
Heim >Technologie-Peripheriegeräte >KI >Sparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung
Sparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-11-24 11:21:35878Durchsuche
Neuer Titel: Sparse4D v3: Weiterentwicklung der End-to-End-3D-Erkennungs- und Tracking-Technologie
Papierlink: https://arxiv.org/pdf/2311.11722.pdf
Der Inhalt, der neu geschrieben werden muss, ist: Code-Link: https://github.com/linxuewu/Sparse4D
Umgeschriebener Inhalt: Die Zugehörigkeit des Autors ist Horizon Corporation

Thesis-Idee:
Im autonomen Fahrerkennungssystem sind 3D-Erkennung und -Verfolgung zwei grundlegende Aufgaben. Dieser Artikel befasst sich eingehender mit diesem Bereich basierend auf dem Sparse4D-Framework. In diesem Artikel werden zwei zusätzliche Trainingsaufgaben vorgestellt (Temporal Instance Denoising und Quality Estimation) und eine entkoppelte Aufmerksamkeit vorgeschlagen, um die Struktur zu verbessern und dadurch die Erkennungsleistung erheblich zu verbessern. Darüber hinaus erweitert dieser Artikel den Detektor auf den Tracker, indem er eine einfache Methode verwendet, die während der Inferenz Instanz-IDs zuweist, was die Vorteile abfragebasierter Algorithmen weiter hervorhebt. Umfangreiche Experimente zum nuScenes-Benchmark bestätigen die Wirksamkeit der vorgeschlagenen Verbesserungen. Mit ResNet50 als Rückgrat stiegen mAP, NDS und AMOTA um 3,0 %, 2,2 % bzw. 7,6 % und erreichten 46,9 %, 56,1 % bzw. 49,0 %. Das beste Modell in diesem Artikel erreichte 71,9 % NDS und 67,7 % AMOTA auf dem nuScenes-Testset Schätzung und Entkopplung der Aufmerksamkeit
Dieses Papier erweitert Sparse4D zu einem End-to-End-Tracking-Modell. Dieses Dokument zeigt die Wirksamkeit der nuScenes-Verbesserungen und die Erzielung modernster Leistung bei Erkennungs- und Verfolgungsaufgaben.
Netzwerkdesign:Erstens wird beobachtet, dass spärliche Algorithmen im Vergleich zu dichten Algorithmen größeren Herausforderungen bei der Konvergenz gegenüberstehen, was sich auf die endgültige Leistung auswirkt. Dieses Problem wurde im Bereich der 2D-Erkennung gut untersucht [17, 48, 53], hauptsächlich weil spärliche Algorithmen eine Eins-zu-eins-positive Stichprobenübereinstimmung verwenden. Diese Matching-Methode ist in den frühen Phasen des Trainings instabil und im Vergleich zum Eins-zu-viele-Matching ist die Anzahl positiver Proben begrenzt, wodurch die Effizienz des Decoder-Trainings verringert wird. Darüber hinaus verwendet Sparse4D ein spärliches Feature-Sampling anstelle einer globalen Queraufmerksamkeit, was die Konvergenz des Encoders aufgrund der Knappheit positiver Samples weiter behindert. In Sparse4Dv2 wird eine dichte Tiefenüberwachung eingeführt, um diese Konvergenzprobleme, mit denen Bildencoder konfrontiert sind, teilweise zu lindern. Das Hauptziel dieses Artikels besteht darin, die Modellleistung zu verbessern, indem der Schwerpunkt auf der Stabilität des Decodertrainings liegt. In diesem Artikel wird die Rauschunterdrückungsaufgabe als Hilfsüberwachung verwendet und die Rauschunterdrückungstechnologie von der 2D-Einzelbilderkennung auf die zeitliche 3D-Erkennung erweitert. Dadurch wird nicht nur ein stabiler positiver Probenabgleich gewährleistet, sondern