
Heim >Technologie-Peripheriegeräte >KI >Ein Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme
Ein Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme

- 王林nach vorne
- 2024-03-22 20:50:221336Durchsuche
CLIP steht für Contrastive Language-Image Pre-Training, eine Vortrainingsmethode oder ein Modell, das auf kontrastiven Text-Bild-Paaren basiert. Die Trainingsdaten für CLIP bestehen aus Text-Bild-Paaren. Bildpaare, bei denen ein Bild mit der entsprechenden Textbeschreibung gepaart wird. Ziel des Modells ist es, die Beziehung zwischen Text- und Bildpaaren zu verstehen.

Open AI hat DALL-E und CLIP veröffentlicht -modale Modelle, die Bilder und Text kombinieren können. DALL-E ist ein Modell, das Bilder basierend auf Text generiert, während CLIP Text als Überwachungssignal verwendet, um ein übertragbares visuelles Modell zu trainieren.
Im Stable Diffusion-Modell werden die vom CLIP-Text-Encoder extrahierten Textmerkmale durch Queraufmerksamkeit in das UNet des Diffusionsmodells eingebettet. Insbesondere werden Textmerkmale als Schlüssel und Wert der Aufmerksamkeit verwendet, während UNet-Merkmale als Abfrage verwendet werden. Mit anderen Worten, CLIP ist tatsächlich eine wichtige Brücke zwischen Text und Bildern, indem es Textinformationen und Bildinformationen organisch kombiniert. Diese Kombination ermöglicht es dem Modell, Informationen zwischen verschiedenen Modalitäten besser zu verstehen und zu verarbeiten und so bessere Ergebnisse bei der Bewältigung komplexer Aufgaben zu erzielen. Auf diese Weise kann das Stable Diffusion-Modell die Textkodierungsfunktionen von CLIP effektiver nutzen, wodurch die Gesamtleistung verbessert und der Anwendungsbereich erweitert wird.
CLIP
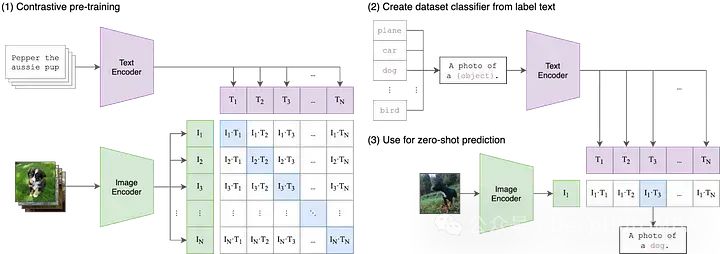
Dies ist das früheste von OpenAI im Jahr 2021 veröffentlichte Papier. Um CLIP zu verstehen, müssen wir das Akronym in drei Komponenten zerlegen: (1)Kontrastiv, (2)Sprache – Bild, ( 3) Vorschulung.
Beginnen wir mit Language-Image.
In herkömmlichen Modellen des maschinellen Lernens kann normalerweise nur eine einzige Modalität der Eingabedaten akzeptiert werden, beispielsweise Text, Bilder, Tabellendaten oder Audio. Wenn Sie Daten aus verschiedenen Modalitäten verwenden müssen, um Vorhersagen zu treffen, müssen Sie mehrere verschiedene Modelle trainieren. In CLIP bedeutet „Language-Image“, dass das Modell sowohl Text- (Sprache) als auch Bildeingabedaten akzeptieren kann. Dieses Design ermöglicht es CLIP, Informationen unterschiedlicher Modalitäten flexibler zu verarbeiten und dadurch seine Vorhersagefähigkeiten und seinen Anwendungsbereich zu verbessern.
