
Heim >Technologie-Peripheriegeräte >KI >OccFusion: Ein einfaches und effektives Multisensor-Fusion-Framework für Occ (Performance SOTA)
OccFusion: Ein einfaches und effektives Multisensor-Fusion-Framework für Occ (Performance SOTA)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-03-08 11:50:03852Durchsuche
Ein umfassendes Verständnis von 3D-Szenen ist beim autonomen Fahren von entscheidender Bedeutung, und neuere semantische 3D-Belegungsvorhersagemodelle haben die Herausforderung, reale Objekte mit unterschiedlichen Formen und Kategorien zu beschreiben, erfolgreich gemeistert. Bestehende 3D-Belegungsvorhersagemethoden basieren jedoch stark auf Panoramakamerabildern, was sie anfällig für Änderungen der Licht- und Wetterbedingungen macht. Durch die Integration der Funktionen zusätzlicher Sensoren wie Lidar und Rundumsichtradar verbessert unser Framework die Genauigkeit und Robustheit der Belegungsvorhersage, was zu einer Spitzenleistung im nuScenes-Benchmark führt. Darüber hinaus bestätigen umfangreiche Experimente mit dem nuScene-Datensatz, einschließlich anspruchsvoller Nacht- und Regenszenen, die überlegene Leistung unserer Sensorfusionsstrategie über verschiedene Erfassungsbereiche hinweg.
Link zum Dokument: https://arxiv.org/pdf/2403.01644.pdf
Name des Dokuments: OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction
Die Hauptbeiträge dieses Artikels sind wie folgt zusammengefasst :
- Es wird ein Multisensor-Fusionsframework vorgeschlagen, um Kamera-, Lidar- und Radarinformationen zu integrieren, um semantische 3D-Belegungsvorhersageaufgaben durchzuführen.
- In der semantischen 3D-Belegungsvorhersageaufgabe wird unsere Methode mit anderen hochmodernen (SOTA)-Algorithmen verglichen, um die Vorteile der Multisensorfusion zu demonstrieren.
- Es wurden gründliche Ablationsstudien durchgeführt, um die Leistungssteigerungen zu bewerten, die durch verschiedene Sensorkombinationen unter schwierigen Licht- und Wetterbedingungen wie Nacht und Regen erzielt werden.
- Eine umfassende Studie wurde durchgeführt, um den Einfluss von Wahrnehmungsbereichsfaktoren auf die Leistung unseres Frameworks bei semantischen 3D-Belegungsvorhersageaufgaben zu analysieren, wobei verschiedene Sensorkombinationen und anspruchsvolle Szenarien berücksichtigt wurden!
Übersicht über die Netzwerkstruktur
Die Gesamtarchitektur von OccFusion ist wie folgt. Zunächst werden Rundumsichtbilder in ein 2D-Backbone eingegeben, um mehrskalige Merkmale zu extrahieren. Anschließend wird in jedem Maßstab eine Ansichtstransformation durchgeführt, um globale BEV-Features und lokales 3D-Feature-Volumen auf jeder Ebene zu erhalten. Die von Lidar und Surround-Radar erzeugten 3D-Punktwolken werden auch in das 3D-Backbone eingegeben, um mehrskalige lokale 3D-Feature-Mengen und globale BEV-Features zu generieren. Dynamische Fusions-3D/2D-Module auf jeder Ebene kombinieren die Fähigkeiten von Kameras und Lidar/Radar. Danach werden die zusammengeführten globalen BEV-Features und das lokale 3D-Feature-Volumen auf jeder Ebene in die global-lokale Aufmerksamkeitsfusion eingespeist, um das endgültige 3D-Volumen auf jeder Skala zu erzeugen. Schließlich wird das 3D-Volumen auf jeder Ebene mit einem Multiskalen-Überwachungsmechanismus hochgesampelt und übersprungsverbunden.
