
Heim >Technologie-Peripheriegeräte >KI >Das MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab
Das MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab

- PHPznach vorne
- 2024-03-11 13:10:10553Durchsuche
Obwohl multimodale Modelle im Bereich des Videoverständnisses Durchbrüche bei der Analyse kurzer Videos erzielt und starke Verständnisfähigkeiten gezeigt haben, scheinen sie bei langen Videos auf Filmebene machtlos zu sein. Daher ist die Analyse und das Verständnis langer Videos, insbesondere das Verständnis stundenlanger Filminhalte, heutzutage zu einer großen Herausforderung geworden.
Die Schwierigkeit des Modells, lange Videos zu verstehen, ist hauptsächlich auf den Mangel an Datenressourcen für lange Videos zurückzuführen, die Mängel in Qualität und Vielfalt aufweisen. Darüber hinaus erfordert das Sammeln und Kennzeichnen dieser Daten einen hohen Arbeitsaufwand.
Angesichts eines solchen Problems schlug das Forschungsteam von Tencent und der Fudan-Universität MovieLLM vor, ein innovatives KI-Generierungs-Framework. MovieLLM verwendet eine innovative Methode, die nicht nur qualitativ hochwertige und vielfältige Videodaten generiert, sondern auch automatisch eine große Anzahl verwandter Frage- und Antwortdatensätze generiert, wodurch die Dimension und Tiefe der Daten erheblich bereichert wird und der gesamte automatisierte Prozess ebenfalls äußerst hoch ist Dadi reduziert menschliche Investitionen.

- Papieradresse: https://arxiv.org/abs/2403.01422
- Homepage-Adresse: https://deaddawn.github.io/MovieLLM/
Diese wichtige Entwicklung verbessert nicht nur das Verständnis des Modells für komplexe Videoerzählungen, sondern erweitert auch die analytischen Fähigkeiten des Modells bei der Verarbeitung stundenlanger Filminhalte. Gleichzeitig überwindet es die Einschränkungen der Knappheit und Verzerrung vorhandener Datensätze und bietet eine neue und effektive Möglichkeit, ultralange Videoinhalte zu verstehen.
MovieLLM nutzt geschickt die leistungsstarken Generierungsfähigkeiten von GPT-4 und Diffusionsmodellen und wendet eine „story-expandierende“ Strategie zur kontinuierlichen Generierung von Frame-Beschreibungen an. Die Methode der „Textinversion“ wird verwendet, um das Diffusionsmodell so zu steuern, dass Szenenbilder generiert werden, die mit der Textbeschreibung übereinstimmen, wodurch fortlaufende Bilder eines vollständigen Films erstellt werden.

Methodenübersicht
MovieLLM kombiniert GPT-4 und Diffusionsmodelle, um das Verständnis großer Modelle für lange Videos zu verbessern. Diese clevere Kombination erzeugt hochwertige, vielfältige lange Videodaten sowie QA-Fragen und -Antworten und trägt so dazu bei, die generativen Fähigkeiten des Modells zu verbessern.
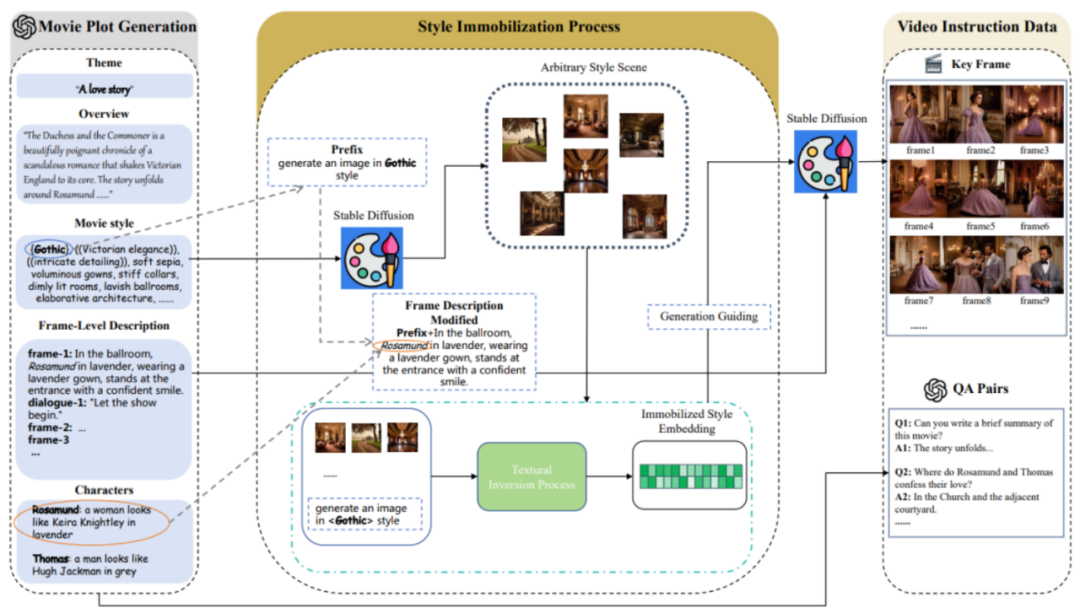
MovieLLM umfasst hauptsächlich drei Phasen:
1. Filmhandlungserstellung.
MovieLLM verlässt sich bei der Generierung von Plots nicht auf das Web oder vorhandene Datensätze, sondern nutzt die Leistungsfähigkeit von GPT-4 voll aus, um synthetische Daten zu erzeugen. Durch die Bereitstellung spezifischer Elemente wie Thema, Übersicht und Stil wird GPT-4 angeleitet, filmische Keyframe-Beschreibungen zu erstellen, die auf den nachfolgenden Generierungsprozess zugeschnitten sind.
2. Stilfixierungsprozess.
MovieLLM nutzt geschickt die Technologie der „Textinversion“, um die im Drehbuch generierte Stilbeschreibung im latenten Raum des Diffusionsmodells zu fixieren. Diese Methode führt das Modell dazu, Szenen mit einem festen Stil zu generieren und die Vielfalt bei gleichzeitiger Beibehaltung einer einheitlichen Ästhetik beizubehalten.
3. Generierung von Videobefehlsdaten.
Basierend auf den ersten beiden Schritten wurden eine feste Stileinbettung und eine Keyframe-Beschreibung erstellt. Auf dieser Grundlage nutzt MovieLLM die Einbettung von Stilen, um das Diffusionsmodell so zu steuern, dass es Schlüsselbilder generiert, die den Schlüsselbildbeschreibungen entsprechen, und generiert nach und nach verschiedene Frage- und Antwortpaare mit Anweisungen entsprechend der Filmhandlung.