CLIP verarbeitet Text- und Bildeingaben mithilfe von zwei verschiedenen Encodern, nämlich Text-Encoder und Bild-Encoder. Diese beiden Encoder bilden die Eingabedaten in einen niedrigerdimensionalen latenten Raum ab und erzeugen für jede Eingabe entsprechende Einbettungsvektoren. Ein wichtiges Detail ist, dass die Text- und Bildencoder die Daten in denselben Raum einbetten, d. h. der ursprüngliche CLIP-Raum ist ein 512-dimensionaler Vektorraum. Dieses Design ermöglicht den direkten Vergleich und Abgleich zwischen Text und Bildern ohne zusätzliche Konvertierung oder Verarbeitung. Auf diese Weise kann CLIP Textbeschreibungen und Bildinhalte im selben Vektorraum darstellen und so modalübergreifende semantische Ausrichtungs- und Abruffunktionen ermöglichen. Das Design dieses gemeinsamen Einbettungsraums verleiht CLIP bessere Generalisierungsfähigkeiten und Anpassungsfähigkeit, sodass es bei einer Vielzahl von Aufgaben und Datensätzen gute Leistungen erbringen kann.
Kontrastiv
Während das Einbetten von Text- und Bilddaten in denselben Vektorraum ein nützlicher Ausgangspunkt sein kann, stellt dies allein nicht sicher, dass das Modell die Darstellung von Text und Bildern effektiv vergleichen kann. Beispielsweise ist es wichtig, einen vernünftigen und interpretierbaren Zusammenhang zwischen der Einbettung von „Hund“ oder „einem Bild eines Hundes“ in einen Text und der Einbettung eines Hundebildes herzustellen. Wir brauchen jedoch eine Möglichkeit, die Lücke zwischen diesen beiden Modellen zu schließen.
Beim multimodalen maschinellen Lernen gibt es verschiedene Techniken, um zwei Modalitäten aufeinander abzustimmen. Die derzeit beliebteste Methode ist jedoch der Kontrast. Kontrastierende Techniken nehmen Eingabepaare aus zwei Modalitäten auf, beispielsweise einem Bild und seiner Bildunterschrift, und trainieren die beiden Encoder des Modells, um diese Eingabedatenpaare so genau wie möglich darzustellen. Gleichzeitig wird das Modell dazu angeregt, ungepaarte Eingaben (z. B. Bilder von Hunden und der Text „Bilder von Autos“) zu nehmen und sie so weit wie möglich entfernt darzustellen. CLIP ist nicht die erste kontrastive Lerntechnik für Bilder und Text, aber seine Einfachheit und Effektivität haben es zu einem festen Bestandteil multimodaler Anwendungen gemacht.
Vorschulung
Während CLIP selbst für Anwendungen wie Zero-Shot-Klassifizierung, semantische Suche und unbeaufsichtigte Datenexploration nützlich ist, wird CLIP auch als Baustein für eine große Anzahl von Multi- Modale Anwendungen, von Stable Diffusion und DALL-E bis StyleCLIP und OWL-ViT. Für die meisten dieser Downstream-Anwendungen gilt das anfängliche CLIP-Modell als Ausgangspunkt für das „Vortraining“ und das gesamte Modell wird für seinen neuen Anwendungsfall feinabgestimmt.
Während OpenAI die zum Training des ursprünglichen CLIP-Modells verwendeten Daten nie explizit spezifiziert oder weitergegeben hat, wurde im CLIP-Papier erwähnt, dass das Modell anhand von 400 Millionen Bild-Text-Paaren trainiert wurde, die aus dem Internet gesammelt wurden.
https://www.php.cn/link/7c1bbdaebec5e20e91db1fe61221228f
ALIGN: Skalierung des visuellen und visuellen Sprachrepräsentationslernens mit verrauschter Textüberwachung

. Mit CLIP nutzt OpenAI 4 Milliarden von Bild-Text-Paaren Da keine Details angegeben werden, ist es unmöglich, genau zu wissen, wie der Datensatz erstellt wurde. Bei der Beschreibung des neuen Datensatzes haben sie sich jedoch von den Conceptual Captions von Google inspirieren lassen – einem relativ kleinen Datensatz (3,3 Millionen Bild-Untertitel-Paare), der teure Filter- und Nachbearbeitungstechniken verwendet, obwohl diese Technologie leistungsstark, aber nicht besonders skalierbar ist. .
Daher sind qualitativ hochwertige Datensätze zur Forschungsrichtung geworden. Kurz nach CLIP löste ALIGN dieses Problem durch Skalenfilterung. ALIGN verlässt sich nicht auf kleine, sorgfältig kommentierte und kuratierte Bildunterschriften-Datensätze, sondern nutzt stattdessen 1,8 Milliarden Bildpaare und Alternativtext.
