

 Technologie-PeripheriegeräteKIGoogles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist da
Technologie-PeripheriegeräteKIGoogles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist daGoogles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist da

Da große Sprachmodelle wie GPT-4 zunehmend in die Robotik integriert werden, hält künstliche Intelligenz allmählich Einzug in die reale Welt. Daher hat auch die Forschung im Zusammenhang mit der verkörperten Intelligenz immer mehr Aufmerksamkeit auf sich gezogen. Bei vielen Forschungsprojekten stand Googles „RT“-Roboterserie schon immer an vorderster Front, und dieser Trend hat sich in letzter Zeit beschleunigt (Einzelheiten siehe „Große Modelle rekonstruieren Roboter, wie Google Deepmind verkörperte Intelligenz in der Zukunft definiert“).

Im Juli letzten Jahres brachte Google DeepMind RT-2 auf den Markt, das weltweit erste Modell, das Roboter für die Interaktion mit visueller Sprache und Aktion (VLA) steuern kann. Allein durch das Erteilen von Anweisungen im Gespräch kann RT-2 Swift auf einer großen Anzahl von Bildern identifizieren und ihr eine Dose Cola liefern.
Jetzt hat sich dieser Roboter erneut weiterentwickelt. Die neueste Version des RT-Roboters heißt „RT-H“. Er kann die Genauigkeit der Aufgabenausführung und die Lerneffizienz verbessern, indem er komplexe Aufgaben in einfache Sprachanweisungen zerlegt und diese Anweisungen dann in Roboteraktionen umwandelt. Wenn beispielsweise eine Aufgabe wie „Den Deckel auf das Pistazienglas setzen“ und ein Szenenbild gegeben wird, verwendet RT-H ein visuelles Sprachmodell (VLM), um Sprachaktionen (Bewegungen) wie „Bewege den Arm nach vorne“ vorherzusagen „ und „Drehe den Arm nach rechts“ und prognostiziere dann die Aktion des Roboters basierend auf diesen verbalen Aktionen.

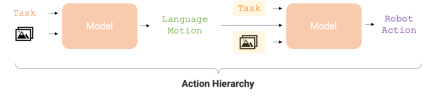
Die Aktionsebene ist entscheidend für die Optimierung der Genauigkeit und Lerneffizienz der Roboteraufgabenausführung. Durch diese hierarchische Struktur leistet RT-H bei verschiedenen Roboteraufgaben eine deutlich bessere Leistung als RT-2 und bietet dem Roboter einen effizienteren Ausführungspfad.

Im Folgenden finden Sie die Details des Papiers.
Papierübersicht

- Papiertitel: RT-H: Action Hierarchies Using Language
- Papierlink: https://arxiv.org/pdf / 2403.01823 .pdf
- Projektlink: https://rt-hierarchy.github.io/
Sprache ist der Motor des menschlichen Denkens, der es uns ermöglicht, komplexe Konzepte in einfachere Komponenten zu zerlegen und zu korrigieren unsere Missverständnisse und verallgemeinern Konzepte in neuen Kontexten. In den letzten Jahren haben Roboter auch damit begonnen, die effiziente und kombinierte Struktur der Sprache zu nutzen, um übergeordnete Konzepte aufzuschlüsseln, Sprachkorrekturen vorzunehmen oder eine Verallgemeinerung in neuen Umgebungen zu erreichen.
Diese Studien folgen in der Regel einem gemeinsamen Paradigma: Wenn sie mit einer Aufgabe auf hohem Niveau konfrontiert werden, die in der Sprache beschrieben wird (wie etwa „die Cola-Dose aufheben“), lernen sie Strategien, um Beobachtungen und Aufgabenbeschreibungen in der Sprache auf einen Roboter auf niedrigem Niveau abzubilden Maßnahmen, die durch umfangreiche Multitasking-Datensätze erreicht werden müssen. Der Vorteil der Sprache in diesen Szenarien besteht darin, dass sie eine gemeinsame Struktur zwischen ähnlichen Aufgaben kodiert (z. B. „Nimm die Cola-Dose auf“ gegenüber „Nimm den Apfel auf“) und reduziert dadurch den Datenaufwand, der zum Erlernen von Zuordnungen von Aufgaben zu Aktionen erforderlich ist. Da die Aufgaben jedoch vielfältiger werden, wird auch die Sprache, die zur Beschreibung der einzelnen Aufgaben verwendet wird, vielfältiger (z. B. „Nimm eine Cola-Dose“ statt „Fülle ein Glas Wasser auf“), sodass das Lernen zwischen verschiedenen Aufgaben ausschließlich durch Hochsprache erfolgt Es wird schwieriger, Strukturen zu teilen
Um vielfältige Aufgaben zu lernen, wollen Forscher die Ähnlichkeiten zwischen diesen Aufgaben genauer erfassen.
Sie fanden heraus, dass Sprache nicht nur Aufgaben auf hoher Ebene beschreiben, sondern auch detailliert erklären kann, wie die Aufgaben erledigt werden – diese Art der Darstellung ist feinfühliger und näher an bestimmten Aktionen. Beispielsweise kann die Aufgabe „Eine Cola-Dose aufheben“ in eine Reihe detaillierterer Schritte unterteilt werden, nämlich „Sprachbewegung“: zuerst „den Arm nach vorne strecken“, dann „die Dose greifen“ und schließlich „heben“. den Arm nach oben" ”. Die Kernerkenntnis der Forscher besteht darin, dass verbale Aktionen als Zwischenschicht zwischen Aufgabenbeschreibungen auf hoher Ebene und Aktionen auf niedriger Ebene zum Aufbau einer Aktionshierarchie verwendet werden können, die durch verbale Aktionen gebildet wird.
Es gibt mehrere Vorteile, dieses Aktionsniveau festzulegen:
- Es ermöglicht einen besseren Datenaustausch auf Sprachaktionsebene zwischen verschiedenen Aufgaben, wodurch die Kombination von Sprachaktionen und die Generalisierung in Datensätzen mit mehreren Aufgaben verbessert werden können. Obwohl beispielsweise „ein Glas Wasser einschenken“ und „eine Cola-Dose aufheben“ semantisch unterschiedlich sind, sind ihre verbalen Aktionen genau gleich, bis sie ausgeführt werden, um das Objekt aufzuheben.
- Sprachaktionen sind keine einfachen festen Grundelemente, sondern werden durch Anweisungen und visuelle Beobachtung basierend auf den Besonderheiten der aktuellen Aufgabe und Szene erlernt. Beispielsweise gibt „Arme nach vorne strecken“ nicht die Geschwindigkeit oder Richtung der Bewegung an, die von der spezifischen Aufgabe und Beobachtung abhängt. Die Kontextabhängigkeit und Flexibilität erlernter verbaler Handlungen bieten uns neue Fähigkeiten: Sie ermöglichen es Menschen, Korrekturen an verbalen Handlungen vorzunehmen, wenn die Strategie nicht zu 100 % erfolgreich ist (siehe orangefarbener Bereich in Abbildung 1). Darüber hinaus kann der Roboter sogar aus diesen menschlichen Korrekturen lernen. Wenn der Roboter beispielsweise bei der Aufgabe „Eine Cola-Dose aufheben“ den Greifer vorher schließt, können wir ihn anweisen, „den Arm länger nach vorne gestreckt zu halten“. Diese Art der Feinabstimmung ist in bestimmten Szenarien nicht möglich nur für die menschliche Führung einfach und für Roboter einfacher zu erlernen.

Angesichts der oben genannten Vorteile von Sprachaktionen haben Forscher von Google DeepMind ein End-to-End-Framework entwickelt – RT-H (Robot Transformer with Action Hierarchies, also Robotertransformatoren mit Aktionsebenen). , wobei der Schwerpunkt auf dem Erlernen dieser Handlungsebene liegt. RT-H versteht, wie eine Aufgabe auf detaillierter Ebene ausgeführt werden kann, indem es Beobachtungen und Aufgabenbeschreibungen auf hoher Ebene analysiert, um aktuelle verbale Handlungsanweisungen vorherzusagen. Mithilfe dieser Beobachtungen, Aufgaben und abgeleiteten verbalen Aktionen sagt RT-H dann die entsprechenden Aktionen für jeden Schritt voraus. Die verbalen Aktionen liefern zusätzlichen Kontext im Prozess, um dabei zu helfen, bestimmte Aktionen genauer vorherzusagen (violetter Bereich in Abbildung 1).
Darüber hinaus entwickelten sie eine automatisierte Methode, um vereinfachte Sprachaktionssätze aus der Propriozeption des Roboters zu extrahieren und so eine umfangreiche Datenbank mit mehr als 2500 Sprachaktionen aufzubauen, ohne dass manuelle Anmerkungen erforderlich sind.
Die Modellarchitektur von RT-H basiert auf RT-2, einem groß angelegten visuellen Sprachmodell (VLM), das gemeinsam auf visuellen und sprachlichen Daten im Internetmaßstab trainiert wird, um die Effekte des politischen Lernens zu verbessern. RT-H verwendet ein einziges Modell, um sowohl Sprachaktionen als auch Aktionsabfragen zu verarbeiten, und nutzt dabei umfassendes Wissen im Internetmaßstab, um jede Ebene der Aktionshierarchie zu unterstützen.
In Experimenten fanden Forscher heraus, dass die Verwendung der Sprachaktionshierarchie bei der Verarbeitung verschiedener Multitask-Datensätze erhebliche Verbesserungen bringen kann und die Leistung bei einer Reihe von Aufgaben im Vergleich zu RT-2 um 15 % steigert. Sie fanden außerdem heraus, dass Modifikationen der Sprechbewegungen zu nahezu perfekten Erfolgsraten bei derselben Aufgabe führten, was die Flexibilität und situative Anpassungsfähigkeit der erlernten Sprechbewegungen demonstrierte. Darüber hinaus übertrifft seine Leistung durch die Feinabstimmung des Modells für sprachliche Handlungsinterventionen die interaktiven Imitationslernmethoden von SOTA (wie IWR) um 50 %. Letztendlich haben sie bewiesen, dass sich Sprachaktionen in RT-H besser an Szenen- und Objektänderungen anpassen können und eine bessere Generalisierungsleistung als RT-2 zeigen.
RT-H-Architektur im Detail
Um die gemeinsame Struktur über Multitask-Datensätze hinweg effektiv zu erfassen (nicht durch Aufgabenbeschreibungen auf hoher Ebene dargestellt), möchte RT-H lernen, Richtlinien auf Aktionsebene explizit zu nutzen.
Konkret führte das Forschungsteam die Zwischenschicht zur Vorhersage von Sprachaktionen in das politische Lernen ein. Sprachliche Aktionen, die das feinkörnige Verhalten von Robotern beschreiben, können nützliche Informationen aus Multitask-Datensätzen erfassen und leistungsstarke Richtlinien generieren. Sprachaktionen können erneut ins Spiel kommen, wenn die erlernte Richtlinie schwierig umzusetzen ist: Sie bieten eine intuitive Schnittstelle für Online-Korrekturen durch Menschen, die für ein bestimmtes Szenario relevant sind. Auf Sprachaktionen trainierte Richtlinien können auf natürliche Weise menschlichen Korrekturen auf niedriger Ebene folgen und Aufgaben anhand von Korrekturdaten erfolgreich abschließen. Darüber hinaus kann die Strategie sogar auf sprachkorrigierten Daten trainiert werden und ihre Leistung weiter verbessern.
Wie in Abbildung 2 dargestellt, besteht RT-H aus zwei Hauptphasen: Zuerst werden verbale Aktionen auf der Grundlage von Aufgabenbeschreibungen und visuellen Beobachtungen vorhergesagt, und dann werden präzise Aktionen basierend auf vorhergesagten verbalen Aktionen, spezifischen Aufgaben und Beobachtungsergebnissen abgeleitet.