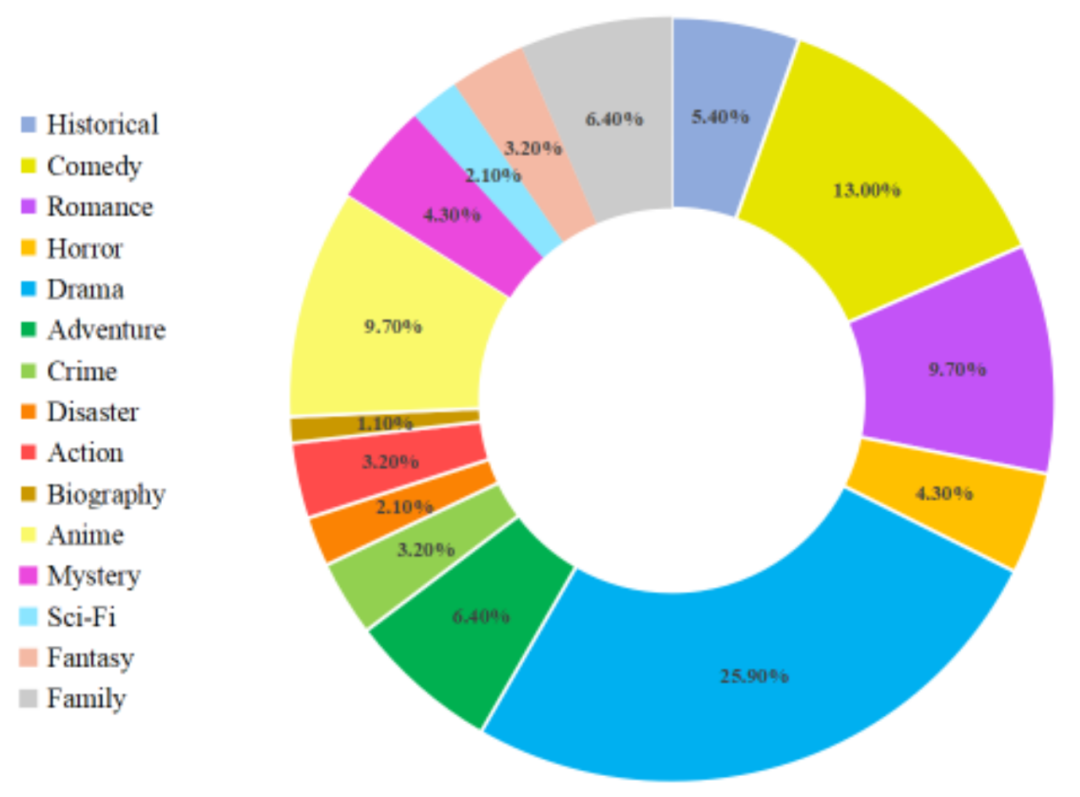
Nach den oben genannten Schritten hat MovieLLM hochwertige, vielfältige Stile, kohärente Filmbilder und entsprechende Frage-Antwort-Paardaten erstellt. Die detaillierte Verteilung der Filmdatentypen ist wie folgt:
Experimentelle Ergebnisse
Durch die Anwendung von auf MovieLLM erstellten Daten zur Feinabstimmung auf LLaMA-VID, einem großen Modell, das sich auf das Verständnis langer Videos konzentriert, verbessert dieser Artikel die Fähigkeit des Modells, Videoinhalte unterschiedlicher Länge zu verstehen, erheblich. Für das Verständnis langer Videos gibt es derzeit keine Arbeit, die einen Test-Benchmark vorschlägt. Daher wird in diesem Artikel auch ein Benchmark zum Testen der Fähigkeiten zum Verstehen langer Videos vorgeschlagen.
Obwohl MovieLLM keine speziellen Kurzvideodaten für das Training erstellt hat, wurden durch das Training dennoch Leistungsverbesserungen bei verschiedenen Kurzvideo-Benchmarks beobachtet:
In MSVD-QA und MSRVTT – im Vergleich zu Mit dem Basismodell hat sich die Qualitätssicherung bei diesen beiden Testdatensätzen deutlich verbessert.