auch die Anzahl positiver Proben deutlich erhöht. Darüber hinaus wird in diesem Artikel auch eine Qualitätsbewertungsaufgabe als Hilfsaufsicht vorgestellt. Dadurch wird der Konfidenzwert der Ausgabe angemessener, die Genauigkeit der Rangfolge der Erkennungsergebnisse verbessert und somit höhere Bewertungsindikatoren erzielt. Darüber hinaus verbessert dieser Artikel die Struktur der Instanz-Selbstaufmerksamkeits- und zeitlichen Queraufmerksamkeitsmodule in Sparse4D und stellt einen entkoppelten Aufmerksamkeitsmechanismus vor, der darauf abzielt, Funktionsinterferenzen im Aufmerksamkeitsgewichtungsberechnungsprozess zu reduzieren. Durch die Verwendung von Ankereinbettungen und Instanzmerkmalen als Eingaben für die Aufmerksamkeitsberechnung können Instanzen mit Ausreißern in den Aufmerksamkeitsgewichten reduziert werden. Dadurch kann die Korrelation zwischen Zielmerkmalen genauer wiedergegeben werden, wodurch eine korrekte Merkmalsaggregation erreicht wird. In diesem Artikel werden Verbindungen anstelle von Aufmerksamkeitsmechanismen verwendet, um diesen Fehler erheblich zu reduzieren. Diese Erweiterungsmethode weist Ähnlichkeiten mit dem bedingten DETR auf, der Hauptunterschied besteht jedoch darin, dass in diesem Artikel die Aufmerksamkeit zwischen Abfragen betont wird, während sich das bedingte DETR auf die gegenseitige Aufmerksamkeit zwischen Abfragen und Bildmerkmalen konzentriert. Darüber hinaus beinhaltet dieser Artikel auch eine einzigartige Codierungsmethode
Um die End-to-End-Funktionen des Wahrnehmungssystems zu verbessern, untersucht dieser Artikel die Methode zur Integration von 3D-Multi-Target-Tracking-Aufgaben in das Sparse4D-Framework, um die direkt auszugeben Bewegungsbahn des Ziels. Im Gegensatz zu erkennungsbasierten Tracking-Methoden integriert dieses Dokument alle Tracking-Funktionen in den Detektor, indem die Notwendigkeit einer Datenzuordnung und -filterung entfällt. Darüber hinaus erfordert unser Tracker im Gegensatz zu bestehenden Methoden zur Gelenkerkennung und -verfolgung keine Modifikation oder Anpassung der Verlustfunktion während des Trainings. Es erfordert keine Bereitstellung von Ground-Truth-IDs, implementiert jedoch eine vordefinierte Instanz-zu-Track-Regression. Die Tracking-Implementierung dieses Artikels integriert den Detektor und den Tracker vollständig, ohne den Trainingsprozess des Detektors zu ändern und ohne zusätzliche Feinabstimmung. Dies ist Abbildung 1 über die Übersicht über das Sparse4D-Framework. Die Eingabe ist a Multi-View-Video und die Ausgabe sind alle Wahrnehmungsergebnisse von Frames
Abbildung 2: Inferenzeffizienz (FPS) – Wahrnehmungsleistung (mAP) auf dem nuScenes-Validierungsdatensatz verschiedener Algorithmen.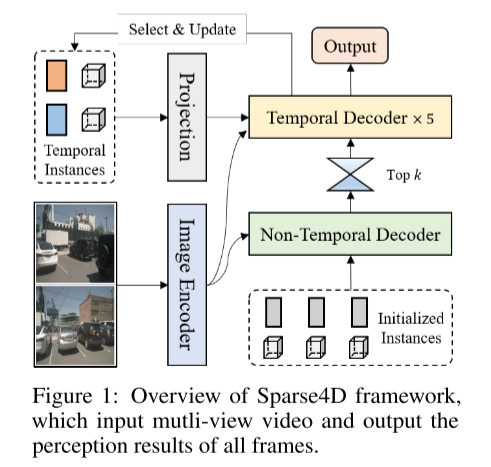
Abbildung 3: Visualisierung der Aufmerksamkeitsgewichte bei der Instanz-Selbstaufmerksamkeit: 1) Die erste Zeile zeigt die Aufmerksamkeitsgewichte bei der normalen Selbstaufmerksamkeit, wobei der Fußgänger im roten Kreis einen Unfall mit dem Zielfahrzeug (grünes Kästchen) zeigt. Korrelation. 2) Die zweite Zeile zeigt das Aufmerksamkeitsgewicht bei entkoppelter Aufmerksamkeit, wodurch dieses Problem effektiv gelöst wird.
