
Heim >Technologie-Peripheriegeräte >KI >Lassen Sie uns über die Modellfusionsmethode großer Modelle sprechen
Lassen Sie uns über die Modellfusionsmethode großer Modelle sprechen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-11 13:10:15687Durchsuche
In früheren Praktiken wurde die Modellfusion häufig verwendet, insbesondere in Diskriminanzmodellen, wo sie als eine Methode angesehen wird, die die Leistung stetig verbessern kann. Allerdings ist die Funktionsweise generativer Sprachmodelle aufgrund des damit verbundenen Decodierungsprozesses nicht so einfach wie bei diskriminierenden Modellen.
Darüber hinaus sind aufgrund der zunehmenden Anzahl von Parametern großer Modelle in Szenarien mit größeren Parameterskalen die Methoden, die beim einfachen Ensemble-Lernen berücksichtigt werden können, eingeschränkter als beim maschinellen Lernen mit niedrigen Parametern, wie z. B. klassisches Stapeln. Boosting und andere Methoden, weil Das Parameterproblem des Stapelmodells kann nicht einfach erweitert werden. Daher erfordert das Ensemble-Lernen für große Modelle sorgfältige Überlegungen.
Im Folgenden erklären wir fünf grundlegende Integrationsmethoden, nämlich Modellintegration, probabilistische Integration, Grafting Learning, Crowdsourcing-Voting und MOE.
1. Die Modellintegration ist relativ einfach, das heißt, große Modelle werden auf der Ausgabetextebene integriert. Verwenden Sie beispielsweise einfach die Ausgabeergebnisse von drei verschiedenen LLama-Modellen und geben Sie sie als Eingabeaufforderungen in das vierte Modell ein Referenz. In der Praxis kann die Informationsübertragung durch Text als Kommunikationsmethode verwendet werden, die aus dem Artikel „Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication“ stammt. Das Rahmenwerk für den Gedankenaustausch, bekannt als „Exchange-of-Thought“, soll die gegenseitige Kommunikation zwischen Modellen erleichtern, um das kollektive Verständnis im Problemlösungsprozess zu verbessern. Durch dieses Framework können Modelle die Argumentation anderer Modelle übernehmen, um ihre eigenen Lösungen besser zu koordinieren und zu verbessern. Dargestellt durch das Diagramm im Artikel:
Bild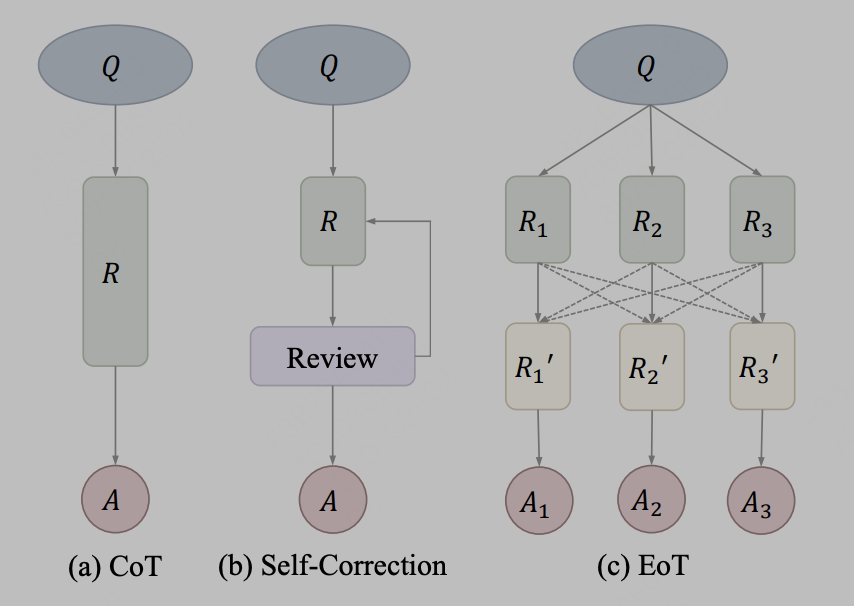 Nachdem der Autor CoT- und Selbstkorrekturmethoden als dasselbe Konzept behandelt, stellt EoT eine neue Methode bereit, die eine hierarchische Nachrichtenübermittlung zwischen mehreren Modellen ermöglicht. Durch die modellübergreifende Kommunikation können Modelle auf die Argumentations- und Denkprozesse der anderen zurückgreifen und so dazu beitragen, Probleme effizienter zu lösen. Es wird erwartet, dass dieser Ansatz die Leistung und Genauigkeit des Modells verbessert.