Während diese Alternativtextbeschreibungen im Durchschnitt viel lauter sind als die Titel, macht die schiere Größe des Datensatzes dies mehr als wett. Die Autoren verwendeten eine einfache Filterung, um Duplikate, Bilder mit über 1.000 relevanten Alternativtexten sowie nicht informativen Alternativtext (entweder zu häufig oder mit seltenen Tags) zu entfernen. Mit diesen einfachen Schritten erreicht oder übertrifft ALIGN den Stand der Technik bei verschiedenen Nullschuss- und Feinabstimmungsaufgaben.
https://arxiv.org/abs/2102.05918
K-LITE: Lernen übertragbarer visueller Modelle mit externem Wissen

Wie ALIGN löst auch K-LITE für das vergleichende Vortraining von hochwertige Bild-Text-Paare für eine begrenzte Anzahl von Problemen.
K-LITE konzentriert sich auf die Erklärung von Konzepten, d. h. Definitionen oder Beschreibungen als Kontext und unbekannte Konzepte können dabei helfen, ein umfassendes Verständnis zu entwickeln. Eine beliebte Erklärung lautet: Wenn Menschen zum ersten Mal Fachbegriffe und ungewöhnliches Vokabular einführen, definieren sie diese normalerweise einfach oder verwenden etwas, das jeder als Analogie kennt!
Um diesen Ansatz umzusetzen, verwendeten Forscher von Microsoft und der UC Berkeley WordNet und Wiktionary, um den Text in Bild-Text-Paaren zu verbessern. Für einige isolierte Konzepte, wie etwa Klassenbezeichnungen in ImageNet, werden die Konzepte selbst verbessert, während für Titel (z. B. von GCC) die am wenigsten verbreiteten Nominalphrasen verbessert werden. Mit diesem zusätzlichen strukturierten Wissen zeigen vorab trainierte Modelle erhebliche Verbesserungen bei Transferlernaufgaben.
https://arxiv.org/abs/2204.09222
OpenCLIP: Reproduzierbare Skalierungsgesetze für kontrastives Sprach-Bild-Lernen
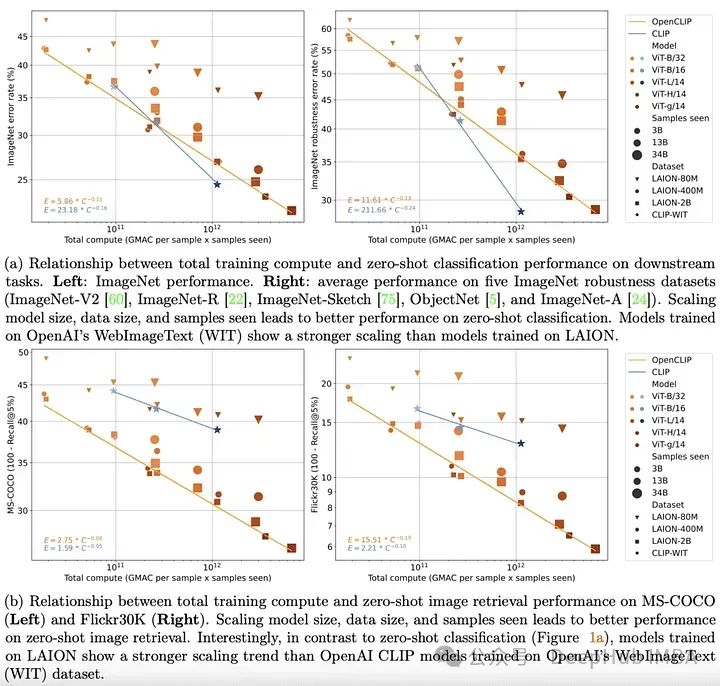
Bis Ende 2022 wurden Transformatormodelle im Text etabliert und visuelle Domänen. Wegweisende empirische Arbeiten in beiden Bereichen haben zudem deutlich gezeigt, dass die Leistung von Transformatormodellen bei unimodalen Aufgaben gut durch einfache Skalierungsgesetze beschrieben werden kann. Dies bedeutet, dass man die Leistung des Modells ziemlich genau vorhersagen kann, wenn die Menge der Trainingsdaten, die Trainingszeit oder die Modellgröße zunehmen.
OpenCLIP untersucht systematisch die Leistung von Trainingsdatenpaarmodellen bei Zero-Shot- und Feinabstimmungsaufgaben, indem es die obige Theorie auf multimodale Szenarien ausdehnt und dabei den größten bisher veröffentlichten Open-Source-Bild-Text-Paardatensatz (5B) verwendet. Auswirkungen . Wie im unimodalen Fall zeigt diese Studie, dass die Modellleistung bei multimodalen Aufgaben mit einem Potenzgesetz in Bezug auf Berechnung, Anzahl der gesehenen Stichproben und Anzahl der Modellparameter skaliert.
Noch interessanter als die Existenz von Potenzgesetzen ist die Beziehung zwischen Potenzgesetzskalierung und Daten vor dem Training. Unter Beibehaltung der CLIP-Modellarchitektur und Trainingsmethode von OpenAI zeigt das OpenCLIP-Modell stärkere Skalierungsfähigkeiten bei Aufgaben zum Abrufen von Beispielbildern. Für die Zero-Shot-Bildklassifizierung auf ImageNet zeigte das Modell von OpenAI (trainiert anhand seines proprietären Datensatzes) stärkere Skalierungsfunktionen. Diese Ergebnisse unterstreichen die Bedeutung von Datenerfassungs- und Filterverfahren für die nachgelagerte Leistung.
https://arxiv.org/abs/2212.07143Kurz nach der Veröffentlichung von OpenCLIP wurde der LAION-Datensatz jedoch aus dem Internet entfernt, da er illegale Bilder enthielt.
MetaCLIP: CLIP-Daten entmystifizieren
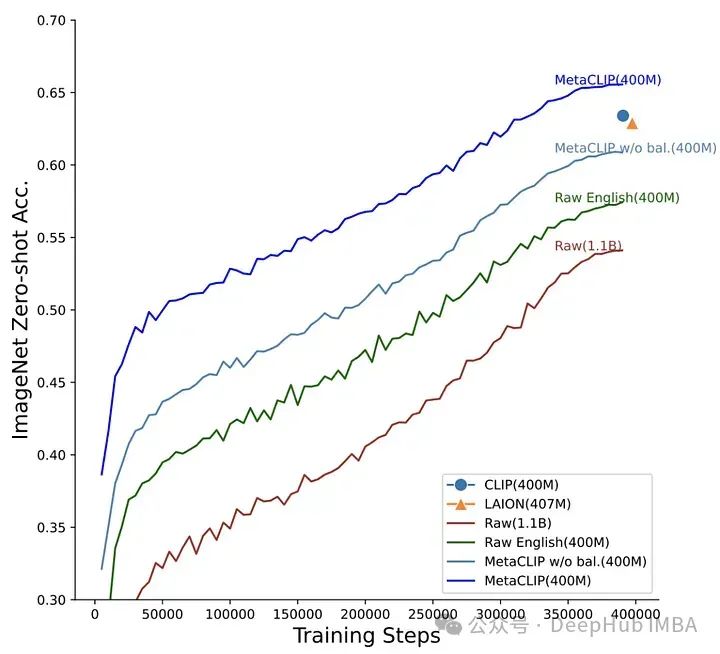
OpenCLIP versucht zu verstehen, wie sich die Leistung nachgelagerter Aufgaben mit der Datenmenge, dem Rechenaufwand und der Anzahl der Modellparameter ändert, während MetaCLIP sich auf die Auswahl von Daten konzentriert. Wie die Autoren sagen: „Wir glauben, dass der Hauptfaktor für den Erfolg von CLIP seine Daten sind und nicht die Modellarchitektur oder die Ziele vor dem Training.“ führte Experimente durch. Das MetaCLIP-Team testete verschiedene Strategien im Zusammenhang mit dem Abgleich von Teilzeichenfolgen, der Filterung und der ausgewogenen Datenverteilung und stellte fest, dass die beste Leistung erzielt wurde, wenn jeder Text maximal 20.000 Mal im Trainingsdatensatz vorkam Auch das Wort „Foto“, das im ursprünglichen Datenpool 54 Millionen Mal vorkam, war in den Trainingsdaten auf 20.000 Bild-Text-Paare beschränkt. Mit dieser Strategie wurde MetaCLIP auf 400 Millionen Bild-Text-Paare aus dem Common Crawl-Datensatz trainiert und übertraf das CLIP-Modell von OpenAI bei verschiedenen Benchmarks.