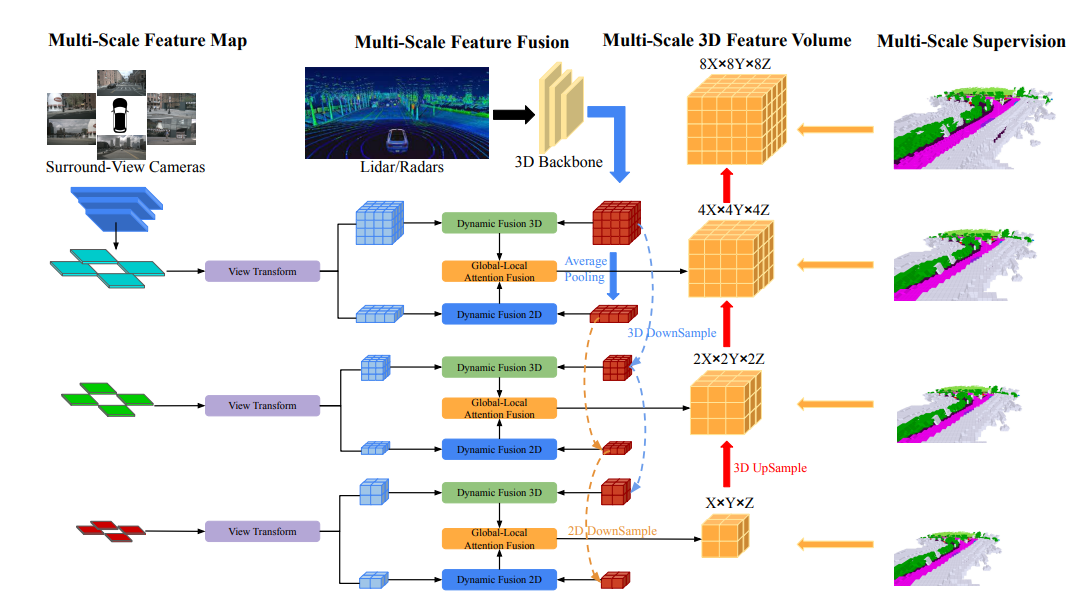
Experimentelle Vergleichsanalyse
Auf dem nuScenes-Validierungssatz werden die Ergebnisse verschiedener Methoden demonstriert, die auf dem Training dichter Belegungsbezeichnungen in der semantischen 3D-Belegungsvorhersage basieren. Diese Methoden umfassen verschiedene modale Konzepte, darunter Kamera (C), Lidar (L) und Radar (R).
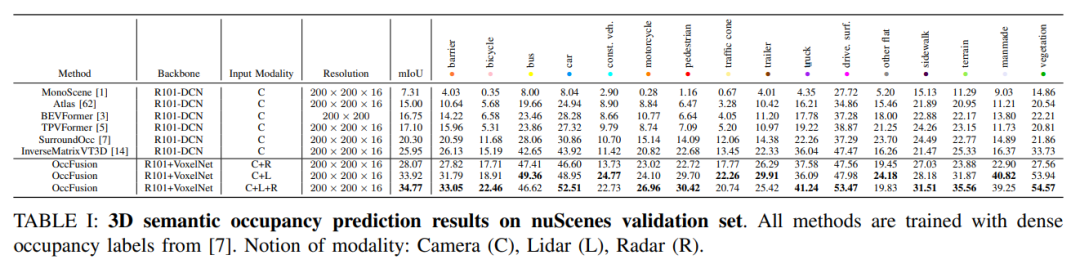
Für die Regenszenen-Teilmenge des nuScenes-Datensatzes sagen wir die semantische 3D-Belegung voraus und verwenden dichte Belegungsbezeichnungen für das Training. In diesem Experiment haben wir Daten von verschiedenen Modalitäten wie Kamera (C), Lidar (L), Radar (R) usw. berücksichtigt. Die Fusion dieser Modi kann uns helfen, Regenszenen besser zu verstehen und vorherzusagen, und stellt eine wichtige Referenz für die Entwicklung autonomer Fahrsysteme dar.
