
Heim >Technologie-Peripheriegeräte >KI >Was tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!
Was tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-13 12:16:20599Durchsuche

End-to-End-differenzierbares Lernen für autonomes Fahren ist in letzter Zeit zu einem prominenten Paradigma geworden. Ein großer Engpass liegt in der enormen Nachfrage nach qualitativ hochwertigen beschrifteten Daten wie 3D-Boxen und semantischer Segmentierung, deren manuelle Annotation notorisch teuer ist. Diese Schwierigkeit wird durch die herausragende Tatsache verschärft, dass das Verhalten innerhalb der Stichprobe bei AD häufig Long-Tail-Verteilungen aufweist. Mit anderen Worten: Die meisten der gesammelten Daten können trivial sein (z. B. beim Vorwärtsfahren auf einer geraden Straße), und nur wenige Situationen sind sicherheitskritisch. In diesem Artikel untersuchen wir ein praktisch wichtiges, aber wenig erforschtes Thema, nämlich die Frage, wie bei der End-to-End-AD eine Proben- und Etiketteneffizienz erreicht werden kann.
Konkret entwirft das Papier eine planungsorientierte aktive Lernmethode, die Teile der gesammelten Rohdaten nach und nach entsprechend den Diversitäts- und Nützlichkeitskriterien der vorgeschlagenen Planungsrouten annotiert. Empirisch kann der vorgeschlagene planorientierte Ansatz allgemeine aktive Lernansätze weit übertreffen. Bemerkenswert ist, dass unsere Methode mit nur 30 % der nuScenes-Daten eine vergleichbare Leistung wie hochmoderne End-to-End-AD-Methoden erreicht. Wir hoffen, dass unsere Arbeit neben methodischen Bemühungen auch künftige Arbeiten aus einer datenzentrierten Perspektive inspirieren wird.
Link zum Papier: https://arxiv.org/pdf/2403.02877.pdf
Hauptbeitrag dieses Artikels:
- Die erste Person, die sich eingehend mit den Datenproblemen von E2E-AD befasst. Bietet außerdem eine einfache, aber effektive Lösung, um wertvolle Daten für die Planung innerhalb eines begrenzten Budgets zu identifizieren und zu kommentieren.
- Basierend auf der planungsorientierten Philosophie des End-to-End-Ansatzes werden neue aufgabenspezifische Diversitäts- und Unsicherheitsmaße für die Routenplanung konzipiert.
- Umfangreiche Experimente und Ablationsstudien haben die Wirksamkeit der Methode nachgewiesen. ActiveAD übertrifft generische Peer-to-Peer-Methoden bei weitem und erreicht eine mit SOTA-Methoden vergleichbare Leistung mit vollständigen Bezeichnungen, die nur 30 % der nuScenes-Daten verwenden.
Einführung in die Methode
ActiveAD wird im End-to-End-AD-Framework ausführlich beschrieben, und Diversitäts- und Unsicherheitsindikatoren werden basierend auf den Datenmerkmalen von AD entworfen.
1) Erstprobenauswahl von Etiketten
Beim aktiven Lernen in Computer Vision basiert die Erstprobenauswahl normalerweise nur auf dem Originalbild ohne zusätzliche Informationen oder erlernte Funktionen, was zur gängigen Praxis der zufälligen Initialisierung führt. Im Fall von AD stehen zusätzliche Vorabinformationen zur Verfügung. Konkret können bei der Erfassung von Daten von Sensoren herkömmliche Informationen wie Geschwindigkeit und Flugbahn des eigenen Fahrzeugs gleichzeitig erfasst werden. Darüber hinaus sind Wetter- und Lichtverhältnisse häufig kontinuierlich und lassen sich auf Fragmentebene leicht annotieren. Diese Informationen erleichtern das Treffen fundierter Entscheidungen für die Erstauswahl des Sets. Aus diesem Grund haben wir ein Selbstdiversitätsmaß für die Erstauswahl entwickelt.
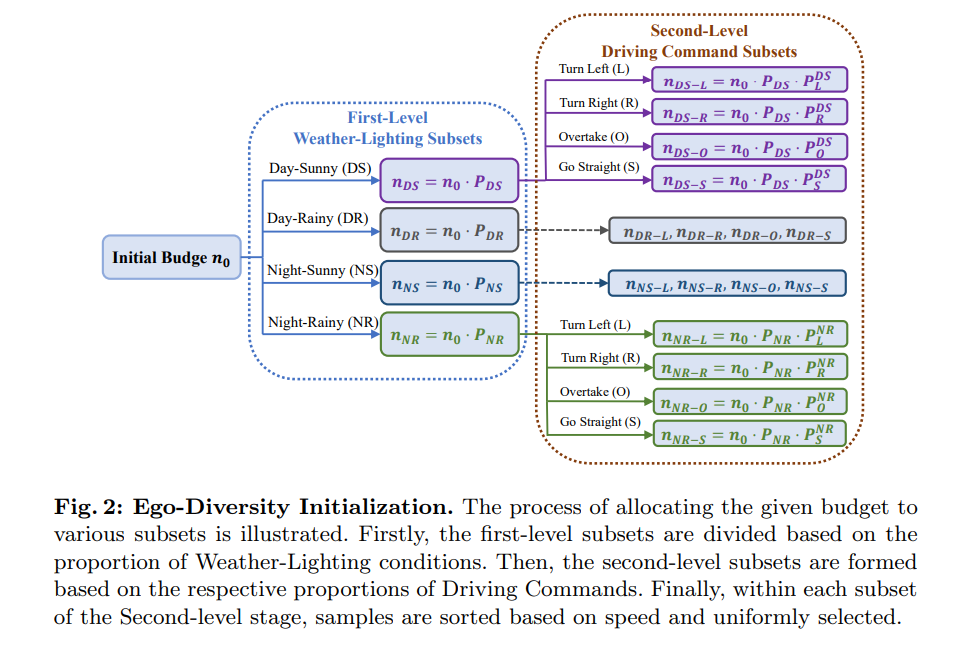
Ego Diversity: Besteht aus drei Teilen: 1) Wetterbeleuchtung 2) Fahranweisungen 3) Durchschnittsgeschwindigkeit. Verwenden Sie zunächst die Beschreibung in nuScenes, um den gesamten Datensatz in vier sich gegenseitig ausschließende Teilmengen zu unterteilen: Day Sunny (DS), Day Rainy (DR), Night Sunny (NS), NightRainy (NR). Zweitens ist jede Teilmenge in vier Kategorien unterteilt, basierend auf der Anzahl der Links-, Rechts- und Geradeausfahrbefehle in einem vollständigen Segment: Linkskurve (L), Rechtskurve (R), Überholen (O) und Geradeaus fahren (S). Das Papier entwirft einen Schwellenwert τc. Wenn die Anzahl der linken und rechten Befehle in einem Clip größer oder gleich dem Schwellenwert τc ist, betrachten wir dies als transzendentes Verhalten im Clip. Wenn nur die Anzahl der Linksbefehle größer als der Schwellenwert τc ist, deutet dies auf eine Linkskurve hin. Wenn nur die Anzahl der Rechtsbefehle größer als der Schwellenwert τc ist, deutet dies auf eine Rechtskurve hin. Alle anderen Fälle gelten als direkt. Drittens berechnen Sie die Durchschnittsgeschwindigkeit in jeder Szene und sortieren sie in aufsteigender Reihenfolge innerhalb der relevanten Teilmenge.
Abbildung 2 zeigt den detaillierten intuitiven Prozess des anfänglichen Auswahlprozesses basierend auf Mehrwegbäumen.