https://arxiv.org/abs/2309.16671
DFN: Data Filtering NetworksMit der Forschung zu MetaCLIP kann gezeigt werden, dass Datenmanagement ein wichtiges Werkzeug für das Training sein kann -leistungsfähige multimodale Modelle (z. B. CLIP). Die Filterstrategie von MetaCLIP ist sehr erfolgreich, basiert aber auch überwiegend auf heuristischen Methoden. Anschließend untersuchten die Forscher, ob ein Modell trainiert werden könnte, um diese Filterung effizienter durchzuführen. 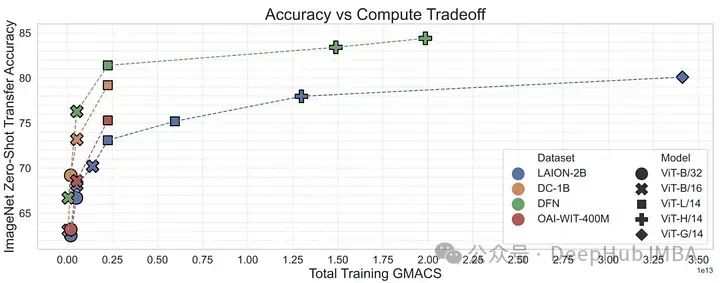
Um dies zu überprüfen, verwendet der Autor hochwertige Daten aus dem konzeptionellen 12M, um das CLIP-Modell zu trainieren, um hochwertige Daten aus Daten geringer Qualität zu filtern. Dieses Data Filtering Network (DFN) wird verwendet, um einen größeren, qualitativ hochwertigen Datensatz zu erstellen, indem nur hochwertige Daten aus einem nicht kuratierten Datensatz (in diesem Fall Common Crawl) ausgewählt werden. CLIP-Modelle, die auf gefilterten Daten trainiert wurden, übertrafen Modelle, die nur auf anfänglichen Daten hoher Qualität trainiert wurden, und Modelle, die auf großen Mengen ungefilterter Daten trainiert wurden.
https://arxiv.org/abs/2309.17425
ZusammenfassungDas CLIP-Modell von OpenAI verändert die Art und Weise, wie wir multimodale Daten verarbeiten, erheblich. Aber CLIP ist nur der Anfang. Von den Daten vor dem Training bis hin zu den Details der Trainingsmethoden und Kontrastverlustfunktionen hat die CLIP-Familie in den letzten Jahren unglaubliche Fortschritte gemacht. ALIGN skaliert verrauschten Text, K-LITE erweitert externes Wissen, OpenCLIP untersucht Skalierungsgesetze, MetaCLIP optimiert das Datenmanagement und DFN verbessert die Datenqualität. Diese Modelle vertiefen unser Verständnis der Rolle von CLIP bei der Entwicklung multimodaler künstlicher Intelligenz und zeigen Fortschritte bei der Verbindung von Bildern und Text.
Das obige ist der detaillierte Inhalt vonEin Rückblick auf die Entwicklung des CLIP-Modells, dem Eckpfeiler der vinzentinischen Diagramme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verbinden Sie Myeclipse mit Navicat
- Tensorflow-Grundlagen (Open-Source-Softwarebibliothek für maschinelles Lernen)
- Vier Kreuzvalidierungstechniken, die Sie beim maschinellen Lernen erlernen müssen
- Grundlagen des maschinellen Lernens: Wie kann eine Überanpassung verhindert werden?
- So konfigurieren Sie maschinelles Lernen mit PyCharm auf Linux-Systemen