Beim videogenerierungsbasierten Leistungsbenchmark wurden in allen fünf Bewertungsbereichen Leistungsverbesserungen erzielt.
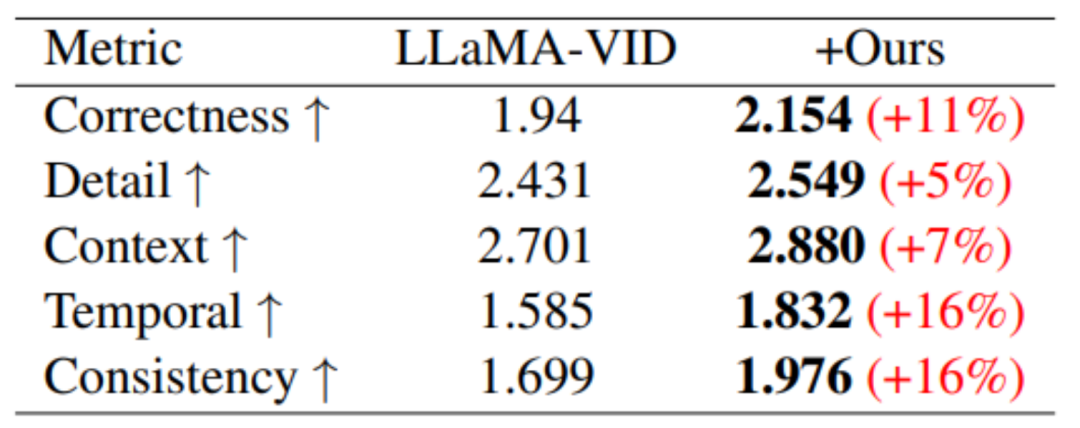
In Bezug auf das Verständnis langer Videos wurde durch das Training von MovieLLM das Verständnis des Modells für Zusammenfassung, Handlung und Timing erheblich verbessert.

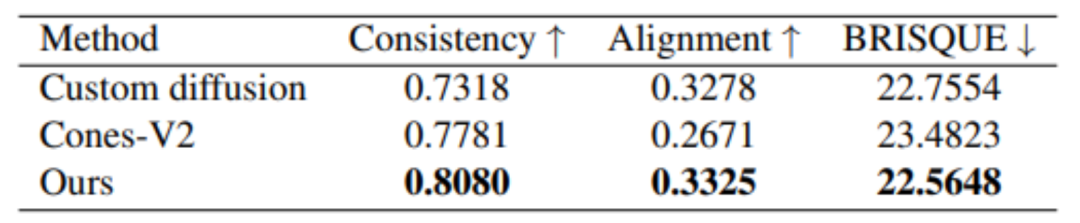
Darüber hinaus erzielt MovieLLM auch bessere Ergebnisse in Bezug auf die Generierungsqualität im Vergleich zu anderen ähnlichen Methoden zur Bildgenerierung mit festem Stil.
Kurz gesagt, der von MovieLLM vorgeschlagene Arbeitsablauf zur Datengenerierung reduziert die Herausforderung der Erstellung von Videodaten auf Filmebene für Modelle erheblich und verbessert die Kontrolle und Vielfalt der generierten Inhalte. Gleichzeitig verbessert MovieLLM die Fähigkeit des multimodalen Modells, lange Videos auf Filmebene zu verstehen, erheblich und bietet so eine wertvolle Referenz für andere Bereiche, um ähnliche Datengenerierungsmethoden zu übernehmen.
Leser, die sich für diese Forschung interessieren, können den Originaltext des Artikels lesen, um mehr über den Forschungsinhalt zu erfahren.
Das obige ist der detaillierte Inhalt vonDas MovieLLM-Framework von Tencent nutzt KI-Kurzvideos, um das Verständnis langer Videos „zurückzumelden', und zielt auf die kontinuierliche Bildgenerierung auf Filmebene ab. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!