Nachdem der Autor CoT- und Selbstkorrekturmethoden als dasselbe Konzept behandelt, stellt EoT eine neue Methode bereit, die eine hierarchische Nachrichtenübermittlung zwischen mehreren Modellen ermöglicht. Durch die modellübergreifende Kommunikation können Modelle auf die Argumentations- und Denkprozesse der anderen zurückgreifen und so dazu beitragen, Probleme effizienter zu lösen. Es wird erwartet, dass dieser Ansatz die Leistung und Genauigkeit des Modells verbessert.
2. Probabilistisches Ensemble
Probabilistisches Ensemble weist Ähnlichkeiten mit traditionellen Methoden des maschinellen Lernens auf. Beispielsweise kann eine Ensemble-Methode durch Mittelung der vom Modell vorhergesagten Logit-Ergebnisse gebildet werden. In großen Modellen können probabilistische Ensembles auf der Ebene der Vokabularausgabewahrscheinlichkeiten des Transformatormodells fusioniert werden. Es ist wichtig zu beachten, dass dieser Vorgang erfordert, dass die Vokabulare der mehreren Originalmodelle, die zusammengeführt werden, konsistent sein müssen. Eine solche Integrationsmethode kann die Leistung und Robustheit des Modells verbessern und es für praktische Anwendungsszenarien geeigneter machen.
Nachfolgend geben wir eine einfache Pseudocode-Implementierung.
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
3. Grafting Learning
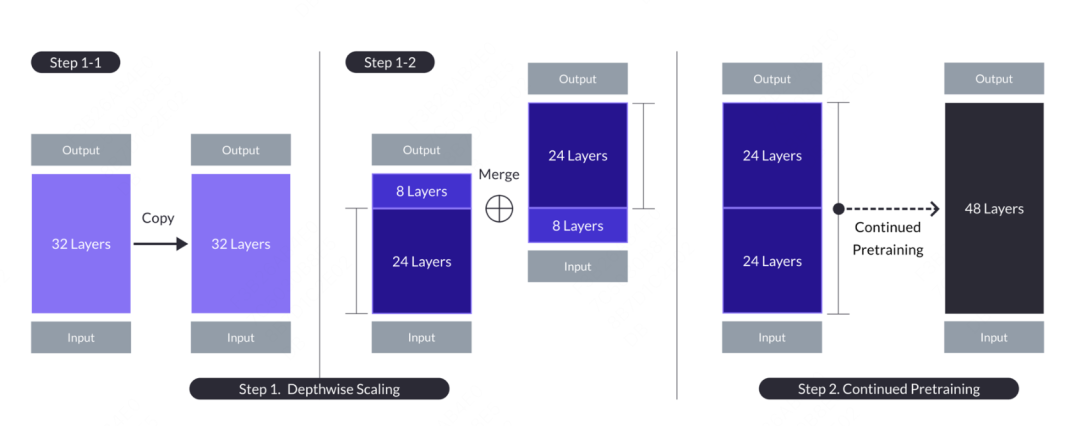
Das Konzept des Grafting Learning stammt aus dem inländischen Kaggle Grandmaster’s Plantsgo, das aus dem Data-Mining-Wettbewerb hervorgegangen ist. Es handelt sich im Wesentlichen um eine Art Transferlernen, das ursprünglich verwendet wurde, um die Methode zu beschreiben, die Ausgabe eines Baummodells als Eingabe eines anderen Baummodells zu verwenden. Diese Methode ähnelt der Veredelung bei der Baumvermehrung, daher der Name. In großen Modellen gibt es auch die Anwendung des Grafting-Lernens. Der Artikel stammt aus „SOLAR 10.7B: Skalierung großer Sprachmodelle mit einfacher, aber effektiver Tiefenskalierung“. Im Gegensatz zum Pfropflernen beim maschinellen Lernen fusioniert das große Modell nicht direkt die Wahrscheinlichkeitsergebnisse eines anderen Modells, sondern pfropft einen Teil der Struktur und Gewichte auf das Fusionsmodell und durchläuft dazu einen bestimmten Vortrainingsprozess Es können Modellparameter an neue Modelle angepasst werden. Der konkrete Vorgang besteht darin, das Grundmodell mit n Schichten zur späteren Änderung zu kopieren. Dann werden die letzten m Schichten aus dem Originalmodell und die ersten m Schichten aus seiner Kopie entfernt, was zu zwei verschiedenen n-m-Schichtenmodellen führt. Abschließend werden die beiden Modelle zu einem skalierten Modell mit 2*(n-m) Schichten verkettet.
Wenn Sie ein 48-Schichten-Zielmodell erstellen müssen, können Sie in Betracht ziehen, die ersten 24 Schichten und die letzten 24 Schichten von zwei 32-Schichten-Modellen zu nehmen und sie zu einem neuen 48-Schichten-Modell zu verbinden. Anschließend wird das kombinierte Modell weiter vorab trainiert. Im Allgemeinen erfordert die Fortsetzung des Vortrainings weniger Datenvolumen und weniger Rechenressourcen als das Training von Grund auf.
 Bilder
Bilder
Nach der Fortsetzung des Vortrainings muss ein Ausrichtungsvorgang durchgeführt werden, der zwei Prozesse umfasst, nämlich die Feinabstimmung der Anweisungen und DPO. Die Befehlsfeinabstimmung nutzt Open-Source-Befehlsdaten und wandelt sie in mathematikspezifische Befehlsdaten um, um die mathematischen Fähigkeiten des Modells zu verbessern. DPO ist ein Ersatz für das traditionelle RLHF, das schließlich zur SOLAR-Chat-Version wurde.
4. Crowdsourcing-Abstimmung
Crowdsourcing-Abstimmung wurde im diesjährigen WSDM CUP-Erstplatzierungsplan eingesetzt und wurde in vergangenen inländischen Generationenwettbewerben praktiziert. Die Kernidee ist: Wenn der von einem Modell generierte Satz den Ergebnissen aller Modelle am ähnlichsten ist, kann dieser Satz als Durchschnitt aller Modelle betrachtet werden. Auf diese Weise wird der Durchschnitt im Sinne der Wahrscheinlichkeit zum Durchschnitt in den Ergebnissen der Token-Generierung. Angenommen, wir haben bei einer Teststichprobe eine Kandidatenantwort, die aggregiert werden muss. Für jeden Kandidaten berechnen wir die Korrelationsbewertung zwischen ) und () und addieren sie als Qualitätsbewertung von (). Quellen können die Kosinusähnlichkeit der Einbettungsebene (bezeichnet als emb_a_s), ROUGE-L auf Wortebene (bezeichnet als word_a_f) und ROUGE-L auf Zeichenebene (bezeichnet als char_a_f) sein. Hier sind einige künstlich konstruierte Ähnlichkeitsindikatoren, einschließlich wörtlicher. und Semantik.
Code-Adresse: https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
Fünfter, MoE
Letztes und wichtigstes, das große Modell gemischter Experten (Mixture of Experts ( Kurz gesagt, MoE: Hierbei handelt es sich um eine Modellarchitekturmethode, die mehrere Untermodelle (d. h. „Experten“) kombiniert. Sie zielt darauf ab, den Gesamtvorhersageeffekt durch die Zusammenarbeit mehrerer Experten zu verbessern Das Modell und die Betriebseffizienz. Die typische MoE-Architektur für große Modelle umfasst einen Gating-Mechanismus und eine Reihe von Expertennetzwerken. Der Gating-Mechanismus ist für die dynamische Zuweisung des Gewichts jedes Experten auf der Grundlage der Eingabedaten verantwortlich . Der Grad des Beitrags zur Ausgabe; gleichzeitig wählt der Expertenauswahlmechanismus einen Teil der Experten aus, die an der tatsächlichen Vorhersageberechnung gemäß den Anweisungen des Gating-Signals teilnehmen , sondern ermöglicht es dem Modell auch, die besten basierend auf verschiedenen Eingaben auszuwählen.
Mixture of Experts (MoE) ist kein neues Konzept. Das Konzept von Mixture of Experts geht auf das Papier „Adaptive Mixture of“ zurück „Local Experts“ wurde 1991 veröffentlicht. Ähnlich wie beim Ensemble-Lernen besteht sein Kern darin, einen Koordinations- und Fusionsmechanismus für eine Sammlung unabhängiger Expertennetzwerke zu schaffen. Bei einer solchen Architektur ist jedes unabhängige Netzwerk (d. h. „Experte“) für die Verarbeitung eines verantwortlich Bestimmter Teil des Datensatzes und Fokus auf einen bestimmten Eingabedatenbereich. Diese Teilmenge kann auf ein bestimmtes Thema, ein bestimmtes Feld, eine bestimmte Problemklassifizierung usw. ausgerichtet sein und ist kein explizites Konzept Angesichts der unterschiedlichen Eingabedaten besteht die zentrale Frage darin, wie das System entscheidet, welcher Experte damit umgeht. Das Gating-Netzwerk ist dazu da, dieses Problem zu lösen, indem es diesen Expertennetzwerken und Gates Gewichtungen zuweist Der gesamte Trainingsprozess wird gleichzeitig trainiert und erfordert keine explizite manuelle Manipulation.
Im Zeitraum von 2010 bis 2015 hatten zwei Forschungsrichtungen einen wichtigen Einfluss auf die Weiterentwicklung des Mixed Expert Model (MoE):
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
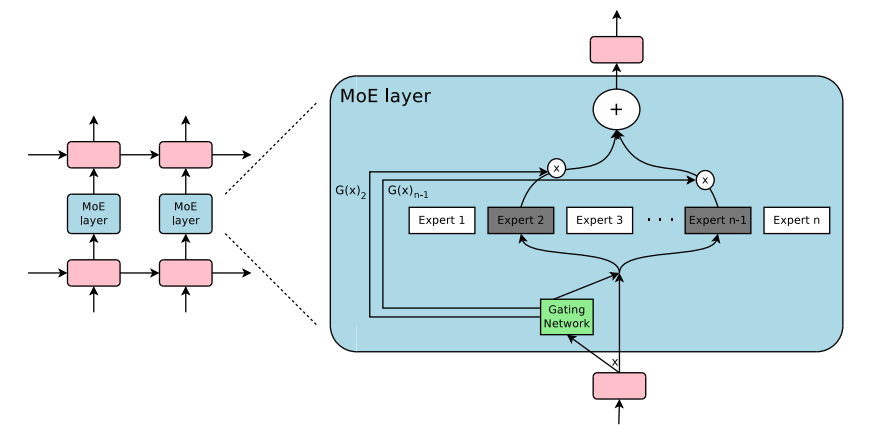
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
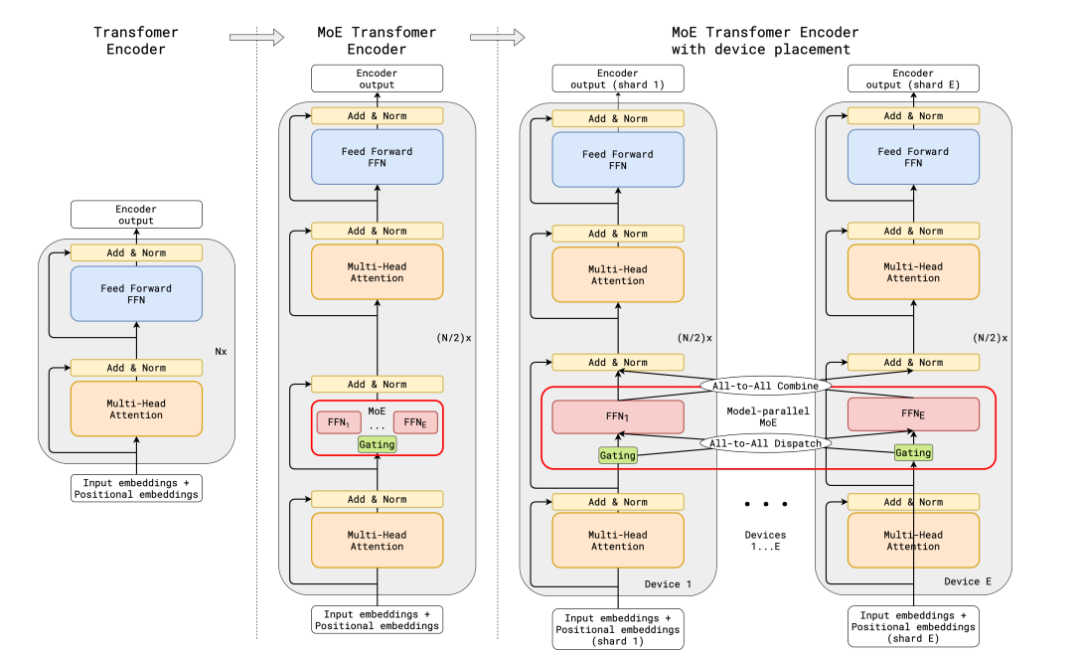
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)Im Hinblick auf die architektonische Verbesserung von MoE hat Switch Transformers eine spezielle Switch Transformer-Schicht entwickelt, die zwei unabhängige Eingaben (d. h. zwei verschiedene Token) verarbeiten kann und mit vier Experten für die Verarbeitung ausgestattet ist. Im Gegensatz zur ursprünglichen Top-2-Experten-Idee verfolgt Switch Transformers eine vereinfachte Top-1-Experten-Strategie. Wie in der folgenden Abbildung dargestellt:
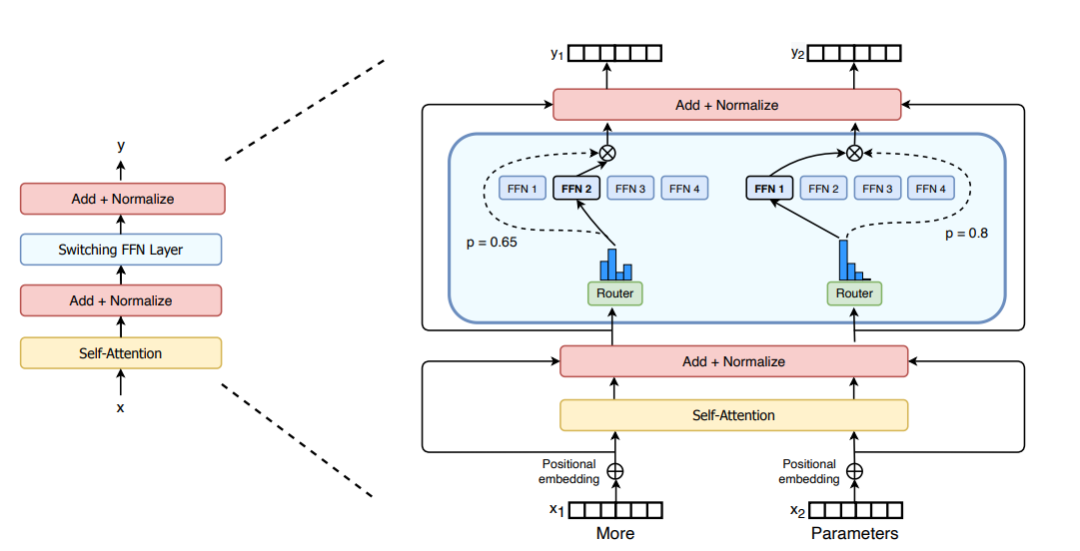 Bild
Bild
Difference, die Architektur von DeepSeek MoE, einem bekannten inländischen Großmodell, basiert auf der Prämisse, dass jedes Mal ein gemeinsamer Experte an der Aktivierung teilnimmt Ein bestimmter Experte kann ein bestimmtes Wissensgebiet beherrschen. Durch eine feinkörnige Segmentierung der Wissensbereiche der Experten kann verhindert werden, dass ein einzelner Experte zu viel Wissen beherrschen muss, und so eine Wissensverwirrung vermieden werden. Gleichzeitig stellt die Einrichtung gemeinsamer Experten sicher, dass in jede Berechnung ein Teil des allgemeingültigen Wissens einfließt. 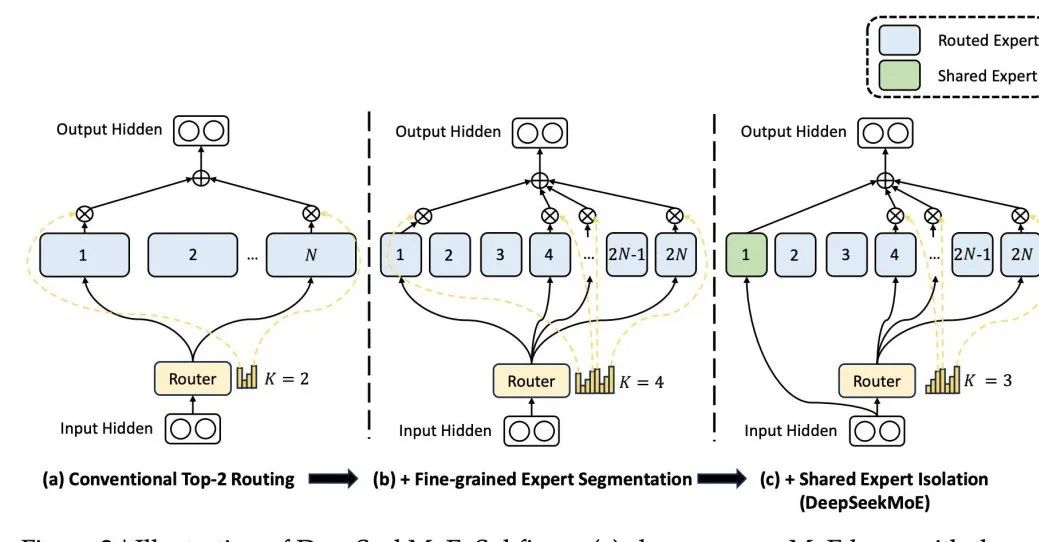 Bilder
Bilder
Das obige ist der detaillierte Inhalt vonLassen Sie uns über die Modellfusionsmethode großer Modelle sprechen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Welche anwendbaren Szenarien gibt es für das Strategiemuster?
- So sortieren Sie Excel in aufsteigender Reihenfolge
- Warum ist die Tastatur nicht alphabetisch geordnet?
- Erfahren Sie in einem Artikel mehr über watchEffect in Vue3 und sprechen Sie über seine Anwendungsszenarien!
- Trinity London integriert technologische Innovationen, um eine brillante Verbindung zwischen Kunsterziehung und künstlicher Intelligenz zu schaffen