
Heim >Technologie-Peripheriegeräte >KI >ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren
ST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren

- 王林nach vorne
- 2023-04-09 18:11:101306Durchsuche
arXiv-Artikel „ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning“, 22. Juli, Autor von der Shanghai Jiao Tong University, dem Shanghai AI Laboratory, der University of California San Diego und Peking-Forschung von JD .com Krankenhaus.

Schlagen Sie ein Lernschema für räumlich-zeitliche Merkmale vor, das gleichzeitig eine Reihe repräsentativerer Merkmale für Wahrnehmungs-, Vorhersage- und Planungsaufgaben bereitstellen kann, genannt ST-P3. Insbesondere wird eine egozentrisch ausgerichtete Akkumulationstechnik vorgeschlagen, um die geometrischen Informationen im 3D-Raum zu speichern, bevor die BEV-Konvertierung erfasst wird, um vergangene Bewegungsänderungen für zukünftige Vorhersagen zu berücksichtigen Eine Verfeinerungseinheit wird eingeführt, um die geplante visuelle Elementerkennung zu kompensieren. Quellcode, Modell- und Protokolldetails Open Source https://github.com/OpenPercepti onX/ST-P3 .
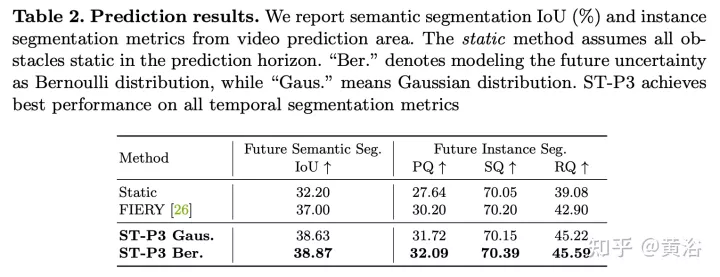
Wegweisende LSS-Methode zum Extrahieren perspektivischer Merkmale aus Multi-View-Kameras über Tiefe. Es ist voraussichtlich auf 3D aufgerüstet und in den BEV-Raum integriert werden. Merkmalskonvertierung zwischen zwei Ansichten, deren latente Tiefenvorhersage entscheidend ist.
Das Upgrade zweidimensionaler Ebeneninformationen auf drei Dimensionen erfordert zusätzliche Dimensionen, dh die Tiefe, die für dreidimensionale geometrische autonome Fahraufgaben geeignet ist. Um die Feature-Darstellung weiter zu verbessern, ist es selbstverständlich, zeitliche Informationen in das Framework einzubeziehen, da die meisten Szenen mit Videoquellen beauftragt sind.
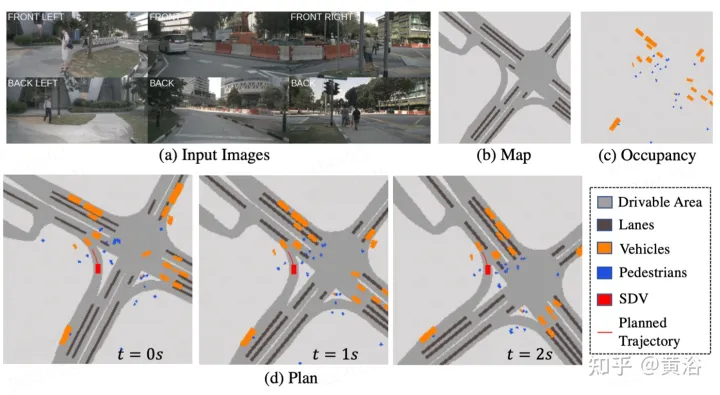
Wie in der Abbildung beschriebenST-P3Gesamtrahmen: Geben Sie insbesondere anhand einer Reihe umgebender Kameravideos diese in das Backbone ein, um vorläufige Vorderansichtsfunktionen zu generieren. Führt eine zusätzliche Tiefenschätzung durch, um 2D-Features in 3D-Raum umzuwandeln. Das selbstzentrierte Ausrichtungsakkumulationsschema richtet zunächst vergangene Features am aktuellen Ansichtskoordinatensystem aus. Aktuelle und vergangene Features werden dann im dreidimensionalen Raum aggregiert, wobei die geometrischen Informationen vor der Konvertierung in die BEV-Darstellung erhalten bleiben. Zusätzlich zum häufig verwendeten Zeitbereichsmodell „Vorhersage“ wird die Leistung durch die Konstruktion eines zweiten Pfads zur Erklärung vergangener Bewegungsänderungen weiter verbessert. Diese Dual-Path-Modellierung gewährleistet eine stärkere Merkmalsdarstellung, um auf zukünftige semantische Ergebnisse zu schließen. Um das ultimative Ziel der Trajektorienplanung zu erreichen, werden die frühen Feature-Vorkenntnisse des Netzwerks integriert. Ein Verfeinerungsmodul wurde entwickelt, um die endgültige Flugbahn mithilfe von Befehlen auf hoher Ebene zu generieren, wenn keine HD-Karten vorhanden sind.