2) Kriteriendesign für die inkrementelle Auswahl
In diesem Abschnitt stellen wir vor, wie neue Teile eines Fragments basierend auf einem Modell, das mit bereits annotierten Fragmenten trainiert wurde, inkrementell annotiert werden. Wir werden das Zwischenmodell verwenden, um Rückschlüsse auf unbeschriftete Segmente zu ziehen, und nachfolgende Auswahlen basieren auf diesen Ausgaben. Dennoch wird eine planungsorientierte Perspektive eingenommen und drei Kriterien für die anschließende Datenauswahl eingeführt: Verschiebungsfehler, weiche Kollisionen und Proxy-Unsicherheiten.
Standard 1: Verschiebungsfehler (DE). wird als Abstand zwischen der vom Modell vorhergesagten geplanten Route τ und den im Datensatz aufgezeichneten menschlichen Flugbahnen τ* ausgedrückt.
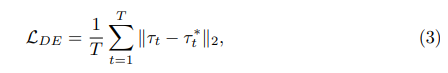
wobei T den Frame in der Szene darstellt. Da der Verschiebungsfehler selbst eine Leistungsmetrik ist (keine Anmerkung erforderlich), wird er natürlich zum ersten und kritischsten Kriterium bei der aktiven Auswahl.
Standard 2: Soft Collision (SC). LSC ist definiert als der Abstand zwischen der vorhergesagten Flugbahn des eigenen Fahrzeugs und der vorhergesagten Flugbahn des Agenten. Vorhersagen von Agenten mit geringem Vertrauen werden durch den Schwellenwert ε herausgefiltert. In jedem Szenario wird die kürzeste Entfernung als Maß für den Gefährdungskoeffizienten gewählt. Gleichzeitig bleibt eine positive Korrelation zwischen Begriff und kürzestem Abstand erhalten:
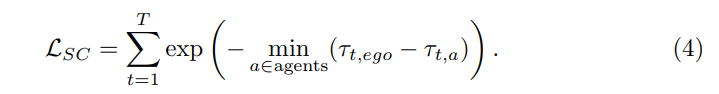
Verwenden Sie „weiche Kollision“ als Kriterium, weil: Einerseits ist die Berechnung des „Kollisionsverhältnisses“ im Gegensatz zum „Verschiebungsfehler“ davon abhängig auf der 3D des Ziels. Anmerkungen für Boxen, die in unbeschrifteten Daten nicht verfügbar sind. Daher sollte es möglich sein, das Kriterium ausschließlich auf der Grundlage der Inferenzergebnisse des Modells zu berechnen. Betrachten Sie andererseits ein hartes Kollisionskriterium: Wenn die vorhergesagte Flugbahn des eigenen Fahrzeugs mit den Flugbahnen anderer vorhergesagter Agenten kollidieren wird, weisen Sie ihr 1 zu, andernfalls weisen Sie ihr 0 zu. Dies kann jedoch zu zu wenigen Stichproben mit Label 1 führen, da die Kollisionsrate moderner Modelle in AD normalerweise gering ist (weniger als 1 %). Daher wurde beschlossen, anstelle der Metrik „Kollisionsrate“ die kürzeste Entfernung zu anderen Zielpaaren zu verwenden. Das Risiko wird als deutlich höher eingeschätzt, wenn der Abstand zu anderen Fahrzeugen oder Fußgängern zu gering ist. Kurz gesagt sind „weiche Kollisionen“ ein wirksames Maß für die Kollisionswahrscheinlichkeit und können eine intensive Überwachung ermöglichen.
Kriterium III: Agentenunsicherheit (AU). Vorhersagen über die zukünftigen Flugbahnen umgebender Agenten sind naturgemäß unsicher, daher generieren Bewegungsvorhersagemodule typischerweise mehrere Modalitäten und entsprechende Konfidenzwerte. Unser Ziel ist es, Daten auszuwählen, bei denen in der Nähe befindliche Agenten eine hohe Unsicherheit haben. Konkret werden entfernte Objekte durch einen Entfernungsschwellenwert δ herausgefiltert und die gewichtete Entropie der vorhergesagten Wahrscheinlichkeiten mehrerer Modi für die verbleibenden Objekte berechnet. Nehmen Sie an, dass die Anzahl der Modalitäten beträgt und der Konfidenzwert des Agenten in verschiedenen Modalitäten Pi(a) ist, wobei i∈{1,…,Nm}. Dann kann die Agentenunsicherheit definiert werden als:
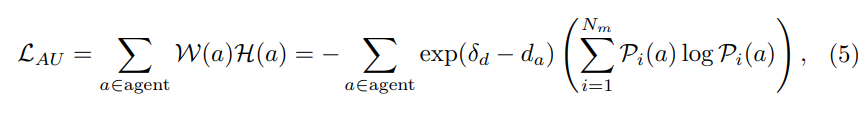
Gesamtverlust:
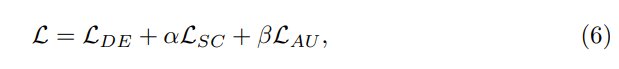
3) Gesamtes aktives Lernparadigma
Alg1 führt den gesamten Arbeitsablauf der Methode ein. Gegeben sei ein verfügbares Budget B, eine anfängliche Auswahlgröße n0, die Anzahl der in jedem Schritt getroffenen Aktivitätsauswahlen ni und insgesamt M Auswahlstufen. Die Auswahl wird zunächst mithilfe der oben beschriebenen Randomisierungs- oder Selbstdiversitätsmethoden initialisiert. Anschließend werden die aktuell annotierten Daten zum Trainieren des Netzwerks verwendet. Basierend auf dem trainierten Netzwerk treffen wir Vorhersagen zu den nicht gekennzeichneten Netzwerken und berechnen den Gesamtverlust. Abschließend werden die Samples nach dem Gesamtverlust sortiert und die Top-Ni-Samples ausgewählt, die in der aktuellen Iteration mit Anmerkungen versehen werden sollen. Dieser Vorgang wird wiederholt, bis die Iteration die Obergrenze M erreicht und die Anzahl der ausgewählten Stichproben die Obergrenze B erreicht.

Experimentelle Ergebnisse
Experimente wurden mit dem weit verbreiteten nuScenes-Datensatz durchgeführt. Alle Experimente werden mit PyTorch implementiert und auf RTX 3090- und A100-GPUs ausgeführt.
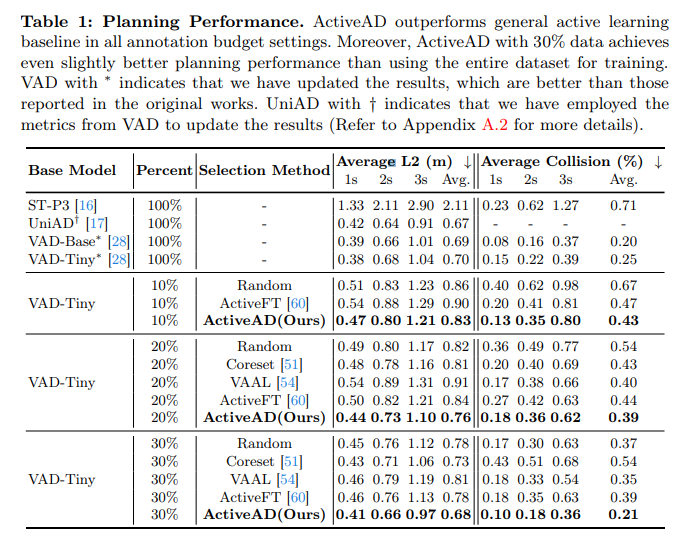
Tabelle 1: Planungsleistung. ActiveAD übertrifft die allgemeinen Basiswerte für aktives Lernen in allen Annotationsbudgeteinstellungen. Darüber hinaus erzielte ActiveAD mit 30 % der Daten eine etwas bessere Planungsleistung im Vergleich zum Training mit dem gesamten Datensatz. VADs mit * kennzeichnen aktualisierte Ergebnisse, die besser sind als die in der Originalarbeit berichteten. UniAD mit † zeigt an, dass die VAD-Indikatoren zur Aktualisierung der Ergebnisse verwendet wurden.