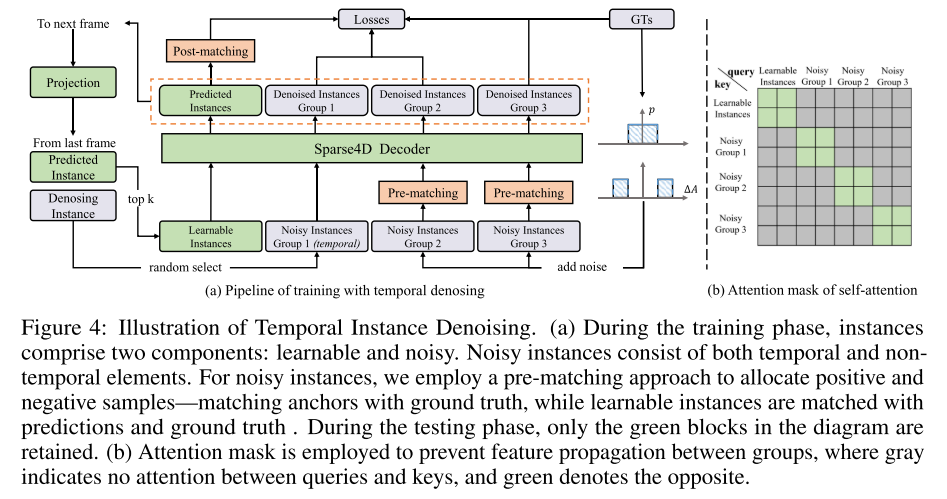
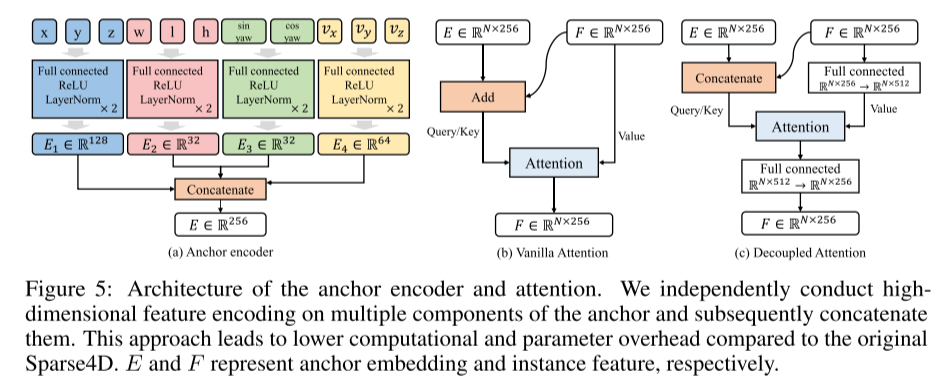
Das vierte Bild zeigt ein Beispiel für die Entrauschung von Zeitreiheninstanzen. Während der Trainingsphase bestehen Instanzen aus zwei Teilen: lernbar und laut. Rauschinstanzen bestehen aus zeitlichen und nichtzeitlichen Elementen. In diesem Artikel wird eine Pre-Matching-Methode verwendet, um positive und negative Stichproben zuzuordnen, d. h. Anker werden mit der Grundwahrheit abgeglichen, während lernbare Instanzen mit Vorhersagen und der Grundwahrheit abgeglichen werden. Während der Testphase bleiben nur grüne Blöcke übrig. Um zu verhindern, dass sich Features zwischen Gruppen ausbreiten, wird eine Aufmerksamkeitsmaske verwendet. Grau bedeutet, dass es keine Aufmerksamkeit zwischen Abfragen und Schlüsseln gibt. Grün bedeutet das Gegenteil. Siehe Abbildung 5: Architektur von Anker-Encoder und Aufmerksamkeit. In diesem Artikel werden hochdimensionale Merkmale mehrerer Ankerkomponenten unabhängig voneinander codiert und anschließend verkettet. Dieser Ansatz reduziert den Rechen- und Parameteraufwand im Vergleich zum ursprünglichen Sparse4D. E und F repräsentieren Ankereinbettungs- und Instanzfunktionen die Erkennungsleistung von Sparse4D . Diese Verbesserung umfasst hauptsächlich drei Aspekte: zeitliche Instanzentrauschung, Qualitätsschätzung und entkoppelte Aufmerksamkeit. Anschließend erläutert der Artikel den Prozess der Erweiterung von Sparse4D zu einem End-to-End-Tracking-Modell. Die Experimente dieses Artikels zu nuScenes zeigen, dass diese Verbesserungen die Leistung erheblich verbessern und Sparse4Dv3 an die Spitze des Feldes bringen.
 Zitat:
Zitat:
 ArXiv. /abs/2311.11722
ArXiv. /abs/2311.11722
Das obige ist der detaillierte Inhalt vonSparse4D v3 ist da! Weiterentwicklung der End-to-End-3D-Erkennung und -Verfolgung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Bard wurde auf ChatGPT-Daten geschult? Die Top-Wissenschaftler von Google protestierten erfolglos und verließen OpenAI
- Googles führender KI-Experte schließt sich OpenAI an und warnt Google davor, ChatGPT-Daten zum Trainieren von Bard zu verwenden
- Erforschung zukünftiger autonomer Fahrtechnologie: 4D-Millimeterwellenradar
- Google schlägt ein datenfreies NAS vor, das nur ein vorab trainiertes Modell für die Websuche erfordert
- So verwenden Sie PyTorch für das Training neuronaler Netzwerke