RT-H nutzt das VLM-Backbone-Netzwerk und folgt dem Trainingsprozess von RT-2 zur Instanziierung. Ähnlich wie RT-2 nutzt RT-H umfangreiche Vorkenntnisse in natürlicher Sprache und Bildverarbeitung aus Daten im Internetmaßstab durch kollaboratives Training. Um dieses Vorwissen in alle Ebenen der Aktionshierarchie zu integrieren, lernt ein einzelnes Modell gleichzeitig sowohl verbale Aktionen als auch Aktionsabfragen.
Experimentelle Ergebnisse
Um die Leistung von RT-H umfassend zu bewerten, stellte das Forschungsteam vier wichtige experimentelle Fragen:
- F1 (Leistung): Wie hoch kann die Handlungsebene mit Sprache sein? verbessert? Richtlinienleistung für Aufgabendatensatz?
- F2 (Situativ): Stehen die von RT-H gelernten Sprachaktionen mit der Aufgabe und dem Szenenkontext in Zusammenhang?
- F3 (Korrektur): Ist das Training zur Sprachbewegungskorrektur besser als die teleoperierte Korrektur?
- F4 (Zusammenfassung): Können Aktionshierarchien die Robustheit in Umgebungen außerhalb der Verteilung verbessern?
In Bezug auf den Datensatz verwendet diese Studie einen großen Multitasking-Datensatz mit 100.000 Demonstrationsproben mit zufälligen Objektposen und Hintergründen. Dieser Datensatz kombiniert die folgenden Datensätze:
- Küche: der von RT-1 und RT-2 verwendete Datensatz, bestehend aus 6 semantischen Aufgabenkategorien aus 70.000 Stichproben.
- Diverse: Ein neuer Datensatz, der aus komplexeren Aufgaben besteht, mit mehr als 24 semantischen Aufgabenkategorien, aber nur 30.000 Stichproben.
Die Studie nennt diesen kombinierten Datensatz den Diverse+Kitchen (D+K)-Datensatz und verwendet ein automatisiertes Programm, um ihn für verbale Aktionen zu kennzeichnen. Um die Leistung von RT-H zu bewerten, das auf dem gesamten Diverse+Kitchen-Datensatz trainiert wurde, wurden in der Studie acht spezifische Aufgaben ausgewertet, darunter:
1) Die Schüssel aufrecht auf die Theke stellen
2) Das Pistazienglas öffnen
3) Schließen Sie das Pistazienglas
4) Bewegen Sie die Schüssel vom Müslispender weg
5) Stellen Sie die Schüssel unter den Müslispender
6) Geben Sie die Haferflocken in die Schüssel
7) Löffel aus Korb holen
8) Serviette aus Spender ziehen
Diese acht Aufgaben wurden ausgewählt, weil sie komplexe Bewegungsabläufe und hohe Präzision erfordern.
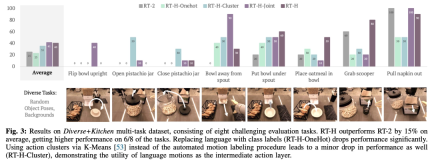
Die folgende Tabelle gibt den minimalen MSE für RT-H-, RT-H-Joint- und RT-2-Trainingskontrollpunkte an, wenn mit dem Diverse+Kitchen-Datensatz oder dem Kitchen-Datensatz trainiert wird. Der MSE von RT-H ist etwa 20 % niedriger als der von RT-2, und der MSE von RTH-Joint ist 5–10 % niedriger als der von RT-2, was darauf hindeutet, dass die Aktionshierarchie dazu beitragen kann, die Offline-Aktionsvorhersage in großen Multi- Aufgabendatensätze. RT-H (GT) verwendet die Ground-Truth-MSE-Metrik und erreicht einen Abstand von 40 % zum End-to-End-MSE, was darauf hinweist, dass korrekt gekennzeichnete Sprachaktionen einen hohen Informationswert für die Vorhersage von Aktionen haben.

Abbildung 4 zeigt mehrere Beispiele kontextbezogener Maßnahmen aus der RT-H-Onlinebewertung. Wie man sehen kann, führt dieselbe verbale Handlung oft zu subtilen Änderungen in den Handlungen, um die Aufgabe zu erfüllen, während die verbale Handlung auf höherer Ebene dennoch respektiert wird.

Wie in Abbildung 5 dargestellt, demonstrierte das Forschungsteam die Flexibilität von RT-H, indem es online in Sprachbewegungen in RT-H intervenierte.

Diese Studie verwendete auch Vergleichsexperimente, um die Wirkung der Korrektur zu analysieren. Die Ergebnisse sind in Abbildung 6 unten dargestellt:
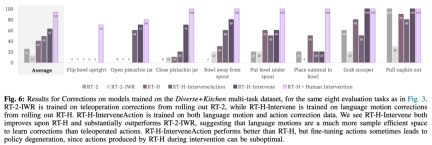
Wie in Abbildung 7 gezeigt, RT-H und RT-H-. Gelenke haben unterschiedliche Auswirkungen auf die Szene. Veränderungen sind spürbar robuster:

Tatsächlich gibt es eine gewisse gemeinsame Struktur zwischen scheinbar unterschiedlichen Aufgaben. Beispielsweise erfordert jede dieser Aufgaben ein gewisses Auswahlverhalten, um die Aufgabe zu starten, und durch das Erlernen der gemeinsamen Struktur von Sprachaktionen über verschiedene Aufgaben hinweg kann RT-H das Aufnehmen erreichen Bühne ohne jegliche Korrektur.

Selbst wenn RT-H nicht mehr in der Lage ist, seine verbalen Handlungsvorhersagen zu verallgemeinern, können verbale Handlungskorrekturen häufig verallgemeinert werden, sodass nur wenige Korrekturen erforderlich sind, um die Aufgabe erfolgreich abzuschließen. Dies zeigt das Potenzial verbaler Aktionen zur Erweiterung der Datenerfassung auf neue Aufgaben.
Interessierte Leser können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonGoogles neue Forschung zur verkörperten Intelligenz: RT-H, das besser als RT-2 ist, ist da. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AM
So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AMNutzen Sie die Kraft von AI On-Device: Bauen eines persönlichen Chatbot-Cli In der jüngeren Vergangenheit schien das Konzept eines persönlichen KI -Assistenten wie Science -Fiction zu sein. Stellen Sie sich Alex vor, ein Technik -Enthusiast, der von einem klugen, lokalen KI -Begleiter träumt - einer, der nicht angewiesen ist
 KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AM
KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AMIhre Eröffnungseinführung von AI4MH fand am 15. April 2025 statt, und Luminary Dr. Tom Insel, M. D., berühmter Psychiater und Neurowissenschaftler, diente als Kick-off-Sprecher. Dr. Insel ist bekannt für seine herausragende Arbeit in der psychischen Gesundheitsforschung und für Techno
 Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM
Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM"Wir möchten sicherstellen, dass die WNBA ein Raum bleibt, in dem sich alle, Spieler, Fans und Unternehmenspartner sicher fühlen, geschätzt und gestärkt sind", erklärte Engelbert und befasste sich mit dem, was zu einer der schädlichsten Herausforderungen des Frauensports geworden ist. Die Anno
 Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AM
Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AMEinführung Python zeichnet sich als Programmiersprache aus, insbesondere in der Datenwissenschaft und der generativen KI. Eine effiziente Datenmanipulation (Speicherung, Verwaltung und Zugriff) ist bei der Behandlung großer Datensätze von entscheidender Bedeutung. Wir haben zuvor Zahlen und ST abgedeckt
 Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AM
Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AMVor dem Eintauchen ist eine wichtige Einschränkung: KI-Leistung ist nicht deterministisch und sehr nutzungsgewohnt. In einfacherer Weise kann Ihre Kilometerleistung variieren. Nehmen Sie diesen (oder einen anderen) Artikel nicht als endgültiges Wort - testen Sie diese Modelle in Ihrem eigenen Szenario
 AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AM
AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AMErstellen eines herausragenden KI/ML -Portfolios: Ein Leitfaden für Anfänger und Profis Das Erstellen eines überzeugenden Portfolios ist entscheidend für die Sicherung von Rollen in der künstlichen Intelligenz (KI) und des maschinellen Lernens (ML). Dieser Leitfaden bietet Rat zum Erstellen eines Portfolios
 Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AM
Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AMDas Ergebnis? Burnout, Ineffizienz und eine Erweiterung zwischen Erkennung und Wirkung. Nichts davon sollte für jeden, der in Cybersicherheit arbeitet, einen Schock erfolgen. Das Versprechen der Agenten -KI hat sich jedoch als potenzieller Wendepunkt herausgestellt. Diese neue Klasse
 Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AM
Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AMSofortige Auswirkungen gegen langfristige Partnerschaft? Vor zwei Wochen hat Openai ein leistungsstarkes kurzfristiges Angebot vorangetrieben und bis Ende Mai 2025 den kostenlosen Zugang zu Chatgpt und Ende Mai 2025 gewährt. Dieses Tool enthält GPT-4O, A A A.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

Dreamweaver CS6
Visuelle Webentwicklungstools

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

