyselösungen richten Betreiber einen vollständig automatisierten Arbeitsablauf ein, der Datenvorverarbeitung, Modellkonfiguration und automatisiertes Neutraining umfasst, um die Modellgenauigkeit bei sich ändernden Betriebsbedingungen aufrechtzuerhalten. Modellvorhersagen fließen direkt in visuelle Dashboards und ausgefüllte Berichte ein und bieten Stakeholdern Echtzeiteinblicke in potenzielle Einfrierprobleme.
Dieser optimierte Arbeitsablauf ist in der Lage, proaktiv einzugreifen, um Gefrierprobleme zu entschärfen, sogar mit an einigen Stellen leicht verbesserter Genauigkeit, was zu jährlichen Einsparungen in Millionenhöhe durch reduzierte Produktgeschenke führt. Die Lösung verbessert nicht nur die Genauigkeit, sondern erleichtert auch die datengesteuerte Zusammenarbeit, die für die kontinuierliche Verbesserung der betrieblichen Effizienz von entscheidender Bedeutung ist.
Diese Arbeit hat den Lieferanten drei wichtige Erkenntnisse gebracht:
- Skalierbarkeit: Fortschrittliche Analyselösungen können die riesigen Datenmengen eines Unternehmens verarbeiten, ein entscheidender Vorteil für die Vermögensverwaltung in großem Maßstab.
- ML als Effizienzmultiplikator: Automatisierte Erkennungsaufgaben ermöglichen es Ingenieuren, sich auf höherwertige Probleme zu konzentrieren.
- Von Erkenntnissen zur Rentabilität: Fortschrittliche Analyselösungen vereinfachen den Prozess von der Vorhersage bis hin zu Kosteneinsparungen, was ein wichtiges Zeichen für einen effektiven ML-Einsatz ist.
Effektive Einführung von maschinellem Lernen in industriellen Umgebungen
Es ist unbestreitbar, dass maschinelles Lernen den Herstellungsprozess verändert. Seine Fähigkeit, komplexe Aufgaben zu automatisieren, Produktionszyklen zu optimieren und vorausschauende Wartung zu ermöglichen, bietet klare Vorteile gegenüber herkömmlichen Methoden. ML steigert die Effizienz und Kosteneinsparungen in vielen Industriesektoren, indem es die Anlagenverfügbarkeit erhöht, den Durchsatz erhöht und Entscheidungsprozesse verbessert.
Während die Implementierung von ML ihre eigenen Herausforderungen mit sich bringt, überwiegen die enormen Vorteile bei weitem die Hindernisse, und fortschrittliche Analyselösungen können dazu beitragen, erfolgreiche Implementierungen sicherzustellen. Diese Softwaretools bieten leistungsstarke Datenanalysefunktionen und sind speziell für die Anforderungen von Zeitreihendaten und ML-Anwendungen in industriellen Umgebungen konzipiert. Mit benutzerfreundlichen Schnittstellen und einem Fokus auf Zusammenarbeit ermöglichen diese Lösungen Unternehmen, auf maschinellem Lernen basierende Erkenntnisse vollständig zu übernehmen und so in einem zunehmend wettbewerbsintensiven Fertigungsmarkt erhebliche Effizienz- und Rentabilitätsvorteile zu erzielen.
Das obige ist der detaillierte Inhalt vonWie können industrielle Anwendungen durch maschinelles Lernen unterstützt werden?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie man maschinelles Lernen und künstliche Intelligenz in der Cybersicherheit nutzt
- Regelbasierte künstliche Intelligenz vs. maschinelles Lernen
- Maschinelles Lernen für Blockchain: Die wichtigsten Fortschritte und was Sie wissen müssen
- So verwenden Sie die Scikit-Learn-Bibliothek für maschinelles Lernen in Python.
- Wie implementiert man Funktionen für künstliche Intelligenz und maschinelles Lernen durch C++-Entwicklung?