Wie im Bild gezeigt, handelt es sich um die egozentrische Ausrichtungsakkumulationsmethode der 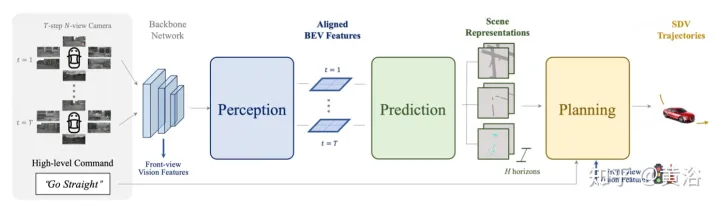 Wahrnehmung
Wahrnehmung
Wie in der Abbildung gezeigt, handelt es sich um ein Zwei-Wege-Modell für 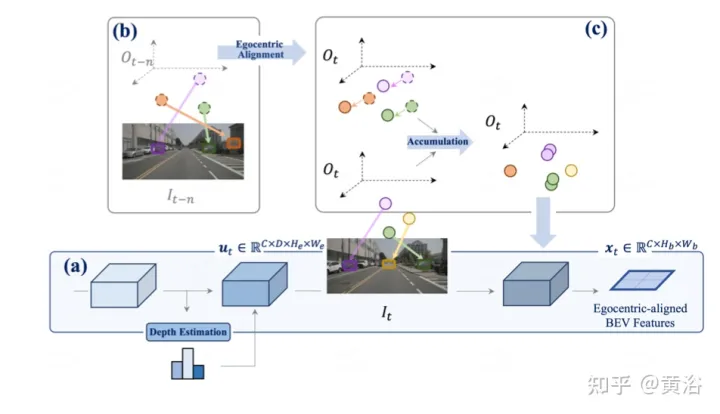 Vorhersage
Vorhersage
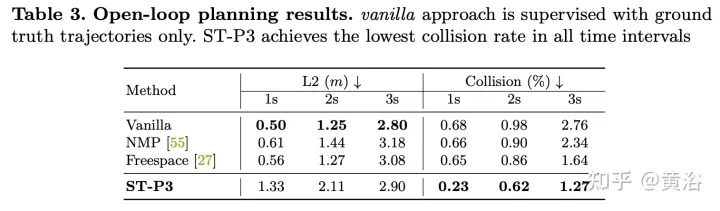
Als ultimatives Ziel müssen Sie eine sichere und bequeme Flugbahn planen, um den Zielpunkt zu erreichen. Dieser Bewegungsplaner tastet eine Reihe verschiedener Trajektorien ab und wählt eine aus, die die erlernte Kostenfunktion minimiert. Die Integration von Informationen von Zielpunkten und Ampeln über ein Zeitbereichsmodell bringt jedoch zusätzliche Optimierungsschritte mit sich. 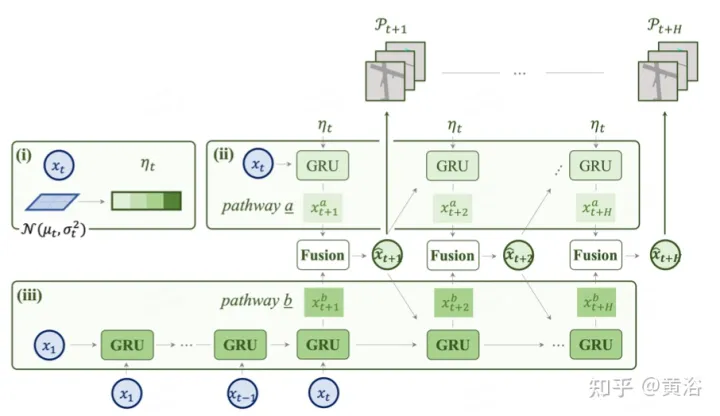
Planung
: Das Gesamtkostendiagramm umfasst zwei Teilkosten. Flugbahnen mit minimalen Kosten werden mithilfe zukunftsweisender Funktionen zur Aggregation visionsbasierter Informationen aus Kameraeingaben weiter neu definiert.
Trajektorien mit großer Querbeschleunigung, Ruck oder Krümmung bestrafen. Hoffentlich wird dieser Weg sein Ziel effizient erreichen, so dass Fortschritte belohnt werden. Die oben genannten Kostenpositionen enthalten jedoch keine Zielinformationen, die normalerweise von Routenkarten bereitgestellt werden. Verwenden Sie übergeordnete Befehle, einschließlich Vorwärts, Linksabbiegen und Rechtsabbiegen, und bewerten Sie Flugbahnen nur anhand der entsprechenden Befehle. 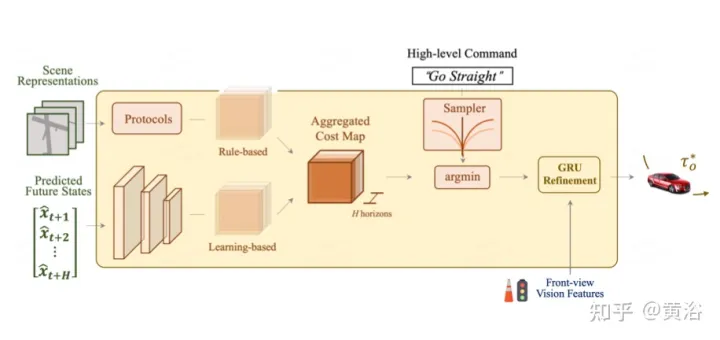
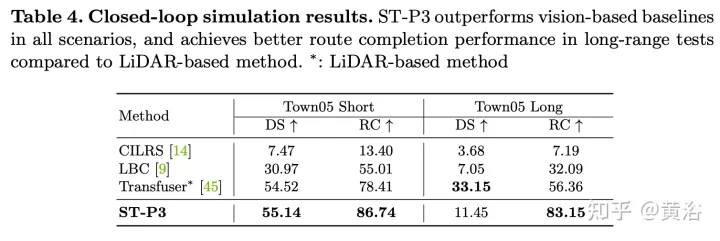
Das obige ist der detaillierte Inhalt vonST-P3: Durchgängige räumlich-zeitliche Feature-Learning-Vision-Methode für autonomes Fahren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr