
Heim >Technologie-Peripheriegeräte >KI >Welche Technologien steckt ByteDance hinter der missverstandenen „chinesischen Version von Sora'?
Welche Technologien steckt ByteDance hinter der missverstandenen „chinesischen Version von Sora'?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-12 22:55:021192Durchsuche
Anfang 2024 veröffentlichte OpenAI einen Blockbuster im Bereich der generativen KI: Sora.
In den letzten Jahren haben sich die technologischen Iterationen im Bereich der Videogenerierung immer weiter beschleunigt, und viele Technologieunternehmen haben auch relevante technologische Fortschritte und Implementierungsergebnisse angekündigt. Zuvor hatten Pika und Runway ähnliche Produkte auf den Markt gebracht, aber die von Sora veröffentlichte Demo hat die Standards im Bereich der Videogenerierung eindeutig im Alleingang angehoben.
Im zukünftigen Wettbewerb ist noch nicht bekannt, welches Unternehmen als erstes ein Produkt entwickeln wird, das Sora übertrifft.
Hier in China liegt der Fokus auf einer Reihe großer Technologiehersteller.
Zuvor wurde berichtet, dass Bytedance vor der Veröffentlichung von Sora ein Videogenerierungsmodell namens Boximator entwickelt hatte.
Boximator bietet eine Möglichkeit, die Generierung von Objekten in Videos präzise zu steuern. Anstatt komplexe Textanweisungen zu schreiben, können Benutzer einfach ein Kästchen im Referenzbild zeichnen, um das Ziel auszuwählen, und dann zusätzliche Kästchen und Linien hinzufügen, um die Endposition des Ziels oder den gesamten bildübergreifenden Bewegungspfad zu definieren, wie unten gezeigt:

ByteDance hat sich diesbezüglich bedeckt gehalten, in den Medien antworteten sie, dass es sich bei Boximator um ihr Projekt zur Erforschung technischer Methoden zur Steuerung von Objektbewegungen im Bereich der Videogenerierung handelt. Es ist noch nicht ganz fertig und hinsichtlich Bildqualität, Wiedergabetreue und Videodauer besteht immer noch ein großer Abstand zu führenden ausländischen Videogenerationsmodellen.
Im entsprechenden technischen Dokument (https://arxiv.org/abs/2402.01566) wird erwähnt, dass Boximator als Plug-in läuft und problemlos in bestehende Videogenerierungsmodelle integriert werden kann. Durch das Hinzufügen von Bewegungssteuerungsfunktionen wird nicht nur die Videoqualität aufrechterhalten, sondern auch die Flexibilität und Benutzerfreundlichkeit verbessert.
Die Videoerzeugung umfasst Technologien in mehreren Unterbereichen und steht in engem Zusammenhang mit Bild-/Videoverständnis, Bilderzeugung, Superauflösung und anderen Technologien. Nach eingehender Recherche wurde festgestellt, dass ByteDance einige Forschungsergebnisse in mehreren Branchen öffentlich veröffentlicht hat.
In diesem Artikel werden 9 Studien des intelligenten Kreationsteams von ByteDance vorgestellt, die die neuesten Ergebnisse von Vincent-Bildern, Vincent-Videos, Videos von Tu-Studenten, Videoverständnis usw. umfassen. Wir könnten genauso gut den technologischen Fortschritt bei der Erforschung visueller generativer Modelle anhand dieser Studien verfolgen.
Welche Erfolge hat Byte in Bezug auf die Videogenerierung vorzuweisen?
Anfang Januar dieses Jahres veröffentlichte ByteDance ein Videogenerierungsmodell MagicVideo-V2, das einst heftige Diskussionen in der Community auslöste.

- Papiertitel: MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
- Papierlink: https://arxiv.org/abs/2401.04468
- Projektadresse: https://magicvideov2.github.io/
Die Innovation von MagicVideo-V2 besteht darin, Text-zu-Bild-Modell, Videobewegungsgenerator, Referenzbild-Einbettungsmodul und Frame-Interpolationsmodul in das zu integrieren end In der End-to-End-Videogenerierungspipeline. Dank dieses Architekturdesigns kann MagicVideo-V2 eine stabile Leistung auf hohem Niveau in Bezug auf „Ästhetik“ aufrechterhalten und nicht nur schöne hochauflösende Videos erzeugen, sondern auch eine relativ gute Wiedergabetreue und Glätte aufweisen.
Konkret verwendeten die Forscher zunächst das T2I-Modul, um ein 1024×1024-Bild zu erstellen, das die beschriebene Szene einkapselte. Das I2V-Modul animiert dann dieses statische Bild, um eine 600×600×32-Frame-Sequenz zu erzeugen, wobei das zugrunde liegende Rauschen die Kontinuität vom ursprünglichen Frame gewährleistet. Das V2V-Modul verbessert diese Bilder auf eine Auflösung von 1048 x 1048 und verfeinert gleichzeitig den Videoinhalt. Schließlich erweitert das Interpolationsmodul die Sequenz auf 94 Bilder, um ein Video mit einer Auflösung von 1048 x 1048 zu erhalten. Das generierte Video weist eine hohe ästhetische Qualität und zeitliche Glätte auf.
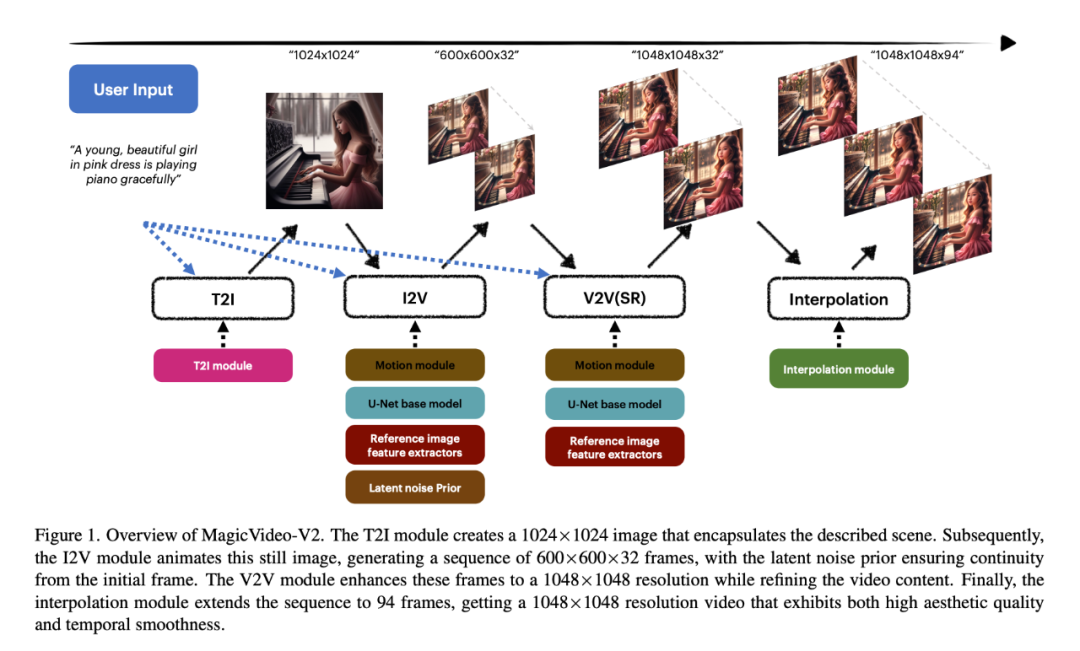
Eine von Forschern durchgeführte groß angelegte Benutzerbewertung hat gezeigt, dass MagicVideo-V2 beliebter ist als einige bekannte T2V-Methoden (grüne, graue und rosa Balken stellen dar, dass MagicVideo-V2 als besser, gleichwertig oder besser bewertet wird). bzw.) Differenz).

Hinter hochwertiger Videogenerierung
Das Forschungsparadigma, das Vision und Sprachlernen vereint
Aus dem MagicVideo-V2-Papier können wir ersehen, dass der Fortschritt der Videogenerierungstechnologie untrennbar miteinander verbunden ist . Wegbereiter für AIGC-Technologien wie Wenshengtu und Tushengvideo. Die Grundlage für die Generierung hochästhetischer Inhalte liegt im Verständnis, insbesondere in der Verbesserung der Fähigkeit des Modells, visuelle und sprachliche Modalitäten zu lernen und zu integrieren.
In den letzten Jahren haben die Skalierbarkeit und allgemeinen Fähigkeiten großer Sprachmodelle zu einem Forschungsparadigma geführt, das Vision und Sprachenlernen vereint. Um die natürliche Lücke zwischen den beiden Modalitäten „visuell“ und „Sprache“ zu schließen, verbinden Forscher die Darstellungen vorab trainierter großer Sprachmodelle und visueller Modelle, extrahieren modalübergreifende Merkmale und erledigen Aufgaben wie die visuelle Beantwortung von Fragen. Aufgaben wie Bildunterschriften, visuelle Wissensbegründung und Dialoge.
In diesen Richtungen hat ByteDance auch relevante Erkundungen durchgeführt.
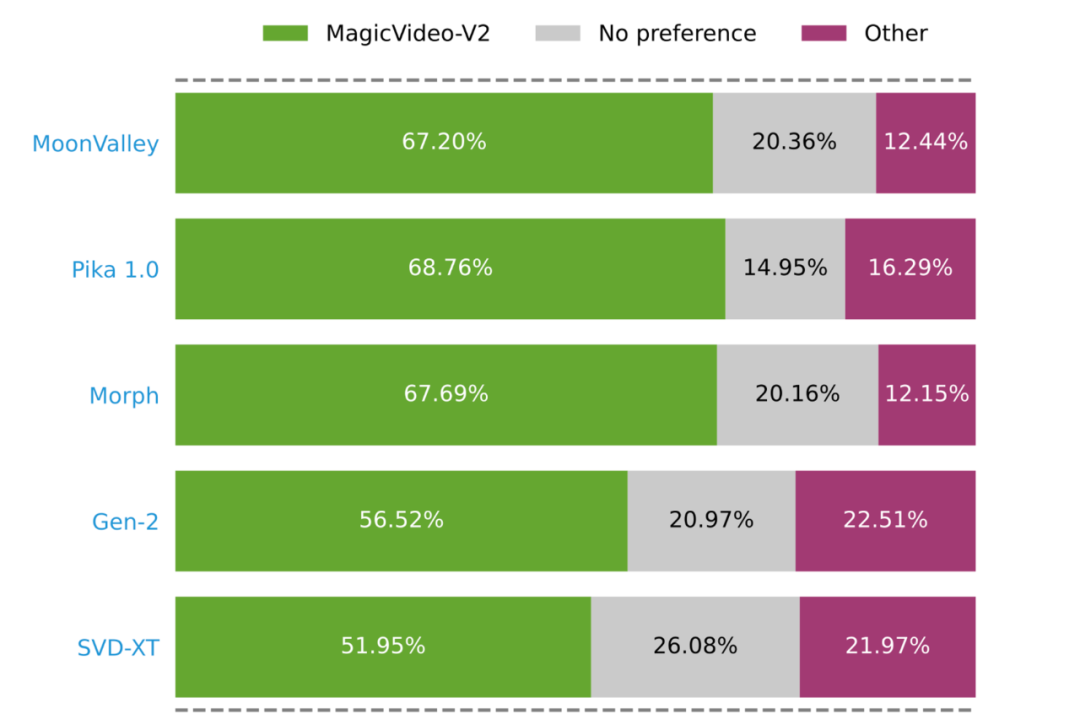
Um beispielsweise die Herausforderung des multiobjektiven Denkens und der Segmentierung bei Open-World-Vision-Aufgaben anzugehen, hat ByteDance mit Forschern der Beijing Jiaotong University und der University of Science and Technology Beijing zusammengearbeitet, um ein effizientes großformatiges Pixel-Modell vorzuschlagen. Level Reasoning-Modell, PixelLM, entwickelt und als Open Source bereitgestellt.

- Papiertitel: PixelLM: Pixel Reasoning with Large Multimodal Model
- Papierlink: https://arxiv.org/pdf/2312.02228.pdf
- Projektadresse: https://pixellm.github.io/
PixelLM kann Aufgaben mit einer beliebigen Anzahl offener Zielsetzungen und unterschiedlicher Argumentationskomplexität geschickt bewältigen. Die folgende Abbildung zeigt PixelLM in verschiedenen Segmentierungsaufgaben hochwertige Zielmasken.

Der Kern von PixelLM ist ein neuartiger Pixeldecoder und ein Segmentierungscodebuch: Das Codebuch enthält lernbare Token, die Kontext und Wissen in Bezug auf Zielreferenzen in verschiedenen visuellen Maßstäben kodieren, und der Pixeldecoder basiert auf versteckten Einbettungen von Codebuch-Tokens und Bildfunktionen generieren Zielmasken. Unter Beibehaltung der Grundstruktur von LMM kann PixelLM hochwertige Masken ohne zusätzliche, teure visuelle Segmentierungsmodelle generieren und so die Effizienz und Übertragbarkeit auf verschiedene Anwendungen verbessern.
Es ist erwähnenswert, dass die Forscher einen umfassenden MUSE-Datensatz zur Inferenzsegmentierung mit mehreren Zielen erstellt haben. Sie wählten insgesamt 910.000 hochwertige Instanzsegmentierungsmasken und detaillierte Textbeschreibungen basierend auf Bildinhalten aus dem LVIS-Datensatz aus und erstellten daraus 246.000 Frage-Antwort-Paare.
Im Vergleich zu Bildern wird das Modell bei Videoinhalten vor viel mehr Herausforderungen stehen. Denn Videos enthalten nicht nur reichhaltige und vielfältige visuelle Informationen, sondern beinhalten auch dynamische Veränderungen in Zeitreihen.
Wenn bestehende große multimodale Modelle Videoinhalte verarbeiten, konvertieren sie normalerweise Videobilder in eine Reihe visueller Token und kombinieren sie mit Sprachtokens, um Text zu generieren. Mit zunehmender Länge des generierten Textes wird jedoch der Einfluss des Videoinhalts allmählich schwächer, sodass der generierte Text immer mehr vom ursprünglichen Videoinhalt abweicht und sogenannte „Illusionen“ entstehen.
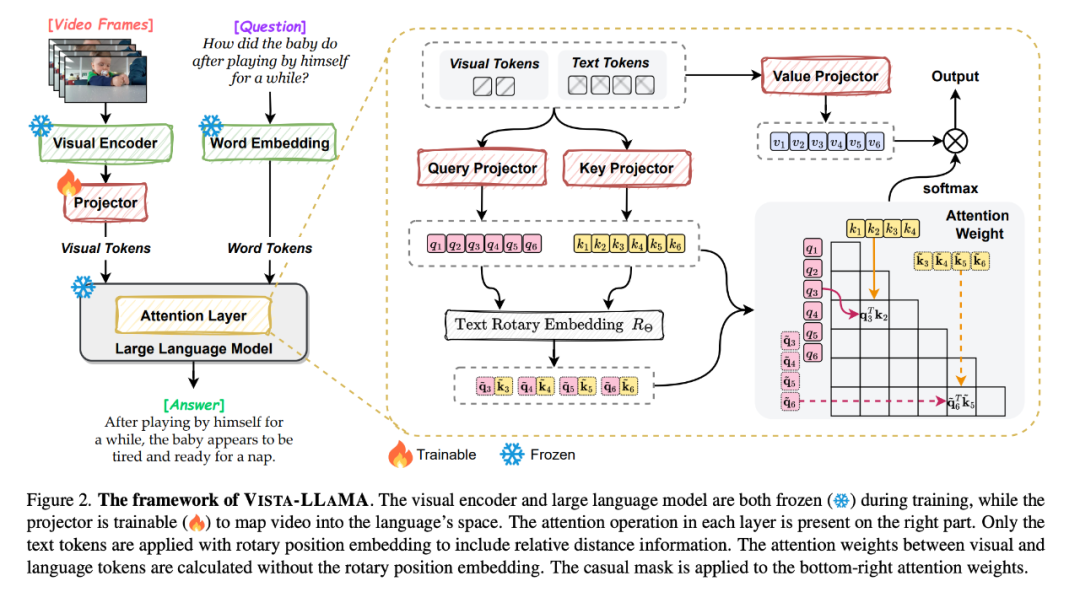
Angesichts dieses Problems schlugen ByteDance und die Zhejiang-Universität Vista-LLaMA vor, ein multimodales großes Modell, das speziell für die Komplexität von Videoinhalten entwickelt wurde.

- Papiertitel: Vista-LLaMA: Reliable Video Narrator via Equal Distance to Visual Tokens
- Papierlink: https://arxiv.org/pdf/2312.08870.pdf
- Projektadresse : https://jinxxian.github.io/Vista-LLaMA/
Vista-LLaMA übernimmt einen verbesserten Aufmerksamkeitsmechanismus – Visual Equidistant Token Attention (EDVT) zur Verarbeitung von Bild und Text. Token entfernt die traditionelle Codierung der relativen Position, während Beibehaltung der relativen Positionskodierung zwischen Text. Diese Methode verbessert die Tiefe und Genauigkeit des Verständnisses von Videoinhalten durch das Sprachmodell erheblich.
Insbesondere der von Vista-LLaMA eingeführte serialisierte visuelle Projektor bietet eine neue Perspektive auf Zeitreihenanalyseprobleme in Videos. Er kodiert den zeitlichen Kontext visueller Token durch eine lineare Projektionsebene und verbessert so die Reaktion des Modells auf dynamische Änderungen das Video.
In einer kürzlich von ICLR 2024 angenommenen Studie untersuchten ByteDance-Forscher auch eine Vortrainingsmethode, um die Fähigkeit des Modells, Videoinhalte zu lernen, zu verbessern.
Aufgrund des begrenzten Umfangs und der begrenzten Qualität des Videotext-Trainingskorpus verwenden die meisten Basismodelle für visuelle Sprache Bild-Text-Datensätze für das Vortraining und konzentrieren sich hauptsächlich auf die Modellierung der visuellen semantischen Darstellung, während die zeitliche semantische Darstellung und das Korrelationsgeschlecht ignoriert werden.
Um dieses Problem zu lösen, schlugen sie COSA vor, ein verkettetes Beispiel für ein vorab trainiertes visuelles Sprachbasismodell.

- Papiertitel: COSA: Concatenated Sample Pretrained Vision-Language Foundation Model
- Papierlink: https://arxiv.org/pdf/2306.09085.pdf
- Projekthomepage: https://github.com/TXH-mercury/COSA
COSA modelliert gemeinsam visuelle Inhalte und zeitliche Hinweise auf Ereignisebene, indem es ausschließlich Bild-Text-Korpora verwendet. Die Forscher verketteten mehrere Bild-Text-Paare nacheinander als Eingabe für das Vortraining. Diese Transformation wandelt effektiv ein vorhandenes Bild-Text-Korpus in ein pseudolanges Video-Absatz-Korpus um und ermöglicht so reichhaltigere Szenenübergänge und explizite Ereignis-Beschreibungs-Korrespondenzen. Experimente zeigen, dass COSA die Leistung bei einer Vielzahl nachgelagerter Aufgaben, einschließlich langer/kurzer Videotextaufgaben und Bildtextaufgaben wie Abrufen, Untertitel und Beantworten von Fragen, kontinuierlich verbessern kann.

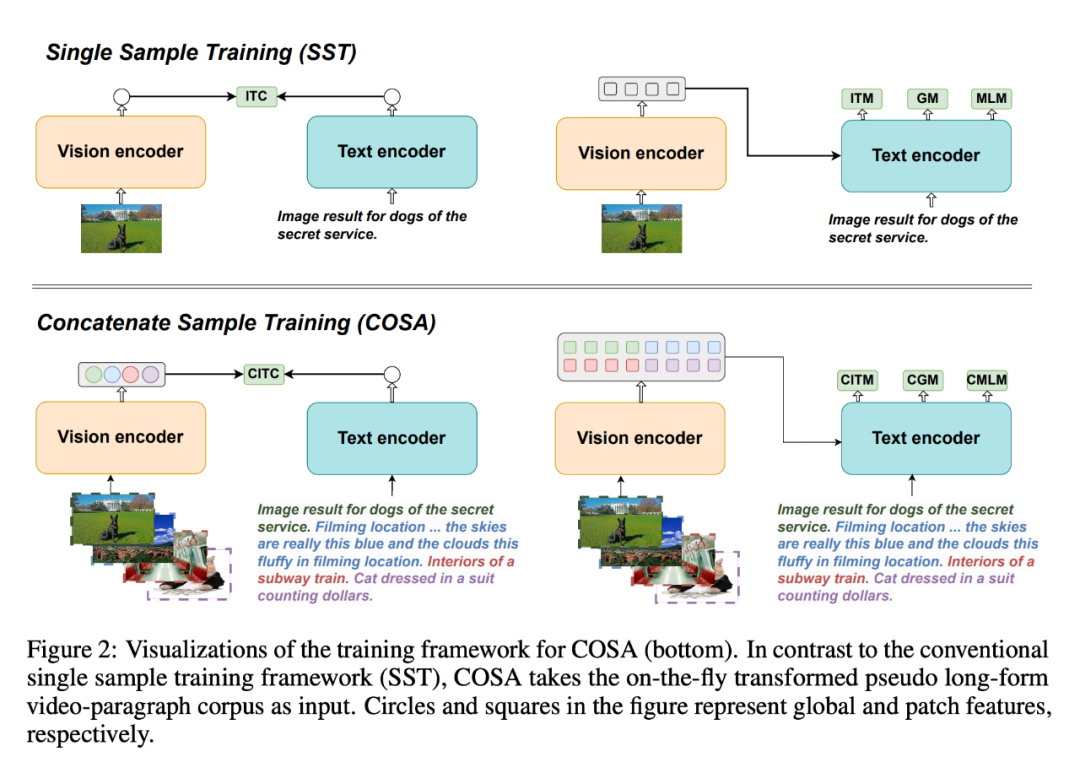
Vom Bild zum Video
Das wiedererkannte „Diffusionsmodell“
Neben dem visuell-linguistischen Modell ist auch das Diffusionsmodell eine Technologie, die von den meisten Videos verwendet wird Generationsmodelle.
Durch rigoroses Training an großen gepaarten Bild-Text-Datensätzen sind Diffusionsmodelle in der Lage, detaillierte Bilder vollständig auf der Grundlage von Textinformationen zu generieren. Zusätzlich zur Bildgenerierung können Diffusionsmodelle auch zur Audiogenerierung, Zeitreihengenerierung, 3D-Punktwolkengenerierung und mehr verwendet werden.
In einigen Kurzvideoanwendungen müssen Benutzer beispielsweise nur ein Bild bereitstellen, um ein gefälschtes Aktionsvideo zu erstellen.
Mona Lisa, die seit Hunderten von Jahren ein geheimnisvolles Lächeln behält, kann sofort mit dem Laufen beginnen:

Die Technologie hinter dieser interessanten Anwendung ist eine gemeinsame Anstrengung von Forschern der National University of Singapore und ByteDance „MagicAnimate“ gestartet.
MagicAnimate ist ein diffusionsbasiertes Framework für die Animation menschlicher Bilder, das die zeitliche Konsistenz der gesamten Animation gewährleisten und die Animationstreue bei der Erstellung von Videos basierend auf bestimmten Bewegungssequenzen verbessern kann. Darüber hinaus ist das MagicAnimate-Projekt Open Source.

- Papiertitel: MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
- Papierlink: https://arxiv.org/pdf/2311.16498.pdf
- Projektadresse: https://showlab.github.io/magicanimate/
Um das häufige Problem des „Flackerns“ generierter Animationen zu lösen, haben die Forscher den Block der zeitlichen Aufmerksamkeit (zeitliche Aufmerksamkeit) in das Diffusionsrückgrat integriert Netzwerk, um ein Videodiffusionsmodell für die zeitliche Modellierung zu erstellen.
MagicAnimate zerlegt das gesamte Video in überlappende Segmente und mittelt einfach die Vorhersagen der überlappenden Frames. Schließlich führten die Forscher auch eine gemeinsame Bild-Video-Trainingsstrategie ein, um die Fähigkeit zur Referenzbildspeicherung und die Einzelbildtreue weiter zu verbessern. Obwohl MagicAnimate nur auf echten menschlichen Daten trainiert wurde, hat es die Fähigkeit zur Verallgemeinerung auf eine Vielzahl von Anwendungsszenarien bewiesen, einschließlich der Animation unsichtbarer Domänendaten, der Integration mit Text-Bild-Diffusionsmodellen und der Animation mehrerer Personen.
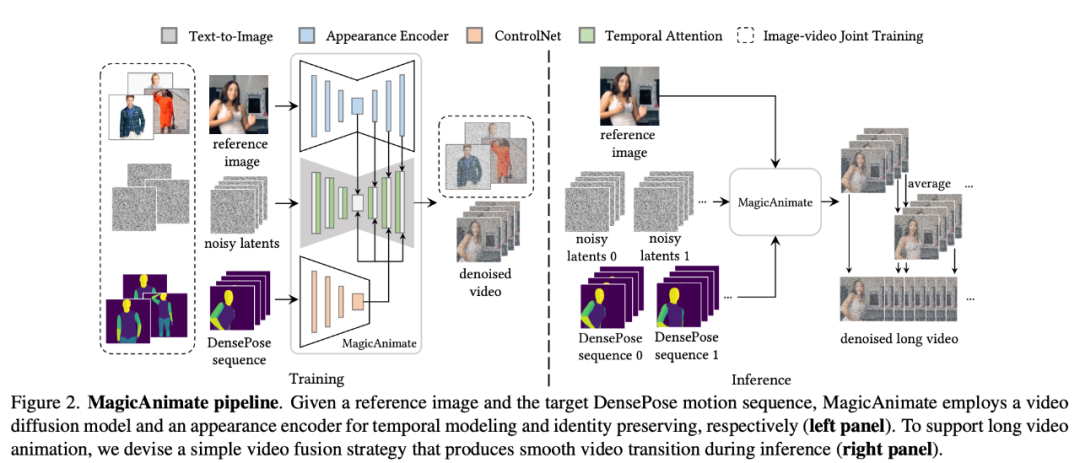
Eine weitere auf der Idee des Diffusionsmodells „DREAM-Talk“ basierende Forschung löst die Aufgabe, aus einem einzigen Porträtbild sprechende emotionale Gesichter zu generieren.

- Papiertitel: DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
- Link zum Papier: https://arxiv.org /pdf/2312.13578.pdf
- Projektadresse: https://dreamtalkemo.github.io/
Wir wissen, dass es bei dieser Aufgabe schwierig ist, gleichzeitig einen ausdrucksstarken emotionalen Dialog und eine genaue Lippensynchronisation zu erreichen Um die Genauigkeit der Lippensynchronisation sicherzustellen, wird die Ausdruckskraft normalerweise stark reduziert.
„DREAM-Talk“ ist ein diffusionsbasiertes audiogesteuertes Framework, das in zwei Phasen unterteilt ist: Zunächst schlugen die Forscher ein neuartiges Diffusionsmodul EmoDiff vor, das eine Vielzahl hochdynamischer Muster basierend auf Audio und emotionalen Referenzen erzeugen kann Stile. Emotionaler Ausdruck und Kopfhaltung. Angesichts der starken Korrelation zwischen Lippenbewegungen und Audio verbesserten die Forscher anschließend die Dynamik mithilfe von Audiofunktionen und emotionalen Stilen, um die Genauigkeit der Lippensynchronisation zu verbessern, und setzten außerdem ein Video-zu-Video-Rendering-Modul ein, um Ausdrücke und Lippenbewegungen auf jedes Porträt zu übertragen.
Aus Sicht der Wirkung ist DREAM-Talk in der Tat gut in Bezug auf Ausdruckskraft, Lippensynchronisationsgenauigkeit und wahrgenommene Qualität:

Aber ob es sich um Bilderzeugung oder Videoerzeugung handelt, das aktuelle Verbreitungsmodell Die Route basiert auf der Forschung und weist noch einige grundlegende Herausforderungen auf, die angegangen werden müssen.
Viele Menschen sind beispielsweise besorgt über die Qualität der generierten Inhalte (entsprechend SAG, DREAM-Talk). Dies hängt möglicherweise mit einigen Schritten im Generierungsprozess des Diffusionsmodells zusammen, beispielsweise mit der geführten Stichprobe.
Geführte Probenahme in Diffusionsmodellen lässt sich grob in zwei Kategorien einteilen: solche, die eine Schulung erfordern, und solche, die keine Schulung erfordern. Bei der ausbildungsfreien geführten Probenahme werden vorgefertigte, vorab trainierte Netzwerke (z. B. ästhetische Bewertungsmodelle) verwendet, um den Generierungsprozess zu leiten, mit dem Ziel, mit weniger Schritten und höherer Genauigkeit Erkenntnisse aus den vorab trainierten Modellen zu gewinnen. Aktuelle trainingsunabhängige Abtastalgorithmen basieren auf der einstufigen Schätzung sauberer Bilder, um die Führungsenergiefunktion zu erhalten. Da das vorab trainierte Netzwerk jedoch auf saubere Bilder trainiert wird, kann der einstufige Schätzprozess für saubere Bilder ungenau sein, insbesondere in den frühen Phasen des Diffusionsmodells, was zu einer ungenauen Führung in frühen Zeitschritten führt.
Als Reaktion auf dieses Problem haben Forscher von ByteDance und der National University of Singapore gemeinsam die Symplectic Adjoint Guidance (SAG) vorgeschlagen.

- Papiertitel: Towards Accurate Guided Diffusion Sampling through Symplegic Adjunkt Method
- Papierlink: https://arxiv.org/pdf/2312.12030.pdf
SAG Die Gradientenführung wird über zwei innere Stufen berechnet: Erstens schätzt SAG ein sauberes Bild durch n Funktionsaufrufe, wobei n als flexibler Parameter dient, der entsprechend den spezifischen Bildqualitätsanforderungen angepasst werden kann. Zweitens verwendet SAG die symmetrische Dual-Methode, um Gradienten in Bezug auf den Speicherbedarf genau und effizient zu erhalten. Dieser Ansatz kann eine Vielzahl von Bild- und Videogenerierungsaufgaben unterstützen, einschließlich stilgesteuerter Bildgenerierung, ästhetischer Verbesserung und Videostilisierung, und verbessert effektiv die Qualität der generierten Inhalte.
Ein kürzlich für ICLR 2024 ausgewählter Artikel konzentriert sich auf die „Methode der kritischen Empfindlichkeit der Gradienten-Backpropagation des Diffusionswahrscheinlichkeitsmodells“.

- Papiertitel: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models
- Papierlink: https://arxiv.org/pdf/2307.107 11.pdf
Da der Sampling-Prozess des Diffusionswahrscheinlichkeitsmodells rekursive Aufrufe an das entrauschende U-Net umfasst, muss die naive Gradienten-Backpropagation die Zwischenzustände aller Iterationen speichern, was zu einem extrem hohen Speicherverbrauch führt.
In diesem Artikel generiert das von den Forschern vorgeschlagene AdjointDPM zunächst neue Stichproben aus dem Diffusionsmodell, indem es die entsprechende probabilistische Fluss-ODE löst. Anschließend wird der Gradient des Verlusts der Modellparameter (einschließlich Konditionierungssignalen, Netzwerkgewichten und anfänglichem Rauschen) mithilfe der Adjazenzsensitivitätsmethode durch Lösen einer weiteren erweiterten ODE zurückpropagiert. Um numerische Fehler während der Vorwärtsgenerierung und der Gradienten-Rückausbreitung zu reduzieren, haben die Forscher die probabilistische Fluss-ODE und die erweiterte ODE mithilfe exponentieller Integration weiter in einfache, nicht starre ODEs umparametrisiert.
Die Forscher weisen darauf hin, dass AdjointDPM bei drei Aufgaben äußerst wertvoll ist: beim Umwandeln visueller Effekte in erkannte Texteinbettungen, bei der Feinabstimmung von Diffusions-Wahrscheinlichkeitsmodellen für bestimmte Arten der Stilisierung und bei der Optimierung des anfänglichen Rauschens, um bei Sicherheitsüberprüfungen kontroverse Beispiele zu reduzieren die Kosten für Optimierungsarbeiten.
Bei visuellen Wahrnehmungsaufgaben hat auch die Methode der Verwendung des Text-zu-Bild-Diffusionsmodells als Merkmalsextraktor immer mehr Aufmerksamkeit erhalten. In dieser Richtung haben ByteDance-Forscher in ihrem Artikel eine einfache und effektive Lösung vorgeschlagen.

- Papiertitel: Nutzung von Diffusionsmodellen für die visuelle Wahrnehmung mit Meta-Eingabeaufforderungen
- Papierlink: https://arxiv.org/pdf/2312.14733.pdf
Das Die Kerninnovation dieses Artikels ist die Einführung lernbarer Einbettungen (Meta-Hinweise) in vorab trainierte Diffusionsmodelle, um Wahrnehmungsmerkmale zu extrahieren, ohne auf zusätzliche multimodale Modelle zur Generierung von Bildunterschriften angewiesen zu sein oder Kategoriebezeichnungen im Datensatz zu verwenden.
Meta-Hinweise dienen zwei Zwecken: Erstens können sie als direkter Ersatz für Texteinbettungen in T2I-Modellen aufgabenrelevante Funktionen während der Merkmalsextraktion aktivieren; zweitens werden sie verwendet, um extrahierte Merkmale neu anzuordnen, um sicherzustellen, dass die Das Modell konzentriert sich auf die Funktionen, die für die jeweilige Aufgabe am relevantesten sind. Darüber hinaus entwickelten die Forscher auch eine zyklische Verfeinerungstrainingsstrategie, um die Eigenschaften des Diffusionsmodells vollständig zu nutzen und stärkere visuelle Merkmale zu erhalten.
Wie weit muss es noch gehen, bis die „chinesische Version von Sora“ geboren ist
?
In diesen neuen Artikeln haben wir von einer Reihe aktiver Erkundungen der Videogenerierungstechnologie durch inländische Technologieunternehmen wie ByteDance erfahren.
Aber im Vergleich zu Sora, sei es ByteDance oder eine Reihe von Starunternehmen im Bereich der KI-Videogenerierung, gibt es eine mit bloßem Auge sichtbare Lücke. Die Vorteile von Sora basieren auf seinem Glauben an das Skalierungsgesetz und bahnbrechenden technologischen Innovationen: Durch die Vereinheitlichung von Videodaten durch Patches, die Nutzung technischer Architekturen wie Diffusion Transformer und die semantischen Verständnisfähigkeiten von DALL・E 3 hat es wirklich „weite Fortschritte“ gemacht.
Von der Explosion von Wenshengtu im Jahr 2022 bis zur Entstehung von Sora im Jahr 2024 hat die Geschwindigkeit der technologischen Iteration im Bereich der künstlichen Intelligenz die Vorstellungskraft aller übertroffen. Ich glaube, dass es im Jahr 2024 weitere „heiße Produkte“ in diesem Bereich geben wird.
Byte erhöht offensichtlich auch die Investitionen in Technologieforschung und -entwicklung. Kürzlich wurde bekannt, dass Jiang Lu, Projektleiter von Google VideoPoet, und Chunyuan Li, Mitglied des LLaVA-Teams für multimodale Open-Source-Großmodelle und ehemaliger Chefforscher von Microsoft Research, dem ByteDance-Team für intelligente Erstellung beigetreten sind. Das Team rekrutiert außerdem energisch, und auf der offiziellen Website wurden zahlreiche Stellen im Zusammenhang mit großen Modellalgorithmen veröffentlicht.
Nicht nur Byte, auch alte Giganten wie BAT haben viele auffällige Forschungsergebnisse zur Videogenerierung veröffentlicht, und eine Reihe großer Modell-Startups sind noch aggressiver. Welche neuen Durchbrüche werden in der Vincent Video Technology erzielt? Wir werden sehen.
Das obige ist der detaillierte Inhalt vonWelche Technologien steckt ByteDance hinter der missverstandenen „chinesischen Version von Sora'?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!