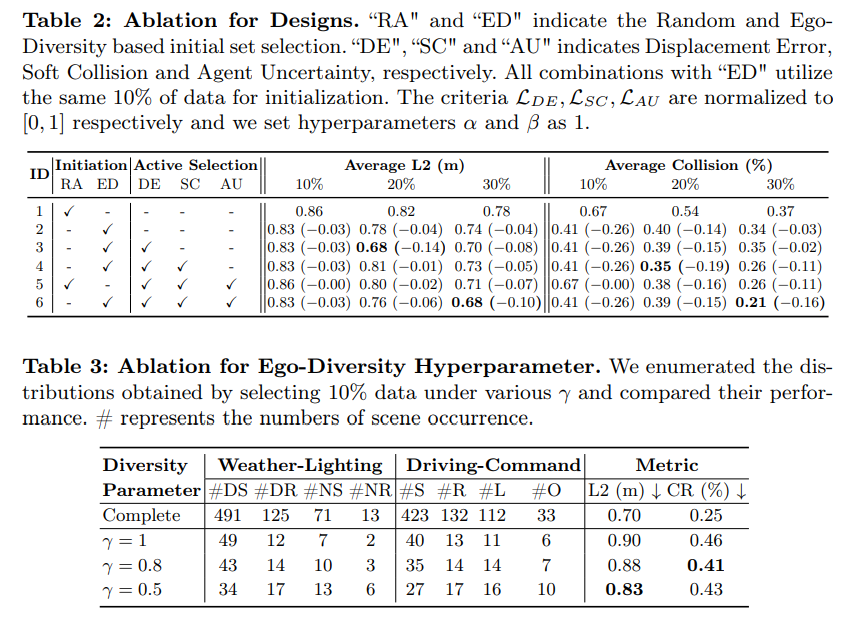
Tabelle 2: Konzipiertes Ablationsexperiment. „RA“ und „ED“ stellen die Auswahl des anfänglichen Satzes basierend auf Zufälligkeit und Selbstvielfalt dar. „DE“, „SC“ und „AU“ stellen Verschiebungsfehler dar, bei denen es sich um weiche Kollisionen bzw. Agentenunsicherheiten handelt. Alle Kombinationen mit „ED“ werden mit den gleichen 10 %-Daten initialisiert. LDE, LSC und LAU werden jeweils auf [0, 1] normalisiert und die Hyperparameter α und β werden auf 1 gesetzt.
Abbildung 3: Visualisierung ausgewählter Szenen. Verschiebungsfehler (Spalte 1), weiche Kollision (Spalte 2), Agentenunsicherheit (Spalte 3) und Hybridkriterien (Spalte 4) basierend auf ausgewählten Frontkamerabildern basierend auf einem Modell, das auf 10 % der Daten trainiert wurde. Mixed stellt unsere endgültige Auswahlstrategie, ActiveAD, dar und berücksichtigt die ersten drei Szenarien!

Tabelle 4, Leistung in verschiedenen Szenarien. Je kleiner die durchschnittliche L2(m)/durchschnittliche Kollisionsrate (%) des aktiven Modells ist, das 30 % der Daten verwendet, desto besser ist die Leistung unter verschiedenen Wetter-/Licht- und Fahrbefehlsbedingungen.
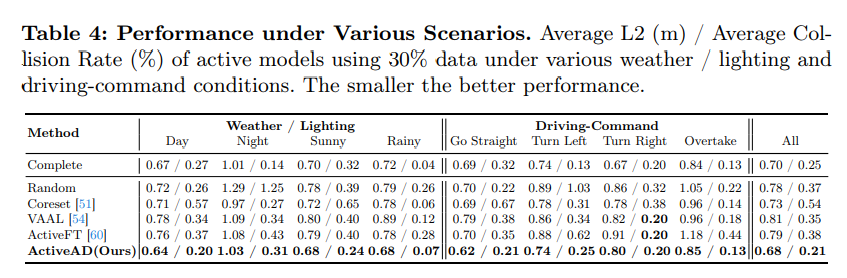
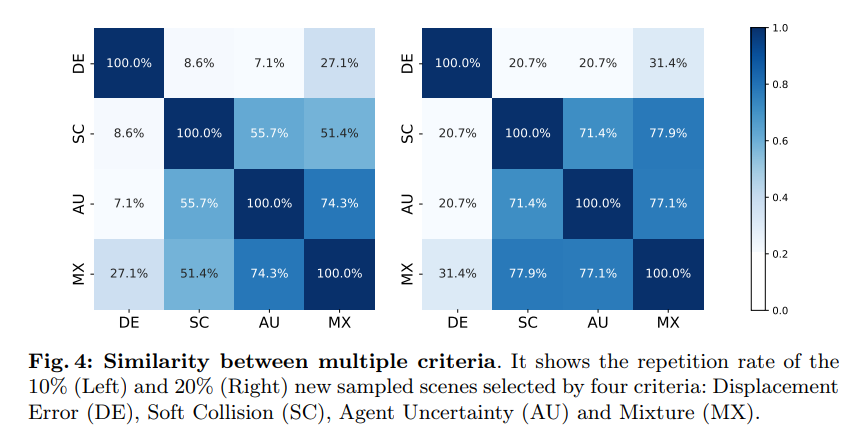
Abbildung 4: Ähnlichkeit zwischen mehreren Kriterien. Es zeigt das neue Stichprobenszenario mit 10 % (links) und 20 % (rechts), ausgewählt nach vier Kriterien: Verschiebungsfehler (DE), weiche Kollision (SC), Agentenunsicherheit (AU) und Mischung (MX)
Einige Schlussfolgerungen dieser Arbeit
Um die hohen Kosten und Langzeitprobleme der End-to-End-Annotation von autonomen Fahrdaten zu lösen, haben wir die Führung bei der Entwicklung einer maßgeschneiderten Lösung für aktives Lernen übernommen, ActiveAD. ActiveAD führt neue aufgabenspezifische Diversitäts- und Unsicherheitsmaße ein, die auf einer planungsorientierten Philosophie basieren. Eine Vielzahl von Experimenten belegt die Wirksamkeit der Methode. Mit nur 30 % der Daten übertrifft sie die allgemeinen bisherigen Methoden deutlich und erreicht eine mit den modernen Modellen vergleichbare Leistung. Dies stellt eine sinnvolle Untersuchung des durchgängigen autonomen Fahrens aus einer datenzentrierten Perspektive dar und wir hoffen, dass unsere Arbeit zukünftige Forschung und Entdeckungen inspirieren kann.
Das obige ist der detaillierte Inhalt vonWas tun, wenn keine End-to-End-Daten vorhanden sind? ActiveAD: Durchgängiges autonomes Fahren, aktives Lernen für die Planung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren
- Nächste Woche beginnt der weltweit größte Selbstfahrtest mit 100 Fahrzeugen
- Das Baidu Research Institute veröffentlicht die zehn wichtigsten Technologietrends im Jahr 2023 und verankert „KI in der Realität': Die große Modellökologie der Branche entsteht, und intelligente Innovationen wie autonomes Fahren, AIGC und Quantentechnologie sind pragmatischer
- Sparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung
- Ideal, NIO und Xpeng arbeiten zusammen, um durchgängiges autonomes Fahren zu einem neuen Wettbewerbsfaktor zu machen