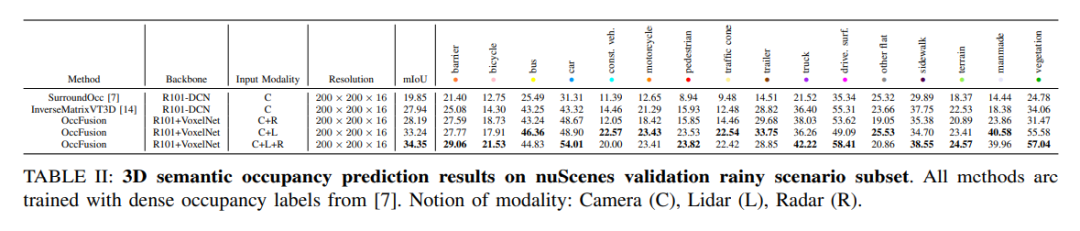
nuScenes validiert semantische 3D-Belegungsvorhersageergebnisse für eine Teilmenge von Nachtszenen. Alle Methoden werden mithilfe dichter Belegungsetiketten trainiert. Modale Konzepte: Kamera (C), Lidar (L), Radar (R).
Leistungsänderungstrends. (a) Leistungsänderungstrend des gesamten nuScenes-Validierungssatzes, (b) nuScenes-Validierungsnachtszenen-Teilsatz und (c) nuScene-Validierungsleistungsänderungstrend des Regenszenen-Teilsatzes.
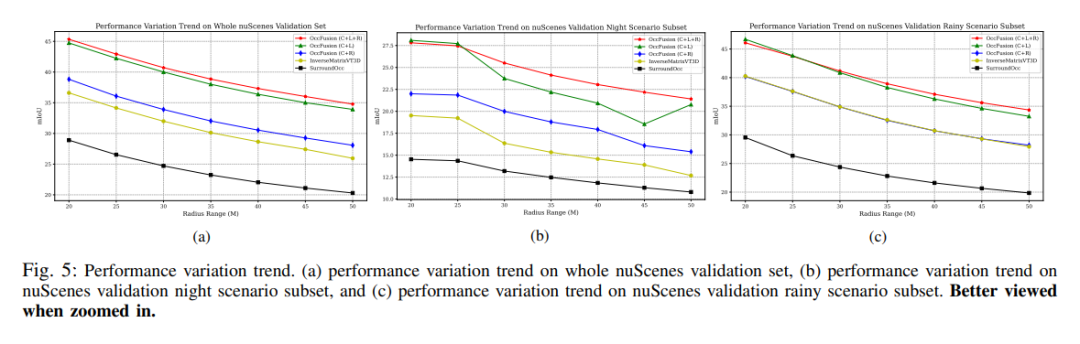
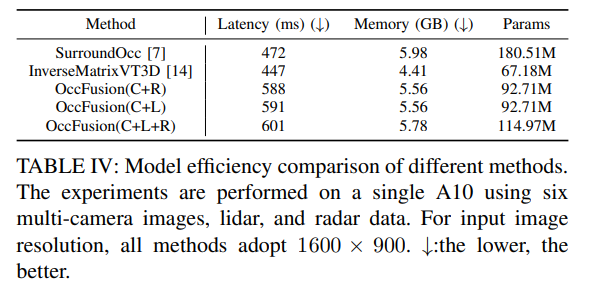
Tabelle 4: Vergleich der Modelleffizienz verschiedener Methoden. Auf einem A10 wurden Experimente mit sechs Multikamerabildern sowie Lidar- und Radardaten durchgeführt. Für die Auflösung des Eingabebildes verwenden alle Methoden 1600×900. ↓:Je niedriger desto besser.
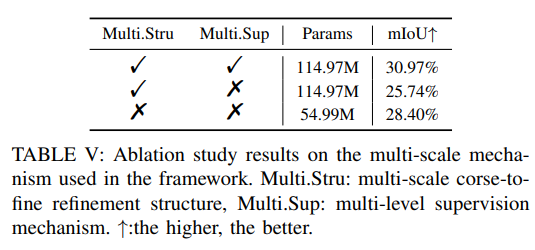
Weitere Ablationsexperimente:


Das obige ist der detaillierte Inhalt vonOccFusion: Ein einfaches und effektives Multisensor-Fusion-Framework für Occ (Performance SOTA). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Beispiel für ein WeChat Mini-Programm: Implementierung eines 3D-Karussell-Spezialeffektcodes
- Kann Unity3d in Python geschrieben werden?
- AirPods Pro und AirPods 3: So ändern Sie die Kraftsensorsteuerung
- Passive drahtlose Sensornetzwerke in PHP
- Lernen Sie PHP-Programmierung: Lesen von Sensordaten über IoT-Hardware